Recognition: 1 theorem link
· Lean TheoremToward Culturally Grounded Natural Language Processing
Pith reviewed 2026-05-15 00:37 UTC · model grok-4.3
The pith
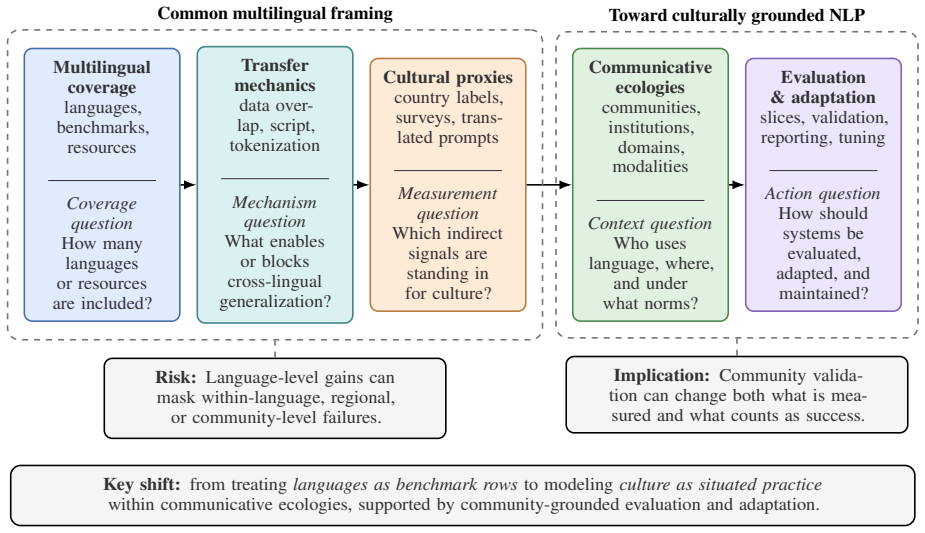
Culturally grounded NLP must move beyond isolated language rows in benchmarks to model full communicative ecologies of institutions, scripts, domains, modalities, and communities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across the synthesized literature, training data coverage remains important, but outcomes are also shaped by tokenization, prompt language, translated benchmark design, culturally grounded supervision, modality, and who authors or validates evaluation data. The paper therefore argues that culturally grounded NLP should move beyond treating languages as isolated rows in benchmark tables and instead model communicative ecologies: the institutions, scripts, domains, modalities, and communities through which language is used. It proposes a layered evaluation and reporting agenda centered on representation audits, mixed elicitation, ecological validity, community validation, adaptation provenance
What carries the argument
communicative ecologies, the institutions, scripts, domains, modalities, and communities through which language is used, positioned as the unit that carries cultural grounding instead of isolated languages in tables.
If this is right
- Evaluation must incorporate representation audits that examine data coverage inside languages rather than across them.
- Benchmarks require mixed elicitation methods and explicit community validation steps.
- Reporting should track adaptation provenance and maintain living cultural resources over time.
- Models need to account for within-language variation and ecological validity in addition to aggregate metrics.
Where Pith is reading between the lines
- This framing implies that current multilingual models may systematically underperform in contexts where modality or institutional setting changes.
- Adoption would likely require new data pipelines that keep cultural resources updated rather than static datasets.
- Similar ecological analysis could be applied to fairness and safety evaluations that currently rely on demographic group labels.
Load-bearing premise
The identified factors from existing literature are sufficient to guide a practical shift to ecological modeling without major new technical barriers.
What would settle it
An experiment that applies the proposed ecological evaluation framework to multiple language communities and finds no measurable gain in alignment with real-world cultural appropriateness compared with standard multilingual benchmarks would falsify the central claim.
