Recognition: 2 theorem links
· Lean TheoremGraphWalker: Agentic Knowledge Graph Question Answering via Synthetic Trajectory Curriculum
Pith reviewed 2026-05-14 22:00 UTC · model grok-4.3
The pith
GraphWalker trains agents for knowledge graph question answering first on synthetic random-walk trajectories and then on expert paths to unlock state-of-the-art results with lightweight reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a two-stage supervised fine-tuning paradigm first trains an agent on structurally diverse trajectories synthesized from constrained random-walk paths to establish a broad exploration prior over the knowledge graph, then fine-tunes it on a small set of expert trajectories to develop reflection and error recovery, thereby unlocking a higher performance ceiling for a subsequent lightweight reinforcement learning stage that achieves state-of-the-art results on CWQ and WebQSP while improving generalization to out-of-distribution reasoning paths.
What carries the argument
The two-stage SFT training paradigm that uses automated trajectory synthesis from constrained random walks to build an exploration prior, followed by fine-tuning on expert trajectories to enable reflection and error recovery before a lightweight RL stage.
If this is right
- GraphWalker reaches state-of-the-art performance on the CWQ and WebQSP benchmarks.
- The method improves generalization to out-of-distribution reasoning paths on GrailQA and the constructed GraphWalkerBench.
- A lightweight RL stage becomes more effective once the agent has undergone the two-stage SFT preparation.
- The framework reduces dependence on large volumes of expert trajectories by first leveraging scalable synthetic data.
Where Pith is reading between the lines
- The synthetic trajectory curriculum could be adapted to train agents for other structured environments such as database querying or semantic web navigation.
- Varying the constraints used to generate the random-walk paths might allow tuning the exploration prior to match particular query distributions.
- Combining the two-stage SFT with larger base models could raise the performance ceiling even further.
- Testing the trained agents on knowledge graphs that change over time would reveal how stable the learned exploration strategies remain.
Load-bearing premise
That trajectories synthesized from constrained random-walk paths establish a broad exploration prior over the KG that generalizes to real user queries and enables effective reflection in the second stage.
What would settle it
If an agent trained only on expert trajectories without the first synthetic random-walk stage achieves equal or higher final performance on CWQ and WebQSP after the same lightweight RL phase, the value of the initial broad prior would be called into question.
Figures








read the original abstract
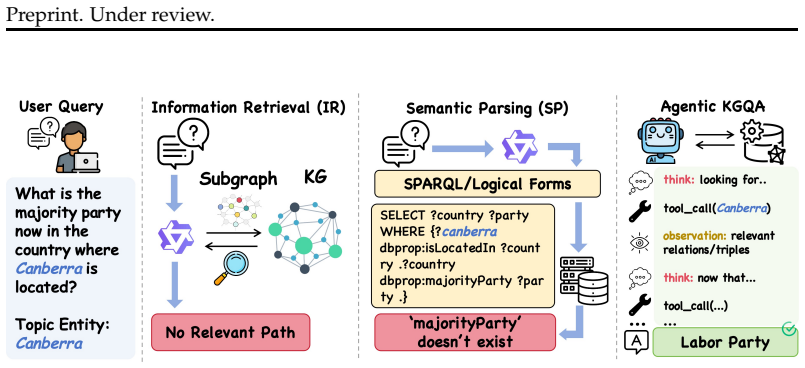
Agentic knowledge graph question answering (KGQA) requires an agent to iteratively interact with knowledge graphs (KGs), posing challenges in both training data scarcity and reasoning generalization. Specifically, existing approaches often restrict agent exploration: prompting-based methods lack autonomous navigation training, while current training pipelines usually confine reasoning to predefined trajectories. To this end, this paper proposes \textit{GraphWalker}, a novel agentic KGQA framework that addresses these challenges through \textit{Automated Trajectory Synthesis} and \textit{Stage-wise Fine-tuning}. GraphWalker adopts a two-stage SFT training paradigm: First, the agent is trained on structurally diverse trajectories synthesized from constrained random-walk paths, establishing a broad exploration prior over the KG; Second, the agent is further fine-tuned on a small set of expert trajectories to develop reflection and error recovery capabilities. Extensive experiments demonstrate that our stage-wise SFT paradigm unlocks a higher performance ceiling for a lightweight reinforcement learning (RL) stage, enabling GraphWalker to achieve state-of-the-art performance on CWQ and WebQSP. Additional results on GrailQA and our constructed GraphWalkerBench confirm that GraphWalker enhances generalization to out-of-distribution reasoning paths. The code is publicly available at https://github.com/XuShuwenn/GraphWalker
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GraphWalker, an agentic KGQA framework that uses automated trajectory synthesis from constrained random-walk paths on KGs, followed by a two-stage SFT paradigm: initial training on these synthetic trajectories to establish a broad exploration prior, then fine-tuning on a small set of expert trajectories to build reflection and error-recovery capabilities. This staged approach is claimed to raise the performance ceiling for a subsequent lightweight RL stage, yielding SOTA results on CWQ and WebQSP plus improved OOD generalization on GrailQA and the authors' new GraphWalkerBench.
