Recognition: 2 theorem links
· Lean TheoremPretrained Video Models as Differentiable Physics Simulators for Urban Wind Flows
Pith reviewed 2026-05-15 06:57 UTC · model grok-4.3
The pith
A repurposed video diffusion model acts as a fast differentiable surrogate for urban wind flow simulations and enables direct gradient-based optimization of building positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
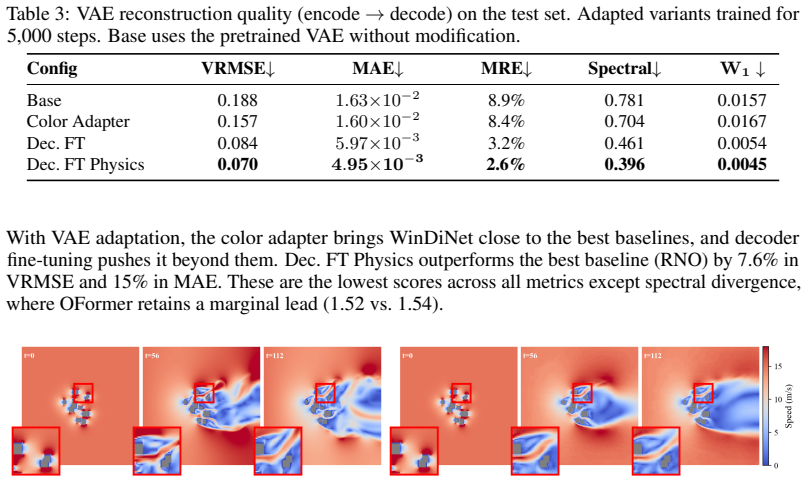
Starting from the LTX-Video latent video transformer, fine-tuning on 10,000 procedurally generated 2D incompressible CFD cases with a physics-informed decoder loss yields WinDiNet, which produces 112-frame wind rollouts in under a second and supports end-to-end differentiable inverse optimization of urban footprints for improved wind metrics, with all discovered improvements confirmed by ground-truth CFD.
What carries the argument
WinDiNet, the fine-tuned latent video diffusion model that serves as an end-to-end differentiable surrogate for time-resolved 2D incompressible CFD wind simulations around building layouts.
If this is right
- Full 112-frame wind flow predictions become available in under one second instead of hours of traditional computation.
- Building positions can be adjusted via backpropagation to satisfy multiple wind comfort objectives simultaneously.
- The surrogate outperforms purpose-built neural PDE solvers on the tested 2D incompressible cases.
- Effective layouts are discovered for both single-inlet and multi-inlet urban configurations.
Where Pith is reading between the lines
- The same fine-tuning strategy may transfer to other time-dependent physics problems that admit video-like representations.
- If systematic biases remain small, the method could be extended to 3D flows or coupled with real sensor data for calibration.
- Embedding the surrogate in interactive design software would allow rapid iteration over thousands of candidate urban layouts.
Load-bearing premise
Fine-tuning a general video model on procedurally generated 2D cases yields predictions accurate enough for gradient-based layout optimization without introducing biases that invalidate the discovered optima on real urban scenes.
What would settle it
An optimized layout produced by the surrogate that, when re-evaluated with full CFD, shows worse wind safety or comfort metrics than the starting layout.
Figures



















read the original abstract
Designing urban spaces that provide pedestrian wind comfort and safety requires time-resolved Computational Fluid Dynamics (CFD) simulations, but their current computational cost makes extensive design exploration impractical. We introduce WinDiNet (Wind Diffusion Network), a pretrained video diffusion model that is repurposed as a fast, differentiable surrogate for this task. Starting from LTX-Video, a 2B-parameter latent video transformer, we fine-tune on 10,000 2D incompressible CFD simulations over procedurally generated building layouts. A systematic study of training regimes, conditioning mechanisms, and VAE adaptation strategies, including a physics-informed decoder loss, identifies a configuration that outperforms purpose-built neural PDE solvers. The resulting model generates full 112-frame rollouts in under a second. As the surrogate is end-to-end differentiable, it doubles as a physics simulator for gradient-based inverse optimization: given an urban footprint layout, we optimize building positions directly through backpropagation to improve wind safety as well as pedestrian wind comfort. Experiments on single- and multi-inlet layouts show that the optimizer discovers effective layouts even under challenging multi-objective configurations, with all improvements confirmed by ground-truth CFD simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WinDiNet, a fine-tuned 2B-parameter latent video diffusion model (based on LTX-Video) repurposed as a differentiable surrogate for 2D incompressible CFD simulations of urban wind flows. Fine-tuned on 10,000 procedurally generated building layouts, the model produces full 112-frame rollouts in under one second and is applied to gradient-based inverse optimization of building positions to improve wind safety and pedestrian comfort, with discovered optima validated by ground-truth CFD.
