Recognition: 1 theorem link
· Lean TheoremEmergent Neural Automaton Policies: Learning Symbolic Structure from Visuomotor Trajectories
Pith reviewed 2026-05-15 00:04 UTC · model grok-4.3
The pith
A Mealy state machine inferred from raw visuomotor trajectories guides low-level control and raises sample efficiency without task labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
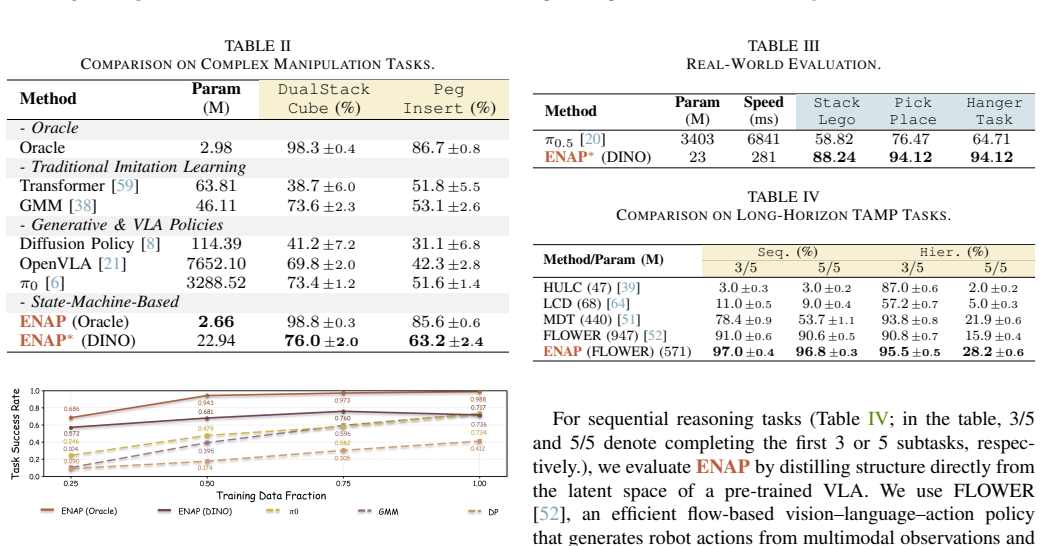
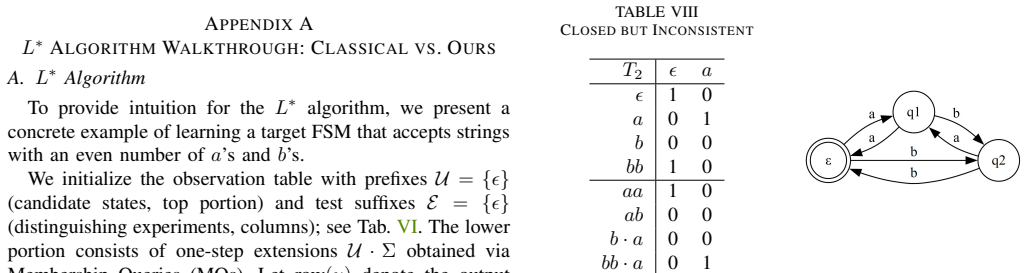
ENAP infers a Mealy state machine from raw visuomotor data by adaptive clustering followed by an extended L* algorithm, yielding states that represent latent task modes; this discrete high-level structure then directs a low-level reactive residual network trained by behavior cloning, delivering up to 27 percent higher success rates than state-of-the-art end-to-end VLA policies in low-data regimes on complex manipulation and long-horizon tasks while supplying an interpretable model of robotic intent.
What carries the argument
The Mealy state machine recovered from visuomotor trajectories via adaptive clustering and extended L* algorithm, which encodes latent task modes as discrete states and transitions to serve as the high-level planner.
If this is right
- Complex long-horizon tasks become solvable with substantially fewer demonstrations than end-to-end methods require.
- The policy produces an explicit, inspectable representation of task structure that can be read without additional post-processing.
- No task-specific labels or auxiliary supervision are needed to obtain the symbolic planner.
