Recognition: no theorem link
Training LLMs for Multi-Step Tool Orchestration with Constrained Data Synthesis and Graduated Rewards
Pith reviewed 2026-05-15 00:11 UTC · model grok-4.3
The pith
A reinforcement learning setup using cached real API responses and graduated rewards lets LLMs execute multi-step tool sequences more accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Training LLMs for multi-step tool orchestration with a deterministic environment backed by cached real API responses and a graduated reward that decomposes correctness into atomic validity and orchestration consistency substantially improves turn accuracy on ComplexFuncBench, with both reward components required, and the learned skills transfer to BFCL v4 yielding consistent gains while preserving single-step performance.
What carries the argument
The graduated reward that scores atomic validity of individual calls at increasing levels of granularity together with orchestration consistency that enforces correct sequencing and dependency respect.
Load-bearing premise
The large-scale cache of real API responses is sufficient to create valid multi-step traces that capture the dependency structure and error patterns of live, dynamic APIs.
What would settle it
If models trained this way show no accuracy gain or lose stability when evaluated on a fresh set of APIs whose response distributions are not covered by the cache, the claim that the cached environment produces transferable orchestration skills would be falsified.
Figures




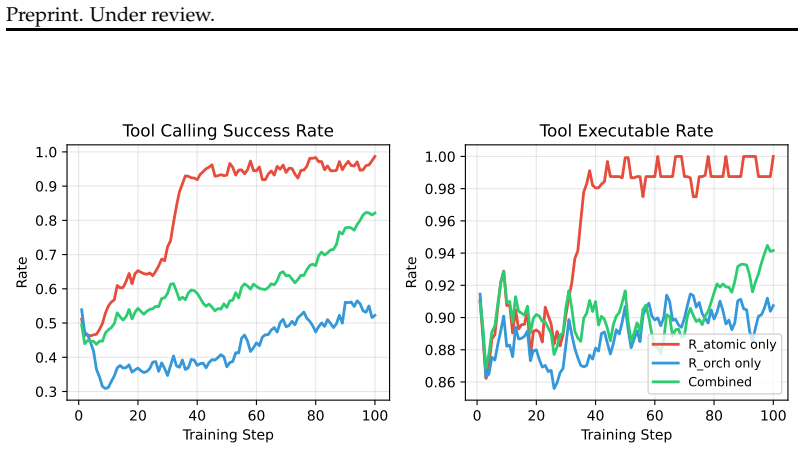
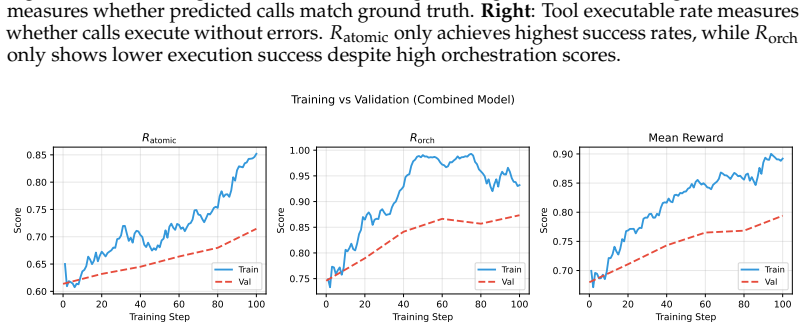
read the original abstract
Multi-step tool orchestration remains challenging for LLMs, as state-of-the-art models frequently fail on full sequence execution due to parameter errors. Training for these workflows faces two obstacles: the lack of environments supporting complex real-world API dependencies, and sparse binary rewards that provide no signal for partial correctness. We propose a reinforcement learning framework addressing both challenges. First, we construct a deterministic environment backed by a large-scale cache of real API responses, enabling constrained synthesis of valid multi-step traces with controllable complexity. Second, we introduce a graduated reward that decomposes correctness into atomic validity (call-level correctness at increasing granularity) and orchestration consistency (correct sequencing with dependency respect). On ComplexFuncBench, our approach substantially improves turn accuracy, with ablations confirming both reward components are essential. Cross-benchmark evaluation on BFCL v4 shows that the learned orchestration skills transfer to entirely different API ecosystems (e.g., agentic web search and memory management), yielding consistent gains while maintaining stable single-step performance. Code is available at https://github.com/horizon-rl/ToolOrchestrationReward
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reinforcement learning framework for training LLMs on multi-step tool orchestration. It constructs a deterministic environment backed by a large-scale cache of real API responses to enable constrained synthesis of valid multi-step traces with controllable complexity, and introduces a graduated reward decomposing correctness into atomic validity (call-level at increasing granularity) and orchestration consistency (sequencing with dependency respect). On ComplexFuncBench the method yields substantial turn accuracy gains with ablations confirming both reward components are essential; cross-benchmark evaluation on BFCL v4 shows transfer of orchestration skills to different API ecosystems while preserving single-step performance. Code is released.
Significance. If the results hold, the work offers a concrete path to denser reward signals and scalable environment construction for training reliable multi-step tool-use agents, addressing two persistent obstacles in LLM agent research. The explicit decomposition of the reward and the demonstration of cross-ecosystem transfer are potentially valuable contributions; the code release further strengthens the paper by enabling direct reproduction and extension.
major comments (1)
- [Environment Construction] Environment Construction section: the central transfer claim on BFCL v4 rests on the assumption that the static cache reproduces live API error patterns, transient failures, rate-limit responses, and state changes closely enough for the graduated reward to produce generalizable policies. No quantitative coverage metrics (fraction of observed live error types reproduced, distributional similarity between cached and live traces) are reported, leaving open the possibility that the deterministic surrogate is easier than real dynamic APIs and that the reported gains are artifacts of this mismatch.
minor comments (2)
- [Abstract] Abstract: reports 'substantial improvements' and 'consistent gains' without any numerical values, baseline comparisons, or error bars, which reduces immediate readability of the magnitude of the claimed advances.
