Recognition: unknown
MemDLM: Memory-Enhanced DLM Training
Pith reviewed 2026-05-15 00:39 UTC · model grok-4.3
The pith
MemDLM offloads part of the memorization burden in diffusion language models from token attention to model parameters using bi-level optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemDLM introduces bi-level optimization in which an inner loop maintains fast weights that form a Parametric Memory encoding the local denoising trajectory, while the outer loop updates the base model conditioned on this memory; offloading contextual information from token-space attention into parameter space improves training dynamics and yields representations usable without the fast weights at inference.
What carries the argument
Bi-level optimization that creates Parametric Memory by updating fast weights on the denoising trajectory in the inner loop and conditioning the base-model update on those weights in the outer loop.
If this is right
- Training converges faster than standard DLM training.
- Long-context representations become stronger.
- Overall training loss decreases.
- Re-enabling the inner loop at inference creates an emergent in-weight retrieval effect on needle-in-a-haystack tasks.
Where Pith is reading between the lines
- The same split between attention and parameter memory could be tested in autoregressive models facing context-length limits.
- Scaling the length or complexity of the simulated trajectory inside the inner loop might further reduce dependence on attention for very long inputs.
- The method points toward hybrid memory designs that combine static parameters with lightweight per-prompt adaptation across other generative architectures.
Load-bearing premise
The bi-level optimization transfers useful denoising trajectory information into the base model parameters without introducing instability or requiring the fast weights to stay present at inference.
What would settle it
Train a standard DLM and a MemDLM on identical long-context data, then compare final loss and convergence speed after discarding fast weights at inference; if the MemDLM shows no advantage, the central claim is falsified.
Figures






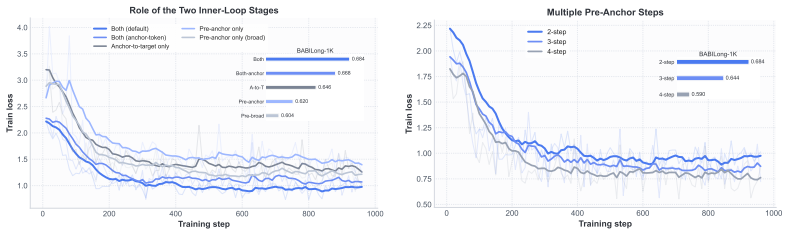

read the original abstract
Diffusion Language Models (DLMs) offer attractive advantages over Auto-Regressive (AR) models, such as full-attention parallel decoding and flexible generation. However, standard DLM training uses a static, single-step masked prediction objective that never exposes the model to the progressive denoising dynamics of inference, and forces all contextual information to be maintained purely through token-space attention, which becomes increasingly diluted as context length grows. We propose MemDLM (Memory-Enhanced DLM), which introduces a second memory channel by embedding a simulated denoising trajectory into training via Bi-level Optimization. An inner loop updates a set of fast weights, forming a Parametric Memory that captures the local trajectory experience, while an outer loop updates the base model conditioned on this memory. By offloading part of the memorization burden from token-space attention to parameter space, MemDLM yields faster convergence, stronger long-context representations, and lower training loss, even when the fast weights are discarded at inference time. Re-enabling the inner loop at inference provides an additional prompt-specific adaptation effect, where the Parametric Memory acts as an emergent in-weight retrieval mechanism on challenging Needle-in-a-Haystack tasks. Code: https://github.com/JarvisPei/MemDLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemDLM, a training method for Diffusion Language Models that uses bi-level optimization to embed simulated denoising trajectories. An inner loop updates fast weights forming a Parametric Memory that captures local trajectory experience, while an outer loop updates the base model conditioned on this memory. The approach offloads memorization from token-space attention to parameter space, claiming faster convergence, stronger long-context representations, and lower training loss that persist even after discarding fast weights at inference; re-enabling the inner loop enables prompt-specific adaptation on tasks like Needle-in-a-Haystack.
