Recognition: 2 theorem links
· Lean TheoremCLEAR: Context-Aware Learning with End-to-End Mask-Free Inference for Adaptive Video Subtitle Removal
Pith reviewed 2026-05-15 00:36 UTC · model grok-4.3
The pith
CLEAR removes video subtitles end-to-end without any masks by learning disentangled representations in one stage and refining them with generation feedback in the next.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CLEAR achieves mask-free subtitle removal by decoupling prior extraction from generative refinement: Stage I trains dual encoders under self-supervised orthogonality constraints to produce disentangled subtitle representations, while Stage II applies LoRA adaptation guided by generation feedback to adjust context dynamically without ground-truth masks.
What carries the argument
Two-stage architecture that uses self-supervised orthogonality constraints on dual encoders to disentangle subtitle representations and LoRA-based adaptation with generation feedback for dynamic context adjustment.
If this is right
- On Chinese subtitle benchmarks the method records +6.77 dB PSNR and -74.7 percent VFID relative to mask-dependent baselines.
- Zero-shot removal works across English, Korean, French, Japanese, Russian and German without retraining.
- Training requires only 0.77 percent of the base diffusion model's parameters.
- Inference proceeds without supplying ground-truth masks at any stage.
Where Pith is reading between the lines
- The same feedback-driven adaptation could apply to other overlay-removal tasks such as logo or watermark erasure.
- Reducing trainable parameters to under one percent opens the possibility of fine-tuning on modest hardware for domain-specific subtitles.
- The disentanglement step may transfer to separating other transient elements like captions or annotations in video streams.
Load-bearing premise
Self-supervised orthogonality constraints on dual encoders can produce subtitle representations disentangled enough to support reliable removal without any masks at inference time.
What would settle it
A set of test videos containing subtitles where the method leaves visible text artifacts or distorts background content that a mask-guided baseline removes cleanly.
Figures





read the original abstract
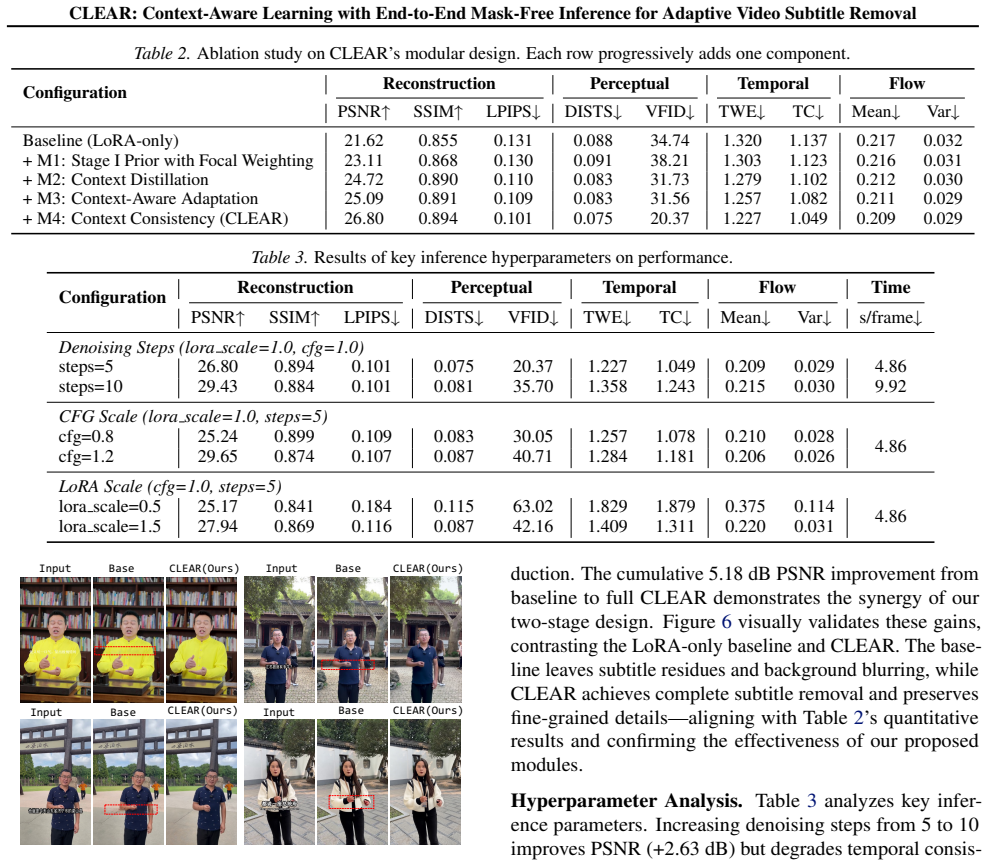
Video subtitle removal aims to distinguish text overlays from background content while preserving temporal coherence. Existing diffusion-based methods necessitate explicit mask sequences during both training and inference phases, which restricts their practical deployment. In this paper, we present CLEAR (Context-aware Learning for End-to-end Adaptive Video Subtitle Removal), a mask-free framework that achieves truly end-to-end inference through context-aware adaptive learning. Our two-stage design decouples prior extraction from generative refinement: Stage I learns disentangled subtitle representations via self-supervised orthogonality constraints on dual encoders, while Stage II employs LoRA-based adaptation with generation feedback for dynamic context adjustment. Notably, our method only requires 0.77% of the parameters of the base diffusion model for training. On Chinese subtitle benchmarks, CLEAR outperforms mask-dependent baselines by + 6.77dB PSNR and -74.7% VFID, while demonstrating superior zero-shot generalization across six languages (English, Korean, French, Japanese, Russian, German), a performance enabled by our generation-driven feedback mechanism that ensures robust subtitle removal without ground-truth masks during inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLEAR, a mask-free framework for adaptive video subtitle removal using a two-stage design. Stage I learns disentangled subtitle representations through self-supervised orthogonality constraints on dual encoders. Stage II uses LoRA-based adaptation with generation feedback for dynamic context adjustment. It reports outperforming mask-dependent baselines by +6.77dB PSNR and -74.7% VFID on Chinese benchmarks and superior zero-shot generalization to six languages, while training only 0.77% of the base model's parameters.
