Recognition: no theorem link
Drift-AR: Single-Step Visual Autoregressive Generation via Anti-Symmetric Drifting
Pith reviewed 2026-05-14 21:59 UTC · model grok-4.3
The pith
Drift-AR uses per-position prediction entropy to drive both speculative AR drafting and anti-symmetric drift, achieving genuine single-step visual generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
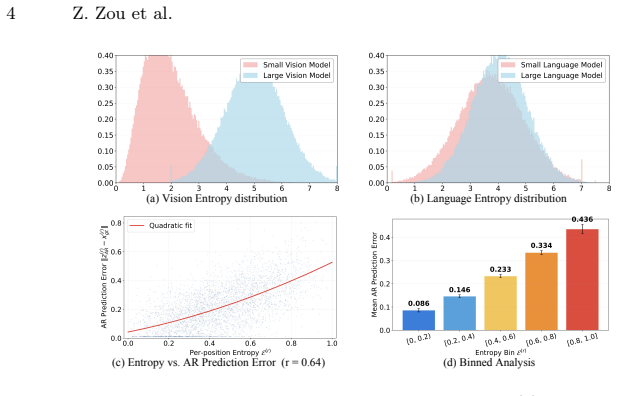
The central claim is that the per-position prediction entropy of continuous-space AR models simultaneously governs draft quality in the autoregressive stage and the corrective effort required in the vision decoding stage. By aligning draft and target entropy distributions through a causal-normalized loss for speculative decoding and by casting entropy as the physical variance of the initial state in an anti-symmetric drifting field, the method enables single-step (1-NFE) decoding without iterative denoising or distillation. Both accelerations reuse the same entropy signal computed once.
What carries the argument
Anti-symmetric drifting field that treats per-position entropy as the variance of the initial state, so high-entropy positions induce stronger drift toward the data manifold while low-entropy positions produce vanishing drift, enabling 1-NFE decoding.
If this is right
- Genuine 1-NFE decoding is achieved without any distillation or iterative denoising steps.
- Speedups between 3.8x and 5.5x are realized on MAR, TransDiff, and NextStep-1 while quality matches or exceeds the original multi-step baselines.
- The same entropy signal accelerates both the AR drafting stage and the visual decoder with zero extra computation.
- Speculative decoding rejection rates drop because draft and target entropy distributions are explicitly aligned.
Where Pith is reading between the lines
- The entropy-as-variance idea could be tested on sequential-iterative hybrids outside vision, such as autoregressive text-to-video models.
- Real-time generation on edge devices becomes plausible once the per-step cost falls to a single function evaluation.
- The anti-symmetric drift formulation might be applied to other continuous-space AR models that already output per-token entropy.
Load-bearing premise
Per-position prediction entropy naturally encodes spatially varying generation uncertainty that simultaneously governs both draft prediction quality and the corrective effort needed in the decoding stage.
What would settle it
If single-step images produced by the entropy-modulated anti-symmetric drift deviate visibly from multi-step reference outputs on standard benchmarks such as ImageNet or COCO, the claim that 1-NFE decoding preserves quality would be refuted.
Figures



read the original abstract
Autoregressive (AR)-Diffusion hybrid paradigms combine AR's structured semantic modeling with diffusion's high-fidelity synthesis, yet suffer from a dual speed bottleneck: the sequential AR stage and the iterative multi-step denoising of the diffusion vision decode stage. Existing methods address each in isolation without a unified principle design. We observe that the per-position \emph{prediction entropy} of continuous-space AR models naturally encodes spatially varying generation uncertainty, which simultaneously governing draft prediction quality in the AR stage and reflecting the corrective effort required by vision decoding stage, which is not fully explored before. Since entropy is inherently tied to both bottlenecks, it serves as a natural unifying signal for joint acceleration. In this work, we propose \textbf{Drift-AR}, which leverages entropy signal to accelerate both stages: 1) for AR acceleration, we introduce Entropy-Informed Speculative Decoding that align draft-target entropy distributions via a causal-normalized entropy loss, resolving the entropy mismatch that causes excessive draft rejection; 2) for visual decoder acceleration, we reinterpret entropy as the \emph{physical variance} of the initial state for an anti-symmetric drifting field -- high-entropy positions activate stronger drift toward the data manifold while low-entropy positions yield vanishing drift -- enabling single-step (1-NFE) decoding without iterative denoising or distillation. Moreover, both stages share the same entropy signal, which is computed once with no extra cost. Experiments on MAR, TransDiff, and NextStep-1 demonstrate 3.8-5.5$\times$ speedup with genuine 1-NFE decoding, matching or surpassing original quality. Code will be available at https://github.com/aSleepyTree/Drift-AR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Drift-AR, which uses per-position prediction entropy from continuous-space AR models as a unifying signal to accelerate both the AR stage (via Entropy-Informed Speculative Decoding with a causal-normalized entropy loss) and the visual decoding stage (via reinterpretation of entropy as variance in an anti-symmetric drifting field). This enables genuine single-step (1-NFE) decoding without iterative denoising or distillation, yielding 3.8-5.5× speedups on MAR, TransDiff, and NextStep-1 while matching or surpassing original quality.