Significance. If the surrogate's accuracy and gradient fidelity hold on real urban layouts, the work would provide a practical route to rapid, end-to-end differentiable physics simulation for urban design, enabling extensive inverse optimization that remains computationally prohibitive with conventional CFD. The demonstration that a pretrained video model can be adapted into a physics surrogate with physics-informed losses is a notable contribution to scientific machine learning.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the claim that the model 'outperforms purpose-built neural PDE solvers' is unsupported by any reported quantitative error metrics (e.g., velocity-field RMSE, divergence error, or rollout accuracy over 112 frames) or ablation tables comparing training regimes, conditioning mechanisms, and the physics-informed decoder loss. Without these numbers the superiority assertion and the suitability for gradient-based optimization cannot be evaluated.
- [Methods / Data generation] Training data and generalization discussion: the 10,000 procedurally generated 2D layouts are described only at a high level; no statistics on shape diversity, aspect-ratio distribution, inlet variability, or boundary-layer fidelity are supplied. This leaves open the possibility that the learned dynamics contain systematic biases that would distort the loss landscape during building-position optimization, exactly as flagged by the skeptic note.
- [Optimization results] Optimization experiments: while the abstract states that 'all improvements [are] confirmed by ground-truth CFD,' neither the number of optimized layouts, the magnitude of the reported wind-speed or comfort gains, nor any comparison against baseline layouts or random search is quantified. Post-hoc verification on a small undisclosed set does not establish that the discovered optima are robust to surrogate artifacts.
minor comments (2)
- [Introduction] The acronym WinDiNet is introduced without an explicit expansion or architectural diagram in the early sections; a single figure showing the conditioning and VAE adaptation pipeline would improve readability.
- [Results] Clarify whether the 112-frame rollout length is fixed by the video model architecture or chosen for the CFD task, and report wall-clock times on the specific hardware used for both inference and back-propagation.
Simulated Author's Rebuttal
We thank the referee for their insightful and constructive comments on our manuscript. We are pleased that the referee recognizes the potential of WinDiNet as a practical approach for differentiable physics simulation in urban design. We address each of the major comments below and will incorporate the suggested revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the claim that the model 'outperforms purpose-built neural PDE solvers' is unsupported by any reported quantitative error metrics (e.g., velocity-field RMSE, divergence error, or rollout accuracy over 112 frames) or ablation tables comparing training regimes, conditioning mechanisms, and the physics-informed decoder loss. Without these numbers the superiority assertion and the suitability for gradient-based optimization cannot be evaluated.
Authors: We fully agree that explicit quantitative metrics are necessary to support the claim of outperforming purpose-built neural PDE solvers and to confirm suitability for gradient-based optimization. In the revised manuscript, we will add detailed quantitative comparisons in the Experiments section, including velocity-field RMSE, divergence error, and rollout accuracy over 112 frames. Additionally, we will include ablation tables that compare different training regimes, conditioning mechanisms, and the impact of the physics-informed decoder loss. These metrics will demonstrate the performance gains and provide the necessary evidence for the assertions made. revision: yes
-
Referee: [Methods / Data generation] Training data and generalization discussion: the 10,000 procedurally generated 2D layouts are described only at a high level; no statistics on shape diversity, aspect-ratio distribution, inlet variability, or boundary-layer fidelity are supplied. This leaves open the possibility that the learned dynamics contain systematic biases that would distort the loss landscape during building-position optimization, exactly as flagged by the skeptic note.
Authors: We acknowledge the importance of providing more detailed dataset statistics to allow assessment of potential biases. In the revised Methods section, we will include comprehensive statistics on the procedural generation process, such as distributions of building shapes and sizes, aspect ratios, inlet flow variability, and boundary layer characteristics. This additional information will help evaluate the diversity of the training data and the robustness of the learned surrogate for optimization purposes. revision: yes
-
Referee: [Optimization results] Optimization experiments: while the abstract states that 'all improvements [are] confirmed by ground-truth CFD,' neither the number of optimized layouts, the magnitude of the reported wind-speed or comfort gains, nor any comparison against baseline layouts or random search is quantified. Post-hoc verification on a small undisclosed set does not establish that the discovered optima are robust to surrogate artifacts.
