Recognition: no theorem link
From Pixels to Digital Agents: An Empirical Study on the Taxonomy and Technological Trends of Reinforcement Learning Environments
Pith reviewed 2026-05-15 01:16 UTC · model grok-4.3
The pith
Reinforcement learning environments are splitting into LLM-driven semantic systems and domain-specific physical generalization systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Automated semantic and statistical analysis of a corpus of over 2,000 RL publications reveals a paradigm shift in which the field bifurcates into a Semantic Prior ecosystem dominated by Large Language Models and a Domain-Specific Generalization ecosystem; each ecosystem carries distinct cognitive fingerprints that govern cross-task synergy, multi-domain interference, and zero-shot generalization.
What carries the argument
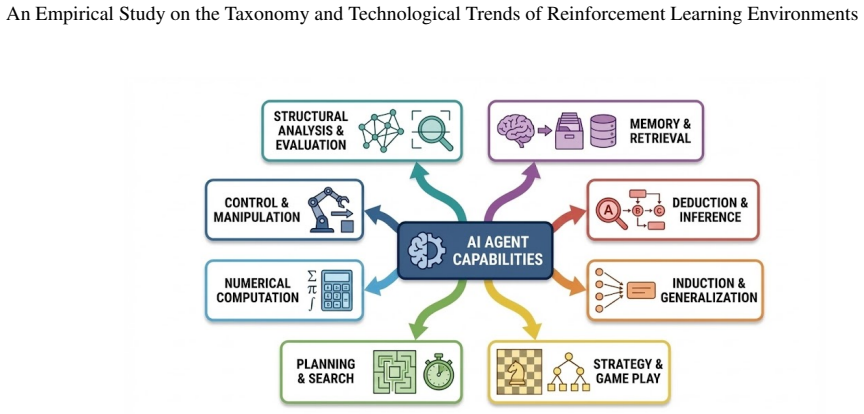
A novel multi-dimensional taxonomy that classifies RL benchmarks by application domains and required cognitive capabilities, derived through automated processing of publication data.
If this is right
- Designers of new agents can target the two ecosystems separately before combining their strengths.
- Cognitive fingerprints offer a practical way to forecast and improve zero-shot transfer between tasks.
- Embodied Semantic Simulators can be built by deliberately bridging pixel-level control with language-level reasoning.
- Environment selection for training can be guided by the quantitative trends rather than qualitative judgment alone.
Where Pith is reading between the lines
- Separate training regimes for semantic and physical skills may become standard before integration into single agents.
- Applying the same automated taxonomy method to other AI domains could expose parallel splits in research focus.
- New environments released after the study can be classified under the taxonomy to test whether the bifurcation continues.
Load-bearing premise
That programmatically analyzing a large corpus of publications produces an unbiased map of RL environment trends without meaningful selection or interpretation bias in the pipeline.
What would settle it
A manual audit of several hundred recent papers that places the majority outside both the Semantic Prior and Domain-Specific Generalization categories or shows no statistical evidence of bifurcation.
Figures
















read the original abstract
The remarkable progress of reinforcement learning (RL) is intrinsically tied to the environments used to train and evaluate artificial agents. Moving beyond traditional qualitative reviews, this work presents a large-scale, data-driven empirical investigation into the evolution of RL environments. By programmatically processing a massive corpus of academic literature and rigorously distilling over 2,000 core publications, we propose a quantitative methodology to map the transition from isolated physical simulations to generalist, language-driven foundation agents. Implementing a novel, multi-dimensional taxonomy, we systematically analyze benchmarks against diverse application domains and requisite cognitive capabilities. Our automated semantic and statistical analysis reveals a profound, data-verified paradigm shift: the bifurcation of the field into a "Semantic Prior" ecosystem dominated by Large Language Models (LLMs) and a "Domain-Specific Generalization" ecosystem. Furthermore, we characterize the "cognitive fingerprints" of these distinct domains to uncover the underlying mechanisms of cross-task synergy, multi-domain interference, and zero-shot generalization. Ultimately, this study offers a rigorous, quantitative roadmap for designing the next generation of Embodied Semantic Simulators, bridging the gap between continuous physical control and high-level logical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a large-scale empirical study analyzing over 2,000 publications on reinforcement learning environments. It proposes a multi-dimensional taxonomy to map the evolution from physical simulations to language-driven agents and claims a paradigm shift bifurcating the field into a 'Semantic Prior' ecosystem dominated by LLMs and a 'Domain-Specific Generalization' ecosystem, while characterizing 'cognitive fingerprints' for cross-task synergy and zero-shot generalization.
