PIM-CACHE: High-Efficiency Content-Aware Copy for Processing-In-Memory
Pith reviewed 2026-05-14 23:56 UTC · model grok-4.3
The pith
PIM-CACHE reduces redundant host-to-DPU transfers in processing-in-memory systems by detecting workload similarity and performing content-aware copies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PIM-CACHE is a lightweight data staging layer that dynamically eliminates redundant data transfers to PIM DPUs by exploiting workload similarity, achieving content-aware copy (CAC).
What carries the argument
The content-aware copy (CAC) mechanism inside the PIM-CACHE staging layer, which inspects data blocks for similarity before issuing host-to-DPU transfers.
If this is right
- Data-transfer overhead drops for any PIM workload that reuses similar blocks across kernels.
- Genome-scale pipelines benefit directly because sequence data often contains repeated motifs.
- The software layer requires no hardware changes to the DPU or DIMM design.
- Overall PIM application runtime improves when transfer time dominates execution.
Where Pith is reading between the lines
- The same staging idea could be applied to other heterogeneous systems that move large buffers between host and accelerator memory.
- Hardware support for fast similarity hashes might amplify the gains beyond the current software-only implementation.
- Workloads with rapidly changing data patterns would expose the point where the staging cost exceeds its benefit.
Load-bearing premise
Workload similarity occurs frequently enough and can be detected cheaply enough that the added staging logic reduces net overhead.
What would settle it
A workload consisting entirely of unique data blocks where the similarity checks add measurable latency with zero skipped transfers.
Figures




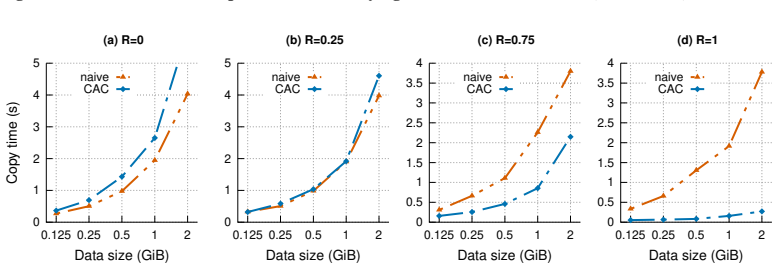
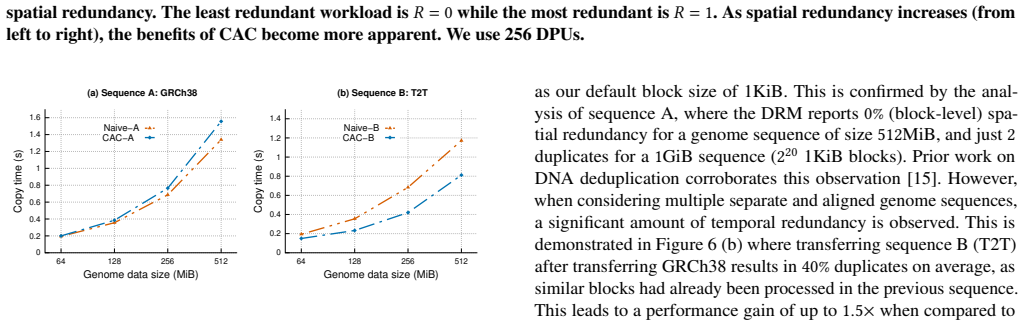


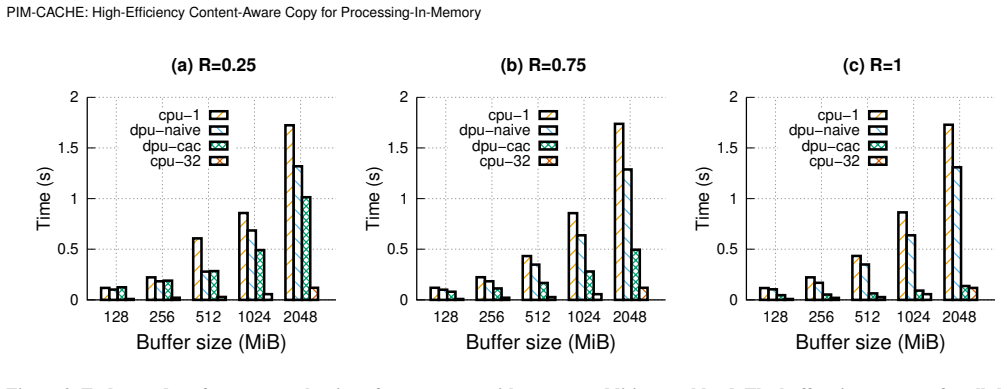
read the original abstract
Processing-in-memory (PIM) architectures bring computation closer to data, reducing the processor-memory transfer bottleneck in traditional processor-centric designs. Novel hardware solutions, such as UPMEM's in-memory processing technology, achieve this by integrating low-power DRAM processing units (DPUs) into memory DIMMs, enabling massive parallelism and improved memory bandwidth. However, paradoxically, these PIM architectures introduce mandatory coarse-grained data transfers between host DRAM and DPUs, which often become the new bottleneck. We present PIM-CACHE, a lightweight data staging layer that dynamically eliminates redundant data transfers to PIM DPUs by exploiting workload similarity, achieving content-aware copy (CAC). We evaluate PIM-CACHE on both synthetic workloads and real-world genome datasets, demonstrating its effectiveness in reducing PIM data transfer overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PIM-CACHE, a lightweight data staging layer for processing-in-memory (PIM) architectures such as UPMEM. It dynamically eliminates redundant host-to-DPU transfers by detecting workload similarity and performing content-aware copy (CAC). The central claim is that this approach reduces PIM data-transfer overhead, with evaluation reported on synthetic workloads and real-world genome datasets.
Significance. If the quantitative claims hold, PIM-CACHE would directly mitigate the coarse-grained transfer bottleneck that remains after computation is moved into memory. The idea of lightweight, similarity-driven staging is a pragmatic extension of existing PIM software stacks and could be relevant to any DPU-based system where repeated data patterns appear. The evaluation on genome data is a positive sign of real-world applicability.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): the manuscript states that PIM-CACHE reduces transfer overhead on synthetic and genome workloads, yet provides no quantitative results, speedups, energy figures, or error bars. Without these numbers it is impossible to judge whether the added staging logic is offset by the savings.
