Recognition: unknown
FireBridge: Cycle-Accurate Hardware + Firmware Co-Verification for Modern Accelerators
Pith reviewed 2026-05-14 23:54 UTC · model grok-4.3
The pith
FireBridge compiles production firmware for x86 and connects it to RTL simulations through randomized memory bridges to enable cycle-accurate co-verification in seconds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FireBridge bridges x86-compiled production firmware with RTL or gate-level hardware simulations via randomized memory bridges, delivering cycle-accurate co-verification, off-chip profiling, and memory congestion emulation that maintains functional equivalence and yields up to 50x faster debug iterations than FPGA-based flows.
What carries the argument
Randomized memory bridges that emulate off-chip data movement, congestion, and register protocols between x86 firmware and simulated hardware subsystems.
If this is right
- Firmware debugging, profiling, and register-level protocol testing occur directly inside standard simulators such as VCS or Vivado.
- Off-chip data movement and memory congestion can be profiled and emulated during verification.
- Functional equivalence holds across accelerator types including systolic arrays and CGRAs.
- Hardware and firmware teams can develop and test in parallel before physical prototypes exist.
Where Pith is reading between the lines
- Teams could begin full system integration checks earlier in the design schedule, before any FPGA hardware is available.
- The same bridge technique might apply to other simulation backends or to modeling additional timing jitter sources.
- Verification labs could reduce dependence on dedicated FPGA boards for routine debug cycles.
Load-bearing premise
The x86-compiled firmware and randomized memory bridges exactly reproduce the cycle-accurate timing and functional behavior of the actual embedded firmware and hardware without discrepancies.
What would settle it
A side-by-side run that produces mismatched cycle counts, incorrect data outputs, or timing violations between a FireBridge simulation and an equivalent FPGA emulation for the same accelerator design and firmware.
Figures






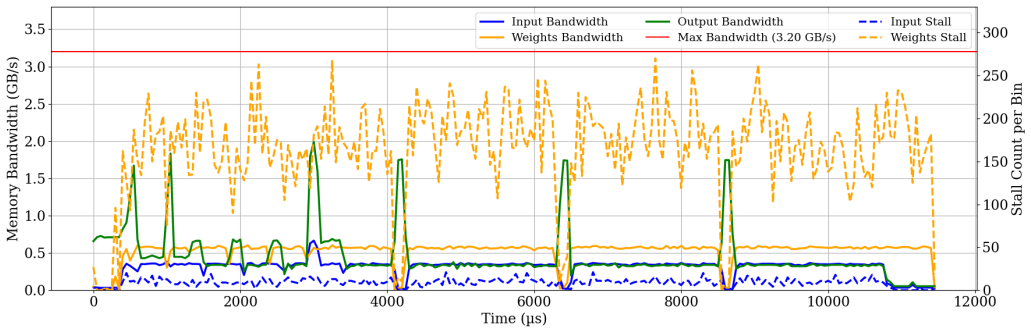

read the original abstract
Hardware-firmware integration is becoming a productivity bottleneck due to the increasing complexity of accelerators, characterized by intricate memory hierarchies and firmware-intensive execution. While numerous verification techniques focus on early-stage, approximate modeling of such systems to speed up initial development, developers still rely heavily on FPGA emulation to integrate firmware with RTL/HLS hardware, resulting in significant delays in debug iterations and time-to-market. We present a fast, cycle-accurate co-verification framework that bridges production firmware and RTL/gate-level hardware. FIREBRIDGE enables firmware debugging, profiling, and verification in seconds using standard simulators such as VCS, Vivado Xsim, or Xcelium, by compiling the firmware for x86 and bridging it with simulated subsystems via randomized memory bridges. Our approach provides off-chip data movement profiling, memory congestion emulation, and register-level protocol testing, which are critical for modern accelerator verification. We demonstrate a speedup of up to 50x in debug iteration over the conventional FPGA-based flow for system integration between RTL/HLS and production firmware on various types of accelerators, such as systolic arrays and CGRAs, while ensuring functional equivalence. FIREBRIDGE accelerates system integration by supporting robust co-verification of hardware and firmware, and promotes a structured, parallel development workflow tailored for teams building heterogeneous computing platforms. Repository: https://github.com/abarajithan11/axis-systolic-array/tree/master/firebridge
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FireBridge, a co-verification framework that compiles production firmware to x86 and connects it to RTL/gate-level hardware simulations via randomized memory bridges inside standard simulators (VCS, Vivado Xsim, Xcelium). It claims this yields up to 50x faster debug iterations than conventional FPGA-based flows for accelerators such as systolic arrays and CGRAs while preserving functional equivalence, with additional features for off-chip data movement profiling and memory congestion emulation.