Significance. If the empirical claims hold, the method could offer a practical way to improve DLM training dynamics and long-context performance without permanent inference overhead, by transferring trajectory information into base parameters via bi-level optimization. The code release aids reproducibility, and the distinction between training-time memory and inference-time discard is a clear strength. However, the absence of quantitative results or ablations in the provided description limits assessment of practical impact relative to standard DLM training.
major comments (3)
- [Abstract] Abstract: The central claims of faster convergence, stronger long-context representations, and lower training loss (even after discarding fast weights) are asserted without any quantitative results, ablation details, or experimental setup description, preventing verification of the bi-level optimization's effectiveness.
- [Method] Method section (bi-level optimization description): The transfer of denoising-trajectory information from inner-loop fast weights to outer-loop base parameters lacks explicit equations or analysis confirming stable gradient flow and independence from the memory channel; without this, it is unclear whether gains are due to auxiliary dynamics rather than encoded trajectory knowledge.
- [Experiments] Experiments: No ablation isolating base-model performance (post-training, fast weights discarded) is described to substantiate that improvements in convergence and long-context handling persist independently of the Parametric Memory, which is load-bearing for the main claim.
minor comments (1)
- The introduction of 'Parametric Memory' as a new entity would benefit from explicit comparison to related concepts such as fast weights in meta-learning or adapter modules, with appropriate citations.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of our results and methods.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of faster convergence, stronger long-context representations, and lower training loss (even after discarding fast weights) are asserted without any quantitative results, ablation details, or experimental setup description, preventing verification of the bi-level optimization's effectiveness.
Authors: We agree that the abstract would benefit from including key quantitative highlights to better support the claims. In the revised version, we have updated the abstract to report specific metrics from our experiments, including the reduction in training steps required for convergence, the improvement in long-context perplexity, and the persistent loss reduction after discarding fast weights, with full experimental details remaining in the Experiments section. revision: yes
-
Referee: [Method] Method section (bi-level optimization description): The transfer of denoising-trajectory information from inner-loop fast weights to outer-loop base parameters lacks explicit equations or analysis confirming stable gradient flow and independence from the memory channel; without this, it is unclear whether gains are due to auxiliary dynamics rather than encoded trajectory knowledge.
Authors: We appreciate this suggestion for greater rigor in the method description. We have revised the Method section to include the complete bi-level optimization equations, along with a gradient-flow analysis showing that trajectory information is stably encoded into the base parameters. This analysis confirms that the observed gains arise from the transferred knowledge rather than auxiliary training dynamics, and that performance improvements hold independently of the memory channel at inference. revision: yes
-
Referee: [Experiments] Experiments: No ablation isolating base-model performance (post-training, fast weights discarded) is described to substantiate that improvements in convergence and long-context handling persist independently of the Parametric Memory, which is load-bearing for the main claim.