- [§3] §3 (Design): the description of similarity detection and the mechanism that preserves correctness under content-aware copy are missing. It is therefore unclear whether the technique is safe for arbitrary workloads or only for the two evaluated domains.
minor comments (1)
- [§2] Notation for the CAC primitive and the similarity threshold should be defined once and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment point-by-point below and will incorporate the suggested changes in the revised manuscript to strengthen the presentation of results and design details.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): the manuscript states that PIM-CACHE reduces transfer overhead on synthetic and genome workloads, yet provides no quantitative results, speedups, energy figures, or error bars. Without these numbers it is impossible to judge whether the added staging logic is offset by the savings.
Authors: We agree that explicit quantitative results are essential for evaluating the claims. Although §4 contains figures and tables with transfer reduction percentages, speedups, and energy measurements on both synthetic and genome workloads (including error bars from multiple runs), the abstract currently summarizes only qualitatively. In the revision we will add concrete numbers (e.g., average transfer reduction of X% and speedup of Y×) to the abstract and ensure every claim in §4 is accompanied by the corresponding numeric values and statistical details. revision: yes
-
Referee: [§3] §3 (Design): the description of similarity detection and the mechanism that preserves correctness under content-aware copy are missing. It is therefore unclear whether the technique is safe for arbitrary workloads or only for the two evaluated domains.
Authors: We acknowledge that the current §3 presents the high-level architecture but omits the low-level details of similarity detection and the correctness argument. In the revised version we will expand §3 with (1) the exact similarity-detection procedure (hash-based content comparison with configurable threshold), (2) the conditions under which content-aware copy is invoked, and (3) a clear argument (with pseudocode) showing that CAC preserves semantic correctness for any workload whose data blocks satisfy the similarity predicate, while noting that the evaluated domains simply exhibit high similarity in practice. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces PIM-CACHE as an empirical systems contribution: a lightweight staging layer that exploits observed workload similarity to perform content-aware copy and reduce redundant host-to-DPU transfers. No equations, fitted parameters, uniqueness theorems, or self-citation chains appear in the abstract or description. The central claim rests on workload similarity being frequent enough to offset added logic, which is presented as an empirical observation rather than a derivation that reduces to its own inputs by construction. Evaluation on synthetic workloads and genome datasets is described as direct measurement, keeping the argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Workload similarity exists and can be detected cheaply enough to justify the staging layer.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present PIM-CACHE, a lightweight data staging layer that dynamically eliminates redundant data transfers to PIM DPUs by exploiting workload similarity, achieving content-aware copy (CAC).