Significance. If the speedup and equivalence claims are rigorously supported, the approach could substantially reduce the hardware-firmware integration bottleneck for heterogeneous accelerators by enabling rapid simulation-based debugging. The public repository link is a positive factor for reproducibility and potential community adoption.
major comments (2)
- [Abstract] Abstract: the claim of 'up to 50x speedup in debug iteration' is stated without any benchmark methodology, error analysis, or tabulated comparison data (e.g., wall-clock times, number of iterations, or variance across runs), preventing evaluation of the quantitative result.
- [Framework description] Framework description (randomized memory bridges and x86 firmware sections): no side-by-side cycle-accurate trace comparison, latency histogram, or formal argument is supplied to show that the substitutions preserve exact cycle counts, memory-hierarchy contention, and protocol timing of the embedded target; randomization can alter access ordering and x86 compilation changes cache and interrupt semantics.
minor comments (2)
- The repository URL is given but the manuscript does not state the exact commit or tag used for the reported experiments; add this for reproducibility.
- Clarify whether the 'randomized memory bridges' are purely stochastic or seeded, and how they emulate deterministic SoC memory hierarchies.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and rigor of our presentation. We address each major comment point by point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'up to 50x speedup in debug iteration' is stated without any benchmark methodology, error analysis, or tabulated comparison data (e.g., wall-clock times, number of iterations, or variance across runs), preventing evaluation of the quantitative result.
Authors: We agree that the abstract would benefit from additional context on the speedup claim. The experimental results section of the manuscript already contains the underlying data (wall-clock times for debug iterations on systolic arrays and CGRAs, comparison against FPGA flows, and multiple-run measurements), but we will revise the abstract to briefly summarize the benchmark methodology, reference the specific tables/figures with tabulated comparisons, and note the observed variance across runs. This will allow readers to evaluate the 50x figure without needing to consult the full experiments section first. revision: yes
-
Referee: [Framework description] Framework description (randomized memory bridges and x86 firmware sections): no side-by-side cycle-accurate trace comparison, latency histogram, or formal argument is supplied to show that the substitutions preserve exact cycle counts, memory-hierarchy contention, and protocol timing of the embedded target; randomization can alter access ordering and x86 compilation changes cache and interrupt semantics.
Authors: We appreciate this observation on the need for explicit verification of cycle accuracy. The randomized memory bridges are designed to preserve exact cycle counts and protocol timing by replaying accesses with fixed latencies and contention emulation while randomizing only non-timing-critical aspects (e.g., data values within valid ranges). However, we acknowledge that the current manuscript lacks side-by-side trace comparisons and latency histograms. In the revision we will add these visualizations from our test cases, along with a concise formal argument explaining why randomization does not affect ordering or contention under the bridge's constraints. We will also clarify our handling of x86-specific effects (cache disabling via compiler flags and explicit interrupt emulation through the bridge) to address potential semantic differences. revision: yes
Circularity Check
No circularity: practical engineering demonstration with external validation
full rationale
The paper describes a co-verification framework and reports an empirical 50x speedup on systolic arrays and CGRAs via an external GitHub repository. No equations, fitted parameters, or derivation steps appear in the provided text. The central claim rests on stated engineering substitutions (x86 firmware compilation and randomized memory bridges) rather than any self-referential definition, prediction-from-fit, or load-bearing self-citation chain. The speedup result is presented as a measured outcome of the implemented system, not a quantity forced by prior fitted values or renamed known results. This is a standard non-circular engineering paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on deep learning hardware accelerators for heterogeneous hpc platforms,
C. Silvano, D. Ielmini, F. Ferrandi, L. Fiorin, S. Curzel, L. Benini, F. Conti, A. Garofalo, C. Zambelli, E. Calore, S. Schifano, M. Palesi, G. Ascia, D. Patti, N. Petra, D. De Caro, L. Lavagno, T. Urso, V . Cardellini, G. Cardarilli, R. Birke, and S. Perri, “A survey on deep learning hardware accelerators for heterogeneous hpc platforms,” ACM Comput. Sur...