Authors: The manuscript already reports base-model results after discarding fast weights, with direct comparisons to standard DLM training showing retained gains. To make this isolation explicit, we have added a dedicated ablation subsection in the Experiments section that compares the post-training base model (fast weights removed) against vanilla DLM baselines on convergence speed and long-context tasks, confirming the improvements are independent of the Parametric Memory at test time. revision: yes
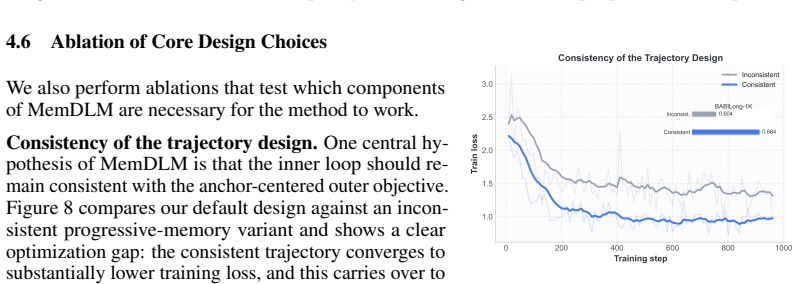
Circularity Check
No significant circularity: new bi-level optimization structure is independent of fitted inputs
full rationale
The paper introduces an explicit bi-level optimization procedure (inner-loop fast weights for parametric memory, outer-loop base model updates) as a novel training mechanism for DLMs. The central claims of faster convergence, stronger long-context representations, and persistent gains after discarding fast weights at inference are framed as empirical outcomes of this new structure rather than re-derivations, predictions from fitted parameters, or self-citations. No equations or steps in the provided description reduce a claimed result to its own inputs by construction. The derivation chain is self-contained against external benchmarks, with the method's independence from fast weights at inference presented as a testable property of the outer-loop training rather than a definitional tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- inner-loop learning rate
axioms (1)
- domain assumption Bi-level optimization can embed denoising dynamics into parameter updates without requiring the fast weights at inference
invented entities (1)
-
Parametric Memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
work page 2021
-
[2]
Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
work page 2024
-
[3]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131–103167, 2024
work page 2024
-
[5]
Your absorbing discrete diffusion secretly models the conditional distributions of clean data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. arXiv preprint arXiv:2406.03736, 2024
-
[6]
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling.arXiv preprint arXiv:2409.02908, 2024
-
[7]
Andrew Campbell, Joe Benton, Valentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models.Advances in Neural Information Processing Systems, 35:28266–28279, 2022
work page 2022
-
[8]
Score-based continuous-time discrete diffusion models
Haoran Sun, Lijun Yu, Bo Dai, Dale Schuurmans, and Hanjun Dai. Score-based continuous-time discrete diffusion models.arXiv preprint arXiv:2211.16750, 2022
-
[9]
Chenlin Meng, Kristy Choi, Jiaming Song, and Stefano Ermon. Concrete score matching: Generalized score matching for discrete data.Advances in Neural Information Processing Systems, 35:34532–34545, 2022
work page 2022
-
[10]
Haoyu He, Katrin Renz, Yong Cao, and Andreas Geiger. Mdpo: Overcoming the training- inference divide of masked diffusion language models.arXiv preprint arXiv:2508.13148, 2025
-
[11]
Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. Revolutioniz- ing reinforcement learning framework for diffusion large language models.arXiv preprint arXiv:2509.06949, 2025
-
[12]
Zemin Huang, Zhiyang Chen, Zijun Wang, Tiancheng Li, and Guo-Jun Qi. Reinforcing the diffu- sion chain of lateral thought with diffusion language models.arXiv preprint arXiv:2505.10446, 2025
-
[13]
Fred Zhangzhi Peng, Zachary Bezemek, Jarrid Rector-Brooks, Shuibai Zhang, Anru R Zhang, Michael Bronstein, Avishek Joey Bose, and Alexander Tong. Planner aware path learning in diffusion language models training.arXiv preprint arXiv:2509.23405, 2025
-
[14]
Scalable-softmax is superior for attention.arXiv preprint arXiv:2501.19399, 2025
Ken M Nakanishi. Scalable-softmax is superior for attention.arXiv preprint arXiv:2501.19399, 2025
-
[15]
DySCO: Dynamic Attention-Scaling Decoding for Long-Context Language Models
Xi Ye, Wuwei Zhang, Fangcong Yin, Howard Yen, and Danqi Chen. Dysco: Dynamic attention- scaling decoding for long-context lms.arXiv preprint arXiv:2602.22175, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
work page 2024
-