Significance. If the transfer from synthetic random-walk trajectories to real multi-hop query reasoning holds and the reported gains are robust, the work would offer a practical route to scalable agent training in KGQA without heavy reliance on expert data, addressing data scarcity and exploration limitations in current prompting or trajectory-restricted methods. Public code release supports reproducibility.
major comments (2)
- Abstract: the SOTA claim on CWQ and WebQSP is presented without any mention of the concrete baselines, statistical significance tests, error bars, or precise train/dev/test splits, making it impossible to assess whether the performance lift is attributable to the two-stage curriculum rather than implementation details or data choices.
- Abstract: the load-bearing claim that constrained random-walk trajectories create a usable exploration prior that transfers to expert trajectories and enables effective reflection in stage 2 (thereby unlocking the RL ceiling) receives no supporting analysis, such as coverage statistics over reasoning patterns in CWQ/WebQSP or an ablation isolating stage-1 versus stage-2 contributions; random walks are structurally local and lack the semantic entity-relation constraints of real queries, so this transfer must be demonstrated rather than assumed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications drawn directly from the manuscript and indicate revisions where they strengthen the presentation without misrepresenting our results.
read point-by-point responses
-
Referee: Abstract: the SOTA claim on CWQ and WebQSP is presented without any mention of the concrete baselines, statistical significance tests, error bars, or precise train/dev/test splits, making it impossible to assess whether the performance lift is attributable to the two-stage curriculum rather than implementation details or data choices.
Authors: We agree the abstract is too terse on this point. The full manuscript reports results against concrete baselines (ToG, ReAct, StructGPT, and others) in Tables 1 and 2, using the canonical train/dev/test splits for CWQ and WebQSP, with means and standard deviations computed over three random seeds. To make the abstract self-contained, we will revise it to name the primary baselines and note that full results with error bars appear in Section 4. This change clarifies attribution to the curriculum while respecting abstract length limits. revision: yes
-
Referee: Abstract: the load-bearing claim that constrained random-walk trajectories create a usable exploration prior that transfers to expert trajectories and enables effective reflection in stage 2 (thereby unlocking the RL ceiling) receives no supporting analysis, such as coverage statistics over reasoning patterns in CWQ/WebQSP or an ablation isolating stage-1 versus stage-2 contributions; random walks are structurally local and lack the semantic entity-relation constraints of real queries, so this transfer must be demonstrated rather than assumed.
Authors: We acknowledge that the abstract itself does not contain the supporting analysis, and that random walks are indeed structurally local. The manuscript already provides ablations in Sections 4.2 and 4.3 that isolate the contribution of stage-1 (synthetic trajectories) versus stage-2 (expert fine-tuning) and show the combined curriculum raises the RL ceiling. We will add a new paragraph with quantitative coverage statistics (hop-length distribution, relation-type diversity, and entity co-occurrence overlap) between the synthetic trajectories and the CWQ/WebQSP expert set to directly demonstrate transfer. This addition addresses the referee's concern on substance. revision: yes
Circularity Check
No circularity in claimed derivation chain
full rationale
The paper presents an empirical agentic KGQA framework using two-stage SFT on synthetic random-walk trajectories followed by expert trajectories and lightweight RL. No equations, fitted parameters renamed as predictions, or self-citation chains reduce the SOTA claims on CWQ/WebQSP or OOD results to inputs by construction. Performance is reported via benchmark experiments rather than derived from self-referential definitions or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Constrained random walks on a knowledge graph can produce structurally diverse trajectories that establish a useful exploration prior for downstream queries
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GraphWalker adopts a two-stage SFT training paradigm: First, the agent is trained on structurally diverse trajectories synthesized from constrained random-walk paths, establishing a broad exploration prior over the KG
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRPO with a simple exact-match reward unlocks a higher performance ceiling enabled by the two-stage SFT prior
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Available: http://dx.doi.org/10.1038/s41586-025-09422-z
URLhttps://arxiv.org/abs/2308.14436. Abhimanyu Dubey et al. The llama 3 herd of models.ArXiv preprint, abs/2407.21783, 2024. URLhttps://arxiv.org/abs/2407.21783. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, and Xu. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645 (8081):633–638, September 2...
