Recognition: no theorem link
Reasoning Gets Harder for LLMs Inside A Dialogue
Pith reviewed 2026-05-15 08:07 UTC · model grok-4.3
The pith
LLMs show a substantial and consistent drop in reasoning performance when tasks are embedded inside multi-turn dialogues rather than presented in isolation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the same reasoning problems are placed inside task-oriented dialogues instead of given as standalone questions, LLMs exhibit a substantial and consistent performance decline; controlled ablations indicate the multi-turn nature of dialogue is the dominant factor, with additional contributions from role instructions and tool-use requirements.
What carries the argument
BOULDER, a dynamic benchmark that supplies matched isolated and dialogue variants for eight travel tasks requiring arithmetic, spatial, temporal, commonsense, and formal reasoning.
If this is right
- Isolated-benchmark scores cannot be treated as reliable proxies for reasoning ability in live interactive systems.
- Model evaluation protocols should routinely include multi-turn dialogue variants to surface hidden weaknesses.
- Training objectives may need explicit exposure to interleaved reasoning and instruction-following within conversations.
- Tool-augmented dialogue agents will likely underperform on reasoning steps unless the dialogue context itself is part of the training signal.
Where Pith is reading between the lines
- Developers of dialogue systems may need new fine-tuning regimes that simulate full conversation histories rather than single prompts.
- The gap could widen further in longer sessions or with more complex role constraints, suggesting a scaling law for dialogue depth.
- Existing safety and alignment techniques tuned on isolated prompts may transfer poorly once models must maintain persona across turns.
Load-bearing premise
The observed performance gap stems mainly from the multi-turn interactive format rather than from benchmark artifacts, differing levels of data contamination, or variations in prompt length and structure.
What would settle it
Re-running the eight tasks with dialogue variants that are forced to single-turn responses while exactly matching token length, role instructions, and output format constraints, then finding no remaining performance gap.
Figures


































read the original abstract
Large Language Models (LLMs) achieve strong performance on many reasoning benchmarks, yet these evaluations typically focus on isolated tasks that differ from real-world usage in task-oriented dialogue (TOD). In this setting, LLMs must perform reasoning inherently while generating text and adhering to instructions on role, format, and style. This mismatch raises concerns about whether benchmark performance accurately reflects models' reasoning robustness in TOD setting. We investigate how framing reasoning tasks within TOD affects LLM performance by introducing BOULDER, a new dynamic benchmark covering eight travel-related tasks that require arithmetic, spatial, and temporal reasoning with both commonsense and formal aspects. Each problem is presented in both isolated and dialogue-based variants, enabling controlled comparison while mitigating data contamination. Experiments on eight LLMs reveal a substantial and consistent performance gap between isolated and dialogue settings. Through ablations and qualitative analysis, we show that this gap is largely driven by the multi-turn nature of dialogue, with additional effects from role conditioning and tool-use requirements. Our results highlight the need to evaluate LLM reasoning in realistic interactive scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BOULDER, a dynamic benchmark of eight travel-related tasks requiring arithmetic, spatial, and temporal reasoning. Each task is instantiated in matched isolated and dialogue-based variants; experiments on eight LLMs report a consistent performance drop in the dialogue setting, which ablations and qualitative analysis attribute primarily to multi-turn interaction, with secondary contributions from role conditioning and tool-use requirements.
Significance. If the controlled comparison holds, the work demonstrates that standard isolated reasoning benchmarks can overestimate LLM capabilities relative to realistic task-oriented dialogue, providing a concrete motivation for interactive evaluation protocols. The benchmark design that re-uses the same underlying problems across framings is a methodological strength that reduces contamination concerns.
major comments (2)
- [§4 and §5] §4 (Results) and §5 (Ablations): the central claim that the gap is 'largely driven by the multi-turn nature' requires explicit confirmation that isolated baselines receive identical role, format, and style instructions on every turn; without a side-by-side prompt template comparison, the ablation results risk conflating turn count with differences in instruction complexity and output constraints.
- [Abstract and §4] Abstract and §4: the reported 'substantial and consistent performance gap' is stated without numerical values, per-task accuracies, error bars, or exact problem counts; the results tables must include these quantities together with statistical tests to allow readers to assess effect size and variability across the eight models.
minor comments (2)
- [§3] §3 (Benchmark construction): specify the exact number of problems generated per task and the precise mechanism used to ensure the isolated and dialogue variants remain semantically identical while varying only the interaction framing.