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our CAC approach identifies repeating data patterns using well-known fingerprinting techniques, deduplicating the data before transferring it to DPU memory.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
iDedup: Latency-aware, Inline Data Deduplication for Primary Storage
2012. iDedup: Latency-aware, Inline Data Deduplication for Primary Storage. In 10th USENIX Conference on File and Storage Technologies (FAST 12). USENIX Association, San Jose, CA. https://www.usenix.org/conference/fast12/idedup- latency-aware-inline-data-deduplication-primary-storage
work page 2012
-
[2]
Mahbod Afarin, Chao Gao, Shafiur Rahman, Nael Abu-Ghazaleh, and Rajiv Gupta
-
[3]
CommonGraph: Graph Analytics on Evolving Data. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Vancouver, BC, Canada)(ASPLOS 2023). Association for Computing Machinery, New York, NY , USA, 133–145. doi:10.1145/3575693.3575713
-
[4]
Sergey Aganezov, Stephanie M Yan, Daniela C Soto, Melanie Kirsche, Samantha Zarate, Pavel Avdeyev, Dylan J Taylor, Kishwar Shafin, Alaina Shumate, Chunlin Xiao, et al. 2022. A complete reference genome improves analysis of human genetic variation.Science376, 6588 (2022), eabl3533
work page 2022
-
[5]
Sandeep R Agrawal, Sam Idicula, Arun Raghavan, Evangelos Vlachos, Venka- traman Govindaraju, Venkatanathan Varadarajan, Cagri Balkesen, Georgios Gi- annikis, Charlie Roth, Nipun Agarwal, and Eric Sedlar. 2017. A many-core architecture for in-memory data processing. InProceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture(Camb...
-
[6]
Junwhan Ahn, Sungpack Hong, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi
-
[7]
A fully associative, tagless dram cache,
A scalable processing-in-memory accelerator for parallel graph process- ing. In2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA). 105–117. doi:10.1145/2749469.2750386
-
[8]
Mohammed Alser, Zülal Bingöl, Damla Senol Cali, Jeremie Kim, Saugata Ghose, Can Alkan, and Onur Mutlu. 2020. Accelerating genome analysis: A primer on an ongoing journey.IEEE Micro40, 5 (2020), 65–75
work page 2020
-
[9]
Jeongcheol An and Dongkun Shin. 2013. Offline deduplication-aware block separation for solid state disk. In11th USENIX Conference on File and Storage Technologies (FAST 13)
work page 2013
-
[10]
Austin Appleby. 2025. XXHash. https://github.com/aappleby/smhasher. Accessed on 20-01-2025
work page 2025
-
[11]
D. H. Bailey, E. Barszcz, J. T. Barton, D. S. Browning, R. L. Carter, L. Dagum, R. A. Fatoohi, P. O. Frederickson, T. A. Lasinski, R. S. Schreiber, H. D. Simon, V . Venkatakrishnan, and S. K. Weeratunga. 1991. The NAS parallel bench- marks—summary and preliminary results. InProceedings of the 1991 ACM/IEEE Conference on Supercomputing(Albuquerque, New Mex...
-
[12]
Paul Bartus and Emmanuel Arzuaga. 2018. GDedup: Distributed File System Level Deduplication for Genomic Big Data. In2018 IEEE International Congress on Big Data (BigData Congress). 120–127. doi:10.1109/BigDataCongress.2018. 00023
-
[13]
Intersection Prediction for Accelerated GPU Ray Tracing,
Abanti Basak, Zheng Qu, Jilan Lin, Alaa R. Alameldeen, Zeshan Chishti, Yufei Ding, and Yuan Xie. 2021. Improving Streaming Graph Processing Perfor- mance using Input Knowledge. InMICRO-54: 54th Annual IEEE/ACM In- ternational Symposium on Microarchitecture(Virtual Event, Greece)(MICRO ’21). Association for Computing Machinery, New York, NY , USA, 1036–105...
