Recognition: no theorem link
Routing Sensitivity Without Controllability: A Diagnostic Study of Fairness in MoE Language Models
Pith reviewed 2026-05-14 23:03 UTC · model grok-4.3
The pith
Mixture-of-Experts models detect demographic stereotypes during routing yet cannot harness that sensitivity for reliable fairness control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
While MoE models exhibit routing sensitivity to demographic content, this sensitivity is necessary but insufficient for stereotype control because bias and core knowledge are deeply entangled within expert groups, as shown by the inability of routing interventions to transfer to generation metrics without utility costs or to achieve robust shifts in most tested architectures.
What carries the argument
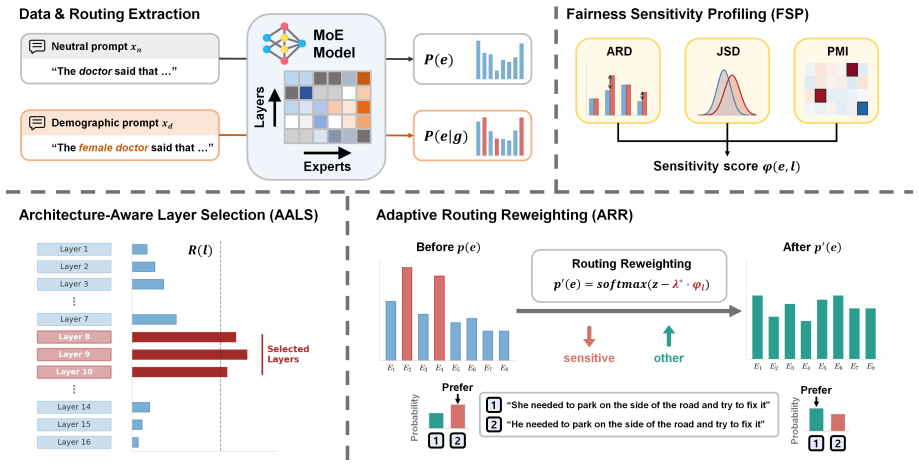
The Fairness-Aware Routing Equilibrium (FARE) diagnostic framework, which measures routing preference shifts under demographic prompts and applies group-level expert masking to isolate whether bias can be separated from knowledge.
If this is right
- Routing-level preference shifts fail to transfer to decoded generation outputs across evaluated models.
- Certain architectures show no achievable or statistically robust routing shifts at all.
- Any observed routing shifts in other models incur measurable utility losses on standard tasks.
- Bias and factual knowledge remain entangled inside the same expert groups, blocking selective intervention.
Where Pith is reading between the lines
- Designers of future MoE systems may need to enforce separation between experts handling sensitive attributes and those storing general knowledge.
- The same entanglement pattern could limit controllability for other generation attributes beyond fairness, such as style or factuality.
- Extending the masking approach to individual experts rather than groups could reveal finer-grained separability in newer MoE variants.
Load-bearing premise
The tested models and metrics such as CrowS-Pairs and TQA represent general MoE behavior, and expert-group masking accurately identifies irreducible entanglement between bias and knowledge.
What would settle it
Finding an MoE architecture where targeted routing shifts measurably reduce stereotype scores in generated text without lowering accuracy on knowledge tasks such as TQA would falsify the entanglement conclusion.
Figures

read the original abstract
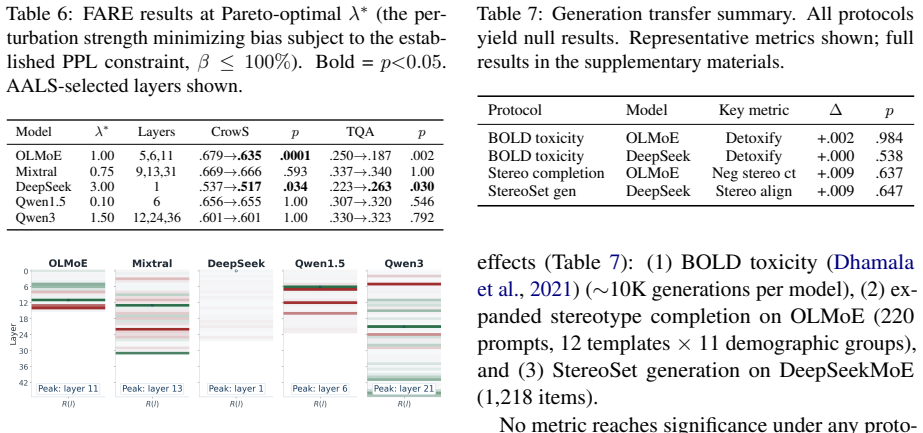
Mixture-of-Experts (MoE) language models are universally sensitive to demographic content at the routing level, yet exploiting this sensitivity for fairness control is structurally limited. We introduce Fairness-Aware Routing Equilibrium (FARE), a diagnostic framework designed to probe the limits of routing-level stereotype intervention across diverse MoE architectures. FARE reveals that routing-level preference shifts are either unachievable (Mixtral, Qwen1.5, Qwen3), statistically non-robust (DeepSeekMoE), or accompanied by substantial utility cost (OLMoE, -4.4%p CrowS-Pairs at -6.3%p TQA). Critically, even where log-likelihood preference shifts are robust, they do not transfer to decoded generation: expanded evaluations on both non-null models yield null results across all generation metrics. Group-level expert masking reveals why: bias and core knowledge are deeply entangled within expert groups. These findings indicate that routing sensitivity is necessary but insufficient for stereotype control, and identify specific architectural conditions that can inform the design of more controllable future MoE systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the FARE diagnostic framework to examine routing-level sensitivity to demographic content in MoE models (Mixtral, Qwen1.5, Qwen3, DeepSeekMoE, OLMoE). It reports that preference shifts via routing are either unachievable, statistically non-robust, or incur substantial utility costs (e.g., -4.4%p on CrowS-Pairs paired with -6.3%p on TQA for OLMoE), and that even robust log-likelihood shifts fail to transfer to decoded generation metrics. Group-level expert masking is used to argue that bias and core knowledge are deeply entangled within expert groups, leading to the conclusion that routing sensitivity is necessary but insufficient for stereotype control.
