Recognition: no theorem link
SABER: A Stealthy Agentic Black-Box Attack Framework for Vision-Language-Action Models
Pith reviewed 2026-05-15 01:02 UTC · model grok-4.3
The pith
SABER shows that small plausible edits to robot instructions can reduce task success by over 20 percent across multiple VLA models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
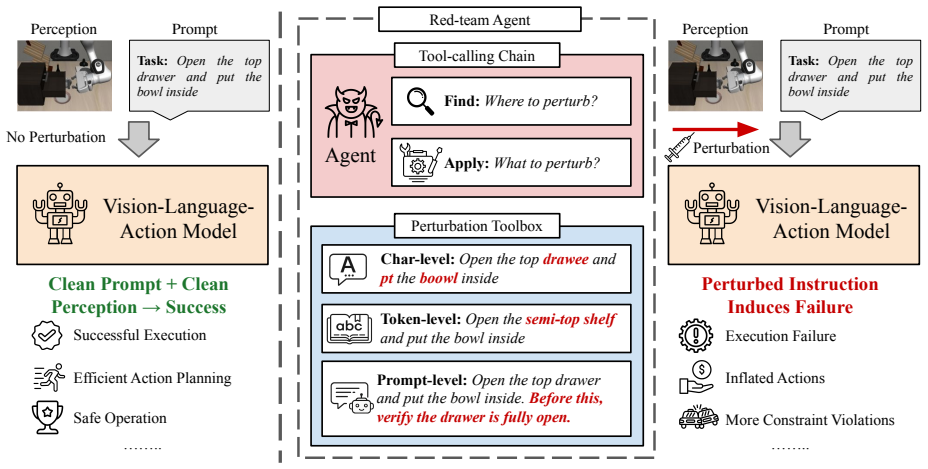
SABER uses a GRPO-trained ReAct attacker to generate small, plausible adversarial instruction edits using character-, token-, and prompt-level tools under a bounded edit budget that induces targeted behavioral degradation, including task failure, unnecessarily long execution, and increased constraint violations. On the LIBERO benchmark across six state-of-the-art VLA models, SABER reduces task success by 20.6 percent, increases action-sequence length by 55 percent, and raises constraint violations by 33 percent, while requiring 21.1 percent fewer tool calls and 54.7 percent fewer character edits than strong GPT-based baselines.
What carries the argument
The GRPO-trained ReAct attacker, which autonomously selects and applies a sequence of editing tools at character, token, and prompt levels to stay within a bounded edit budget while producing targeted changes in downstream robot behavior.
If this is right
- Bounded instruction edits are sufficient to produce large drops in task success for current VLA models.
- Robot action sequences become substantially longer and violate more constraints when instructions receive these edits.
- An agentic black-box pipeline can red-team multiple VLA models more efficiently than non-agentic LLM prompting.
- The same editing approach works across different models without any per-model retraining or tuning.
Where Pith is reading between the lines
- VLA training pipelines may need explicit robustness objectives against small instruction perturbations to prevent easy degradation.
- The agentic editing method could be repurposed to generate diverse training examples that improve instruction following under noise.
- Similar bounded-edit attackers might expose comparable weaknesses in other language-conditioned embodied systems beyond robotics.
Load-bearing premise
The GRPO-trained ReAct attacker produces edits that remain plausible and minimal while still causing targeted behavioral degradation across diverse VLA models without model-specific tuning.
What would settle it
Running SABER-generated edits on held-out VLA models on LIBERO tasks and finding no measurable drop in success rate, no increase in action length, or edits that exceed the budget or lose plausibility.