Significance. If the central claims hold, the work offers a unified entropy-driven principle for joint acceleration of hybrid AR-diffusion pipelines, with the attractive property that the same signal is computed once at no extra cost. The empirical demonstration across three distinct models and the avoidance of distillation are strengths that could influence efficient generation methods if the drifting mechanism is shown to preserve the target distribution.
major comments (2)
- [Method (drifting field)] Description of anti-symmetric drifting field: the reinterpretation of per-position entropy directly as physical variance for the drift operator lacks a derivation (e.g., Fokker-Planck analysis or fixed-point guarantee) establishing that the single forward pass lands on the original diffusion marginal; without this, the 1-NFE claim rests on an unverified heuristic and is load-bearing for the headline speedup result.
- [Experiments] Experiments section: reported speedups of 3.8-5.5× and quality matching are presented without error bars, exact baseline NFE counts, or ablations isolating the entropy loss versus the drift scaling, making it difficult to verify that the gains are robust rather than tied to specific model calibrations.
minor comments (2)
- [Abstract] Abstract and method: the phrase 'genuine 1-NFE decoding' should explicitly contrast the function-evaluation count against the original iterative baselines for each model.
- [Method] Notation: the definition of the anti-symmetric drift operator should include the precise functional form relating entropy to the position-wise scaling factor.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (drifting field)] Description of anti-symmetric drifting field: the reinterpretation of per-position entropy directly as physical variance for the drift operator lacks a derivation (e.g., Fokker-Planck analysis or fixed-point guarantee) establishing that the single forward pass lands on the original diffusion marginal; without this, the 1-NFE claim rests on an unverified heuristic and is load-bearing for the headline speedup result.
Authors: We agree that the current presentation relies primarily on empirical validation and the intuitive mapping of entropy to local variance in the drifting field. The anti-symmetric design is intended to ensure that the expected displacement aligns with the data manifold without introducing directional bias, and the single-step result is supported by matching sample quality across models. However, a full Fokker-Planck derivation or explicit fixed-point guarantee is not provided. In the revision we will add a dedicated subsection with a fixed-point analysis showing that the operator has the target marginal as its stationary distribution and a brief discussion of why one step is sufficient under the observed entropy distribution. revision: partial
-
Referee: [Experiments] Experiments section: reported speedups of 3.8-5.5× and quality matching are presented without error bars, exact baseline NFE counts, or ablations isolating the entropy loss versus the drift scaling, making it difficult to verify that the gains are robust rather than tied to specific model calibrations.
Authors: We accept this criticism. The reported speedups compare against the original models' standard inference configurations, but error bars, precise baseline NFE values, and isolating ablations are indeed absent. In the revised manuscript we will report error bars over multiple seeds, list exact NFE counts for every baseline, and include ablations that separately disable the causal-normalized entropy loss and vary the drift scaling factor to demonstrate robustness. revision: yes
Circularity Check
No significant circularity in Drift-AR derivation
full rationale
The paper begins from an empirical observation that per-position prediction entropy in continuous AR models correlates with spatially varying uncertainty. It then proposes two concrete techniques that reuse this computed signal: Entropy-Informed Speculative Decoding (via a causal-normalized entropy loss) and an anti-symmetric drifting field whose variance is set to the same entropy values. Both are presented as design choices rather than mathematical derivations that reduce the claimed 1-NFE output to the input entropy by construction. No equations are shown that equate the final state distribution to the original diffusion marginal via the entropy mapping alone; quality and speedup are instead demonstrated empirically on MAR, TransDiff, and NextStep-1. No load-bearing self-citations, fitted parameters renamed as predictions, or uniqueness theorems imported from prior author work appear in the provided text. The central claim therefore remains an independent engineering proposal supported by external benchmarks rather than a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Per-position prediction entropy of continuous-space AR models naturally encodes spatially varying generation uncertainty governing both draft quality and decoding corrective effort.