- Continuous control accuracy improves because the residual network only learns deviations around the discrete plan.
- The same framework applies across different manipulation and sequential robot tasks without per-task redesign.
Where Pith is reading between the lines
- The discovered automaton could be used directly for model-based planning or safety verification on top of the learned policy.
- Similar unsupervised automata extraction might transfer to other sequential domains such as video understanding or natural-language instruction following.
- If the automaton states prove stable across environments, the high-level structure could support transfer learning between related tasks.
Load-bearing premise
Adaptive clustering plus the extended L* algorithm can recover a Mealy state machine whose states reliably match the latent task modes present in the unlabeled visuomotor trajectories.
What would settle it
If the states of the inferred automaton fail to correspond to distinct, repeatable phases when inspected on held-out trajectories, or if success rates in low-data experiments do not exceed those of end-to-end baselines, the central claim would be falsified.
Figures












read the original abstract
Scaling robot learning to long-horizon tasks remains a formidable challenge. While end-to-end policies often lack the structural priors needed for effective long-term reasoning, traditional neuro-symbolic methods rely heavily on hand-crafted symbolic priors. To address the issue, we introduce ENAP (Emergent Neural Automaton Policy), a framework that allows a bi-level neuro-symbolic policy adaptively emerge from visuomotor demonstrations. Specifically, we first employ adaptive clustering and an extension of the L* algorithm to infer a Mealy state machine from visuomotor data, which serves as an interpretable high-level planner capturing latent task modes. Then, this discrete structure guides a low-level reactive residual network to learn precise continuous control via behavior cloning (BC). By explicitly modeling the task structure with discrete transitions and continuous residuals, ENAP achieves high sample efficiency and interpretability without requiring task-specific labels. Extensive experiments on complex manipulation and long-horizon tasks demonstrate that ENAP outperforms state-of-the-art (SoTA) end-to-end VLA policies by up to 27% in low-data regimes, while offering a structured representation of robotic intent (Fig. 1).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ENAP, a bi-level neuro-symbolic policy framework that infers a Mealy state machine from unlabeled visuomotor trajectories via adaptive clustering and an extended L* algorithm to serve as an interpretable high-level planner; this discrete structure then conditions a low-level residual network trained by behavior cloning. It claims this yields up to 27% higher success than state-of-the-art end-to-end VLA policies in low-data regimes on complex manipulation and long-horizon tasks while providing sample efficiency and interpretability without task-specific labels.
Significance. If the core unsupervised recovery of task-mode-aligned automata is shown to be reliable, the work would offer a concrete route to hybrid neuro-symbolic policies that improve long-horizon reasoning and interpretability in robotics without hand-crafted priors.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the central performance claim of a 27% improvement over SoTA VLA policies is stated without any baseline names, number of trials, statistical tests, ablation studies, or data-regime definitions, rendering the result unverifiable and load-bearing for the paper's contribution.
- [§3.1–3.2] §3.1–3.2: the unsupervised extension of L* relies on clustering-derived signals to replace membership and equivalence queries, yet no explicit algorithm, loss function, or convergence argument is supplied showing that the resulting states correspond to latent dynamics modes rather than spurious visual clusters.
- [§3.2] §3.2, Eq. (X) (inferred automaton): the transition function of the recovered Mealy machine is asserted to guide the residual policy, but without a formal statement of how the discrete state is encoded and injected into the continuous network, it is impossible to assess whether the claimed structure actually constrains the low-level controller.
minor comments (2)
- [Figure 1, §2] Figure 1 caption and §2: the schematic of the bi-level architecture would benefit from explicit arrows indicating how the automaton state is fed to the residual network at each time step.