-
[15]
Marty C Brandon, Douglas C Wallace, and Pierre Baldi. 2009. Data structures and compression algorithms for genomic sequence data.Bioinformatics25, 14 (2009), 1731–1738
work page 2009
-
[16]
Shuangyu Cai, Boyu Tian, Huanchen Zhang, and Mingyu Gao. 2024. PimPam: Efficient Graph Pattern Matching on Real Processing-in-Memory Hardware.Proc. ACM Manag. Data2, 3, Article 161 (May 2024), 25 pages. doi:10.1145/3654964
-
[17]
Vinicius Cogo, João Paulo, and Alysson Bessani. 2021. GenoDedup: Similarity- Based Deduplication and Delta-Encoding for Genome Sequencing Data.IEEE Trans. Comput.70, 5 (2021), 669–681. doi:10.1109/TC.2020.2994774
-
[18]
Jeffrey Dean. 2009. Challenges in building large-scale information retrieval systems: invited talk. InProceedings of the Second ACM International Conference on Web Search and Data Mining(Barcelona, Spain)(WSDM ’09). Association for Computing Machinery, New York, NY , USA, 1. doi:10.1145/1498759.1498761
-
[19]
Biplob Debnath, Sudipta Sengupta, and Jin Li. 2010. ChunkStash: Speeding Up Inline Storage Deduplication Using Flash Memory. In2010 USENIX Annual Technical Conference (USENIX ATC 10). USENIX Associa- tion. https://www.usenix.org/conference/usenix-atc-10/chunkstash-speeding- inline-storage-deduplication-using-flash-memory
work page 2010
-
[20]
Safaa Diab, Amir Nassereldine, Mohammed Alser, Juan Gómez Luna, Onur Mutlu, and Izzat El Hajj. 2023. A framework for high-throughput sequence alignment using real processing-in-memory systems.Bioinformatics39, 5 (2023), btad155
work page 2023
-
[21]
Maitreya J Dunham and Douglas M Fowler. 2013. Contemporary, yeast-based approaches to understanding human genetic variation.Current opinion in genetics & development23, 6 (2013), 658–664
work page 2013
-
[22]
Ahmed El-Shimi, Ran Kalach, Ankit Kumar, Adi Ottean, Jin Li, and Sudipta Sengupta. 2012. Primary Data Deduplication—Large Scale Study and System De- sign. In2012 USENIX Annual Technical Conference (USENIX ATC 12). USENIX Association, Boston, MA, 285–296. https://www.usenix.org/conference/atc12/ technical-sessions/presentation/el-shimi
work page 2012
-
[23]
Birte Friesel, Marcel Lütke Dreimann, and Olaf Spinczyk. 2023. A Full-System Perspective on UPMEM Performance. InProceedings of the 1st Workshop on Disruptive Memory Systems(Koblenz, Germany)(DIMES ’23). Association for Computing Machinery, New York, NY , USA, 1–7. doi:10.1145/3609308.3625266
-
[24]
Mingyu Gao and Christos Kozyrakis. 2016. HRL: Efficient and flexible reconfig- urable logic for near-data processing. In2016 IEEE International Symposium on High Performance Computer Architecture (HPCA). 126–137. doi:10.1109/HPCA. 2016.7446059
-
[25]
Christina Giannoula, Ivan Fernandez, Juan Gómez Luna, Nectarios Koziris, Georgios Goumas, and Onur Mutlu. 2022. SparseP: Towards Efficient Sparse Matrix Vector Multiplication on Real Processing-In-Memory Architectures. Proc. ACM Meas. Anal. Comput. Syst.6, 1, Article 21 (Feb. 2022), 49 pages. doi:10.1145/3508041
- [26]
-
[27]
Google. 2025. FarmHash. https://github.com/google/farmhash/. Accessed on 20-01-2025
work page 2025
-
[28]
Saransh Gupta and Tajana Šimuni ´c Rosing. 2021. Invited: Accelerating Fully Homomorphic Encryption with Processing in Memory. In2021 58th ACM/IEEE Design Automation Conference (DAC). 1335–1338. doi:10.1109/DAC18074.2021. 9586285