invented entities (1)
-
Anti-symmetric drifting field
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Anil, R., Dai, A.M., Firat, O., Johnson, M., Lepikhin, D., Passos, A., Shakeri, S., Taropa, E., Bailey, P., Chen, Z., et al.: Palm 2 technical report. arXiv preprint arXiv:2305.10403 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Token Merging: Your ViT But Faster
Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461 (2022) 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bolya, D., Hoffman, J.: Token merging for fast stable diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4599– 4603 (2023) 5
work page 2023
-
[5]
Generative Modeling via Drifting
Deng, M., Li, H., Li, T., Du, Y., He, K.: Generative modeling via drifting. arXiv preprint arXiv:2602.04770 (2026) 3, 5, 6, 9
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021) 2
work page 2021
-
[7]
Advances in Neural Information Processing Systems36, 52132–52152 (2023) 2, 11
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems36, 52132–52152 (2023) 2, 11
work page 2023
-
[8]
arXiv preprint arXiv:2305.10924 (2023) 5
Gongfan, F., Xinyin, M., Xinchao, W.: Structural pruning for diffusion models. arXiv preprint arXiv:2305.10924 (2023) 5
-
[9]
Advances in neural information processing systems30(2017) 11
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017) 11
work page 2017
-
[10]
Advances in neural information processing systems33, 6840–6851 (2020) 2
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 2
work page 2020
- [11]
-
[12]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Li, D., Kamko, A., Akhgari, E., Sabet, A., Xu, L., Doshi, S.: Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation. arXiv preprint arXiv:2402.17245 (2024) 11, 12
work page internal anchor Pith review arXiv 2024
-
[13]
Advances in Neural Information Processing Systems37, 56424–56445 (2024) 2, 4, 5, 10, 11
Li, T., Tian, Y., Li, H., Deng, M., He, K.: Autoregressive image generation with- out vector quantization. Advances in Neural Information Processing Systems37, 56424–56445 (2024) 2, 4, 5, 10, 11
work page 2024
-
[14]
arXiv preprint arXiv:2406.16858 (2024) 2, 5
Li, Y., Wei, F., Zhang, C., Zhang, H.: Eagle-2: Faster inference of language models with dynamic draft trees. arXiv preprint arXiv:2406.16858 (2024) 2, 5
-
[15]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Li, Y., Wei, F., Zhang, C., Zhang, H.: Eagle: Speculative sampling requires re- thinking feature uncertainty. arXiv preprint arXiv:2401.15077 (2024) 2, 3, 5, 7, 11, 13
work page internal anchor Pith review arXiv 2024
-
[16]
arXiv preprint arXiv:2503.01840 (2025) 5 16 Z
Li, Y., Wei, F., Zhang, C., Zhang, H.: Eagle-3: Scaling up inference acceleration of large language models via training-time test. arXiv preprint arXiv:2503.01840 (2025) 5 16 Z. Zou et al
-
[17]
Sdxl- lightning: Progressive adversarial diffusion distillation
Lin, S., Wang, A., Yang, X.: Sdxl-lightning: Progressive adversarial diffusion dis- tillation. arXiv preprint arXiv:2402.13929 (2024) 5
-
[18]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
arXiv preprint arXiv:2408.02657 (2024) 1
Liu, D., Zhao, S., Zhuo, L., Lin, W., Qiao, Y., Li, H., Gao, P.: Lumina-mgpt: Illu- minate flexible photorealistic text-to-image generation with multimodal generative pretraining. arXiv preprint arXiv:2408.02657 (2024) 1
-
[20]
In: International conference on learning representations (2023) 4
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: International conference on learning representations (2023) 4
work page 2023
-
[21]
Token caching for diffusion transformer acceleration.arXiv preprint arXiv:2409.18523, 2024
Lou, J., Luo, W., Liu, Y., Li, B., Ding, X., Hu, W., Cao, J., Li, Y., Ma, C.: To- ken caching for diffusion transformer acceleration. arXiv preprint arXiv:2409.18523 (2024) 5
-
[22]
arXiv preprint arXiv:2412.15205 (2024) 2, 4
Ren, S., Yu, Q., He, J., Shen, X., Yuille, A., Chen, L.C.: Flowar: Scale-wise autore- gressive image generation meets flow matching. arXiv preprint arXiv:2412.15205 (2024) 2, 4
-
[23]
Advances in neural information processing systems29(2016) 11