- [§3] Notation: define the alphabet Σ and output alphabet Γ of the Mealy machine at first use to avoid ambiguity with the visual feature space.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that several aspects of the presentation require strengthening for verifiability and rigor. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the central performance claim of a 27% improvement over SoTA VLA policies is stated without any baseline names, number of trials, statistical tests, ablation studies, or data-regime definitions, rendering the result unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the performance claims must be presented with full experimental details to be verifiable. In the revised manuscript we will name the specific SoTA VLA baselines, report the exact number of trials per task and condition, include statistical significance tests (e.g., paired t-tests with p-values), add ablation studies isolating the automaton component, and explicitly define the low-data regimes by demonstration count. These additions will make the reported gains transparent and reproducible. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2: the unsupervised extension of L* relies on clustering-derived signals to replace membership and equivalence queries, yet no explicit algorithm, loss function, or convergence argument is supplied showing that the resulting states correspond to latent dynamics modes rather than spurious visual clusters.
Authors: We acknowledge that the description of the unsupervised L* extension is insufficiently detailed. The revision will supply the complete algorithm in pseudocode, the precise loss function used for adaptive clustering, and either a convergence sketch or quantitative empirical validation (e.g., state-to-phase alignment metrics) demonstrating that recovered states track latent task dynamics rather than visual artifacts. revision: yes
-
Referee: [§3.2] §3.2, Eq. (X) (inferred automaton): the transition function of the recovered Mealy machine is asserted to guide the residual policy, but without a formal statement of how the discrete state is encoded and injected into the continuous network, it is impossible to assess whether the claimed structure actually constrains the low-level controller.
Authors: We agree that the interface between the discrete automaton and the continuous residual policy requires formal specification. We will add a precise mathematical description of state encoding (e.g., embedding or one-hot vector) and its injection mechanism (e.g., concatenation or conditioning layer) into the low-level network, together with the fully expanded Eq. (X). This will clarify how the high-level structure constrains low-level control. revision: yes
Circularity Check
No significant circularity; derivation relies on standard external algorithms
full rationale
The paper describes a pipeline that applies adaptive clustering followed by an extension of the L* algorithm to extract a Mealy automaton from raw visuomotor trajectories, then uses the resulting discrete structure to condition a residual network trained via behavior cloning. No equations are presented that define performance metrics or state recovery in terms of the outputs themselves, nor are any load-bearing claims justified solely by self-citations whose content reduces to the present work. The central steps invoke well-known algorithms (clustering, L*, BC) whose correctness is independent of the target results and can be evaluated against external benchmarks, so the claimed gains in sample efficiency and interpretability do not reduce to a fitted parameter or self-referential definition by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visuomotor trajectories contain latent discrete task modes discoverable by adaptive clustering without labels.
invented entities (1)
-
Emergent Neural Automaton Policy (ENAP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Finite-state controllers based on mealy machines for cen- tralized and decentralized pomdps