Significance. If the automated analysis is shown to be robust, the quantitative taxonomy could provide a valuable roadmap for designing next-generation embodied semantic simulators that bridge continuous physical control and high-level reasoning, moving the field beyond purely qualitative reviews.
major comments (2)
- [Methodology] The automated semantic and statistical analysis section provides no description of the embedding model, dimensionality reduction technique, clustering algorithm, or any other implementation details used to derive the multi-dimensional taxonomy and the bifurcation into Semantic Prior and Domain-Specific Generalization ecosystems. This prevents assessment of whether the reported paradigm shift is an artifact of the pipeline choices.
- [Results] No human-annotated ground-truth dataset, precision/recall metrics, or external benchmark comparisons are reported to validate the automated labels or the claimed cross-task synergy and zero-shot generalization patterns. The central claim of a 'data-verified paradigm shift' therefore rests on an unvalidated process.
minor comments (1)
- [Abstract] The abstract introduces 'cognitive fingerprints' without a concise operational definition, which should be clarified early to aid reader comprehension.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical analysis of reinforcement learning environments. The comments highlight important areas for improving methodological transparency and validation, which we address below.
read point-by-point responses
-
Referee: [Methodology] The automated semantic and statistical analysis section provides no description of the embedding model, dimensionality reduction technique, clustering algorithm, or any other implementation details used to derive the multi-dimensional taxonomy and the bifurcation into Semantic Prior and Domain-Specific Generalization ecosystems. This prevents assessment of whether the reported paradigm shift is an artifact of the pipeline choices.
Authors: We agree that the original manuscript omits key implementation details of the automated pipeline. In the revised version, we will insert a dedicated 'Implementation Details' subsection describing the embedding model (all-MiniLM-L6-v2 via sentence-transformers), dimensionality reduction (UMAP with n_neighbors=15 and min_dist=0.1), clustering (HDBSCAN with min_cluster_size=5), and the statistical procedures used to detect the bifurcation and cognitive fingerprints. These additions will support reproducibility and allow readers to evaluate whether the observed paradigm shift depends on specific pipeline choices. revision: yes
-
Referee: [Results] No human-annotated ground-truth dataset, precision/recall metrics, or external benchmark comparisons are reported to validate the automated labels or the claimed cross-task synergy and zero-shot generalization patterns. The central claim of a 'data-verified paradigm shift' therefore rests on an unvalidated process.
Authors: We acknowledge the absence of quantitative validation in the submitted manuscript. The revised version will add a validation subsection that reports a human annotation study on a random subset of 150 papers, yielding precision/recall figures and inter-annotator agreement against the automated labels. We will also include direct comparisons with prior qualitative taxonomies from the RL literature. While exhaustive ground-truth labeling of the full corpus remains resource-intensive, these targeted validations will provide concrete support for the bifurcation, cross-task synergy, and zero-shot patterns. revision: yes
Circularity Check
No circularity: empirical taxonomy derived from corpus analysis
full rationale
The paper conducts a data-driven literature review by programmatically processing >2000 publications to propose a novel multi-dimensional taxonomy and then applies automated semantic/statistical analysis to identify a bifurcation into Semantic Prior and Domain-Specific Generalization ecosystems. This bifurcation is reported as an output of the analysis on the processed corpus rather than a definitional premise or fitted parameter renamed as a prediction. No equations, self-citations, uniqueness theorems, or ansatzes are invoked in the provided sections that would reduce the central claims to their own inputs by construction. The methodology remains self-contained as an empirical mapping exercise.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The corpus of over 2,000 core publications accurately represents the evolution of RL environments
invented entities (3)
-
Semantic Prior ecosystem
no independent evidence
-
Domain-Specific Generalization ecosystem
no independent evidence
-
cognitive fingerprints
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MIT press, 2018
Richard S Sutton and Andrew G Barto.Reinforce- ment learning: An introduction. MIT press, 2018
2018
-
[2]
Mastering the game of go with deep neural networks and tree search.Nature, 529(7587):484– 489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Pan- neershelvam, Marc Lanctot, Sander Dieleman, Do- minik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Ko- ray Kavukcuoglu, Thore Graepel, and Demis Has- sabis. Masterin...