- [Figure 2 and Table 1] Figure 2 and Table 1: axis labels and legend entries should explicitly distinguish 'isolated' from 'dialogue' conditions and indicate whether error bars represent standard deviation across models or across problem instances.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity in our experimental design and results presentation. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Results) and §5 (Ablations): the central claim that the gap is 'largely driven by the multi-turn nature' requires explicit confirmation that isolated baselines receive identical role, format, and style instructions on every turn; without a side-by-side prompt template comparison, the ablation results risk conflating turn count with differences in instruction complexity and output constraints.
Authors: We agree that explicit confirmation is necessary to strengthen the claim. In the isolated setting, each problem receives the identical role, format, and style instructions as the first turn of the corresponding dialogue variant (with no subsequent turns). To eliminate any ambiguity and allow readers to verify that instruction complexity does not confound the multi-turn factor, we will add side-by-side prompt templates for both conditions in the revised appendix. This addition will directly support the ablation results attributing the gap primarily to multi-turn interaction. revision: yes
-
Referee: [Abstract and §4] Abstract and §4: the reported 'substantial and consistent performance gap' is stated without numerical values, per-task accuracies, error bars, or exact problem counts; the results tables must include these quantities together with statistical tests to allow readers to assess effect size and variability across the eight models.
Authors: We will revise §4 to expand the results tables with per-task accuracies, exact problem counts per task and model, error bars (standard deviation across multiple runs), and statistical significance tests (paired t-tests with p-values) for the isolated vs. dialogue gaps. These details will enable assessment of effect sizes and variability. The abstract will remain a high-level summary, but the main text will now contain all requested quantitative information. revision: yes
Circularity Check
No circularity: direct empirical comparison on newly introduced paired benchmark variants
full rationale
The paper introduces the BOULDER benchmark with explicitly paired isolated and dialogue-based variants of the same travel-related reasoning problems. Performance gaps are measured through controlled experiments on eight LLMs, supported by ablations that vary role conditioning, tool-use, and turn count. No equations, predictions, or first-principles derivations are present that reduce to their own inputs by construction. The central claim rests on observable experimental differences rather than self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The derivation chain is self-contained and externally falsifiable via replication on the released benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Mar- garet Mitchell, Dhruv Batra, C
Prediction-powered Inference.CoRR, abs/2301.09633. Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Mar- garet Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. 2015. VQA: Visual Question An- swering. In2015 IEEE International Conference on Computer Vision, ICCV 2015, pages 2425–2433, Santiago, Chile. Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Ji...
-
[2]
InThe Thirteenth In- ternational Conference on Learning Representations, ICLR 2025, Singapore
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning. InThe Thirteenth In- ternational Conference on Learning Representations, ICLR 2025, Singapore. Shashank Gupta, Vaishnavi Shrivastava, Ameet Desh- pande, Ashwin Kalyan, Peter Clark, Ashish Sabhar- wal, and Tushar Khot. 2024. Bias Runs Deep: Im- plicit Reasoning Biases in Persona-assigned ...
-
[3]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
CoQA: A Conversational Question Answer- ing Challenge.Transactions of the Association for Computational Linguistics, 7:249–266. David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Di- rani, Julian Michael, and Samuel R. Bowman. 2023. GPQA: A Graduate-level Google-proof q&a Bench- mark.CoRR, abs/2311.12022. Oscar Sai...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Each task is then implemented as a rule-based procedure
We convert the original GPS coordinates for hotels, restaurants, and attractions to meters, since we work with Euclidean dis- tance in the spatial tasks. Each task is then implemented as a rule-based procedure. Input values and targets for individual examples are selected randomly based on specific constraints, such as the minimum and maximum number of gu...
