Recognition: no theorem link
Dynamic analysis enhances issue resolution
Pith reviewed 2026-05-15 00:43 UTC · model grok-4.3
The pith
Dynamic analysis embedded in LLM agents resolves 79.4% of code issues
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
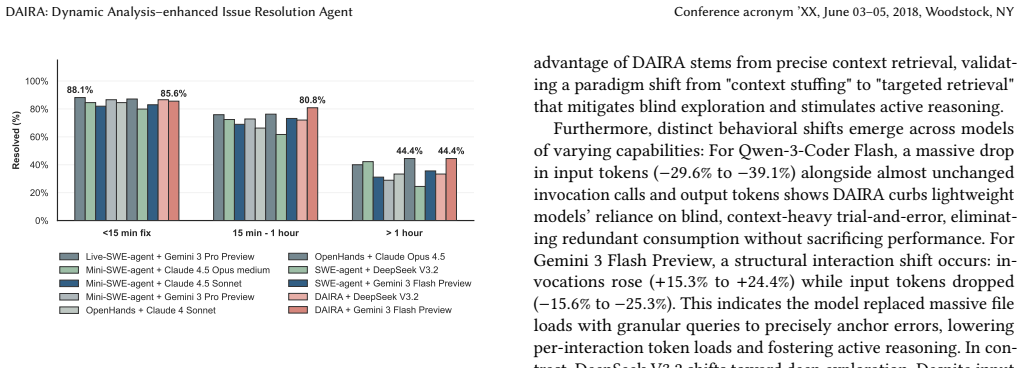
DAIRA is an automated repair framework that deeply embeds dynamic analysis into the agent's decision loop via a Test Tracing-Driven workflow. It uses lightweight tools to capture runtime evidence including call stacks and variable states, then converts this into structured semantic reports. These reports illuminate execution paths and causal dependencies, shifting the agent from speculative reasoning to precise, deterministic inference while avoiding irrelevant code retrievals that flood the context window.
What carries the argument
The Test Tracing-Driven workflow that employs lightweight dynamic analysis tools to capture runtime evidence and convert it into structured semantic reports for guiding the LLM agent's repair process.
If this is right
- Precise fault localization becomes possible even in intricate polymorphic control flows and implicit type issues.
- Resolution rate reaches 79.4% on SWE-bench Verified and 44.4% on the most demanding tasks.
- Unique resolution of complex edge cases that static-analysis baselines cannot handle.
- Inference costs reduce by approximately 10% and input token consumption by 25% across different LLMs.
Where Pith is reading between the lines
- Similar dynamic tracing could be applied to other LLM agent tasks involving stateful reasoning beyond code repair.
- Lightweight tools open the door to integrating this approach into interactive development environments for real-time assistance.
- The shift to runtime evidence might generalize to reduce token waste in long-horizon agent interactions.
- Future work could explore combining this with static methods for even broader coverage of defect types.
Load-bearing premise
Lightweight dynamic analysis tools can reliably capture and convert runtime evidence into structured reports that enable precise fault localization without introducing overhead or misleading the LLM agent in complex control flows.
What would settle it
A direct comparison on SWE-bench Verified where DAIRA fails to exceed baseline resolution rates on tasks involving deep logical defects would disprove the advantage of embedding dynamic analysis.
Figures







read the original abstract
Resolving complex code defects from natural language descriptions remains a fundamental software engineering challenge. Recently, large language models (LLMs) have driven the creation of agent-based automated repair systems. While improving repository-level problem-solving, current methods struggle with complex defects like intricate polymorphic control flows and implicit type degradation. These approaches rely on static analysis and shallow execution feedback, lacking the ability to monitor intermediate execution states. Consequently, agents often fall into speculative exploration, consuming significant tokens without identifying the root cause. We introduce DAIRA (Dynamic Analysis-enhanced Issue Resolution Agent), a pioneering automated repair framework deeply embedding dynamic analysis into the agent's decision loop. DAIRA employs a Test Tracing-Driven workflow, using lightweight tools to capture runtime evidence (e.g., call stacks and variable states) and convert it into structured semantic reports. By illuminating execution paths and causal dependencies, DAIRA enables precise fault localization and prevents context window flooding from irrelevant code retrievals. This shifts the agent's approach from speculative reasoning to deterministic inference. Evaluations on the SWE-bench Verified benchmark show DAIRA achieves a state-of-the-art 79.4% resolution rate when powered by Gemini 3 Flash Preview. Furthermore, it demonstrates robustness in addressing deep-seated logical defects, securing a 44.4% resolution rate on the most demanding tasks. Compared to baselines, DAIRA uniquely resolves complex edge cases and improves operational efficiency. Across various LLMs, it reduces inference costs by approximately 10% and input token consumption by 25%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DAIRA, an LLM agent framework for automated issue resolution that embeds lightweight dynamic analysis via a Test Tracing-Driven workflow. This workflow captures runtime evidence such as call stacks and variable states and converts it into structured semantic reports to support precise fault localization. The central empirical claim is that this approach yields a state-of-the-art 79.4% resolution rate on SWE-bench Verified (with Gemini 3 Flash Preview) and 44.4% on the most demanding tasks, while also reducing token consumption by ~25% and inference costs by ~10% relative to baselines.