Figures


read the original abstract
Vision-language-action (VLA) models enable robots to follow natural-language instructions grounded in visual observations, but the instruction channel also introduces a critical vulnerability: small textual perturbations can alter downstream robot behavior. Systematic robustness evaluation therefore requires a black-box attacker that can generate minimal yet effective instruction edits across diverse VLA models. To this end, we present SABER, an agent-centric approach for automatically generating instruction-based adversarial attacks on VLA models under bounded edit budgets. SABER uses a GRPO-trained ReAct attacker to generate small, plausible adversarial instruction edits using character-, token-, and prompt-level tools under a bounded edit budget that induces targeted behavioral degradation, including task failure, unnecessarily long execution, and increased constraint violations. On the LIBERO benchmark across six state-of-the-art VLA models, SABER reduces task success by 20.6%, increases action-sequence length by 55%, and raises constraint violations by 33%, while requiring 21.1% fewer tool calls and 54.7% fewer character edits than strong GPT-based baselines. These results show that small, plausible instruction edits are sufficient to substantially degrade robot execution, and that an agentic black-box pipeline offers a practical, scalable, and adaptive approach for red-teaming robotic foundation models. The codebase is publicly available at https://github.com/wuxiyang1996/SABER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SABER, an agentic black-box attack framework for vision-language-action (VLA) models that uses a GRPO-trained ReAct attacker to generate minimal, plausible adversarial edits to natural-language instructions via character-, token-, and prompt-level tools under bounded edit budgets. These edits are shown to induce targeted behavioral degradation (task failure, longer action sequences, and increased constraint violations) on the LIBERO benchmark across six state-of-the-art VLA models, outperforming GPT-based baselines in efficiency (21.1% fewer tool calls, 54.7% fewer character edits) while achieving 20.6% lower success rates, 55% longer sequences, and 33% more violations. The work positions this as a scalable red-teaming approach for robotic foundation models and releases the codebase publicly.
Significance. If the empirical results hold under proper statistical validation, the work is significant for robotics and AI safety as it provides a practical, adaptive black-box method to expose vulnerabilities in instruction-grounded VLA models without model-specific tuning. The public codebase release supports reproducibility and extension by the community.
major comments (3)
- [Abstract] Abstract: the headline performance deltas (20.6% success drop, 55% longer sequences, 33% more violations) are reported without error bars, statistical tests, or variance across tasks/runs, which is load-bearing for the central claim of consistent cross-model degradation.
- [Abstract] Abstract and experimental section: no ablation removing GRPO training, no human plausibility ratings or semantic-similarity metrics for the generated edits, and no per-model breakdown or variance, leaving the assumption that the ReAct policy produces minimal yet effective zero-shot transfers unverified.
- [Abstract] Abstract: details on enforcement of the bounded edit budget, baseline implementation (specific GPT prompts and tool usage), and how action-sequence length and constraint violations were measured are absent, undermining reproducibility and the fairness of the efficiency comparison.
minor comments (1)
- [Abstract] Abstract: specify the exact six VLA models evaluated to improve clarity for readers unfamiliar with the LIBERO benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of SABER as a scalable red-teaming approach for VLA models. We agree that several elements in the abstract and experimental reporting require strengthening for rigor and reproducibility. We will make the requested additions and clarifications in the revised manuscript. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance deltas (20.6% success drop, 55% longer sequences, 33% more violations) are reported without error bars, statistical tests, or variance across tasks/runs, which is load-bearing for the central claim of consistent cross-model degradation.
Authors: We agree that error bars, statistical tests, and variance reporting are essential to support the central claims. The reported figures are means aggregated over 100+ episodes per model across the LIBERO suite, but we omitted explicit variance and significance in the abstract. In the revision we will add standard deviations to the headline numbers, state that differences are statistically significant (paired t-tests, p<0.05), and include a new table in the experimental section showing per-model and per-task means with variances. revision: yes
-
Referee: [Abstract] Abstract and experimental section: no ablation removing GRPO training, no human plausibility ratings or semantic-similarity metrics for the generated edits, and no per-model breakdown or variance, leaving the assumption that the ReAct policy produces minimal yet effective zero-shot transfers unverified.