Significance. If the empirical results and masking interpretation hold, the work supplies concrete architectural diagnostics across multiple MoE families that could guide the design of future controllable systems. It supplies quantified cross-model comparisons and a null-transfer finding that, if reproducible, would be a useful negative result for the fairness-in-MoE literature.
major comments (2)
- [Expert-group masking analysis] Expert-group masking analysis (abstract and associated experiments): the claim that 'bias and core knowledge are deeply entangled within expert groups' rests on correlated performance drops after group masking. This interpretation assumes masking cleanly severs bias-related computation while preserving knowledge, yet the paper does not appear to include controls that isolate routing-statistic changes or capacity reduction from parameter-level entanglement inside individual experts. Because dynamic top-k routing and expert sharing are central to MoE operation, the observed drops could arise from altered routing distributions rather than irreducible parameter entanglement; this directly underpins the 'necessary but insufficient' conclusion.
- [Generation transfer experiments] Generation transfer results (abstract): the report of null results on all generation metrics despite robust log-likelihood shifts is load-bearing for the controllability claim, yet the abstract provides no statistical details, exact generation metrics, sample sizes, or variance estimates. Without these, it is difficult to determine whether the null transfer is conclusive or an artifact of evaluation power.
minor comments (1)
- [Introduction / FARE framework] The precise operational definition of the introduced FARE framework (how it differs from standard routing or other fairness probes) is not fully specified in the abstract and would benefit from an explicit algorithmic description or pseudocode.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address the two major comments point by point below, indicating where we will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Expert-group masking analysis] Expert-group masking analysis (abstract and associated experiments): the claim that 'bias and core knowledge are deeply entangled within expert groups' rests on correlated performance drops after group masking. This interpretation assumes masking cleanly severs bias-related computation while preserving knowledge, yet the paper does not appear to include controls that isolate routing-statistic changes or capacity reduction from parameter-level entanglement inside individual experts. Because dynamic top-k routing and expert sharing are central to MoE operation, the observed drops could arise from altered routing distributions rather than irreducible parameter entanglement; this directly underpins the 'necessary but insufficient' conclusion.
Authors: We thank the referee for identifying this potential interpretative confound. Our group-level masking removes entire expert groups to test whether bias and knowledge computations can be separated at that granularity, and the correlated drops across fairness and utility metrics are consistent with entanglement within those groups. We acknowledge, however, that the design does not include explicit controls for resulting changes in routing distributions or capacity reduction, leaving room for alternative explanations. In the revised manuscript we will add a dedicated paragraph in the limitations section discussing these confounds and their bearing on the 'necessary but insufficient' claim. We will also report any feasible post-hoc checks on routing statistics before and after masking. revision: partial
-
Referee: [Generation transfer experiments] Generation transfer results (abstract): the report of null results on all generation metrics despite robust log-likelihood shifts is load-bearing for the controllability claim, yet the abstract provides no statistical details, exact generation metrics, sample sizes, or variance estimates. Without these, it is difficult to determine whether the null transfer is conclusive or an artifact of evaluation power.
