Recognition: 2 theorem links
· Lean TheoremModeling AI-RAN Economics: A Techno-Economic Framework
Pith reviewed 2026-05-14 00:37 UTC · model grok-4.3
The pith
GPU-based RAN deployments can offset extra hardware costs and deliver up to 8x returns by leasing idle capacity to AI workloads
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining public 5G Layer-1 benchmarks on heterogeneous platforms with traffic models and AI service demand profiles, the analysis quantifies surplus GPU capacity available in RAN deployments; leasing this capacity to AI tenants offsets the incremental capital and operational expenditures of GPU-heavy systems and produces returns on investment of up to 8x across the tested scenarios.
What carries the argument
Joint cost-revenue model that estimates surplus GPU capacity from idle RAN periods and computes net returns from AI workload leasing
Load-bearing premise
The surplus capacity and resulting ROI rest on public 5G Layer-1 benchmarks and assumed traffic and AI demand profiles accurately representing real-world operation.
What would settle it
A controlled live deployment that measures actual GPU idle time and realized AI leasing revenue under known traffic loads would directly test whether the modeled 8x return materializes.
Figures







read the original abstract
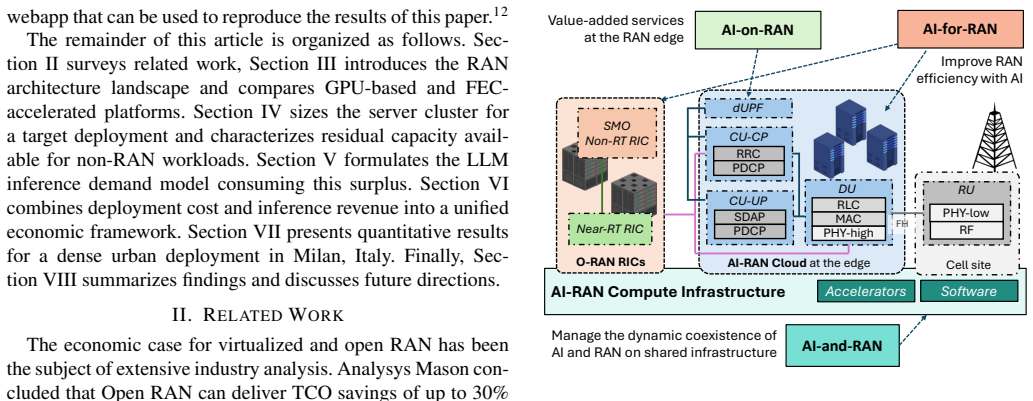
The large-scale deployment of 5G networks has not delivered the expected return on investment for mobile network operators, raising concerns about the economic viability of future 6G rollouts. At the same time, surging demand for Artificial Intelligence (AI) inference and training workloads is straining global compute capacity. AI-RAN architectures, in which Radio Access Network (RAN) platforms accelerated on Graphics Processing Unit (GPU) share idle capacity with AI workloads during off-peak periods, offer a potential path to improved capital efficiency. However, the economic case for such systems remains unsubstantiated. In this paper, we present a techno-economic analysis of AI-RAN deployments by combining publicly available benchmarks of 5G Layer-1 processing on heterogeneous platforms -- from x86 servers with accelerators for channel coding to modern GPUs -- with realistic traffic models and AI service demand profiles for Large Language Model (LLM) inference. We construct a joint cost and revenue model that quantifies the surplus compute capacity available in GPU-based RAN deployments and evaluates the returns from leasing it to AI tenants. Our results show that, across a range of scenarios encompassing token depreciation, varying demand dynamics, and diverse GPU serving densities, the additional capital and operational expenditures of GPU-heavy deployments are offset by AI-on-RAN revenue, yielding a return on investment of up to 8x. These findings strengthen the long-term economic case for accelerator-based RAN architectures and future 6G deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a techno-economic framework for AI-RAN deployments that combines publicly available 5G Layer-1 processing benchmarks on GPU-accelerated platforms with realistic traffic models and LLM inference demand profiles. It constructs a joint cost-revenue model to quantify surplus GPU capacity available for leasing to AI workloads and reports that, across scenarios varying token depreciation rates, demand dynamics, and GPU serving densities, the additional CAPEX/OPEX of GPU-heavy RAN is offset by AI revenue, producing ROI up to 8x.