2016
-
[3]
Grandmaster level in star- craft ii using multi-agent reinforcement learning
Oriol Vinyals, Igor Babuschkin, Wojciech M Czar- necki, Michaël Mathieu, Andrew Dudzik, Juny- oung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Hor- gan, Manuel Kroiss, Ivo Danihelka, Aja Huang, Laurent Sifre, Trevor Cai, John P Agapiou, Max Jaderberg, Alexander S Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalib...
2019
-
[4]
End-to-end training of deep visuomo- tor policies.Journal of Machine Learning Research, 17(39):1–40, 2016
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end training of deep visuomo- tor policies.Journal of Machine Learning Research, 17(39):1–40, 2016
2016
-
[5]
Rusu, Joel Veness, Marc G
V olodymyr Mnih, Koray Kavukcuoglu, David Sil- ver, Andrei A. Rusu, Joel Veness, Marc G. Belle- mare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level con- trol through deep reinforc...
2015
-
[6]
Deep reinforcement learning that matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. InPro- ceedings of the AAAI Conference on Artificial Intel- ligence, volume 32, 2018
2018
-
[7]
The arcade learning environment: An evaluation platform for general agents.Jour- nal of Artificial Intelligence Research, 47:253–279, 2013
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents.Jour- nal of Artificial Intelligence Research, 47:253–279, 2013
2013
-
[8]
Mu- JoCo: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mu- JoCo: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelli- gent Robots and Systems, pages 5026–5033. IEEE, 2012
2012
-
[9]
Unity: A general platform for intelligent agents.arXiv:1809.02627, 2018
Arthur Juliani, Vincent-Pierre Berges, Ervin Teng, Andrew Cohen, Jonathan Harper, Chris Elion, Christopher Goy, Yuan Gao, Hunter Henry, Mar- wan Mattar, and Danny Lange. Unity: A general platform for intelligent agents.arXiv:1809.02627, 2018
-
[10]
Language models are few-shot learners.Advances in Neural Information Process- ing Systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. Language models are few-shot learners.Advances in Neural Information Process- ing Systems, 33:1877–1901, 2020
1901
-
[11]
OpenAI. Gpt-4 technical report.arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Neuronlike adaptive elements that can solve difficult learning control problems.IEEE Transactions on Systems, Man, and Cybernetics, (5):834–846, 1983
Andrew G Barto, Richard S Sutton, and Charles W Anderson. Neuronlike adaptive elements that can solve difficult learning control problems.IEEE Transactions on Systems, Man, and Cybernetics, (5):834–846, 1983
1983
-
[13]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schnei- der, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 23–30, 2017
2017
-
[14]
Leveraging procedural generation 34 An Empirical Study on the Taxonomy and Technological Trends of Reinforcement Learning Environments to benchmark reinforcement learning
Karl Cobbe, Christopher Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation 34 An Empirical Study on the Taxonomy and Technological Trends of Reinforcement Learning Environments to benchmark reinforcement learning. InInter- national Conference on Machine Learning, pages 2048–2056. PMLR, 2020
2048
-
[15]
A markovian decision process
Richard Bellman. A markovian decision process. Journal of Mathematics and Mechanics, pages 679– 684, 1957
1957
-
[16]
Textworld: A learning environment for text-based games
Marc-Alexandre Côté, Akos Kádár, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Matthew Hausknecht, Layla cross El Asri, Mahmoud Adada, Wendy Tay, and Adam Trischler. Textworld: A learning environment for text-based games. InWorkshop on Computer Games, pages 41–75, 2018
2018
-
[17]
Re- act: Synergizing reasoning and acting in language models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Re- act: Synergizing reasoning and acting in language models, 2023
2023
-
[18]
Transfer learning for reinforcement learning domains: A survey.Journal of Machine Learning Research, 10(Jul):1633–1685, 2009
Matthew E Taylor and Peter Stone. Transfer learning for reinforcement learning domains: A survey.Journal of Machine Learning Research, 10(Jul):1633–1685, 2009
2009
-
[19]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InInternational Conference on Machine Learning, pages 1126–1135, 2017
2017
-
[20]
The episodic buffer: a new com- ponent of working memory?Trends in Cognitive Sciences, 4(11):417–423, 2000
Alan D Baddeley. The episodic buffer: a new com- ponent of working memory?Trends in Cognitive Sciences, 4(11):417–423, 2000
2000
-
[21]
Darwin’s mistake: Explaining the discon- tinuity between human and nonhuman minds.Be- havioral and Brain Sciences, 31(2):109–130, 2008
Derek C Penn, Keith J Holyoak, and Daniel J Povinelli. Darwin’s mistake: Explaining the discon- tinuity between human and nonhuman minds.Be- havioral and Brain Sciences, 31(2):109–130, 2008