-
[29]
Juan Gómez-Luna, Izzat El Hajj, Ivan Fernandez, Christina Giannoula, Geraldo F. Oliveira, and Onur Mutlu. 2022. Benchmarking a New Paradigm: Experimental Analysis and Characterization of a Real Processing-in-Memory System.IEEE Access10 (2022), 52565–52608. doi:10.1109/ACCESS.2022.3174101
-
[30]
Gernot Heiser. 2025. Systems Benchmarking Crimes. https://gernot-heiser.org/ benchmarking-crimes.html. Accessed on 10-02-2025
work page 2025
- [31]
-
[32]
Bongjoon Hyun, Taehun Kim, Dongjae Lee, and Minsoo Rhu. 2024. Pathfinding Future PIM Architectures by Demystifying a Commercial PIM Technology. In 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 263–279. doi:10.1109/HPCA57654.2024.00029
-
[33]
Anand Padmanabha Iyer, Qifan Pu, Kishan Patel, Joseph E. Gonzalez, and Ion Stoica. 2021. TEGRA: Efficient Ad-Hoc Analytics on Evolving Graphs. In18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21). USENIX Association, 337–355. https://www.usenix.org/conference/nsdi21/ presentation/iyer
work page 2021
-
[34]
Myeongjae Jeon, Shivaram Venkataraman, Amar Phanishayee, Junjie Qian, Wen- cong Xiao, and Fan Yang. 2019. Analysis of Large-Scale Multi-Tenant GPU Clusters for DNN Training Workloads. In2019 USENIX Annual Technical Conference (USENIX ATC 19). USENIX Association, Renton, WA, 947–960. https://www.usenix.org/conference/atc19/presentation/jeon
work page 2019
-
[35]
Abellán, Ajay Joshi, David Kaeli, and John Kim
Gilbert Jonatan, Haeyoon Cho, Hyojun Son, Xiangyu Wu, Neal Livesay, Evelio Mora, Kaustubh Shivdikar, José L. Abellán, Ajay Joshi, David Kaeli, and John Kim. 2024. Scalability Limitations of Processing-in-Memory using Real System Evaluations.Proc. ACM Meas. Anal. Comput. Syst.8, 1, Article 5 (feb 2024), 28 pages. doi:10.1145/3639046
-
[36]
Ricardo Koller and Raju Rangaswami. 2010. I/O A High Performance Deduplication Engine with Mixed Pages. In8th USENIX Conference on File and Storage Technologies (FAST 10). USENIX Association, San Jose, CA. https://www.usenix.org/conference/fast-10/io-deduplication-utilizing- content-similarity-improve-io-performance
work page 2010
-
[37]
Dominique Lavenier, Jean-Francois Roy, and David Furodet. 2016. DNA mapping using Processor-in-Memory architecture. In2016 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). 1429–1435. doi:10.1109/BIBM. 2016.7822732 Peterson Yuhala, Mpoki Mwaisela, Pascal Felber, and Valerio Schiavoni
-
[38]
Dongjae Lee, Bongjoon Hyun, Taehun Kim, and Minsoo Rhu. 2024. PIM-MMU: A Memory Management Unit for Accelerating Data Transfers in Commercial PIM Systems . In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE Computer Society, Los Alamitos, CA, USA, 627–642. doi:10. 1109/MICRO61859.2024.00053
-
[39]
D. Lee, B. Hyun, T. Kim, and M. Rhu. 2024. Analysis of Data Transfer Bottle- necks in Commercial PIM Systems: A Study with UPMEM-PIM.IEEE Computer Architecture Letters01 (apr 2024), 1–4. doi:10.1109/LCA.2024.3387472
-
[40]
Daniel Lemire, Nathan Kurz, and Christoph Rupp. 2018. Stream VByte: Faster byte-oriented integer compression.Inform. Process. Lett.130 (2018), 1–6
work page 2018
-
[41]