- [Graduated Reward] Reward definition: the exact weighting scheme balancing atomic validity and orchestration consistency, as well as the precise granularity levels used in the atomic component, should be stated explicitly (ideally with pseudocode or equations) to support replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the presentation of our environment construction and transfer claims. We respond to the major comment below.
read point-by-point responses
-
Referee: [Environment Construction] Environment Construction section: the central transfer claim on BFCL v4 rests on the assumption that the static cache reproduces live API error patterns, transient failures, rate-limit responses, and state changes closely enough for the graduated reward to produce generalizable policies. No quantitative coverage metrics (fraction of observed live error types reproduced, distributional similarity between cached and live traces) are reported, leaving open the possibility that the deterministic surrogate is easier than real dynamic APIs and that the reported gains are artifacts of this mismatch.
Authors: We agree that quantitative coverage metrics would strengthen the manuscript. The cache was populated via systematic real API executions across diverse parameter spaces and conditions to capture authentic error patterns, rate-limit behaviors, and state-dependent responses. In the revision we will expand the Environment Construction section with explicit metrics, including the fraction of live error types reproduced in the cache and distributional similarity measures (such as KL divergence or embedding-based comparisons) between cached and live traces, computed from additional validation sampling. These additions will directly support the cross-benchmark transfer results on BFCL v4. We maintain that the deterministic surrogate does not artificially inflate performance, because the graduated reward is computed against the exact cached real responses and the ablations isolate the contribution of the reward components. revision: yes
Circularity Check
No circularity: empirical gains on held-out benchmarks with independent evaluation
full rationale
The paper's central claims are measured improvements in turn accuracy on ComplexFuncBench and transfer gains on BFCL v4, supported by ablations on reward components. The method uses a cached deterministic environment for trace synthesis and a decomposed graduated reward, but no equations or derivations reduce the reported performance metrics to quantities defined by the method's own fitted parameters or self-referential definitions. Results are externally benchmarked and falsifiable, with no load-bearing self-citations or ansatz smuggling identified in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights balancing atomic validity and orchestration consistency
axioms (1)
- domain assumption Cached API responses form a deterministic environment that supports controllable multi-step traces with realistic dependencies
Reference graph
Works this paper leans on
-
[1]
Nestful: A benchmark for evaluating llms on nested sequences of api calls
Kinjal Basu, Ibrahim Abdelaziz, Kiran Kate, Mayank Agarwal, Maxwell Crouse, Yara Rizk, Kelsey Bradford, Asim Munawar, Sadhana Kumaravel, Saurabh Goyal, et al. Nestful: A benchmark for evaluating llms on nested sequences of api calls. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 33526–33535,
2025
-
[2]
Huacan Chai, Zijie Cao, Maolin Ran, Yingxuan Yang, Jianghao Lin, Xin Peng, Hairui Wang, Renjie Ding, Ziyu Wan, Muning Wen, et al. Parl-mt: Learning to call functions in multi- turn conversation with progress awareness.arXiv preprint arXiv:2509.23206,
-
[3]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models. InFindings of the Association for Computational Linguistics ACL 2024, pp. 11143–11156,
2024
-
[5]
Apigen-mt: Agentic pipeline for multi-turn data generation via simulated agent-human interplay
Akshara Prabhakar, Zuxin Liu, Ming Zhu, Jianguo Zhang, Tulika Awalgaonkar, Shiyu Wang, Zhiwei Liu, Haolin Chen, Thai Hoang, Juan Carlos Niebles, et al. Apigen-mt: Agentic pipeline for multi-turn data generation via simulated agent-human interplay. arXiv preprint arXiv:2504.03601,
-
[6]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. Toolrl: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Toolalpaca: Generalized tool learning for language models with 3000 simulated cases
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases. arXiv preprint arXiv:2306.05301,
-
[10]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
10 Preprint. Under review. Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, et al. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning.arXiv preprint arXiv:2504.20073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Seal-tools: Self-instruct tool learning dataset for agent tuning and detailed benchmark
Mengsong Wu, Tong Zhu, Han Han, Chuanyuan Tan, Xiang Zhang, and Wenliang Chen. Seal-tools: Self-instruct tool learning dataset for agent tuning and detailed benchmark. arXiv preprint arXiv:2405.08355,
-
[12]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Qwen An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
URLhttps://api.semanticscholar.org/CorpusID:274859421. Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Lucen Zhong, Zhengxiao Du, Xiaohan Zhang, Haiyi Hu, and Jie Tang. Complexfuncbench: exploring multi-step and constrained function calling under long-context scenario.arXiv preprint arXiv:2501.10132,
-
[16]
Generate user query
A Data Synthesis Algorithm Algorithm 1Constrained Data Synthesis Pipeline Input:Workflow TemplatesT, CacheC, Generator LLMM Output:Synthetic DatasetD syn Build Inverted IndexI:(f, param, val)→ {cache_ids} foreach templateT= (f 1, . . . ,f n)∈ Tdo Initialize empty traceτ= [] forstept=1tondo ifstepthas dependencies on previous outputsthen Extract required v...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.