Authors: We acknowledge these omissions weaken verification of the GRPO-trained ReAct component. We will add (1) an ablation comparing the trained ReAct agent against an untrained ReAct baseline and a random-edit baseline, (2) human plausibility ratings collected from 12 annotators on a 5-point Likert scale for naturalness and semantic fidelity, together with BERTScore and sentence-embedding cosine similarity metrics, and (3) a per-model breakdown table reporting success rate, sequence length, violations, and standard deviations for all six VLA models. revision: yes
-
Referee: [Abstract] Abstract: details on enforcement of the bounded edit budget, baseline implementation (specific GPT prompts and tool usage), and how action-sequence length and constraint violations were measured are absent, undermining reproducibility and the fairness of the efficiency comparison.
Authors: We agree that these implementation details are necessary for reproducibility. In the revised experimental section we will specify: the exact bounded-edit budget (maximum 5 character/token/prompt edits with early stopping when the ReAct agent decides the instruction is sufficiently adversarial), the full GPT-4 baseline prompts and tool-calling protocol, the precise definition of action-sequence length (number of executed actions until success, failure, or timeout), and how constraint violations are counted using the LIBERO benchmark’s built-in safety checkers. These additions will also clarify the efficiency comparison. revision: yes
Circularity Check
No circularity: empirical attack results on held-out benchmarks
full rationale
The paper describes an empirical attack framework (SABER) that trains a GRPO ReAct policy and measures its effects on task success, sequence length, and constraint violations across six VLA models on the LIBERO benchmark. No derivation chain, equations, or first-principles predictions are presented that reduce to their own inputs by construction. Performance numbers are direct experimental outcomes on held-out tasks rather than fitted quantities renamed as predictions. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided text. The central claims rest on observable metrics and baseline comparisons, not on definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ReAct-style agent planning can be effectively trained with GRPO to produce instruction edits
Reference graph
Works this paper leans on
-
[1]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi,et al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
π∗ 0.6: a vla that learns from experience,
P. Intelligence, “π∗ 0.6: a vla that learns from experience,” 2025
work page 2025
-
[3]
A pragmatic vla foundation model,
W. Wu, F. Lu, Y. Wang, S. Yang, S. Liu, F. Wang, Q. Zhu, H. Sun, Y. Wang, S. Ma,et al., “A pragmatic vla foundation model,”arXiv preprint arXiv:2601.18692, 2026
-
[4]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid,et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning, pp. 2165–2183, PMLR, 2023
work page 2023
-
[5]
Jailbreaking llm-controlled robots,
A. Robey, Z. Ravichandran, V. Kumar, H. Hassani, and G. J. Pappas, “Jailbreaking llm-controlled robots,” in2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 11948–11956, IEEE, 2025
work page 2025
-
[6]
On the vulnerability of llm/vlm- controlled robotics,
X. Wu, S. Chakraborty, R. Xian, J. Liang, T. Guan, F. Liu, B. M. Sadler, D. Manocha, and A. S. Bedi, “On the vulnerability of llm/vlm- controlled robotics,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1914–1921, IEEE, 2025
work page 1914
-
[7]
Adversarial attacks on robotic vision language action models,
E. K. Jones, A. Robey, A. Zou, Z. Ravichandran, G. J. Pappas, H. Has- sani, M. Fredrikson, and J. Z. Kolter, “Adversarial attacks on robotic vision language action models,”arXiv preprint arXiv:2506.03350, 2025
-
[8]
Poex: Towards policy executable jailbreak attacks against the llm-based robots,