-
[2]
Smaug: End-to-end full-stack simulation infrastructure for deep learn- ing workloads,
S. Xi, Y . Yao, K. Bhardwaj, P. Whatmough, G.-Y . Wei, and D. Brooks, “Smaug: End-to-end full-stack simulation infrastructure for deep learn- ing workloads,”ACM Transactions on Architecture and Code Optimiza- tion (TACO), vol. 17, no. 4, pp. 1–26, 2020
work page 2020
-
[3]
gem5-accel: A pre- rtl simulation toolchain for accelerator architecture validation,
J. Vieira, N. Roma, G. Falcao, and P. Tom ´as, “gem5-accel: A pre- rtl simulation toolchain for accelerator architecture validation,”IEEE Computer Architecture Letters, 2023
work page 2023
-
[4]
N. Binkert, B. Beckmann, G. Black, S. K. Reinhardt, A. Saidi, A. Basu, J. Hestness, D. R. Hower, T. Krishna, S. Sardashtiet al., “The gem5 simulator,”ACM SIGARCH computer architecture news, vol. 39, no. 2, pp. 1–7, 2011
work page 2011
-
[5]
1.1 computing’s energy problem (and what we can do about it),
M. Horowitz, “1.1 computing’s energy problem (and what we can do about it),” in2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 2014, pp. 10–14
work page 2014
-
[6]
T. Benz, A. Ottaviano, C. Liang, R. Balas, A. Garofalo, F. Restuccia, A. Biondi, D. Rossi, and L. Benini, “Axi-realm: Safe, modular and lightweight traffic monitoring and regulation for heterogeneous mixed- criticality systems,”arXiv preprint arXiv:2501.10161, 2025
-
[7]
The main memory system: Challenges and opportunities,
O. Mutlu, J. Meza, and L. Subramanian, “The main memory system: Challenges and opportunities,” 2015
work page 2015
-
[8]
J. Park, M. Naumov, P. Basu, S. Deng, A. Kalaiah, D. Khudia, J. Law, P. Malani, A. Malevich, S. Nadathuret al., “Deep learning inference in facebook data centers: Characterization, performance optimizations and hardware implications,”arXiv preprint arXiv:1811.09886, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
J. Cong, Z. Fang, M. Gill, and G. Reinman, “Parade: A cycle-accurate full-system simulation platform for accelerator-rich architectural design and exploration,” in2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), ser. ICCAD ’15. IEEE Press, 2015, p. 380–387
work page 2015
-
[10]
Stonne: Enabling cycle-level microarchitectural simulation for dnn inference accelerators,
F. Mu ˜noz-Mart´ınez, J. L. Abell ´an, M. E. Acacio, and T. Krishna, “Stonne: Enabling cycle-level microarchitectural simulation for dnn inference accelerators,” in2021 IEEE International Symposium on Workload Characterization (IISWC). IEEE, 2021, pp. 201–213
work page 2021
-
[11]
SCALE-Sim: Systolic CNN Accelerator Simulator
A. Samajdar, Y . Zhu, P. Whatmough, M. Mattina, and T. Kr- ishna, “Scale-sim: Systolic cnn accelerator simulator,”arXiv preprint arXiv:1811.02883, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Lambda: An open framework for deep neural network accelerators simulation,
E. Russo, M. Palesi, S. Monteleone, D. Patti, G. Ascia, and V . Catania, “Lambda: An open framework for deep neural network accelerators simulation,” in2021 IEEE International Conference on Pervasive Com- puting and Communications Workshops and other Affiliated Events (PerCom Workshops), 2021, pp. 161–166