-
[2]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
URLhttps://openreview.net/forum?id=cPgh4gWZlz. Haoran Luo, Haihong E, Zichen Tang, Shiyao Peng, Yikai Guo, Wentai Zhang, Chenghao Ma, Guanting Dong, Meina Song, Wei Lin, Yifan Zhu, and Anh Tuan Luu. Chatkbqa: A generate-then-retrieve framework for knowledge base question answering with fine- tuned large language models. InFindings of the Association for C...
-
[3]
Association for Computational Linguistics. doi: 10.18653/v1/D19-1250. URL https://aclanthology.org/D19-1250. 11 Preprint. Under review. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, et al. Qwen2.5 technical report, 2024. URL https://arxiv. org/abs/2412.15115. Stephen Robertson and Hugo Zaragoza...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d19-1250 2024
-
[4]
Association for Computational Linguistics. doi: 10.18653/v1/N18-1059. URL https://aclanthology.org/N18-1059. Denny Vrandeˇ ci´ c and Markus Krötzsch. Wikidata: A free collaborative knowledge base. In Proceedings of WWW, 2014. Yike Wu, Yi Huang, Nan Hu, Yuncheng Hua, Guilin Qi, Jiaoyan Chen, and Jeff Z. Pan. Cotkr: Chain-of-thought enhanced knowledge rewri...
-
[5]
URLhttps://openreview.net/pdf?id=WE_vluYUL-X
OpenReview.net, 2023. URLhttps://openreview.net/pdf?id=WE_vluYUL-X. 12 Preprint. Under review. Wen-tau Yih, Ming-Wei Chang, Xiaodong He, and Jianfeng Gao. Semantic parsing via staged query graph generation. InProceedings of ACL, 2015. Wen-tau Yih, Matthew Richardson, Chris Meek, Ming-Wei Chang, and Jina Suh. The value of semantic parse labeling for knowle...
-
[6]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma
URLhttps://www.ijcai.org/proceedings/2024/734. Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models,
work page 2024
-
[7]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
URLhttps://arxiv.org/abs/2403.13372. 13 Preprint. Under review. A Preliminaries Knowledge graph.A knowledge graph (KG) G= (E , R, T) consists of a set of entities E, a set of relations R, and a triple set T ⊆ E × R × E , where each triple ⟨e, r, e′⟩ ∈ T encodes a directed relation r from entity e to entity e′. Each entity is assigned a unique entity ID (e...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
First, perform careful reasoning inside<think>...</think>tags. In this section, briefly outline your plan, record any working memory or intermediate observations, check for mistakes or ambiguous interpretations
-
[9]
If you need to query knowledge for more information, you can set a query statement between<kg-query>...</kg- query>to query from knowledge graph. The query tool-using rules are provided in "KG Query Server Instruction" part. Each<kg-query>call must occur after<think>...</think>, and you must not issue another <kg-query>until you have received the environm...
-
[10]
If you have already found the answer, return it directly in the form<answer>...</answer>and end your search. Your answer must strictly follow the KG Query Server Instruction. KG Instructions: {kg_instruction} Question:{question} Begin your search with the following initial entities. Useget_relationsto explore their relations. Initial Entities:{initial_ent...
-
[11]
If you encounter a KG-related error, read the error message carefully and correct your query
-
[12]
Use only the two query functions above; do not write natural-language queries inside<kg-query>tags
-
[13]
If Initial Entities are provided, begin your search from them usingget_relations(“initial_entity”). If multiple initial entities are given, start with the most specific one. Analyze each systematically
-
[14]
Use the ENTITY NAME EXACTLY as shown in the<information>section. Example:get_relations(“Barack Obama”)
-
[15]
Before callingget_triples(...), you MUST have calledget_relations(...)for that entity (or already seen its relations) to ensure the relations exist
-
[16]
When callingget_triples, provide a list of ALL candidate relations returned by the previous step, ranked by relevance to the question. We will automatically use the top 4. Copy each relation EXACTLY as it appears in the<information>list. Example:get_triples(“Barack Obama”, [“people.person.place_of_birth”, “peo- ple.person.nationality”, ...])
-
[17]
Always use double quotes around all function parameters (entity names and relations). Answer Output Rules:
-
[18]
Format:<answer>[“Answer1”, “Answer2”, ...]</answer>. Return a JSON list of strings. The final answer must be a human-readable entity name, not a MID (e.g., m.01234). If the only candidate you have is a MID, do NOT output it as the final answer. Instead, explore the MID’s neighbors (useget_relations/get_triples) to find a named entity to return
-
[19]
The answer(s) MUST be EXACT and COMPLETE entity names from the retrieved triples
No external knowledge: answer ONLY using KG query results you have retrieved. The answer(s) MUST be EXACT and COMPLETE entity names from the retrieved triples. If multiple entities satisfy the question, list them all in the JSON list in<answer>tags
-
[20]
Do NOT include any explanations in the<answer>tags
-
[21]
NEVER include “I don’t know” or “Information not available” in<answer>tags. Provide the best possible answer(s) from the entities you have retrieved
-
[22]
CRITICAL: Your final answer must only contain entities that exist in the provided graph triples. 23 Preprint. Under review. Trajectory Generation Prompt (Composition Type) === OVERVIEW === You are a helpful assistant that generates Supervised Fine-Tuning samples for a Knowledge Graph question-answering task. Your task is to generate a concise reasoning th...