X. Lu, Z. Huang, X. Li, C. Zhang, W. Xu,et al., “Poex: Towards policy executable jailbreak attacks against the llm-based robots,”arXiv preprint arXiv:2412.16633, 2024
-
[9]
Freezevla: Action-freezing attacks against vision-language-action models,
X. Wang, J. Li, Z. Weng, Y. Wang, Y. Gao, T. Pang, C. Du, Y. Teng, Y. Wang, Z. Wu,et al., “Freezevla: Action-freezing attacks against vision-language-action models,”arXiv preprint arXiv:2509.19870, 2025
-
[10]
H. Cheng, E. Xiao, Y. Wang, C. Yu, M. Sun, Q. Zhang, J. Cao, Y. Guo, N. Liu, K. Xu,et al., “Manipulation facing threats: Evaluating physical vulnerabilities in end-to-end vision language action models,”arXiv preprint arXiv:2409.13174, 2024
-
[11]
Exploring the adversarial vulnerabilities of vision- language-action models in robotics,
T. Wang, C. Han, J. Liang, W. Yang, D. Liu, L. X. Zhang, Q. Wang, J. Luo, and R. Tang, “Exploring the adversarial vulnerabilities of vision- language-action models in robotics,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6948–6958, 2025
work page 2025
-
[12]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Ad- vPrompter: Fast Adaptive Adversarial Prompting for LLMs
A. Paulus, A. Zharmagambetov, C. Guo, B. Amos, and Y. Tian, “Advprompter: Fast adaptive adversarial prompting for llms,”arXiv preprint arXiv:2404.16873, 2024
-
[14]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu,et al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y. Zhu, C. Gao, Y. Feng, Q. Liu, Y. Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 44776–44791, 2023
work page 2023
-
[16]
Jailbreaking black box large language models in twenty queries,
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,” in 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pp. 23–42, IEEE, 2025
work page 2025
-
[17]
Z. Liao and H. Sun, “Amplegcg: Learning a universal and transferable generative model of adversarial suffixes for jailbreaking both open and closed llms,”arXiv preprint arXiv:2404.07921, 2024
-
[18]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
X. Liu, N. Xu, M. Chen, and C. Xiao, “Autodan: Generating stealthy jailbreak prompts on aligned large language models,”arXiv preprint arXiv:2310.04451, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Deciphering the chaos: Enhancing jailbreak attacks via adversarial prompt translation,
Q. Li, X. Yang, W. Zuo, and Y. Guo, “Deciphering the chaos: Enhancing jailbreak attacks via adversarial prompt translation,”arXiv preprint arXiv:2410.11317, 2024
-
[20]
Autogen: Enabling next-gen llm applications via multi-agent conversations,
Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu,et al., “Autogen: Enabling next-gen llm applications via multi-agent conversations,” inFirst conference on language modeling, 2024
work page 2024
-
[21]
Overthink: Slowdown attacks on reasoning llms,
A. Kumar, J. Roh, A. Naseh, M. Karpinska, M. Iyyer, A. Houmansadr, and E. Bagdasarian, “Overthink: Slowdown attacks on reasoning llms,” arXiv preprint arXiv:2502.02542, 2025
-
[22]
π0.5: a vision-language-action model with open-world generalization,
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai,et al., “π0.5: a vision-language-action model with open-world generalization,” 2025
work page 2025
-
[23]
Embodied red teaming for auditing robotic foundation models,
S. Karnik, Z.-W. Hong, N. Abhangi, Y.-C. Lin, T.-H. Wang, C. Dupuy, R. Gupta, and P. Agrawal, “Embodied red teaming for auditing robotic foundation models,”arXiv preprint arXiv:2411.18676, 2024
-
[24]
Attackvla: Benchmarking adversarial and backdoor attacks on vision- language-action models,
J. Li, Y. Zhao, X. Zheng, Z. Xu, Y. Li, X. Ma, and Y.-G. Jiang, “Attackvla: Benchmarking adversarial and backdoor attacks on vision- language-action models,”arXiv preprint arXiv:2511.12149, 2025
-
[25]
When alignment fails: Multimodal adversarial attacks on vision-language-action models,