Christopher Amato, Blai Bonet, and Shlomo Zilberstein. Finite-state controllers based on mealy machines for cen- tralized and decentralized pomdps. InProceedings of the AAAI Conference on Artificial Intelligence, volume 24, pages 1052–1058, 2010. 3
work page 2010
-
[2]
Dana Angluin. Learning regular sets from queries and counterexamples.Information and computation, 75(2): 87–106, 1987. 3
work page 1987
-
[3]
Classical planning in deep latent space: Bridging the subsymbolic-symbolic boundary
Masataro Asai and Alex Fukunaga. Classical planning in deep latent space: Bridging the subsymbolic-symbolic boundary. InProceedings of the aaai conference on artificial intelligence, volume 32, 2018. 2
work page 2018
-
[4]
Paul B Badcock, Karl J Friston, Maxwell JD Ramstead, Annemie Ploeger, and Jakob Hohwy. The hierarchically mechanistic mind: an evolutionary systems theory of the human brain, cognition, and behavior.Cognitive, Affective, & Behavioral Neuroscience, 19(6):1319–1351,
-
[5]
Learning task specifications from demonstrations as probabilistic automata
Mattijs Baert, Sam Leroux, and Pieter Simoens. Learning task specifications from demonstrations as probabilistic automata. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8267–8274. IEEE, 2025. 3
work page 2025
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision- language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024. 7, 8, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
A survey of pomdp applica- tions
Anthony R Cassandra. A survey of pomdp applica- tions. InWorking notes of AAAI 1998 fall symposium on planning with partially observable Markov decision processes, volume 1724, 1998. 3
work page 1998
-
[8]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025. 7, 8, 10
work page 2025
-
[9]
Learning neuro-symbolic relational transition models for bilevel planning
Rohan Chitnis, Tom Silver, Joshua B Tenenbaum, Tomas Lozano-Perez, and Leslie Pack Kaelbling. Learning neuro-symbolic relational transition models for bilevel planning. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4166–
-
[10]
Glen Chou, Necmiye Ozay, and Dmitry Berenson. Ex- plaining multi-stage tasks by learning temporal logic formulas from suboptimal demonstrations.arXiv preprint arXiv:2006.02411, 2020. 3
-
[11]
Distributional learning of some context-free languages with a minimally adequate teacher
Alexander Clark. Distributional learning of some context-free languages with a minimally adequate teacher. InInternational Colloquium on Grammatical Inference, pages 24–37. Springer, 2010. 4
work page 2010
-
[12]
Bruno Da Silva, George Konidaris, and Andrew Barto. Learning parameterized skills.arXiv preprint arXiv:1206.6398, 2012. 2
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[13]
Re-understanding finite-state representations of recurrent policy networks, 2021.URL https://arxiv
Mohamad H Danesh, Anurag Koul, Alan Fern, and Saeed Khorram. Re-understanding finite-state representations of recurrent policy networks, 2021.URL https://arxiv. org/abs/2006, 3745. 3
work page 2021
-
[14]
Sahil Rajesh Dhayalkar. Neural networks as universal finite-state machines: A constructive deterministic finite automaton theory.arXiv preprint arXiv:2505.11694,
-
[15]
An analogue of the myhill-nerode theorem and its use in computing finite-basis characterizations
Michael R Fellows and Michael A Langston. An analogue of the myhill-nerode theorem and its use in computing finite-basis characterizations. In30th Annual Symposium on Foundations of Computer Science, pages 520–525. IEEE, 1989. 3
work page 1989
-
[16]
Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning
Caelan Reed Garrett, Tom ´as Lozano-P ´erez, and Leslie Pack Kaelbling. Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning. InProceedings of the international conference on automated planning and scheduling, volume 30, pages 440–448, 2020. 2