Significance. Should the central claims hold, this would represent a meaningful advance in video editing by enabling truly end-to-end inference without masks, addressing a practical limitation in diffusion-based approaches. The low parameter overhead and cross-lingual performance are strengths that could broaden applicability in real-world scenarios.
major comments (2)
- [Stage I] Stage I, orthogonality constraints: The self-supervised orthogonality constraints on dual encoders are claimed to produce disentangled subtitle representations sufficient for mask-free inference. However, orthogonality enforces linear independence in feature space but does not guarantee semantic separation when subtitle pixels share low-level statistics with background content (e.g., edges or hues). This assumption is load-bearing for the +6.77 dB PSNR claim and zero-shot cross-language results; targeted ablations or feature visualizations are needed to validate it.
- [Results] Experimental results: The reported gains (+6.77 dB PSNR, -74.7% VFID) and zero-shot generalization across six languages depend on the disentanglement holding outside the Chinese training distribution, but the manuscript provides limited detail on how the generation feedback mechanism prevents leakage from residual subtitle features into the refined output.
minor comments (1)
- [Abstract] Abstract: A brief note on the specific Chinese subtitle datasets used would help contextualize the quantitative benchmarks immediately.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our method's assumptions and mechanisms. We address each major point below and will incorporate targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Stage I] Stage I, orthogonality constraints: The self-supervised orthogonality constraints on dual encoders are claimed to produce disentangled subtitle representations sufficient for mask-free inference. However, orthogonality enforces linear independence in feature space but does not guarantee semantic separation when subtitle pixels share low-level statistics with background content (e.g., edges or hues). This assumption is load-bearing for the +6.77 dB PSNR claim and zero-shot cross-language results; targeted ablations or feature visualizations are needed to validate it.
Authors: We agree that linear independence via orthogonality does not automatically ensure semantic disentanglement when low-level features overlap. While our empirical results (including cross-lingual zero-shot performance) indicate effective separation in practice, we will add targeted ablations and visualizations in the revised manuscript. These will include t-SNE projections of dual-encoder features before/after the orthogonality loss, quantitative metrics such as mutual information between subtitle and background subspaces, and controlled experiments on synthetic edge/hue-overlap cases. This will directly validate the assumption's contribution to the reported gains. revision: yes
-
Referee: [Results] Experimental results: The reported gains (+6.77 dB PSNR, -74.7% VFID) and zero-shot generalization across six languages depend on the disentanglement holding outside the Chinese training distribution, but the manuscript provides limited detail on how the generation feedback mechanism prevents leakage from residual subtitle features into the refined output.