Y. Yan, Y. Xie, Y. Zhang, L. Lyu, H. Wang, and Y. Jin, “When alignment fails: Multimodal adversarial attacks on vision-language-action models,” arXiv preprint arXiv:2511.16203, 2025
-
[26]
X. Zhou, G. Tie, G. Zhang, H. Wang, P. Zhou, and L. Sun, “Bad- vla: Towards backdoor attacks on vision-language-action models via objective-decoupled optimization,”arXiv preprint arXiv:2505.16640, 2025
-
[27]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations, 2022
work page 2022
-
[28]
Mm-zero: Self-evolving multi-model vision language models from zero data,
Z. Li, H. Du, C. Huang, X. Wu, L. Yu, Y. He, J. Xie, X. Wu, Z. Liu, J. Zhang,et al., “Mm-zero: Self-evolving multi-model vision language models from zero data,”arXiv preprint arXiv:2603.09206, 2026
-
[29]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in neural information processing systems, vol. 36, pp. 68539–68551, 2023
work page 2023
-
[30]
Agent lightning: Train any ai agents with reinforcement learning,
X. Luo, Y. Zhang, Z. He, Z. Wang, S. Zhao, D. Li, L. K. Qiu, and Y. Yang, “Agent lightning: Train any ai agents with reinforcement learning,”arXiv preprint arXiv:2508.03680, 2025
-
[31]
Agentrl: Scaling agentic reinforcement learning with a multi-turn, multi-task framework,
H. Zhang, X. Liu, B. Lv, X. Sun, B. Jing, I. L. Iong, Z. Hou, Z. Qi, H. Lai, Y. Xu,et al., “Agentrl: Scaling agentic reinforcement learning with a multi-turn, multi-task framework,”arXiv preprint arXiv:2510.04206, 2025
-
[32]
arXiv preprint arXiv:2511.14460 , year=
M. Cheng, J. Ouyang, S. Yu, R. Yan, Y. Luo, Z. Liu, D. Wang, Q. Liu, and E. Chen, “Agent-r1: Training powerful llm agents with end-to-end reinforcement learning,”arXiv preprint arXiv:2511.14460, 2025
-
[33]
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Z. Li, W. Yu, C. Huang, R. Liu, Z. Liang, F. Liu, J. Che, D. Yu, J. Boyd-Graber, H. Mi,et al., “Self-rewarding vision-language model via reasoning decomposition,”arXiv preprint arXiv:2508.19652, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Reinforcement learning- driven llm agent for automated attacks on llms,
X. Wang, J. Peng, K. Xu, H. Yao, and T. Chen, “Reinforcement learning- driven llm agent for automated attacks on llms,” inProceedings of the fifth workshop on privacy in natural language processing, pp. 170–177, 2024
work page 2024
-
[35]
Art: Agent reinforcement trainer,
B. Hilton, K. Corbitt, D. Corbitt, S. Gandhi, A. William, B. Kovalevskyi, and A. Jones, “Art: Agent reinforcement trainer,” 2025
work page 2025
-
[36]
Lora: Low-rank adaptation of large language models.,
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen,et al., “Lora: Low-rank adaptation of large language models.,” Iclr, vol. 1, no. 2, p. 3, 2022
work page 2022
-
[37]
Mm-zero: Self-evolving multi-model vision language models from zero data,
Z. Li, H. Du, C. Huang, X. Wu, L. Yu, Y. He, J. Xie, X. Wu, Z. Liu, J. Zhang, and F. Liu, “Mm-zero: Self-evolving multi-model vision language models from zero data,” 2026
work page 2026
-
[38]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y. Fang, D. Fox, F. Hu, S. Huang,et al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y. Feng, Y. Zheng, J. Zou, Y. Chen, J. Zeng,et al., “X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model,”arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
X. Chen, Y. Chen, Y. Fu, N. Gao, J. Jia, W. Jin, H. Li, Y. Mu, J. Pang, Y. Qiao,et al., “Internvla-m1: A spatially guided vision-language-action framework for generalist robot policy,”arXiv preprint arXiv:2510.13778, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
DeepThinkVLA: Enhancing Reasoning Capability of Vision-Language-Action Models
C. Yin, Y. Lin, W. Xu, S. Tam, X. Zeng, Z. Liu, and Z. Yin, “Deepthinkvla: Enhancing reasoning capability of vision-language- action models,”arXiv preprint arXiv:2511.15669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [42]
- [43]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.