[17]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Using fast weights to improve persistent contrastive divergence
Tijmen Tieleman and Geoffrey Hinton. Using fast weights to improve persistent contrastive divergence. InProceedings of the 26th annual international conference on machine learning, pages 1033–1040, 2009
work page 2009
-
[19]
Jimmy Ba, Geoffrey E Hinton, V olodymyr Mnih, Joel Z Leibo, and Catalin Ionescu. Using fast weights to attend to the recent past.Advances in neural information processing systems, 29, 2016
work page 2016
-
[20]
Using fast weights to deblur old memories
Geoffrey E Hinton and David C Plaut. Using fast weights to deblur old memories. InProceedings of the ninth annual conference of the Cognitive Science Society, pages 177–186, 1987
work page 1987
-
[21]
Memory-based Parameter Adaptation
Pablo Sprechmann, Siddhant M Jayakumar, Jack W Rae, Alexander Pritzel, Adria Puig- domenech Badia, Benigno Uria, Oriol Vinyals, Demis Hassabis, Razvan Pascanu, and Charles Blundell. Memory-based parameter adaptation.arXiv preprint arXiv:1802.10542, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Llada-moe: A sparse moe diffusion language model.arXiv preprint arXiv:2509.24389, 2025
Fengqi Zhu, Zebin You, Yipeng Xing, Zenan Huang, Lin Liu, Yihong Zhuang, Guoshan Lu, Kangyu Wang, Xudong Wang, Lanning Wei, et al. Llada-moe: A sparse moe diffusion language model.arXiv preprint arXiv:2509.24389, 2025
-
[23]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [24]
-
[25]
Babilong: Testing the limits of llms with long context reasoning-in-a-haystack
Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, and Mikhail Burtsev. Babilong: Testing the limits of llms with long context reasoning-in-a-haystack. Advances in Neural Information Processing Systems, 37:106519–106554, 2024
work page 2024
-
[26]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[27]
dllm: Simple diffusion language modeling, 2026
Zhanhui Zhou, Lingjie Chen, Hanghang Tong, and Dawn Song. dllm: Simple diffusion language modeling, 2026
work page 2026
-
[28]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
work page 2024
-
[29]
Long alpaca: Long-context instruction-following models
Yukang Chen, Shaozuo Yu, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. Long alpaca: Long-context instruction-following models. https://github.com/ dvlab-research/LongLoRA, 2023
work page 2023
-
[30]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
work page 2024
-
[32]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Dllm agent: See farther, run faster.arXiv preprint arXiv:2602.07451, 2026
Huiling Zhen, Weizhe Lin, Renxi Liu, Kai Han, Yiming Li, Yuchuan Tian, Hanting Chen, Xiaoguang Li, Xiaosong Li, Chen Chen, et al. Dllm agent: See farther, run faster.arXiv preprint arXiv:2602.07451, 2026
-
[35]
Yunhe Wang, Kai Han, Huiling Zhen, Yuchuan Tian, Hanting Chen, Yongbing Huang, Yufei Cui, Yingte Shu, Shan Gao, Ismail Elezi, et al. Top 10 open challenges steering the future of diffusion language model and its variants.arXiv preprint arXiv:2601.14041, 2026
-
[36]
Fast-weight product key memory.arXiv preprint arXiv:2601.00671, 2026
Tianyu Zhao and Llion Jones. Fast-weight product key memory.arXiv preprint arXiv:2601.00671, 2026
-
[37]
Jihoon Tack, Jaehyung Kim, Eric Mitchell, Jinwoo Shin, Yee Whye Teh, and Jonathan Richard Schwarz. Online adaptation of language models with a memory of amortized contexts.Advances in Neural Information Processing Systems, 37:130109–130135, 2024
work page 2024
-
[38]
Mass-Editing Memory in a Transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer.arXiv preprint arXiv:2210.07229, 2022
work page internal anchor Pith review arXiv 2022
-
[39]
Fast model editing at scale.arXiv preprint arXiv:2110.11309, 2021
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale.arXiv preprint arXiv:2110.11309, 2021
-
[40]
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, Jingbo Shang, and Julian J. McAuley. MEMORYLLM: towards self-updatable large language models. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024
work page 2024
-
[41]
Yu Wang, Xinshuang Liu, Xiusi Chen, Sean O’Brien, Junda Wu, and Julian McAuley. Self- updatable large language models by integrating context into model parameters.arXiv preprint arXiv:2410.00487, 2024