Significance. If the surplus-capacity calculations and revenue projections prove robust, the work supplies a quantitative economic rationale for accelerator-based RAN architectures, directly addressing the low-ROI concerns that have slowed 5G monetization and that threaten 6G viability. The framework could inform operator investment decisions and 6G standardization discussions on shared compute platforms.
major comments (2)
- [Model description and results sections] The headline 8x ROI result depends on the surplus GPU capacity being computed as (total GPU cycles minus 5G L1 load under realistic traffic). Public benchmarks for channel coding and PHY on GPUs are used without reported adjustments for real-time scheduling contention, integration overheads, or thermal/power limits that exist in live RAN deployments; if these reduce available idle capacity materially, the modeled AI revenue falls and ROI drops below 1x. This assumption is load-bearing for the central claim.
- [Parameter table and scenario results] The parameter set (token depreciation rate, GPU serving density, demand dynamics) is fitted or chosen rather than externally benchmarked; no sensitivity analysis or closed-form bounds on how ROI varies with ±20% perturbations in these inputs is shown, leaving the 8x figure without quantified uncertainty.
minor comments (2)
- [Abstract] The abstract states quantitative results (8x ROI) without referencing any equation, table, or validation step; the manuscript should include a brief pointer to the relevant model equation and data source in the abstract.
- [Notation and assumptions] Notation for GPU serving density and token depreciation should be defined at first use with units and a short justification for the chosen range.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our techno-economic framework for AI-RAN. The comments highlight important considerations regarding model assumptions and parameter robustness. We address each major comment below and have revised the manuscript to strengthen the presentation of limitations and uncertainty.
read point-by-point responses
-
Referee: The headline 8x ROI result depends on the surplus GPU capacity being computed as (total GPU cycles minus 5G L1 load under realistic traffic). Public benchmarks for channel coding and PHY on GPUs are used without reported adjustments for real-time scheduling contention, integration overheads, or thermal/power limits that exist in live RAN deployments; if these reduce available idle capacity materially, the modeled AI revenue falls and ROI drops below 1x. This assumption is load-bearing for the central claim.
Authors: We agree that the public benchmarks used for 5G L1 processing do not incorporate real-time scheduling contention, integration overheads, or thermal/power constraints present in live deployments, and that these could materially reduce surplus capacity. In the revised manuscript we have added a dedicated Limitations subsection (Section 4.4) that explicitly discusses these factors and their potential to lower idle capacity by 15-40% based on related literature. We also performed additional numerical sensitivity runs assuming 20% and 30% reductions in available surplus; under these conditions the ROI remains above 1.8x in the base scenarios and reaches 4.2x under optimistic demand. We cannot, however, provide operator-specific traces to quantify the exact overheads. revision: partial
-
Referee: The parameter set (token depreciation rate, GPU serving density, demand dynamics) is fitted or chosen rather than externally benchmarked; no sensitivity analysis or closed-form bounds on how ROI varies with ±20% perturbations in these inputs is shown, leaving the 8x figure without quantified uncertainty.
Authors: The parameter values were drawn from published 5G traffic models and recent LLM inference studies rather than fitted to proprietary data. We acknowledge the absence of a formal sensitivity study in the original submission. The revised version includes a new Section 5.3 with one-way and multi-way sensitivity analyses that perturb each key parameter (token depreciation rate, GPU serving density, demand dynamics) by ±20% and ±50%. Results show that ROI stays positive (minimum 1.4x) across the tested ranges, with the headline 8x value occurring only under the most favorable combination of inputs. We have also added shaded uncertainty bands to the primary ROI figures. revision: yes
- Precise quantification of real-time scheduling contention and thermal/power limits on idle GPU capacity in operational RAN deployments, which would require access to proprietary operator traces not available from public benchmarks.
Circularity Check
No significant circularity: ROI is computed output from explicit input benchmarks and parameter sweeps
full rationale
The paper constructs a joint cost-revenue model that takes as inputs publicly available 5G Layer-1 benchmarks, realistic traffic models, and AI demand profiles (including token depreciation rates, demand dynamics, and GPU serving densities). Surplus GPU capacity is quantified as the difference between total GPU capacity and 5G L1 load under those traffic models; revenue is then evaluated by leasing the surplus at modeled token prices. The reported ROI values (up to 8x) are direct numerical outputs of this forward computation across chosen scenario ranges. No equation reduces the final ROI to a fitted parameter by construction, no self-citation supplies a uniqueness theorem that forces the architecture, and no ansatz or known empirical pattern is renamed as a derived result. The framework remains self-contained against its stated external benchmarks and parameter assumptions.