Authors: We agree that more quantitative details on the optimization experiments are required to demonstrate the robustness of the results. In the revised manuscript, we will specify the number of layouts optimized, quantify the improvements in wind-speed and comfort metrics, and provide comparisons to baseline configurations and random search. We will also clarify the extent of the ground-truth CFD validation, ensuring that the verification covers a representative set of cases to confirm that the optima are not artifacts of the surrogate. revision: yes
Circularity Check
No significant circularity; derivation relies on external CFD data and independent verification
full rationale
The paper's core chain—pretraining on LTX-Video, fine-tuning on 10,000 external procedurally generated 2D CFD cases, producing differentiable rollouts, and performing gradient-based optimization with post-hoc ground-truth CFD confirmation—does not reduce any prediction or claim to its inputs by construction. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The optimization results are explicitly validated outside the surrogate, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- fine-tuning hyperparameters and conditioning mechanisms
axioms (1)
- domain assumption A 2D incompressible CFD simulation on procedurally generated building layouts is a sufficient proxy for real 3D urban wind flows.
invented entities (1)
-
WinDiNet
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce WinDiNet... fine-tune on 10,000 2D incompressible CFD simulations... physics-informed decoder loss... gradient-based inverse optimization of building positions
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dec. FT Physics... divergence penalty enforcing incompressibility (∇·w=0)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Eurocode 1: Actions on structures – part 1-4: General actions – wind actions
CEN. Eurocode 1: Actions on structures – part 1-4: General actions – wind actions. Standard, 2010
work page 2010
-
[3]
Cheng Chen, Geng Tian, Shaoxiang Qin, Senwen Yang, Dingyang Geng, Dongxue Zhan, Jinqiu Yang, David Vidal, and Liangzhu Leon Wang. Generalization of urban wind environ- ment using fourier neural operator across different wind directions and cities.arXiv preprint arXiv:2501.05499, 2025
-
[4]
Wind microclimate guidelines for developments in the city of london
City of London Corporation. Wind microclimate guidelines for developments in the city of london. https://www.cityoflondon.gov.uk/assets/Services-Environment/ wind-microclimate-guidelines.pdf, 2019
work page 2019
-
[5]
Adam Clarke, Knut Erik Teigen Giljarhus, Luca Oggiano, Alistair Saddington, and Karthik Depuru-Mohan. Deep learning for urban wind prediction: An mlp-mixer approach with 3d encoding.Building and Environment, page 113495, 2025
work page 2025
-
[6]
Alfredo Vicente Clemente, Knut Erik Teigen Giljarhus, Luca Oggiano, and Massimiliano Ruocco. Rapid pedestrian-level wind field prediction for early-stage design using pareto- optimized convolutional neural networks.Computer-Aided Civil and Infrastructure Engineering, 39(18):2826–2839, 2024
work page 2024
-
[7]
Pan Du, Meet Hemant Parikh, Xiantao Fan, Xin-Yang Liu, and Jian-Xun Wang. Conditional neural field latent diffusion model for generating spatiotemporal turbulence.Nature Communi- cations, 15(1):10416, 2024
work page 2024
-
[8]
Spencer Folk, John Melton, Benjamin W. L. Margolis, Mark Yim, and Vijay Kumar. Learning local urban wind flow fields from range sensing.IEEE Robotics and Automation Letters, 9(9): 7413–7420, 2024. doi: 10.1109/LRA.2024.3426209
-
[9]
Nate Gillman, Charles Herrmann, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun. Force prompting: Video generation models can learn and generalize physics-based control signals.arXiv preprint arXiv:2505.19386, 2025
-
[10]
Generative urban flow modeling: From geometry to airflow with graph diffusion
Francisco Giral, Álvaro Manzano, Ignacio Gómez, Petros Koumoutsakos, and Soledad Le Clainche. Generative urban flow modeling: From geometry to airflow with graph diffusion. arXiv preprint arXiv:2512.14725, 2025
-
[11]
Efficient token mixing for transformers via adaptive fourier neural operators
John Guibas, Morteza Mardani, Zongyi Li, Andrew Tao, Anima Anandkumar, and Bryan Catanzaro. Efficient token mixing for transformers via adaptive fourier neural operators. In International conference on learning representations, 2021
work page 2021
-
[12]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richard- son, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Poseidon: Efficient foundation models for pdes
Maximilian Herde, Bogdan Raoni ´c, Tobias Rohner, Roger Käppeli, Roberto Molinaro, Em- manuel De Bezenac, and Siddhartha Mishra. Poseidon: Efficient foundation models for pdes. Advances in Neural Information Processing Systems, 37:72525–72624, 2024