Figures
read the original abstract
Multilingual NLP is often treated as a route to global inclusion, but linguistic coverage and cultural competence frequently diverge. This paper synthesizes over 50 papers spanning multilingual performance inequality, cross-lingual transfer, culture-aware evaluation, cultural alignment, multimodal benchmarks, benchmark-design critique, and community-grounded data practices. Across this literature, training data coverage remains important, but outcomes are also shaped by tokenization, prompt language, translated benchmark design, culturally grounded supervision, modality, and who authors or validates evaluation data. We argue that culturally grounded NLP should move beyond treating languages as isolated rows in benchmark tables and instead model communicative ecologies: the institutions, scripts, domains, modalities, and communities through which language is used. We propose a layered evaluation and reporting agenda centered on representation audits, mixed elicitation, ecological validity, community validation, adaptation provenance, within-language variation, and maintenance of living cultural resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript synthesizes literature from over 50 papers on multilingual performance gaps, cross-lingual transfer, culture-aware evaluation, and community data practices to argue that multilingual NLP should move beyond isolated-language rows in benchmark tables. It proposes instead modeling communicative ecologies (institutions, scripts, domains, modalities, communities) and outlines a layered evaluation agenda covering representation audits, mixed elicitation, ecological validity, community validation, adaptation provenance, within-language variation, and maintenance of living cultural resources.
Significance. If the synthesis of drivers such as tokenization, prompt language, and benchmark translation is accurate and comprehensive, the paper could usefully reframe priorities in multilingual NLP toward more context-sensitive and participatory methods. Its value is primarily agenda-setting rather than empirical or formal; adoption would depend on whether the proposed factors prove sufficient to guide implementable changes without new technical barriers.
major comments (2)
- [Abstract] Abstract: the central normative claim that 'outcomes are also shaped by tokenization, prompt language, translated benchmark design, culturally grounded supervision, modality, and who authors or validates evaluation data' is presented as a synthesis without effect-size estimates, relative importance rankings, or counterexamples where data coverage alone explains gaps; this weakens the load-bearing argument that benchmark tables must be replaced by ecological modeling.
- [Evaluation agenda proposal] Section proposing the layered evaluation agenda: the recommendation to model communicative ecologies is not accompanied by any operational definition, concrete metrics, or pilot workflow showing how institutions/scripts/domains would be encoded or audited in an NLP system, leaving the practical shift from current practice underspecified.
minor comments (1)
- [Abstract] Abstract: 'communicative ecologies' is introduced as a novel framing without a concise definition or pointer to its use in prior sociolinguistic literature, which may reduce immediate accessibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us clarify the scope and contributions of our synthesis paper. We address the major comments point-by-point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central normative claim that 'outcomes are also shaped by tokenization, prompt language, translated benchmark design, culturally grounded supervision, modality, and who authors or validates evaluation data' is presented as a synthesis without effect-size estimates, relative importance rankings, or counterexamples where data coverage alone explains gaps; this weakens the load-bearing argument that benchmark tables must be replaced by ecological modeling.
Authors: We appreciate this critique. The manuscript is a literature synthesis rather than a new empirical analysis, so it does not introduce original effect-size estimates or rankings. The claim draws from the body of work cited, where studies have shown that factors like tokenization and benchmark translation contribute to performance gaps beyond mere data coverage (for instance, in papers on subword tokenization biases and translated benchmark artifacts). We will revise the abstract to better frame this as a synthesis of documented influences and add a brief section or paragraph in the main text discussing available quantitative evidence and limitations in current meta-analyses. This addresses the concern without altering the paper's agenda-setting focus. revision: partial
-
Referee: [Evaluation agenda proposal] Section proposing the layered evaluation agenda: the recommendation to model communicative ecologies is not accompanied by any operational definition, concrete metrics, or pilot workflow showing how institutions/scripts/domains would be encoded or audited in an NLP system, leaving the practical shift from current practice underspecified.
Authors: We agree that the proposal would benefit from greater specificity to guide implementation. While the paper intentionally focuses on outlining a broad agenda to stimulate discussion, we will expand the relevant section with operational examples. For instance, we will describe how representation audits could involve mapping language use to institutional contexts using existing sociolinguistic frameworks, and suggest initial metrics such as domain coverage scores or community validation rates. We will also reference pilot studies from related fields that demonstrate feasible workflows for auditing scripts and modalities. These additions will make the agenda more actionable while preserving its high-level nature. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript is a position paper that synthesizes literature on multilingual NLP gaps and proposes modeling communicative ecologies (institutions, scripts, domains, modalities, communities) rather than isolated-language benchmarks. It contains no equations, formal derivations, fitted parameters, predictions, or self-referential definitions. The central claim is a normative recommendation grounded in a review of >50 external papers; no load-bearing step reduces to a self-citation chain, ansatz, or input-by-construction. The argument is therefore self-contained as an interpretive synthesis without circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Linguistic coverage and cultural competence in multilingual NLP frequently diverge
- domain assumption NLP outcomes are shaped by tokenization, prompt language, translated benchmark design, culturally grounded supervision, modality, and data authorship/validation
invented entities (1)
-
communicative ecologies
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We argue that culturally grounded NLP should move beyond treating languages as isolated rows in benchmark tables and instead model communicative ecologies: the institutions, scripts, domains, modalities, and communities through which language is used.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
CARE: Multilingual human preference learn- ing for cultural awareness. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 32866–32895, Suzhou, China. Association for Computational Linguistics. Katharina Hämmerl, Tomasz Limisiewicz, Jindˇrich Li- bovický, and Alexander Fraser. 2025. Beyond literal token overlap:...