Authors: We acknowledge the need for greater detail on leakage prevention. In the revision we will expand Section 3.2 with an explicit description of the generation feedback loop, including the iterative loss formulation that penalizes residual subtitle signals detected via the Stage-I encoder on the refined output. We will also add analysis (e.g., feature-norm comparisons and qualitative residual maps) demonstrating reduced leakage across the six languages, showing how the LoRA adaptation dynamically suppresses subtitle remnants without requiring masks at inference. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents a two-stage framework relying on newly introduced self-supervised orthogonality constraints for disentangled subtitle representations in Stage I and LoRA-based adaptation with generation feedback in Stage II. These mechanisms are defined as architectural and training innovations without any equations or claims reducing the outputs to fitted parameters by construction, self-citations that bear the central load, or uniqueness theorems imported from prior author work. Performance claims rest on empirical benchmark comparisons rather than tautological re-derivations of inputs, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Stage I learns disentangled subtitle representations via self-supervised orthogonality constraints on dual encoders... L_ortho = 1/(T·H'·W') Σ <F_sub, F_content>²
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LoRA-based adaptation with generation feedback for dynamic context adjustment... only 0.77% of the parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y ., English, Z., V oleti, V ., Letts, A., et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al. Hunyuan- video: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2501.10018 (2025) 4, 10, 3
Li, X., Xue, H., Ren, P., and Bo, L. Diffueraser: A diffusion model for video inpainting.arXiv preprint arXiv:2501.10018,
-
[4]
Understanding attention mechanism in video dif- fusion models.arXiv preprint arXiv:2504.12027,
Liu, B., Wang, C., Su, T., Ten, H., Huang, J., Guo, K., and Jia, K. Understanding attention mechanism in video dif- fusion models.arXiv preprint arXiv:2504.12027,
-
[5]
Liu, J. and Hui, Z. Eraserdit: Fast video inpaint- ing with diffusion transformer model.arXiv preprint arXiv:2506.12853,
-
[6]
Decoupled Weight Decay Regularization
URL https://arxiv.org/abs/ 1711.05101. Mao, F., Hao, A., Chen, J., Liu, D., Feng, X., Zhu, J., Wu, M., Chen, C., Wu, J., and Chu, X. Omni-effects: Unified and spatially-controllable visual effects generation.arXiv preprint arXiv:2508.07981,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Diffstr: Controlled diffusion models for scene text removal.arXiv preprint arXiv:2410.21721,
Pathak, S., Kaushik, V ., and Lall, B. Diffstr: Controlled diffusion models for scene text removal.arXiv preprint arXiv:2410.21721,
-
[8]
Vip: Video inpainting pipeline for real world human removal.arXiv preprint arXiv:2504.03041,
Sun, H., Li, Y ., Yang, K., Li, R., Xing, D., Xie, Y ., Fu, L., Zhang, K., Chen, M., Ding, J., et al. Vip: Video inpainting pipeline for real world human removal.arXiv preprint arXiv:2504.03041,
-
[9]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., and Gelly, S. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Wan: Open and Advanced Large-Scale Video Generative Models
9 CLEAR: Context-Aware Learning with End-to-End Mask-Free Inference for Adaptive Video Subtitle Removal Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2503.11412 (2025) 4
Yang, S., Gu, Z., Hou, L., Tao, X., Wan, P., Chen, X., and Liao, J. Mtv-inpaint: Multi-task long video inpainting. arXiv preprint arXiv:2503.11412,
-
[12]
Minimax-remover: Taming bad noise helps video object removal,
Zi, B., Peng, W., Qi, X., Wang, J., Zhao, S., Xiao, R., and Wong, K.-F. Minimax-remover: Taming bad noise helps video object removal.arXiv preprint arXiv:2505.24873,
-
[13]
11 CLEAR: Context-Aware Learning with End-to-End Mask-Free Inference for Adaptive Video Subtitle Removal We introduce a context-dependent occlusion head H with only 2.1M parameters attached to the diffusion transformer’s middle encoder layer. The head consists of two convolutional layers: H(henc) =Conv 1 1×1(SiLU(Conv64 3×3(henc))), where henc represents ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.