work page 2020
-
[17]
Georgios Giantamidis, Stavros Tripakis, and Stylianos Basagiannis. Learning moore machines from input– output traces.International Journal on Software Tools for Technology Transfer, 23(1):1–29, 2021. 3
work page 2021
-
[18]
Learning general- ized reactive policies using deep neural networks
Edward Groshev, Maxwell Goldstein, Aviv Tamar, Sid- dharth Srivastava, and Pieter Abbeel. Learning general- ized reactive policies using deep neural networks. InPro- ceedings of the International Conference on Automated Planning and Scheduling, volume 28, pages 408–416,
-
[19]
Huihui Guo, Fan Wu, Yunchuan Qin, Ruihui Li, Keqin Li, and Kenli Li. Recent trends in task and motion plan- ning for robotics: A survey.ACM Computing Surveys, 55(13s):1–36, 2023. 1
work page 2023
-
[20]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025. 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 1, 2, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
George Konidaris and Andrew Barto. Skill discovery in continuous reinforcement learning domains using skill chaining.Advances in neural information processing systems, 22, 2009. 2
work page 2009
-
[24]
From skills to symbols: Learning sym- bolic representations for abstract high-level planning
George Konidaris, Leslie Pack Kaelbling, and Tomas Lozano-Perez. From skills to symbols: Learning sym- bolic representations for abstract high-level planning. Journal of Artificial Intelligence Research, 61:215–289,
-
[25]
Learning Finite State Representations of Recurrent Policy Networks
Anurag Koul, Sam Greydanus, and Alan Fern. Learning finite state representations of recurrent policy networks. arXiv preprint arXiv:1811.12530, 2018. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Hadas Kress-Gazit, Morteza Lahijanian, and Vasumathi Raman. Synthesis for robots: Guarantees and feedback for robot behavior.Annual Review of Control, Robotics, and Autonomous Systems, 1(1):211–236, 2018. 3
work page 2018
-
[27]
Sanjay Krishnan, Animesh Garg, Sachin Patil, Colin Lea, Gregory Hager, Pieter Abbeel, and Ken Goldberg. Tran- sition state clustering: Unsupervised surgical trajectory segmentation for robot learning.The International jour- nal of robotics research, 36(13-14):1595–1618, 2017. 2
work page 2017
-
[28]
Bilevel learning for bilevel planning.arXiv preprint arXiv:2502.08697, 2025
Bowen Li, Tom Silver, Sebastian Scherer, and Alexander Gray. Bilevel learning for bilevel planning.arXiv preprint arXiv:2502.08697, 2025. 2
-
[29]
The equivalence between fuzzy mealy and fuzzy moore machines.Soft Computing, 10(10):953–959, 2006
Yongming Li and Witold Pedrycz. The equivalence between fuzzy mealy and fuzzy moore machines.Soft Computing, 10(10):953–959, 2006. 3
work page 2006
-
[30]
Few-shot neuro-symbolic imitation learning for long-horizon planning and acting
Pierrick Lorang, Hong Lu, Johannes Huemer, Patrik Zips, and Matthias Scheutz. Few-shot neuro-symbolic imitation learning for long-horizon planning and acting. arXiv preprint arXiv:2508.21501, 2025. 2
-
[31]
Cambridge University Press, 2009
Jan Lunze and Franc ¸oise Lamnabhi-Lagarrigue.Hand- book of hybrid systems control: theory, tools, applica- tions. Cambridge University Press, 2009. 2
work page 2009
-
[32]
Xusheng Luo and Changliu Liu. Simultaneous task al- location and planning for multi-robots under hierarchical temporal logic specifications.IEEE Transactions on Robotics, 2025. 3
work page 2025
-
[33]
Online planner selection with graph neural networks and adaptive scheduling
Tengfei Ma, Patrick Ferber, Siyu Huo, Jie Chen, and Michael Katz. Online planner selection with graph neural networks and adaptive scheduling. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5077–5084, 2020. 2
work page 2020
-
[34]