2008
-
[22]
How to grow a mind: Statistics, structure, and abstraction.Science, 331(6022):1279–1285, 2011
Joshua B Tenenbaum, Charles Kemp, Thomas L Griffiths, and Noah D Goodman. How to grow a mind: Statistics, structure, and abstraction.Science, 331(6022):1279–1285, 2011
2011
-
[23]
Does the chim- panzee have a theory of mind?Behavioral and Brain Sciences, 1(4):515–526, 1978
David Premack and Guy Woodruff. Does the chim- panzee have a theory of mind?Behavioral and Brain Sciences, 1(4):515–526, 1978
1978
-
[24]
Prospective memory: Theoretical considerations and opera- tional definitions.The Cognitive Neuroscience of Memory, pages 112–128, 2007
Sam J Gilbert and Paul W Burgess. Prospective memory: Theoretical considerations and opera- tional definitions.The Cognitive Neuroscience of Memory, pages 112–128, 2007
2007
-
[25]
Abstract representations of numbers in the animal and human brain.Trends in Neurosciences, 21(8):355–361, 1998
Stanislas Dehaene, Ghislaine Dehaene-Lambertz, and Laurent Cohen. Abstract representations of numbers in the animal and human brain.Trends in Neurosciences, 21(8):355–361, 1998
1998
-
[26]
The sensorimotor foundations of higher cognition
Daniel M Wolpert, Zoubin Ghahramani, and J Ran- dall Flanagan. The sensorimotor foundations of higher cognition. InCommon Minds: Themes from the Philosophy of Philip Pettit. Oxford University Press, 2003
2003
-
[27]
Three models for the description of language.IRE Transactions on Information Theory, 2(3):113–124, 1956
Noam Chomsky. Three models for the description of language.IRE Transactions on Information Theory, 2(3):113–124, 1956
1956
-
[28]
Planning and acting in partially observable stochastic domains.Artificial Intelli- gence, 101(1-2):99–134, 1998
Leslie Pack Kaelbling, Michael L Littman, and An- thony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial Intelli- gence, 101(1-2):99–134, 1998
1998
-
[29]
Superhuman AI for multiplayer poker.Science, 365(6456):885– 890, 2019
Noam Brown and Tuomas Sandholm. Superhuman AI for multiplayer poker.Science, 365(6456):885– 890, 2019
2019
-
[30]
Continuous con- trol with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous con- trol with deep reinforcement learning. InInter- national Conference on Learning Representations (ICLR), 2016
2016
-
[31]
Deep recur- rent q-learning for partially observable mdps
Matthew Hausknecht and Peter Stone. Deep recur- rent q-learning for partially observable mdps. In 2015 AAAI Fall Symposium Series, 2015
2015
-
[32]
Policy invariance under reward transforma- tions: Theory and application to reward shaping
Andrew Y Ng, Daishi Harada, and Stuart Rus- sell. Policy invariance under reward transforma- tions: Theory and application to reward shaping. InInternational Conference on Machine Learning (ICML), pages 278–287, 1999
1999
-
[33]
Exploration by random network dis- tillation
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network dis- tillation. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[34]
A survey of multi- objective sequential decision-making.Journal of Artificial Intelligence Research, 48:67–113, 2013
Diederik M Roijers, Peter Vamplew, Shimon White- son, and Richard Dazeley. A survey of multi- objective sequential decision-making.Journal of Artificial Intelligence Research, 48:67–113, 2013
2013
-
[35]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kel- ton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
2022
-
[36]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wo- jciech Zaremba. Openai gym.arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[37]
SWE-bench: Can language models resolve real-world GitHub issues? InThe Twelfth International Conference on Learning Rep- resentations, 2024
Carlos E Jimenez, John Yang Murphy, Alexander Shirinov, Kweon Chen, Austin McMillan, Guil- laume Lample, et al. SWE-bench: Can language models resolve real-world GitHub issues? InThe Twelfth International Conference on Learning Rep- resentations, 2024
2024
-
[38]
We- bArena: A realistic web environment for building autonomous agents
Shuyan Zhou, Frank F Hou, Yikang Cheng, Keisuke Hong, Graham Neubig, and Pengcheng Yin. We- bArena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[39]
A com- prehensive survey on safe reinforcement learning
Javier García and Fernando Fernández. A com- prehensive survey on safe reinforcement learning. 35 An Empirical Study on the Taxonomy and Technological Trends of Reinforcement Learning Environments Journal of Machine Learning Research, 16(1):1437– 1480, 2015
2015
-
[40]
On the Measure of Intelligence
François Chollet. On the measure of intelligence. arXiv:1911.01547, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[41]
Processbench: Identifying process errors in mathematical reasoning, 2025
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning, 2025
2025
-
[42]