work page 2021
-
[13]
Firesim: Fpga- accelerated cycle-exact scale-out system simulation in the public cloud,
S. Karandikar, H. Mao, D. Kim, D. Biancolin, A. Amid, D. Lee, N. Pemberton, E. Amaro, C. Schmidt, A. Chopraet al., “Firesim: Fpga- accelerated cycle-exact scale-out system simulation in the public cloud,” in2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2018, pp. 29–42
work page 2018
-
[14]
Fast inference of deep neural networks in FPGAs for particle physics,
J. Duarteet al., “Fast inference of deep neural networks in FPGAs for particle physics,”JINST, vol. 13, no. 07, p. P07027, 2018
work page 2018
-
[15]
Esp4ml: Platform-based design of systems-on-chip for embedded machine learning,
D. Giri, K.-L. Chiu, G. Di Guglielmo, P. Mantovani, and L. P. Car- loni, “Esp4ml: Platform-based design of systems-on-chip for embedded machine learning,” in2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), 2020, pp. 1049–1054
work page 2020
-
[16]
The aladdin approach to accelerator design and modeling,
Y . S. Shao, B. Reagen, G.-Y . Wei, and D. Brooks, “The aladdin approach to accelerator design and modeling,”IEEE Micro, vol. 35, no. 3, pp. 58– 70, 2015
work page 2015
-
[17]
Co- designing accelerators and soc interfaces using gem5-aladdin,
Y . S. Shao, S. L. Xi, V . Srinivasan, G.-Y . Wei, and D. Brooks, “Co- designing accelerators and soc interfaces using gem5-aladdin,” in2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2016, pp. 1–12
work page 2016
-
[18]
W. Won, T. Heo, S. Rashidi, S. Sridharan, S. Srinivasan, and T. Kr- ishna, “Astra-sim2.0: Modeling hierarchical networks and disaggregated systems for large-model training at scale,” in2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2023, pp. 283–294
work page 2023
-
[19]
X. Yi, J. Yu, Z. Wu, X. Xiong, D. Xu, C. Chen, J. Tao, and F. Yang, “Nnasim: An efficient event-driven simulator for dnn accelerators with accurate timing and area models,” in2022 IEEE International Sympo- sium on Circuits and Systems (ISCAS), 2022, pp. 2806–2810
work page 2022
-
[20]
Timeloop: A systematic approach to dnn accelerator evaluation,
A. Parashar, P. Raina, Y . S. Shao, Y .-H. Chen, V . A. Ying, A. Mukkara, R. Venkatesan, B. Khailany, S. W. Keckler, and J. Emer, “Timeloop: A systematic approach to dnn accelerator evaluation,” in2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2019, pp. 304–315
work page 2019
-
[21]
Accelergy: An architecture- level energy estimation methodology for accelerator designs,
Y . N. Wu, J. S. Emer, and V . Sze, “Accelergy: An architecture- level energy estimation methodology for accelerator designs,” in2019 IEEE/ACM International Conference on Computer-Aided Design (IC- CAD), 2019, pp. 1–8
work page 2019
-
[22]
Accelerating rtl simulation with hardware-software co-design,
F. Elsabbagh, S. Sheikhha, V . A. Ying, Q. M. Nguyen, J. S. Emer, and D. Sanchez, “Accelerating rtl simulation with hardware-software co-design,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 153–166. [Online]. Available: https://doi...