-
[31]
The topic entities (starting points)
-
[35]
Avoid over-summarizing or repeating information
Directly explains why the given next action is the right choice at this point For the final step (when the next action is to provide an<answer>): • Briefly explain how the observations from the last step provide the answer Keep your thought concise and direct. Avoid over-summarizing or repeating information. Focus on the essential reasoning that leads to ...
-
[40]
Do NOT simply restate the action - explain the REASONING behind choosing it, but keep it brief. === OUTPUT FORMAT === <think> Your concise reasoning thought (typically 2-5 sentences, following the example’s brief style) </think> 24 Preprint. Under review. Trajectory Generation Prompt (Conjunction Type) === OVERVIEW === You are a helpful assistant that gen...
-
[41]
Copy names exactly as shown in the last<information>
Always use ENTITY NAME in all function calls. Copy names exactly as shown in the last<information>
-
[42]
If Initial entities are provided, you must start your search from them usingget_relations(“your_initial_entity”)
-
[43]
Use double quotes around all function parameters (entity and relations)
-
[44]
When callingget_triples, provide a list of relations that are helpful to answer the question, triples related to these relations will be automatically retrieved. Each relation must be copied EXACTLY from the latest<infor- mation>list. Example:get_triples(“Barack Obama”, [“people.person.place_of_birth”, “people.person.nationality”])
-
[45]
Only use the two query functions listed above; do not write natural language queries inside<kg-query>tags
-
[46]
Before callingget_triples(...), first callget_relations(...)for your current entity to obtain the predicate list
-
[47]
=== WHAT TO WRITE === You will be given:
No outside knowledge: answer ONLY using KG results you have retrieved. === WHAT TO WRITE === You will be given:
-
[48]
The question to answer
-
[49]
The topic entities (starting points - may be multiple for conjunction questions)
-
[50]
Historical information: all previous steps with their thoughts, actions, and observations
-
[51]
The next action that should be taken (this is the "golden action" that leads to the answer) Your task is to write a concise thought that:
-
[52]
Briefly mentions what you learned from the last observation (relations or triples)
-
[53]
Avoid over-summarizing or repeating information
Directly explains why the given next action is the right choice at this point For the final step (when the next action is to provide an<answer>): • Briefly explain how the observations from the previous step provide the answer Keep your thought concise and direct. Avoid over-summarizing or repeating information. Focus on the essential reasoning that leads...
-
[54]
NEVER mention entities, relations, or facts that may appear in future steps
ONLY reference information from previous steps (historical information provided to you). NEVER mention entities, relations, or facts that may appear in future steps
-
[55]
Avoid lengthy summaries or over-explanation
Keep your thought concise and direct - typically 2-5 sentences, similar to the example style. Avoid lengthy summaries or over-explanation
-
[56]
Copy entity/predicate strings EXACTLY as shown in observations
-
[57]
Use natural language only; never include<kg-query>or<answer>tags in your thoughts
-
[58]
Do NOT simply restate the action - explain the REASONING behind choosing it, but keep it brief. === OUTPUT FORMAT === <think> Your concise reasoning thought (typically 2-5 sentences, following the example’s brief style) </think> 25 Preprint. Under review. Question Generation Prompts Single-Path Question: You are given: - A path represented as an ordered s...
-
[59]
name_path: A reasoning path in the knowledge graph, represented as a sequence of entities and relations connected by “->” 2.question: The natural language question that should be answerable by following this path Input Example: name_path: “Emap International Limited -> organization.organization.founders -> Richard Winfrey -> peo- ple.person.place_of_birth...
-
[60]
Do not include any text outside the valid structure
Output Consistency: Always output the score in the exact format above. Do not include any text outside the valid structure
-
[61]
Do not include any other text or explanation. Output Format You must output only a single score from 0 to 10:<score><0-10></score> Relation Reranking Prompt Template You are an expert Knowledge Graph navigator. Your goal is to select the most relevant relations that will lead to the answer for a given question. You will be provided with:
-
[62]
A Topic Entity involved in the question
-
[63]
A list of Candidate Relations connected to that entity
-
[64]
A Previous Model Thinking Process: The reasoning from the model’s last turn (if available), which may provide helpful context about the query strategy and what information is being sought. Task (STRICT RULES): • You MUST select relations ONLY from the provided Candidate Relations list. –Each selected string MUST be an EXACT character-by-character match to...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.