Reward is enough.Artificial Intelligence, 299:103535, 2021
David Silver, Satinder Singh, Doina Precup, and Richard S Sutton. Reward is enough.Artificial Intelligence, 299:103535, 2021
2021
-
[43]
Vizdoom: A doom-based ai research platform for visual re- inforcement learning
Michał Kempka, Marek Wydmuch, Grzegorz Runc, Jakub Toczek, and Wojciech Ja´skowski. Vizdoom: A doom-based ai research platform for visual re- inforcement learning. In2016 IEEE Conference on Computational Intelligence and Games (CIG), pages 1–8, 2016
2016
-
[44]
Charles Beattie, Joel Z. Leibo, Denis Teplyashin, Tom Ward, Marcus Wainwright, Heinrich Küttler, Andrew Lefrancq, Simon Green, Víctor Valdés, Amir Sadik, Julian Schrittwieser, Keith Anderson, Sarah York, Max Cant, Adam Cain, Adrian Bolton, Stephen Gaffney, Helen King, Demis Hassabis, Shane Legg, and Stig Petersen. Deepmind lab. arXiv:1612.03801, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[45]
Minimalistic gridworld environment for OpenAI Gym
Maxime Chevalier-Boisvert, Lucas Willems, and Suman Pal. Minimalistic gridworld environment for OpenAI Gym. GitHub repository, 2018
2018
-
[46]
Habitat: A platform for embodied AI research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Ma- lik, et al. Habitat: A platform for embodied AI research. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 9339– 9347, 2019
2019
-
[47]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on Robot Learning, pages 1094–1100, 2020
2020
-
[48]
ALFWorld: Aligning text and embod- ied environments for interactive learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning text and embod- ied environments for interactive learning. InInter- national Conference on Learning Representations, 2021
2021
-
[49]
Brax–a differentiable physics engine for large scale rigid body simulation
C Daniel Freeman, Erik Frey, Anton Raichuk, Ser- tan Girgin, Igor Mordatch, and Olivier Bachem. Brax–a differentiable physics engine for large scale rigid body simulation. InThirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[50]
Minedojo: Building open-ended embodied agents with internet-scale knowledge, 2022
Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Man- dlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. Minedojo: Building open-ended embodied agents with internet-scale knowledge, 2022
2022
-
[51]
WebShop: Towards scalable real- world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards scalable real- world web interaction with grounded language agents. InAdvances in Neural Information Pro- cessing Systems, volume 35, pages 20744–20757, 2022
2022
-
[52]
Training software engineering agents and verifiers with swe-gym, 2025
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with swe-gym, 2025
2025
-
[53]
Sparks of artificial general intelli- gence: Early experiments with gpt-4, 2023
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, and Yi Zhang. Sparks of artificial general intelli- gence: Early experiments with gpt-4, 2023
2023
-
[54]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xi- aochuan Li, Ruiyuan Zhao, Ruisheng Cao, et al. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. arXiv preprint arXiv:2404.07972, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. Android- world: A dynamic benchmarking environment for autonomous agents.arXiv:2405.14573, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander M ˛ adry. Mle-bench: Evaluating machine learning agents on machine learning engineering.arXiv:2410.07095, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[58]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. InProceed- ings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
2021
-
[59]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[60]
The lean 4 theorem prover and programming language
Leonardo de Moura and Sebastian Ullrich. The lean 4 theorem prover and programming language. In Automated Deduction–CADE 28, pages 625–635, 2021. 36 An Empirical Study on the Taxonomy and Technological Trends of Reinforcement Learning Environments
2021
-
[61]
miniF2F: A cross-system benchmark for for- mal olympiad-level mathematics
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. miniF2F: A cross-system benchmark for for- mal olympiad-level mathematics. InInternational Conference on Learning Representations, 2022
2022
-
[62]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023
2023
-
[63]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Live- codebench: Holistic and contamination free eval- uation of large language models for code, 2024. arXiv:2403.07974
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Olympiad- bench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scien- tific problems
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiad- bench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scien- tific problems. InProceedings of the 62nd Annual Meeting of the Association fo...