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision-language- action models for embodied ai.arXiv preprint arXiv:2405.14093, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Steven Macenski, Tully Foote, Brian Gerkey, Chris Lalancette, and William Woodall. Robot operating sys- tem 2: Design, architecture, and uses in the wild.Science robotics, 7(66):eabm6074, 2022. 2
work page 2022
-
[36]
Jiayuan Mao, Chuang Gan, Pushmeet Kohli, Joshua B Tenenbaum, and Jiajun Wu. The neuro-symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision.arXiv preprint arXiv:1904.12584,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[37]
Hdbscan: Hierarchical density based clustering.Journal of Open Source Software, 2(11):205, 2017
Leland McInnes, John Healy, and Steve Astels. Hdbscan: Hierarchical density based clustering.Journal of Open Source Software, 2(11):205, 2017. 4
work page 2017
-
[38]
Geoffrey J McLachlan and Suren Rathnayake. On the number of components in a gaussian mixture model.Wi- ley Interdisciplinary Reviews: Data Mining and Knowl- edge Discovery, 4(5):341–355, 2014. 7, 8, 10
work page 2014
-
[39]
Oier Mees, Lukas Hermann, and Wolfram Burgard. What matters in language conditioned robotic imitation learning over unstructured data.IEEE Robotics and Automation Letters, 7(4):11205–11212, 2022. 7, 8
work page 2022
-
[40]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot ma- nipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022. 7
work page 2022
-
[41]
Interpretable machine learning–a brief history, state- of-the-art and challenges
Christoph Molnar, Giuseppe Casalicchio, and Bernd Bis- chl. Interpretable machine learning–a brief history, state- of-the-art and challenges. InJoint European confer- ence on machine learning and knowledge discovery in databases, pages 417–431. Springer, 2020. 2
work page 2020
-
[42]
Tong Mu, Yihao Liu, and Mehran Armand. Look before you leap: Using serialized state machine for lan- guage conditioned robotic manipulation.arXiv preprint arXiv:2503.05114, 2025. 3
-
[43]
Tongzhou Mu, Zhan Ling, Fanbo Xiang, Derek Yang, Xuanlin Li, Stone Tao, Zhiao Huang, Zhiwei Jia, and Hao Su. Maniskill: Generalizable manipulation skill bench- mark with large-scale demonstrations.arXiv preprint arXiv:2107.14483, 2021. 7
-
[44]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marcin Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaa El- Nouby, and Mahmoud Assran. Dinov2: Learning ro- bust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Yiyuan Pan, Zhe Liu, and Hesheng Wang. Wonder wins ways: Curiosity-driven exploration through multi-agent contextual calibration.arXiv preprint arXiv:2509.20648,
-
[46]
Yiyuan Pan, Yunzhe Xu, Zhe Liu, and Hesheng Wang. Planning from imagination: Episodic simulation and episodic memory for vision-and-language navigation. In Proceedings of the AAAI Conference on Artificial Intel- ligence, volume 39, pages 6345–6353, 2025. 2
work page 2025
-
[47]
Yiyuan Pan, Yunzhe Xu, Zhe Liu, and Hesheng Wang. Seeing through uncertainty: Robust task-oriented optimization in visual navigation.arXiv preprint arXiv:2510.00441, 2025. 1
-
[48]
Hanna M Pasula, Luke S Zettlemoyer, and Leslie Pack Kaelbling. Learning symbolic models of stochastic domains.Journal of Artificial Intelligence Research, 29: 309–352, 2007. 2
work page 2007
-
[49]
Accel- erating reinforcement learning with learned skill priors
Karl Pertsch, Youngwoon Lee, and Joseph Lim. Accel- erating reinforcement learning with learned skill priors. InConference on robot learning, pages 188–204. PMLR,
-
[50]
Michael Poli, Stefano Massaroli, Luca Scimeca, Sanghyuk Chun, Seong Joon Oh, Atsushi Yamashita, Hajime Asama, Jinkyoo Park, and Animesh Garg. Neural hybrid automata: Learning dynamics with multiple modes and stochastic transitions.Advances in Neural Information Processing Systems, 34:9977–9989,
-
[51]
Moritz Reuss, ¨Omer Erdinc ¸ Ya˘gmurlu, Fabian Wenzel, and Rudolf Lioutikov. Multimodal diffusion transformer: Learning versatile behavior from multimodal goals.arXiv preprint arXiv:2407.05996, 2024. 7, 8
-
[52]
