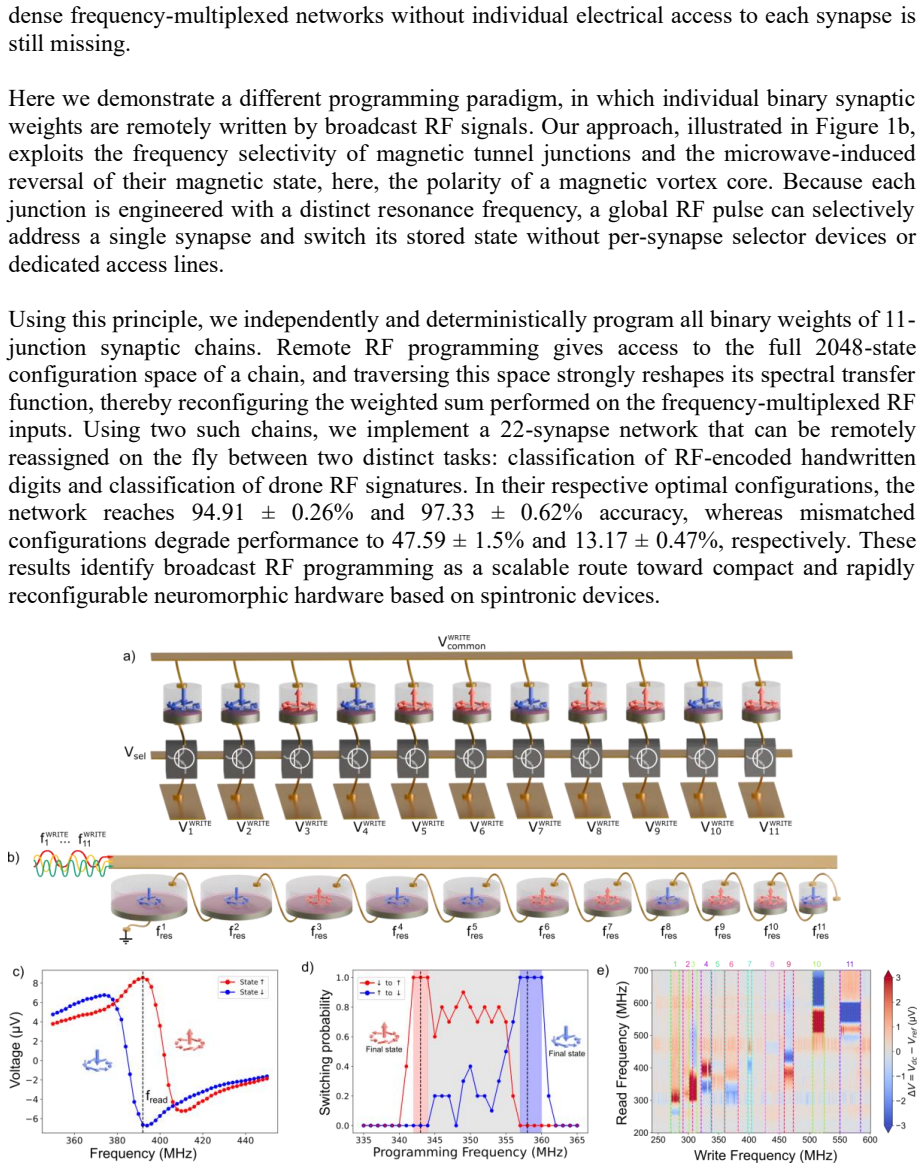
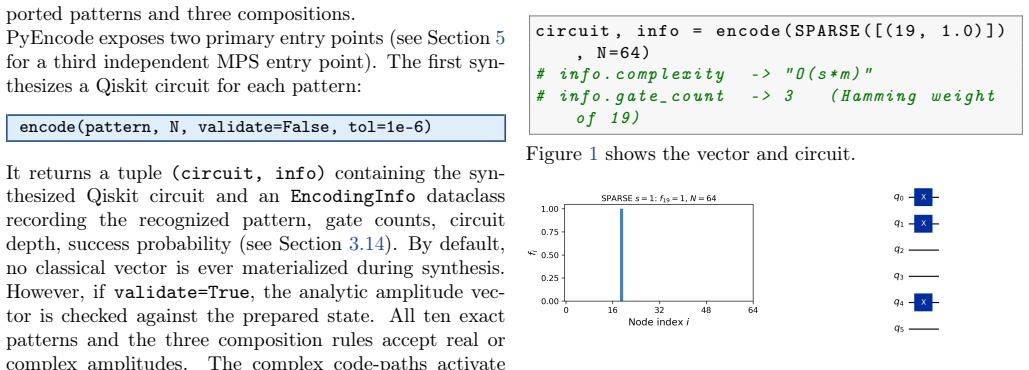
0
Latched memristor cell cuts AI search energy by 33 percent
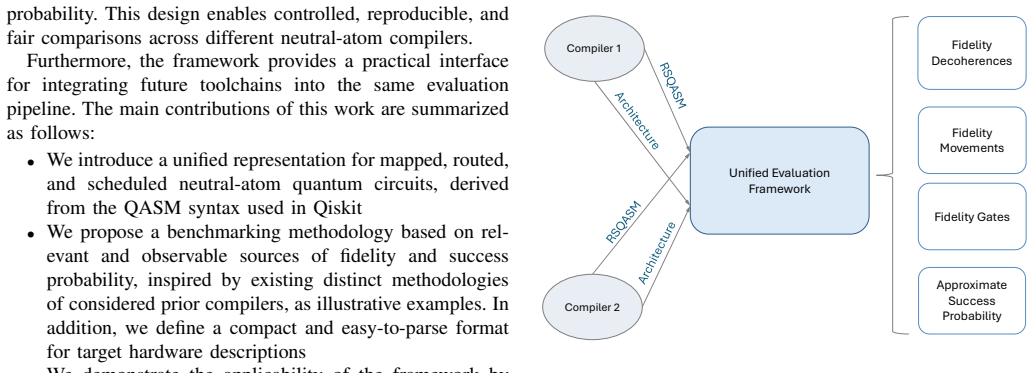
A Fast and Energy-Efficient Latch-Based Memristive Analog Content-Addressable Memory
Dynamic comparator removes gain and crosstalk limits of earlier designs and supports workload-specific energy-latency tradeoffs.
 full image
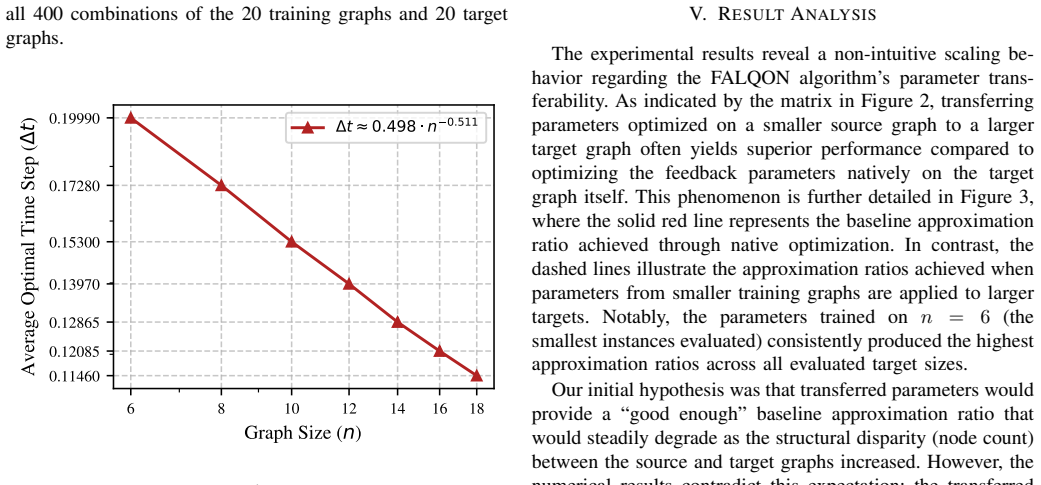
full image
abstract click to expand
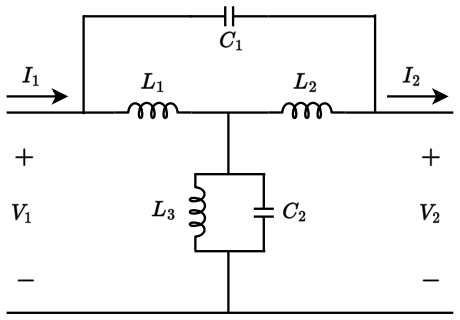
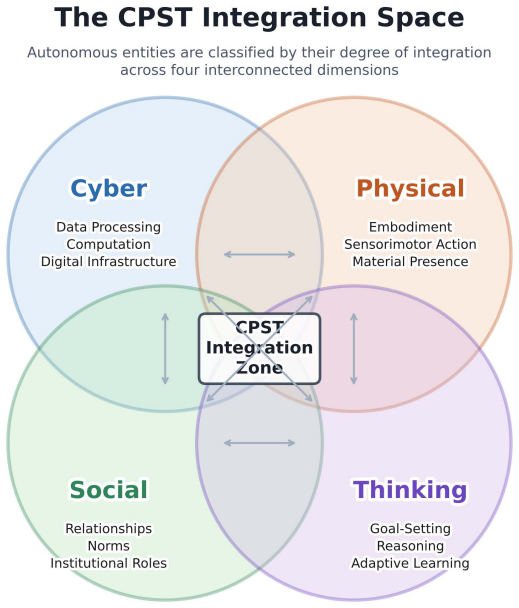