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Improved techniques for training gans. Advances in neural information processing systems29(2016) 11
work page 2016
-
[24]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512 (2022) 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shang, Y., Yuan, Z., Xie, B., Wu, B., Yan, Y.: Post-training quantization on dif- fusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1972–1981 (2023) 5
work page 1972
-
[26]
Advances in Neural Information Processing Systems36(2024) 5
So, J., Lee, J., Ahn, D., Kim, H., Park, E.: Temporal dynamic quantization for diffusion models. Advances in Neural Information Processing Systems36(2024) 5
work page 2024
-
[27]
In: International conference on machine learning
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsuper- vised learning using nonequilibrium thermodynamics. In: International conference on machine learning. pp. 2256–2264. PMLR (2015) 2
work page 2015
-
[28]
In: Interna- tional conference on machine learning
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: Interna- tional conference on machine learning. pp. 32211–32252. PMLR (2023) 2
work page 2023
-
[29]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020) 2
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[30]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024) 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Nextstep-1: Toward autoregressive image generation with continuous tokens at scale
Team, N., Han, C., Li, G., Wu, J., Sun, Q., Cai, Y., Peng, Y., Ge, Z., Zhou, D., Tang, H., et al.: Nextstep-1: Toward autoregressive image generation with contin- uous tokens at scale. arXiv preprint arXiv:2508.10711 (2025) 2, 4, 10, 12, 13
-
[32]
Advances in Neural Informa- tion Processing Systems37, 84839–84865 (2024) 5
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalable image generation via next-scale prediction. Advances in Neural Informa- tion Processing Systems37, 84839–84865 (2024) 5
work page 2024
-
[33]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Advances in neural information processing systems30(2017) 2
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. Advances in neural information processing systems30(2017) 2
work page 2017
-
[35]
arXiv preprint arXiv:2412.15119 (2024) 5 Drift-AR: Single-Step Visual AR via Drifting 17
Wang, Y., Ren, S., Lin, Z., Han, Y., Guo, H., Yang, Z., Zou, D., Feng, J., Liu, X.: Parallelized autoregressive visual generation. arXiv preprint arXiv:2412.15119 (2024) 5 Drift-AR: Single-Step Visual AR via Drifting 17
-
[36]
arXiv preprint arXiv:2411.11925 (2024) 10
Wang, Z., Zhang, R., Ding, K., Yang, Q., Li, F., Xiang, S.: Continuous specula- tive decoding for autoregressive image generation. arXiv preprint arXiv:2411.11925 (2024) 10
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yan, F., Wei, Q., Tang, J., Li, J., Wang, Y., Hu, X., Li, H., Zhang, L.: Lazymar: Accelerating masked autoregressive models via feature caching. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15552–15561 (2025) 10, 11
work page 2025
-
[38]
Advances in neural information processing systems37, 47455–47487 (2024) 2, 5
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F., Freeman, B.: Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems37, 47455–47487 (2024) 2, 5
work page 2024
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6613– 6623 (2024) 2, 5, 6, 10, 11, 13, 14
work page 2024
-
[40]
arXiv preprint arXiv:2406.08552 (2024) 5
Yuan, Z., Zhang, H., Lu, P., Ning, X., Zhang, L., Zhao, T., Yan, S., Dai, G., Wang, Y.: Ditfastattn: Attention compression for diffusion transformer models. arXiv preprint arXiv:2406.08552 (2024) 5
-
[41]
arXiv preprint arXiv:2404.11098 (2024) 5
Zhang, D., Li, S., Chen, C., Xie, Q., Lu, H.: Laptop-diff: Layer pruning and normal- ized distillation for compressing diffusion models. arXiv preprint arXiv:2404.11098 (2024) 5
-
[42]
arXiv preprint arXiv:2506.09482 (2025) 2, 4, 5, 10, 11
Zhen, D., Qiao, Q., Zheng, X., Yu, T., Wu, K., Zhang, Z., Liu, S., Yin, S., Tao, M.: Marrying autoregressive transformer and diffusion with multi-reference autore- gression. arXiv preprint arXiv:2506.09482 (2025) 2, 4, 5, 10, 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.