Significance. If the reported gains are shown to stem specifically from the dynamic-analysis component, the work would provide concrete evidence that runtime traces can reduce speculative reasoning in LLM agents for repository-level repair. This has direct implications for practical automated program repair tools, particularly for complex control-flow and type-related defects.
major comments (3)
- [Evaluation] Evaluation section: the 79.4% resolution claim on SWE-bench Verified is not supported by an ablation that disables the Test Tracing-Driven workflow (while holding prompting, retrieval, and base LLM fixed). Without this isolation, the performance delta cannot be attributed to dynamic analysis rather than other unstated factors.
- [§4] §4 (experimental setup): no quantitative measurement of tracing error rates or cases in which the generated runtime reports mislead the agent on polymorphic flows or implicit type degradation is provided, leaving the weakest modeling assumption untested.
- [Results] Results tables: baseline comparisons lack reported variance across runs, exact configuration details for competing methods, and statistical significance tests, weakening the state-of-the-art assertion.
minor comments (2)
- [§3] Clarify the precise format and content of the 'structured semantic reports' produced from captured call stacks and variable states.
- Add a reproducibility note specifying the exact versions of SWE-bench Verified and the Gemini model used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the empirical claims without altering the core contributions of DAIRA.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the 79.4% resolution claim on SWE-bench Verified is not supported by an ablation that disables the Test Tracing-Driven workflow (while holding prompting, retrieval, and base LLM fixed). Without this isolation, the performance delta cannot be attributed to dynamic analysis rather than other unstated factors.
Authors: We agree that an ablation isolating the Test Tracing-Driven workflow is necessary to attribute gains specifically to dynamic analysis. In the revised manuscript we will add this controlled ablation (disabling only the tracing and report-generation steps while freezing prompting, retrieval, and the Gemini 3 Flash Preview backbone) and report the resulting resolution rates, token usage, and cost figures. revision: yes
-
Referee: [§4] §4 (experimental setup): no quantitative measurement of tracing error rates or cases in which the generated runtime reports mislead the agent on polymorphic flows or implicit type degradation is provided, leaving the weakest modeling assumption untested.
Authors: We acknowledge the absence of quantitative tracing-error analysis. The revised version will include measured error rates from the lightweight tracing tools on SWE-bench Verified, together with a qualitative breakdown of failure modes on polymorphic control flows and implicit type degradation, including the frequency with which such reports led the agent to incorrect localizations. revision: yes
-
Referee: [Results] Results tables: baseline comparisons lack reported variance across runs, exact configuration details for competing methods, and statistical significance tests, weakening the state-of-the-art assertion.