work page 2025
-
[2]
HESEIA: A community-based dataset for eval- uating social biases in large language models, co- designed in real school settings in Latin America. InProceedings of the 2025 Conference on Empiri- cal Methods in Natural Language Processing, pages 25095–25117, Suzhou, China. Association for Com- putational Linguistics. Pratik Joshi, Sebastin Santy, Amar Budhi...
work page 2025
-
[3]
Break the checkbox: Challenging closed-style evaluations of cultural alignment in LLMs. InPro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 24–51, Suzhou, China. Association for Computational Lin- guistics. Kyuhee Kim and Sangah Lee. 2025. Nunchi-bench: Benchmarking language models on cultural reason- ing wi...
work page 2025
-
[4]
Tokenization impacts multilingual language modeling: Assessing vocabulary allocation and over- lap across languages. InFindings of the Association for Computational Linguistics: ACL 2023, pages 5661–5681, Toronto, Canada. Association for Com- putational Linguistics. Chen Cecilia Liu, Iryna Gurevych, and Anna Korho- nen. 2025a. Culturally aware and adapted...
work page 2023
-
[5]
DaKultur: Evaluating the cultural awareness of language models for Danish with native speakers. In Proceedings of the 3rd Workshop on Cross-Cultural Considerations in NLP (C3NLP 2025), pages 50–58, Albuquerque, New Mexico. Association for Compu- tational Linguistics. Tarek Naous, Michael J Ryan, Alan Ritter, and Wei Xu
work page 2025
-
[6]
Having beer after prayer? measuring cultural bias in large language models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long Papers), pages 16366–16393, Bangkok, Thailand. Association for Computational Linguistics. Tarek Naous and Wei Xu. 2025. On the origin of cul- tural biases in language model...
work page 2025
-
[7]
Towards a common understanding of con- tributing factors for cross-lingual transfer in multi- lingual language models: A review. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 5877–5891, Toronto, Canada. Association for Computational Linguistics. Salsabila Zahirah Pranida, Rifo Ahm...
work page 2025
-
[8]
No Language Left Behind: Scaling Human-Centered Machine Translation
Global MMLU: Understanding and addressing cultural and linguistic biases in multilingual evalua- tion. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V ol- ume 1: Long Papers), pages 18761–18799, Vienna, Austria. Association for Computational Linguistics. Hayk Stepanyan, Aishwarya Verma, Andrew Zaldivar, Rutledg...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
CaMMT: Benchmarking culturally aware mul- timodal machine translation. InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2025, pages 22423–22441, Suzhou, China. Association for Computational Linguistics. Yuhang Wang, Yanxu Zhu, Chao Kong, Shuyu Wei, Xi- aoyuan Yi, Xing Xie, and Jitao Sang. 2024. CDEval: A benchmark for measuring the cul...
work page 2025
-
[10]
WorldCuisines: A massive-scale benchmark for multilingual and multicultural visual question answering on global cuisines. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technologies (V olume 1: Long Papers), pages 3242–3264, Albuquerque, New Mexico. Association...
work page 2025
-
[11]
Self-pluralising culture alignment for large language models. InProceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 6859–6877, Albuquerque, New Mexico. Asso- ciation for Computational Linguistics. Senqi Yang, Dongyu Zhang, ...
work page 2025
-
[12]
Culture is not trivia: Sociocultural theory for cultural NLP. InProceedings of the 63rd An- nual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 25869– 25886, Vienna, Austria. Association for Computa- tional Linguistics. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.