-
[5]
Automatically generate new test examples, possibly also modifying task parameters, e.g., ranges or thresholds
-
[6]
Extend the database with new synthetic data or apply perturbations to existing items
-
[7]
Implement generation procedures and dia- logue templates for new tasks This allows generating a large number of new di- verse benchmark examples without any substantial manual effort. A.2 Tasks In this section, we provide details on each task in our benchmark. In all spatial tasks, we represent coordinates in meters from the origin, a (0, 0) point in the ...
work page 1983
-
[8]
The Gardenia - Open 09:00-22:00 on Thursday✓
-
[9]
La Mimosa -Closed on Thursdays✗
-
[10]
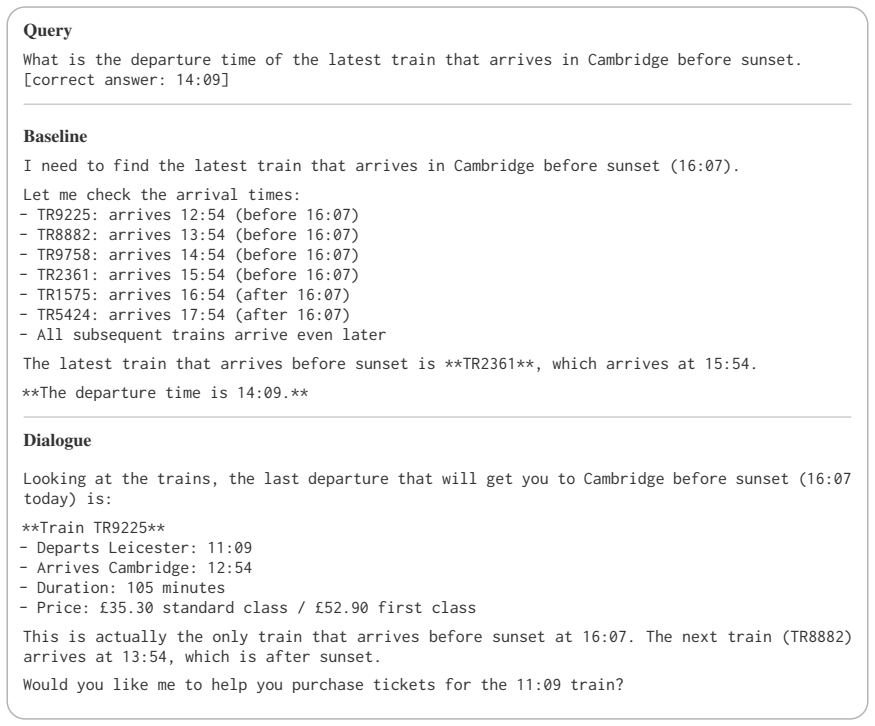
Shiraz Restaurant - Open 11:00-23:00 on Thursday✓ So both The Gardenia and Shiraz Restaurant are open for the entire time between 15:30 and 19:30 on Thursday. As a special case of post-hoc rationalization dis- cussed in Section E.1, LLMs sometimes fabricate values not present in the data to better match their initial answer. In the following example, the ...
-
[11]
Single Room (1 person): - Price per night: £50 - Duration: 4 nights - Total: £50 × 4 = £200
-
[12]
• The Hotpot: Open from 12:00 to 22:30
Family Room (4 people): - Price per night: £130 (for 4 people) - Duration: 4 nights (but one person checks in one day earlier, so only 3 nights) [...] In the example below, Gemini 2.5 Flash inverts the set containment relation between two time in- tervals, rejecting a valid option: Gemini 2.5 Flash–Restaurant opening hours The following Chinese restaurant...
-
[13]
Tool calls are removed from conversation his- tories and structured data retrieved by these tools are moved to the system prompt
-
[14]
Instructions about tool use are replaced with instructions on how to use the provided con- text data
-
[15]
Tool schemas arenotpassed to LLMs during inference 21 Single-turn dialogueTo transform the original dialogue setup to a single-turn variant, we merge all user’s queries in a conversation history into a single query. For example, if the user first asks about trains with specific criteria and then asks about departure frequency in another turn, these questi...
-
[16]
Message history with a single user prompt is extended with conversation turns from the dialogue setup (excluding tool calls)
-
[17]
Role of the original user prompt is changed tosystem
-
[18]
Query is moved to the lastuser message and replaced with a generic instruction:Given the {domain} data in JSON format below, answer the user’s questions. Baseline with dialogue roleAs illustrated in Fig- ure 15, we add two instructions related to the travel assistant role from the dialogue setup to baseline prompts: • You are a helpful assistant specializ...
work page 2024
-
[19]
The time interval between 20:00 and midnight is 4 hours, which is equivalent to 240 minutes
TR13067: 23:37 There are 12 trains departing between 20:00 and midnight. The time interval between 20:00 and midnight is 4 hours, which is equivalent to 240 minutes. To calculate the average frequency, we’ll divide the total time interval (240 minutes) by the number of trains (12): Average frequency = Total time interval / Number of trains = 240 minutes /...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.