work page 2024
-
[14]
Video diffusion models.Advances in neural information processing systems, 35: 8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35: 8633–8646, 2022
work page 2022
-
[15]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 12
work page 2022
-
[16]
Chenyu Huang, Gengjia Zhang, Jiawei Yao, Xiaoxin Wang, John Kaiser Calautit, Cairong Zhao, Na An, and Xi Peng. Accelerated environmental performance-driven urban design with generative adversarial network.Building and Environment, 224:109575, 2022
work page 2022
-
[17]
The ground level wind environment in built-up areas
N Isyumov. The ground level wind environment in built-up areas. Inproc. of 4ˆ< th> Int. Conf. on Wind Effects on Buildings and Structures, London, 1975, 1975
work page 1975
-
[18]
Zeynab Kaseb and Morteza Rahbar. Towards cfd-based optimization of urban wind condi- tions: Comparison of genetic algorithm, particle swarm optimization, and a hybrid algorithm. Sustainable Cities and Society, 77:103565, 2022
work page 2022
-
[19]
Patrick Kastner and Timur Dogan. A gan-based surrogate model for instantaneous urban wind flow prediction.Building and Environment, 242:110384, 2023
work page 2023
-
[20]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
T. V . Lawson. The wind content of the built environment.Journal of Wind Engineering and Industrial Aerodynamics, 3(2–3):93–105, 1978
work page 1978
-
[22]
High resolution large-eddy simulation of turbulent flow around buildings, 2007
Marcus Oliver Letzel. High resolution large-eddy simulation of turbulent flow around buildings, 2007
work page 2007
-
[23]
Edward Li, Zichen Wang, Jiahe Huang, and Jeong Joon Park. Videopde: Unified generative pde solving via video inpainting diffusion models.arXiv preprint arXiv:2506.13754, 2025
-
[24]
Zijie Li, Kazem Meidani, and Amir Barati Farimani. Transformer for partial differential equations’ operator learning.arXiv preprint arXiv:2205.13671, 2022
-
[25]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations.arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[26]
Soft rasterizer: A differentiable renderer for image-based 3d reasoning
Shichen Liu, Tianye Li, Weikai Chen, and Hao Li. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 7708–7717, 2019
work page 2019
-
[27]
Zhijian Liu, Siqi Zhang, Xuqiang Shao, and Zhaohui Wu. Accurate and efficient urban wind prediction at city-scale with memory-scalable graph neural network.Sustainable Cities and Society, 2023
work page 2023
-
[28]
Miguel Liu-Schiaffini, Clare E Singer, Nikola Kovachki, Tapio Schneider, Kamyar Azizzade- nesheli, and Anima Anandkumar. Tipping point forecasting in non-stationary dynamics on function spaces.arXiv preprint arXiv:2308.08794, 2023
-
[29]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Machine learning predicts pedestrian wind flow from urban morphology and prevailing wind direction
Jiachen Lu, Wei Li, Sanaa Hobeichi, Shakir Aymam Azad, and Negin Nazarian. Machine learning predicts pedestrian wind flow from urban morphology and prevailing wind direction. Environmental Research Letters, 20(5):054006, 2025
work page 2025
-
[31]
Parham A Mirzaei. Cfd modeling of micro and urban climates: Problems to be solved in the new decade.Sustainable Cities and Society, 69:102839, 2021
work page 2021
-
[32]
Pedestrian wind factor estimation in complex urban environments
Sarah Mokhtar, Matt Beveridge, Yumeng Cao, and Iddo Drori. Pedestrian wind factor estimation in complex urban environments. InAsian conference on machine learning, pages 486–501. PMLR, 2021
work page 2021
-
[33]
Roberto Molinaro, Samuel Lanthaler, Bogdan Raoni ´c, Tobias Rohner, Victor Armegioiu, Stephan Simonis, Dana Grund, Yannick Ramic, Zhong Yi Wan, Fei Sha, et al. Generative ai for fast and accurate statistical computation of fluids.arXiv preprint arXiv:2409.18359, 2024
-
[34]
Physix: A foundation model for physics simulations.arXiv preprint arXiv:2506.17774, 2025
Tung Nguyen, Arsh Koneru, Shufan Li, and Aditya Grover. Physix: A foundation model for physics simulations.arXiv preprint arXiv:2506.17774, 2025. 13
-
[35]
Siddarth Nilol Kundur Satish, Devesh Jaiswal, Hongyu Chen, and Abhishek Bakshi. PhysVideo- Generator: Towards Physically Aware Video Generation via Latent Physics Guidance.arXiv e-prints, art. arXiv:2601.03665, January 2026. doi: 10.48550/arXiv.2601.03665
-
[36]
NVIDIA PhysicsNeMo: An open-source framework for physics-ML model building and training, 2025
NVIDIA Corporation. NVIDIA PhysicsNeMo: An open-source framework for physics-ML model building and training, 2025. URLhttps://github.com/NVIDIA/physicsnemo
work page 2025
-
[37]