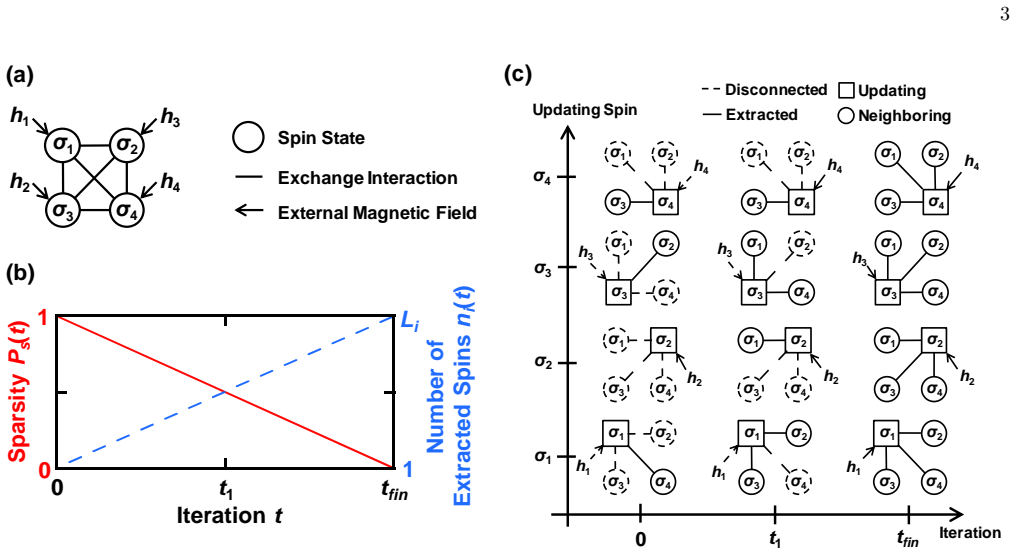
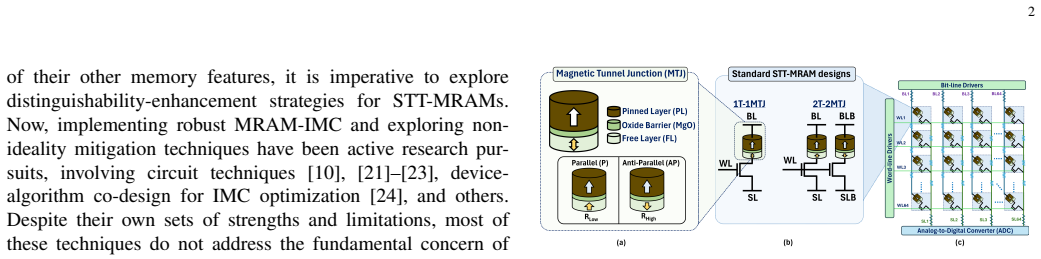
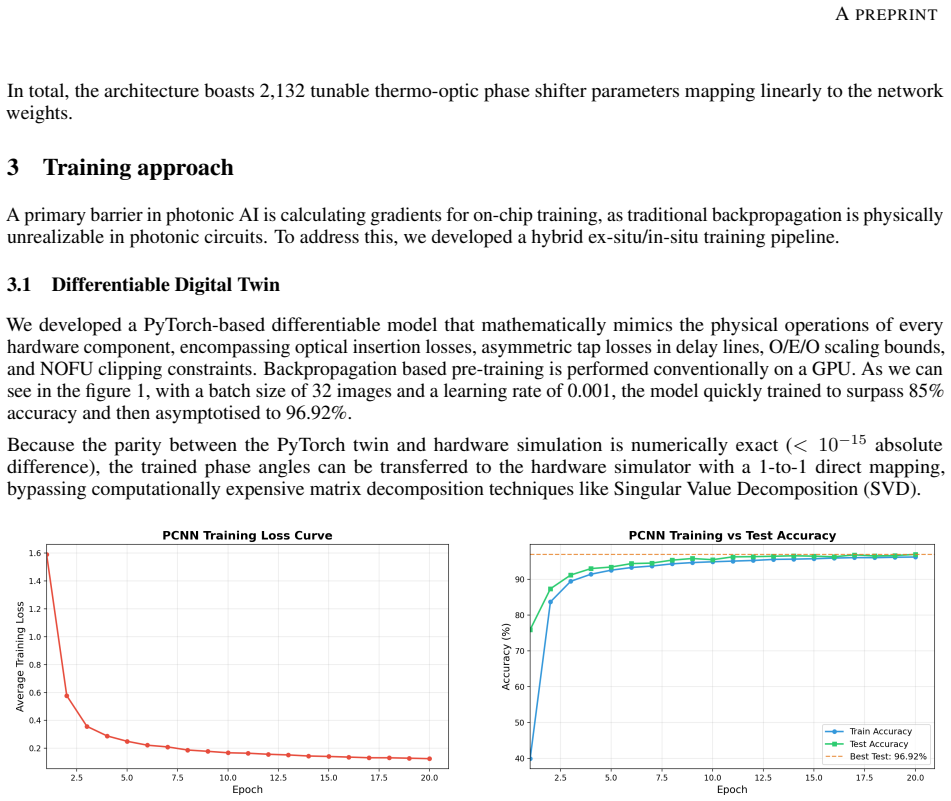
Analog content-addressable memories (aCAMs) based on memristors provide a promising pathway toward energy-efficient large-scale associative computing for Edge AI and embedded intelligence applications. They have been successfully applied to decision-tree inference and extend the capabilities of compute-in-memory (CIM) architectures beyond conventional vector-matrix multiplication. However, conventional designs such as the 6T2M architecture suffer from static search power, limited voltage gain, and pronounced match-line crosstalk, constraining analog precision and scalability. We introduce a strong-arm latched memristor (SALM) aCAM cell that replaces static voltage division with a dynamic current-race comparator, enabling high regenerative gain, intrinsic result latching, and near-zero static search power. Compared to 6T2M, SALM reduces read energy by 33% at identical latency while eliminating the gain and crosstalk limitations that prevent 6T2M from scaling to large arrays. SALM further enables scalable sequential and parallel latch sharing, and a dataset-aware optimization framework exposes an explicit energy-latency tradeoff, achieving up to 50% energy reduction at 3x latency across representative workloads. To enable architectural exploration, we develop a circuit-accurate behavioral model derived from SPICE lookup tables in 22 nm FD-SOI technology, capturing match-line dynamics and crosstalk. Integrated into the X-TIME decision-tree compiler, this framework demonstrates that SALM maintains near-software accuracy for high-dimensional datasets, whereas baseline designs degrade due to limited gain and cumulative crosstalk.