-
[23]
I. Corporation, “Intel® cofluent™ studio,” https://www.intel.com/ content/www/us/en/cofluent/cofluent-studio.html, accessed: 2025-04-20
work page 2025
-
[24]
Hepsim: An esl hw/sw co-simulator/analysis tool for heterogeneous parallel embedded systems,
D. Ciambrone, V . Muttillo, L. Pomante, and G. Valente, “Hepsim: An esl hw/sw co-simulator/analysis tool for heterogeneous parallel embedded systems,” in2018 7th Mediterranean Conference on Embedded Com- puting (MECO), 2018, pp. 1–6
work page 2018
-
[25]
Hepsycode-rt: A real-time extension for an esl hw/sw co-design methodology,
V . Muttillo, G. Valente, D. Ciambrone, V . Stoico, and L. Pomante, “Hepsycode-rt: A real-time extension for an esl hw/sw co-design methodology,” inProceedings of the Rapido’18 Workshop on Rapid Simulation and Performance Evaluation: Methods and Tools, 2018, pp. 1–6
work page 2018
-
[26]
Chipyard: Integrated design, simulation, and implementation framework for custom socs,
A. Amid, D. Biancolin, A. Gonzalez, D. Grubb, S. Karandikar, H. Liew, A. Magyar, H. Mao, A. Ou, N. Pembertonet al., “Chipyard: Integrated design, simulation, and implementation framework for custom socs,” IEEE Micro, vol. 40, no. 4, pp. 10–21, 2020
work page 2020
-
[27]
Integrating nvidia deep learning accelerator (nvdla) with risc-v soc on firesim,
F. Farshchi, Q. Huang, and H. Yun, “Integrating nvidia deep learning accelerator (nvdla) with risc-v soc on firesim,” in2019 2nd Workshop on Energy Efficient Machine Learning and Cognitive Computing for Embedded Applications (EMC2). IEEE, 2019, pp. 21–25
work page 2019
-
[28]
D. Nikiforov, S. C. Dong, C. L. Zhang, S. Kim, B. Nikolic, and Y . S. Shao, “Ros´E: A hardware-software co-simulation infrastructure enabling pre-silicon full-stack robotics soc evaluation,” inProceedings of the 50th Annual International Symposium on Computer Architecture, ser. ISCA ’23. New York, NY , USA: Association for Computing Machinery,
-
[29]
Available: https://doi.org/10.1145/3579371.3589099
[Online]. Available: https://doi.org/10.1145/3579371.3589099
-
[30]
Amd zynq ultrascale+ mpsoc zcu102 evaluation kit,
AMD, “Amd zynq ultrascale+ mpsoc zcu102 evaluation kit,” https://www.amd.com/en/products/adaptive-socs-and-fpgas/evaluation- boards/ek-u1-zcu102-g.html, 2024, accessed: 2025-04-20
work page 2024
-
[31]
Aws trainium research program,
Amazon Web Services, “Aws trainium research program,” https://aws. amazon.com/ai/machine-learning/trainium/research/, 2024, accessed: 2025-04-20
work page 2024
-
[32]
The design process for google’s training chips: Tpuv2 and tpuv3,
T. Norrie, N. Patil, D. H. Yoon, G. Kurian, S. Li, J. Laudon, C. Young, N. Jouppi, and D. Patterson, “The design process for google’s training chips: Tpuv2 and tpuv3,”IEEE Micro, vol. 41, no. 2, pp. 56–63, 2021
work page 2021
-
[33]
Intel Gaudi 3 AI Accelerator: Architected for Gen AI Training and Inference ,
R. Kaplan, “ Intel Gaudi 3 AI Accelerator: Architected for Gen AI Training and Inference ,” in2024 IEEE Hot Chips 36 Symposium (HCS). Los Alamitos, CA, USA: IEEE Computer Society, Aug. 2024, pp. 1–16. [Online]. Available: https://doi.ieeecomputersociety.org/10. 1109/HCS61935.2024.10665178
-
[34]
Tenstorrent overview: Products and software,
M. Bahnas, “Tenstorrent overview: Products and software,” https://icl.utk.edu/newsletter/presentations/2024/mohamed-bahnas- 2024-03-22.pdf, Mar. 2024, presentation at the University of Tennessee, Knoxville
work page 2024
-
[35]
Autosa: A polyhedral compiler for high-performance systolic arrays on fpga,
J. Wang, L. Guo, and J. Cong, “Autosa: A polyhedral compiler for high-performance systolic arrays on fpga,” inThe 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, ser. FPGA ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 93–104. [Online]. Available: https://doi.org/10. 1145/3431920.3439292
-
[36]
H. Genc, A. Haj-Ali, V . Iyer, A. Amid, H. Mao, J. Wright, C. Schmidt, J. Zhao, A. Ou, M. Banisteret al., “Gemmini: An agile systolic array generator enabling systematic evaluations of deep-learning architec- tures,”arXiv preprint arXiv:1911.09925, vol. 3, no. 25, pp. 15–17, 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.