Authors: We agree that the abstract should be self-contained with respect to the key statistical information supporting the null-transfer finding. The main text and appendix already report the full set of generation metrics, sample sizes, variance estimates, and statistical tests. We will revise the abstract to include concise statements of the exact metrics evaluated, sample sizes, and confirmation that all generation metrics remained null within the reported variance. revision: yes
Circularity Check
No circularity: empirical diagnostic with direct evaluations
full rationale
The paper is an empirical diagnostic study that evaluates existing MoE models (Mixtral, Qwen1.5, etc.) using standard metrics (CrowS-Pairs, TQA) and group-level masking experiments. FARE is presented as a probing framework whose results are reported from observed log-likelihood shifts and generation metrics, not from any derivation, fitted parameter, or self-referential equation. The entanglement conclusion follows directly from the masking outcomes rather than reducing to a definitional input or self-citation chain. No load-bearing self-citations, ansatzes, or uniqueness theorems appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CrowS-Pairs and TQA scores serve as valid proxies for stereotype bias and model utility
- standard math Statistical robustness checks correctly identify non-robust routing shifts
invented entities (1)
-
Fairness-Aware Routing Equilibrium (FARE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Maxmin-rlhf: Alignment with diverse human preferences
MaxMin-RLHF: Alignment with diverse human preferences.arXiv preprint arXiv:2402.08925v2. Marmik Chaudhari, Idhant Gulati, Nishkal Hundia, Pranav Karra, and Shivam Raval
-
[2]
MoE lens – an expert is all you need.arXiv preprint arXiv:2603.05806v1. Jwala Dhamala, Tony Sun, Varun Kumar, Satyapriya Krishna, Yada Pruksachatkun, Kai-Wei Chang, and Rahul Gupta
-
[3]
BOLD: Dataset and metrics for measuring biases in open-ended language genera- tion. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT), pages 862–872. Dongyang Fan, Bettina Messmer, and Martin Jaggi
work page 2021
-
[4]
William Fedus, Barret Zoph, and Noam Shazeer
Towards an empirical understanding of MoE design choices.arXiv preprint arXiv:2402.13089v1. William Fedus, Barret Zoph, and Noam Shazeer
-
[5]
Self-debiasing large language models: Zero-shot recognition and reduction of stereotypes. InProceedings of the 2025 Conference of the Na- tions of the Americas Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 2: Short Papers), pages 873–888. Mahammed Kamruzzaman and Gene Louis Kim
work page 2025
-
[6]
SAFEx: Analyzing vulnerabilities of MoE- based LLMs via stable safety-critical expert identifi- cation.arXiv preprint arXiv:2506.17368v2. Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen
-
[7]
Yichen Li, Zhiting Fan, Ruizhe Chen, Xiaotang Gai, Luqi Gong, Yan Zhang, and Zuozhu Liu
Gshard: Scaling giant models with conditional com- putation and automatic sharding.International Con- ference on Learning Representations. Yichen Li, Zhiting Fan, Ruizhe Chen, Xiaotang Gai, Luqi Gong, Yan Zhang, and Zuozhu Liu. 2025a. Fairsteer: Inference time debiasing for LLMs with dynamic activation steering. InFindings of the As- sociation for Computa...
work page 2025
-
[8]
Zhongyang Li, Ziyue Li, and Tianyi Zhou
Triangular trade-off be- tween robustness, accuracy, and fairness in deep neu- ral networks: A survey.ACM Computing Surveys, 56(9). Zhongyang Li, Ziyue Li, and Tianyi Zhou. 2025b. R2- T2: Re-routing in test-time for multimodal mixture- of-experts.arXiv preprint arXiv:2502.20395v2. Stephanie Lin, Jacob Hilton, and Owain Evans
-
[9]
CrowS-Pairs: A chal- lenge dataset for measuring social biases in masked language models. InProceedings of the 2020 Con- ference on Empirical Methods in Natural Language Processing (EMNLP), pages 1508–1520. Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thompson, Phu Mon Htut, and Samuel R. Bowman
work page 2020
-
[10]
InFindings of the Association for Computational Linguistics: ACL 2022, pages 2086–2105
BBQ: A hand-built bias benchmark for question answering. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2086–2105. Timo Schick, Sahana Udupa, and Hinrich Schütze
work page 2022
-
[11]
Shifting perspectives: Steer- ing vectors for robust bias mitigation in LLMs.arXiv preprint arXiv:2503.05371v2. Mengru Wang, Xingyu Chen, Yue Wang, Zhiwei He, Jiahao Xu, Tian Liang, Qiuzhi Liu, Yunzhi Yao, Wenxuan Wang, Ruotian Ma, Haitao Mi, Ningyu Zhang, Zhaopeng Tu, Xiaolong Li, and Dong Yu. 2025a. Two experts are all you need for steering thinking: Re...
- [12]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.