Ruben Ohana, Michael McCabe, Lucas Meyer, Rudy Morel, Fruzsina J Agocs, Miguel Beneitez, Marsha Berger, Blakesley Burkhart, Stuart B Dalziel, Drummond B Fielding, et al. The well: a large-scale collection of diverse physics simulations for machine learning.Advances in Neural Information Processing Systems, 37:44989–45037, 2024
work page 2024
-
[38]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[39]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[40]
Shaoxiang Qin, Dongxue Zhan, Dingyang Geng, Wenhui Peng, Geng Tian, Yurong Shi, Naiping Gao, Xue Liu, and Liangzhu Leon Wang. Modeling multivariable high-resolution 3d urban microclimate using localized fourier neural operator.Building and Environment, 273:112668, 2025
work page 2025
-
[41]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
work page 2015
-
[42]
En-Ze Rui, Zheng-Wei Chen, Yi-Qing Ni, Lei Yuan, and Guang-Zhi Zeng. Reconstruction of 3d flow field around a building model in wind tunnel: a novel physics-informed neural network framework adopting dynamic prioritization self-adaptive loss balance strategy.Engineering Applications of Computational Fluid Mechanics, 17(1):2238849, 2023
work page 2023
-
[43]
Temporal generative adversarial nets with singular value clipping
Masaki Saito, Eiichi Matsumoto, and Shunta Saito. Temporal generative adversarial nets with singular value clipping. InProceedings of the IEEE international conference on computer vision, pages 2830–2839, 2017
work page 2017
-
[44]
Xuqiang Shao, Zhijian Liu, Siqi Zhang, Zijia Zhao, and Chenxing Hu. Pignn-cfd: A physics- informed graph neural network for rapid predicting urban wind field defined on unstructured mesh.Building and Environment, 232:110056, 2023
work page 2023
-
[45]
Pedestrian wind comfort analysis – online documentation
SimScale GmbH. Pedestrian wind comfort analysis – online documentation. https://www. simscale.com/docs/analysis-types/pedestrian-wind-comfort-analysis/, 2025
work page 2025
-
[46]
Reda Snaiki, Jiachen Lu, Shaopeng Li, and Negin Nazarian. A hierarchical deep learning model for predicting pedestrian-level urban winds.Building and Environment, page 114354, 2026
work page 2026
-
[47]
Towards a foundation model for partial differential equations across physics domains
Eduardo Soares, Emilio Vital Brazil, Victor Shirasuna, Breno WSR de Carvalho, and Cristiano Malossi. Towards a foundation model for partial differential equations across physics domains. arXiv preprint arXiv:2511.21861, 2025
-
[48]
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Daniel MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. Pdebench: An extensive benchmark for scientific machine learning.Advances in neural information processing systems, 35:1596–1611, 2022
work page 2022
-
[49]
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains.Advances in neural information processing systems, 33:7537–7547, 2020
work page 2020
-
[50]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Mocogan: Decomposing motion and content for video generation
Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. Mocogan: Decomposing motion and content for video generation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1526–1535, 2018
work page 2018
-
[52]
Diffusion models are real-time game engines.arXiv preprint arXiv:2408.14837, 2024
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines.arXiv preprint arXiv:2408.14837, 2024
-
[53]
Generating videos with scene dynamics
Carl V ondrick, Hamed Pirsiavash, and Antonio Torralba. Generating videos with scene dynamics. Advances in neural information processing systems, 29, 2016
work page 2016
-
[54]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Chen Wang, Chuhao Chen, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu. Physctrl: Generative physics for controllable and physics-grounded video generation.arXiv preprint arXiv:2509.20358, 2025
-
[56]
Video models are zero-shot learners and reasoners
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
InThe Thirteenth International Conference on Learning Representations(2025)
Florian Wiesner, Matthias Wessling, and Stephen Baek. Towards a physics foundation model. arXiv preprint arXiv:2509.13805, 2025
-
[58]
Yihan Wu and Steven Jige Quan. A review of surrogate-assisted design optimization for improving urban wind environment.Building and Environment, 253:111157, 2024
work page 2024
-
[59]
Ke Zhang, Cihan Xiao, Jiacong Xu, Yiqun Mei, and Vishal M Patel. Think before you diffuse: Infusing physical rules into video diffusion.arXiv preprint arXiv:2505.21653, 2025. 15 A Dataset Details A.1 Incompressible CFD Setup We model the atmospheric boundary-layer flow as an incompressible fluid, which is appropriate for typical urban wind speeds where Ma...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.