-
[42]
Shankar Padmanabhan, Yasumasa Onoe, Michael Zhang, Greg Durrett, and Eunsol Choi. Propagating knowledge updates to lms through distillation.Advances in Neural Information Processing Systems, 36:47124–47142, 2023
work page 2023
-
[43]
Learning to learn: Introduction and overview
Sebastian Thrun and Lorien Pratt. Learning to learn: Introduction and overview. InLearning to learn, pages 3–17. Springer, 1998
work page 1998
-
[44]
Model-agnostic meta-learning for fast adap- tation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adap- tation of deep networks. InInternational conference on machine learning, pages 1126–1135. PMLR, 2017
work page 2017
-
[45]
On First-Order Meta-Learning Algorithms
Alex Nichol, Joshua Achiam, and John Schulman. On first-order meta-learning algorithms. arXiv preprint arXiv:1803.02999, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
Matching networks for one shot learning.Advances in neural information processing systems, 29, 2016
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning.Advances in neural information processing systems, 29, 2016
work page 2016
-
[47]
Prototypical networks for few-shot learning
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. Advances in neural information processing systems, 30, 2017
work page 2017
-
[48]
Meta-learning with memory-augmented neural networks
Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. Meta-learning with memory-augmented neural networks. InInternational conference on machine learning, pages 1842–1850. PMLR, 2016
work page 2016
-
[49]
Meta-learning with implicit gradients.Advances in neural information processing systems, 32, 2019
Aravind Rajeswaran, Chelsea Finn, Sham M Kakade, and Sergey Levine. Meta-learning with implicit gradients.Advances in neural information processing systems, 32, 2019
work page 2019
-
[50]
Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes.Advances in neural information processing systems, 35:30583–30598, 2022
work page 2022
-
[51]
Test-time training with self-supervision for generalization under distribution shifts
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt. Test-time training with self-supervision for generalization under distribution shifts. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 9229–9248. PMLR, ...
work page 2020
-
[52]
Siheng Xiong, Oguzhan Gungordu, Blair Johnson, James C Kerce, and Faramarz Fekri. Scaling search-augmented llm reasoning via adaptive information control.arXiv preprint arXiv:2602.01672, 2026
-
[53]
Scope: Prompt evolution for enhancing agent effectiveness.arXiv preprint arXiv:2512.15374, 2025
Zehua Pei, Hui-Ling Zhen, Shixiong Kai, Sinno Jialin Pan, Yunhe Wang, Mingxuan Yuan, and Bei Yu. Scope: Prompt evolution for enhancing agent effectiveness.arXiv preprint arXiv:2512.15374, 2025
-
[54]
Tent: Fully test-time adaptation by entropy minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Representations, 2021
work page 2021
-
[55]
Test-time training done right.arXiv preprint arXiv:2505.23884, 2025
Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T Freeman, and Hao Tan. Test-time training done right.arXiv preprint arXiv:2505.23884, 2025
-
[56]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
End-to-end test-time training for long context.arXiv preprint arXiv:2512.23675, 2025
Arnuv Tandon, Karan Dalal, Xinhao Li, Daniel Koceja, Marcel Rød, Sam Buchanan, Xiaolong Wang, Jure Leskovec, Sanmi Koyejo, Tatsunori Hashimoto, et al. End-to-end test-time training for long context.arXiv preprint arXiv:2512.23675, 2025
-
[58]
Self- adapting language models.arXiv preprint arXiv:2506.10943, 2025
Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, and Pulkit Agrawal. Self- adapting language models.arXiv preprint arXiv:2506.10943, 2025
-
[59]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 13 A Additional Experimental Details Implementation and Baselines.We implement MemDLM in PyTorch [26] on top of the open-source dllm [27] training library and use lm-evaluation-harness [28] for downstream evaluation. We study two backbones in the...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.