Moritz Reuss, Hongyi Zhou, Marcel R ¨uhle, ¨Omer Erdinc ¸ Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. Flower: Democratizing generalist robot policies with efficient vision-language-action flow policies.arXiv preprint arXiv:2509.04996, 2025. 7, 8
-
[53]
Robovqa: Multimodal long-horizon reasoning for robotics
Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Chris- tine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, et al. Robovqa: Multimodal long-horizon reasoning for robotics. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 645–652. IEEE, 2024. 1
work page 2024
-
[54]
Supervised bayesian specification inference from demonstrations
Ankit Shah, Pritish Kamath, Shen Li, Patrick Craven, Kevin Landers, Kevin Oden, and Julie Shah. Supervised bayesian specification inference from demonstrations. The International Journal of Robotics Research, 42(14): 1245–1264, 2023. 2
work page 2023
-
[55]
Muzammil Shahbaz and Roland Groz. Inferring mealy machines. InInternational Symposium on Formal Meth- ods, pages 207–222. Springer, 2009. 3
work page 2009
-
[56]
PhD thesis, Massachusetts Institute of Tech- nology, 2024
Tom Silver.Neuro-Symbolic Learning for Bilevel Robot Planning. PhD thesis, Massachusetts Institute of Tech- nology, 2024. 2
work page 2024
-
[57]
Planning with learned object importance in large problem instances using graph neural networks
Tom Silver, Rohan Chitnis, Aidan Curtis, Joshua B Tenenbaum, Tom´as Lozano-P´erez, and Leslie Pack Kael- bling. Planning with learned object importance in large problem instances using graph neural networks. InPro- ceedings of the AAAI conference on artificial intelligence, volume 35, pages 11962–11971, 2021. 2
work page 2021
-
[58]
Learning neuro-symbolic skills for bilevel planning.arXiv preprint arXiv:2206.10680, 2022
Tom Silver, Ashay Athalye, Joshua B Tenenbaum, Tom´as Lozano-P´erez, and Leslie Pack Kaelbling. Learning neuro-symbolic skills for bilevel planning.arXiv preprint arXiv:2206.10680, 2022. 2
-
[59]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 7, 8
work page 2017
-
[60]
Marcell Vazquez-Chanlatte, Susmit Jha, Ashish Tiwari, Mark K Ho, and Sanjit Seshia. Learning task spec- ifications from demonstrations.Advances in neural information processing systems, 31, 2018. 3
work page 2018
-
[61]
Yanwei Wang, Nadia Figueroa, Shen Li, Ankit Shah, and Julie Shah. Temporal logic imitation: Learning plan- satisficing motion policies from demonstrations.arXiv preprint arXiv:2206.04632, 2022. 2
-
[62]
Extracting weighted finite automata from recurrent neural networks for natural languages
Zeming Wei, Xiyue Zhang, and Meng Sun. Extracting weighted finite automata from recurrent neural networks for natural languages. InInternational Conference on Formal Engineering Methods, pages 370–385. Springer,
-
[63]
Latmos: Latent automaton task model from observation sequences.arXiv preprint arXiv:2503.08090, 2025
Weixiao Zhan, Qiyue Dong, Eduardo Sebasti ´an, and Nikolay Atanasov. Latmos: Latent automaton task model from observation sequences.arXiv preprint arXiv:2503.08090, 2025. 3
-
[64]
Edwin Zhang, Yujie Lu, William Wang, and Amy Zhang. Language control diffusion: Efficiently scaling through space, time, and tasks.arXiv preprint arXiv:2210.15629,
-
[65]
Au- tomata extraction from transformers.arXiv preprint arXiv:2406.05564, 2024
Yihao Zhang, Zeming Wei, and Meng Sun. Au- tomata extraction from transformers.arXiv preprint arXiv:2406.05564, 2024. 3
-
[66]
lower” path (τ 1) correctly but still misinterprets the “upper
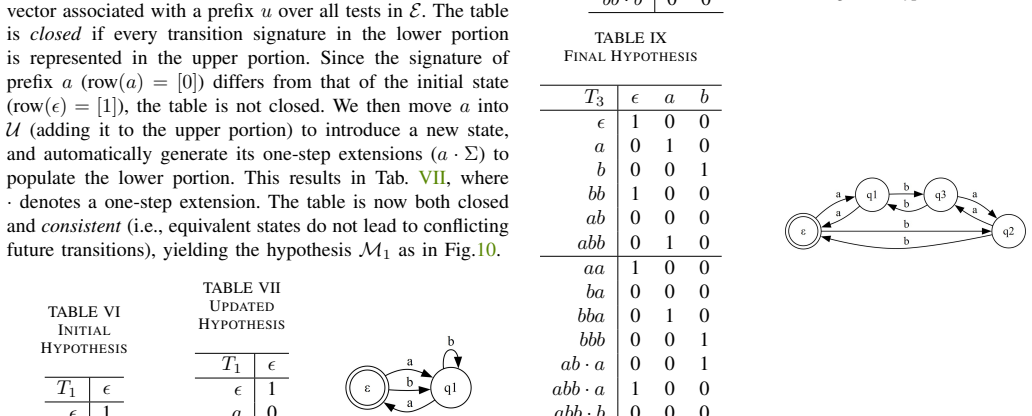
Zhigen Zhao, Shuo Cheng, Yan Ding, Ziyi Zhou, Shiqi Zhang, Danfei Xu, and Ye Zhao. A survey of optimization-based task and motion planning: From clas- sical to learning approaches.IEEE/ASME Transactions on Mechatronics, 2024. 1 APPENDIXA L∗ ALGORITHMWALKTHROUGH: CLASSICAL VS. OURS A.L ∗ Algorithm To provide intuition for theL ∗ algorithm, we present a con...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.