Authors: We agree that variance, configuration transparency, and statistical tests are required to support the SOTA claim. The updated tables will report mean and standard deviation over at least three independent runs per configuration, list exact hyper-parameters and retrieval settings for every baseline, and include p-values from paired statistical tests comparing DAIRA against each baseline. revision: yes
Circularity Check
No circularity: empirical benchmark results with no derivations or self-referential reductions
full rationale
The paper presents DAIRA as an empirical framework that embeds dynamic analysis into an LLM agent and reports resolution rates on the external SWE-bench Verified benchmark (79.4% overall, 44.4% on hard tasks). No equations, parameters, or first-principles derivations appear in the provided text. Performance claims rest on direct benchmark measurements rather than any fitted inputs renamed as predictions, self-citations that carry the central argument, or definitions that presuppose the claimed outcome. The derivation chain is therefore self-contained against the benchmark and exhibits no reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can effectively leverage structured runtime reports (call stacks, variable states) for precise fault localization in complex code
invented entities (1)
-
DAIRA framework with Test Tracing-Driven workflow
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anonymous Author(s). 2025. DAIRA: Replication Package. https://anonymous. 4open.science/r/DAIRA-1EC0 Accessed: 2025-01-30
work page 2025
- [2]
-
[3]
Nicolas Bettenburg, Sascha Just, Adrian Schröter, Cathrin Weiss, Rahul Premraj, and Thomas Zimmermann. 2008. What makes a good bug report?. InProceedings of the 16th ACM SIGSOFT International Symposium on Foundations of Software Engineering(Atlanta, Georgia)(SIGSOFT ’08/FSE-16). Association for Computing Machinery, New York, NY, USA, 308–318. doi:10.1145/...
- [4]
-
[5]
SGM Cornelissen, AE Zaidman, A van Deursen, LMF Moonen, and R Koschke
-
[6]
A Systematic Survey of Program Comprehension through Dynamic Analysis.IEEE Transactions on Software Engineering35, 5 (2009), 684–702. doi:10.1109/TSE.2009.28
-
[7]
J. D. Hunter. 2007. Matplotlib: A 2D graphics environment.Computing in Science & Engineering9, 3 (2007), 90–95. doi:10.1109/MCSE.2007.55
-
[8]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [9]
-
[10]
Jierui Li, Hung Le, Yingbo Zhou, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. 2025. CodeTree: Agent-guided Tree Search for Code Generation with Large Language Models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Luis Ch...
-
[11]
Changshu Liu, Alireza Ghazanfari, Yang Chen, and Reyhan Jabbarvand. 2025. Evaluating Code Reasoning Abilities of Large Language Models Under Real-World Settings. https://api.semanticscholar.org/CorpusID:283920955
work page 2025
- [12]
-
[13]
Smith, Mateusz Paprocki, Ondřej Čertík, Sergey B
Aaron Meurer, Christopher P. Smith, Mateusz Paprocki, Ondřej Čertík, Sergey B. Kirpichev, Matthew Rocklin, Amit Kumar, Sergiu Ivanov, Jason K. Moore, Sar- taj Singh, Thilina Rathnayake, Sean Vig, Brian E. Granger, Richard P. Muller, Francesco Bonazzi, Harsh Gupta, Shivam Vats, Fredrik Johansson, Fabian Pe- dregosa, Matthew J. Curry, Andy R. Terrel, Štěpán...
-
[14]
Manish Motwani, Sandhya Sankaranarayanan, René Just, and Yuriy Brun. 2018. Do automated program repair techniques repair hard and important bugs?. In Proceedings of the 40th International Conference on Software Engineering(Gothen- burg, Sweden)(ICSE ’18). Association for Computing Machinery, New York, NY, USA, 25. doi:10.1145/3180155.3182533
-
[15]
Fangwen Mu, Junjie Wang, Lin Shi, Song Wang, Shoubin Li, and Qing Wang. 2025. EXPEREPAIR: Dual-Memory Enhanced LLM-based Repository-Level Program Repair. arXiv:2506.10484 [cs.SE] https://arxiv.org/abs/2506.10484
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
2025.Hunter: A flexible code tracing toolkit
Ionel Cristian Măries,. 2025.Hunter: A flexible code tracing toolkit. https://github. com/ionelmc/python-hunter BSD 2-Clause License
work page 2025
- [17]
-
[18]
Gregory Tassey. 2002. The economic impacts of inadequate infrastructure for software testing. https://api.semanticscholar.org/CorpusID:107332102
work page 2002
-
[19]
G Tassey. 2002. Economic Impacts of Inadequate Infrastructure for Software Testing. (2002)
work page 2002
-
[20]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang
-
[22]
Agentless: Demystifying LLM-based Software Engineering Agents
Agentless: Demystifying LLM-based Software Engineering Agents. arXiv:2407.01489 [cs.SE] https://arxiv.org/abs/2407.01489
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Chunqiu Steven Xia, Zhe Wang, Yan Yang, Yuxiang Wei, and Lingming Zhang
- [24]
- [25]
-
[26]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer In- terfaces Enable Automated Software Engineering. InAdvances in Neural Informa- tion Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran A...
- [27]
- [28]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.