Wenji Li, Gregory Jean-Baptise, Juan Riveros, Giri Narasimhan, Tony Zhang, and Ming Zhao. 2016. CacheDedup: In-line Deduplication for Flash Caching. In 14th USENIX Conference on File and Storage Technologies (FAST 16). USENIX Association, Santa Clara, CA, 301–314. https://www.usenix.org/conference/ fast16/technical-sessions/presentation/li-wenji
work page 2016
-
[42]
Dutch T Meyer and William J Bolosky. 2012. A study of practical deduplication. ACM Transactions on Storage (ToS)7, 4 (2012), 1–20
work page 2012
-
[43]
Onur Mutlu, Saugata Ghose, Juan Gómez-Luna, and Rachata Ausavarungnirun
-
[44]
Microprocessors and Microsystems67 (2019), 28–41
Processing data where it makes sense: Enabling in-memory computation. Microprocessors and Microsystems67 (2019), 28–41
work page 2019
-
[45]
Mpoki Mwaisela, Joel Hari, Peterson Yuhala, Jämes Ménétrey, Pascal Felber, and Valerio Schiavoni. 2024. Evaluating the Potential of In-Memory Processing to Accelerate Homomorphic Encryption: Practical Experience Report. In2024 43rd International Symposium on Reliable Distributed Systems (SRDS). 92–103. doi:10.1109/SRDS64841.2024.00019
-
[46]
Mpoki Mwaisela, Peterson Yuhala, Pascal Felber, and Valerio Schiavoni
- [47]
-
[48]
Joel Nider, Craig Mustard, Andrada Zoltan, and Alexandra Fedorova. 2020. Pro- cessing in Storage Class Memory. In12th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 20). USENIX Association. https: //www.usenix.org/conference/hotstorage20/presentation/nider
work page 2020
-
[49]
Joel Nider, Craig Mustard, Andrada Zoltan, John Ramsden, Larry Liu, Jacob Grossbard, Mohammad Dashti, Romaric Jodin, Alexandre Ghiti, Jordi Chauzi, and Alexandra Fedorova. 2021. A Case Study of Processing-in-Memory in off- the-Shelf Systems. In2021 USENIX Annual Technical Conference (USENIX ATC 21). USENIX Association, 117–130. https://www.usenix.org/conf...
work page 2021
-
[50]
University of California Santa Cruz. 2025. UCSC Genome Browser Home. https://hgdownload.soe.ucsc.edu/downloads.html. Accessed on 24-02-2025
work page 2025
-
[51]
National Library of Medicine. [n. d.]. Genome assembly GRCh38. https://www. ncbi.nlm.nih.gov/datasets/genome/GCF_000001405.26/. Accessed on 20-01- 2025
work page 2025
-
[52]
National Library of Medicine. 2025. FASTA Format for Nucleotide Sequences. https://www.ncbi.nlm.nih.gov/genbank/fastaformat/. Accessed on 24-02-2025
work page 2025
-
[53]
Park, Saurabh Hukerikar, Ryan Adamson, and Christian Engelmann
Byung H. Park, Saurabh Hukerikar, Ryan Adamson, and Christian Engelmann
-
[54]
In2017 IEEE International Conference on Cluster Computing (CLUSTER)
Big Data Meets HPC Log Analytics: Scalable Approach to Understanding Systems at Extreme Scale. In2017 IEEE International Conference on Cluster Computing (CLUSTER). 758–765. doi:10.1109/CLUSTER.2017.113
-
[55]
Gerardo Perez, Galt P Barber, Anna Benet-Pages, Jonathan Casper, Hiram Claw- son, Mark Diekhans, Clay Fischer, Jairo Navarro Gonzalez, Angie S Hinrichs, Christopher M Lee, et al . 2025. The UCSC Genome Browser database: 2025 update.Nucleic Acids Research53, D1 (2025), D1243–D1249
work page 2025
-
[56]
Jiansheng Qiu, Yanqi Pan, Wen Xia, Xiaojia Huang, Wenjun Wu, Xiangyu Zou, Shiyi Li, and Yu Hua. 2023. Light-Dedup: A Light-weight Inline Deduplication Framework for Non-V olatile Memory File Systems. In2023 USENIX Annual Technical Conference (USENIX ATC 23). USENIX Association, Boston, MA, 101–116. https://www.usenix.org/conference/atc23/presentation/qiu-...