2024
-
[65]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[66]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning. arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
From local to global: A graph rag approach to query-focused summarization, 2025
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization, 2025
2025
-
[68]
Can llm al- ready serve as a database interface? a big bench for large-scale database grounded text-to-sqls
Jinyang Li, Binyuan Hui, Chengwei Qu, Binhua Li, Ruiying Geng, Bowen Li, Bailin Wang, Bowen Qin, Ruiyao Dong, Chenhao Zhang, et al. Can llm al- ready serve as a database interface? a big bench for large-scale database grounded text-to-sqls. InAd- vances in Neural Information Processing Systems, volume 36, 2023
2023
-
[69]
Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu, and Oriol Vinyals
Yujia Li, David Choi, Junyoung Chung, Nate Kush- man, Julian Schrittwieser, Rémi Leblond, Tom Ec- cles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Mas- son d’Autume, Igor Babuschkin, Xinyun Chen, Po- Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson...
2022
-
[70]
Visualwebarena: Evaluating multi- modal agents on realistic visual web tasks, 2024
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multi- modal agents on realistic visual web tasks, 2024
2024
-
[71]
Solving sokoban using hierarchi- cal reinforcement learning with landmarks, 2025
Sergey Pastukhov. Solving sokoban using hierarchi- cal reinforcement learning with landmarks, 2025
2025
-
[72]
Reasoning gym: Reason- ing environments for reinforcement learning with verifiable rewards, 2025
Zafir Stojanovski, Oliver Stanley, Joe Sharratt, Richard Jones, Abdulhakeem Adefioye, Jean Kad- dour, and Andreas Köpf. Reasoning gym: Reason- ing environments for reinforcement learning with verifiable rewards, 2025
2025
-
[73]
Athena scientific, 2012
Dimitri P Bertsekas.Dynamic programming and optimal control: Vol I. Athena scientific, 2012
2012
-
[74]
Foerster, Yannis M
Jakob N. Foerster, Yannis M. Assael, Nando de Fre- itas, and Shimon Whiteson. Learning to communi- cate with deep multi-agent reinforcement learning, 2016
2016
-
[75]
A general reinforcement learn- ing algorithm that masters chess, shogi, and go through self-play.Science, 362(6419):1140–1144, 2018
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis. A general reinforcement learn- ing algorithm that masters chess, shogi, and go through self-play.Science, 362(6419):1140–1144, 2018
2018
-
[76]
Multi-agent actor-critic for mixed cooperative-competitive environments, 2020
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments, 2020
2020
-
[77]
Magent: A many- agent reinforcement learning platform for artificial collective intelligence, 2017
Lianmin Zheng, Jiacheng Yang, Han Cai, Weinan Zhang, Jun Wang, and Yong Yu. Magent: A many- agent reinforcement learning platform for artificial collective intelligence, 2017
2017
-
[78]
Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H
Nolan Bard, Jakob N. Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H. Francis Song, Emilio Parisotto, Vincent Dumoulin, Subhodeep Moitra, Edward Hughes, Iain Dunning, Shibl Mourad, Hugo Larochelle, Marc G. Bellemare, and Michael Bowl- ing. The hanabi challenge: A new frontier for ai research.Artificial Intelligence, 280:103216, 2020
2020
-
[79]
Application of self-play rein- forcement learning to a four-player game of imper- fect information, 2018
Henry Charlesworth. Application of self-play rein- forcement learning to a four-player game of imper- fect information, 2018
2018
-
[80]
Google re- search football: A novel reinforcement learning en- vironment
Karol Kurach, Anton Raichuk, Piotr Sta ´nczyk, Michał Zaj ˛ ac, Olivier Bachem, Lasse Espeholt, Car- los Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet, and Sylvain Gelly. Google re- search football: A novel reinforcement learning en- vironment. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 4501– 4510, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.