work page 2023
-
[57]
Sourjya Roy, Mustafa Ali, and Anand Raghunathan. 2021. PIM-DRAM: Acceler- ating machine learning workloads using processing in commodity DRAM.IEEE Journal on Emerging and Selected Topics in Circuits and Systems11, 4 (2021), 701–710
work page 2021
-
[58]
Sophie Schbath, Véronique Martin, Matthias Zytnicki, Julien Fayolle, Valentin Loux, and Jean-François Gibrat. 2012. Mapping reads on a genomic sequence: an algorithmic overview and a practical comparative analysis.Journal of Computa- tional Biology19, 6 (2012), 796–813
work page 2012
-
[59]
Valerie A Schneider, Tina Graves-Lindsay, Kerstin Howe, Nathan Bouk, Hsiu- Chuan Chen, Paul A Kitts, Terence D Murphy, Kim D Pruitt, Françoise Thibaud- Nissen, Derek Albracht, et al. 2017. Evaluation of GRCh38 and de novo haploid genome assemblies demonstrates the enduring quality of the reference assembly. Genome research27, 5 (2017), 849–864
work page 2017
-
[60]
Vivek Seshadri, Yoongu Kim, Chris Fallin, Donghyuk Lee, Rachata Ausavarung- nirun, Gennady Pekhimenko, Yixin Luo, Onur Mutlu, Phillip B. Gibbons, Michael A. Kozuch, and Todd C. Mowry. 2013. RowClone: Fast and energy- efficient in-DRAM bulk data copy and initialization. In2013 46th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). 185–197
work page 2013
-
[61]
Alexander A. Stepanov, Anil R. Gangolli, Daniel E. Rose, Ryan J. Ernst, and Paramjit S. Oberoi. 2011. SIMD-based decoding of posting lists. InProceed- ings of the 20th ACM International Conference on Information and Knowledge Management(Glasgow, Scotland, UK)(CIKM ’11). Association for Computing Machinery, New York, NY , USA, 317–326. doi:10.1145/2063576.2063627
-
[62]
Todd J Treangen and Steven L Salzberg. 2012. Repetitive DNA and next- generation sequencing: computational challenges and solutions.Nature Reviews Genetics13, 1 (2012), 36–46
work page 2012
-
[63]
UPMEM. 2022.UPMEM Processing In-Memory (PIM): ultra-efficient accelera- tion for data-intensive applications. White paper
work page 2022
-
[64]
UPMEM. 2025. UPMEM SDK. https://sdk.upmem.com/2025.1.0/031_ DPURuntimeService_Memory.html. Accessed on 24-02-2025
work page 2025
-
[65]
Sébastien Vaucher, Niloofar Yazdani, Pascal Felber, Daniel E. Lucani, and Valerio Schiavoni. 2020. ZipLine: in-network compression at line speed. InProceedings of the 16th International Conference on Emerging Networking EXperiments and Technologies(Barcelona, Spain)(CoNEXT ’20). Association for Computing Machinery, New York, NY , USA, 399–405. doi:10.1145...
-
[66]
Qiuping Wang, Jinhong Li, Wen Xia, Erik Kruus, Biplob Debnath, and Patrick P. C. Lee. 2020. Austere Flash Caching with Deduplication and Compression. In2020 USENIX Annual Technical Conference (USENIX ATC 20). USENIX Association, 713–726. https://www.usenix.org/conference/atc20/presentation/wang-qiuping
work page 2020
-
[67]
Yufeng Wang and Charith Mendis. 2023. TGOpt: Redundancy-Aware Optimiza- tions for Temporal Graph Attention Networks. InProceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming (Montreal, QC, Canada)(PPoPP ’23). Association for Computing Machinery, New York, NY , USA, 354–368. doi:10.1145/3572848.3577490
-
[68]
Huijun Wu, Chen Wang, Yinjin Fu, Sherif Sakr, Kai Lu, and Liming Zhu. 2018. A Differentiated Caching Mechanism to Enable Primary Storage Deduplication in Clouds.IEEE Transactions on Parallel and Distributed Systems29, 6 (2018), 1202–1216. doi:10.1109/TPDS.2018.2790946
-
[69]
XXHash. 2025. XXHash. https://xxhash.com/. Accessed on 20-01-2025
work page 2025
-
[70]
Zhiguo Zhang, Lu Zhang, Guoqing Zhang, Ze Zhao, Hui Wang, and Feng Ju
-
[71]
Deduplication improves cost-efficiency and yields of de novo assembly and binning of shotgun metagenomes in microbiome research.Microbiology Spectrum11, 2 (2023), e04282–22
work page 2023
-
[72]
Zhao Zhang, Zhichun Zhu, and Xiaodong Zhang. 2000. A permutation-based page interleaving scheme to reduce row-buffer conflicts and exploit data locality. In Proceedings of the 33rd Annual ACM/IEEE International Symposium on Microar- chitecture(Monterey, California, USA)(MICRO 33). Association for Computing Machinery, New York, NY , USA, 32–41. doi:10.1145...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.