Axiom & Free-Parameter Ledger
free parameters (3)
- token depreciation rate
- GPU serving density
- demand dynamics parameters
axioms (2)
- domain assumption Publicly available benchmarks of 5G Layer-1 processing on heterogeneous platforms accurately represent real deployment performance.
- domain assumption Realistic traffic models and AI service demand profiles for LLM inference are representative of future conditions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct a joint cost and revenue model that quantifies the surplus compute capacity available in GPU-based RAN deployments and evaluates the returns from leasing it to AI tenants... yielding a return on investment of up to 8×.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The additional capital and operational expenditures of GPU-heavy deployments are offset by AI-on-RAN revenue
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
GSMA Intelligence, “Global mobile trends 2023,” 2023, accessed: 2025-06. [Online]. Available: https://www.gsma.com/
work page 2023
-
[2]
The economic potential of generative AI: The next productivity frontier,
McKinsey Global Institute, “The economic potential of generative AI: The next productivity frontier,” McKinsey & Company, Tech. Rep., Jun. 2023, accessed: 2025-06. [Online]. Available: https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/ the-economic-potential-of-generative-ai-the-next-productivity-frontier
work page 2023
-
[3]
BurstGPT: A real-world workload dataset to optimize LLM serving systems,
Y . Wang, Y . Chenet al., “BurstGPT: A real-world workload dataset to optimize LLM serving systems,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’25). Toronto, ON, Canada: ACM, 2025. [Online]. Available: https://doi.org/10.1145/3711896.3737413
-
[4]
Beyond connectivity: An open architecture for AI-RAN convergence in 6G,
M. Polese, N. Mohamadiet al., “Beyond connectivity: An open architecture for AI-RAN convergence in 6G,”IEEE Communications Magazine (to appear), 2025. [Online]. Available: https://arxiv.org/abs/ 2507.06911
-
[5]
Industry leaders form AI-RAN alliance,
AI-RAN Alliance, “Industry leaders form AI-RAN alliance,” 2024, mWC Barcelona. [Online]. Available: https://ai-ran.org/news/industry- leaders-in-ai-and-wireless-form-ai-ran-alliance/
work page 2024
-
[6]
AI-RAN: Transforming RAN with AI-driven computing infrastructure,
L. Kundu, X. Linet al., “AI-RAN: Transforming RAN with AI-driven computing infrastructure,”arXiv preprint arXiv:2501.09007, 2025. [Online]. Available: https://arxiv.org/abs/2501.09007
-
[7]
The interplay of AI-and- RAN: Dynamic resource allocation for converged 6G platform,
S. D. A. Shah, Z. Nezamiet al., “The interplay of AI-and- RAN: Dynamic resource allocation for converged 6G platform,” arXiv preprint arXiv:2503.07420, 2025. [Online]. Available: https: //arxiv.org/abs/2503.07420
-
[9]
Available: https://arxiv.org/abs/2507.09124
[Online]. Available: https://arxiv.org/abs/2507.09124
-
[10]
Analysys Mason, “Open RAN TCO analysis,” Tech. Rep., 2022, commissioned by Wind River. [Online]. Available: https://www.analysysmason.com/contentassets/ b3260036a0d449718117eeaf5ac83472/analysys mason open ran tco feb2022 rma16 rma18.pdf
work page 2022
-
[11]
Open RAN progress drives confidence,
——, “Open RAN progress drives confidence,” Tech. Rep., 2024, commissioned by Wind River. [Online]. Available: https://www.analysysmason.com/contentassets/ a99b7d01b9e64a2cafc375459c99de99/analysys mason open ran confidence apr2024 rma18.pdf
work page 2024
-
[12]
Open RAN and vRAN revenue trends,
S. Pongratz, “Open RAN and vRAN revenue trends,” 2024, dell’Oro Group. [Online]. Available: https://www.fierce-network.com/ modernization/open-ran-and-vran-tanks-2023
work page 2024
-
[13]
Inference economics of language models,
E. Erdil, “Inference economics of language models,”arXiv preprint arXiv:2506.04645, 2025. [Online]. Available: https://arxiv.org/abs/ 2506.04645
-
[14]
The price of progress: Algorithmic efficiency and the falling cost of AI inference,
H. Gundlach, J. Lynchet al., “The price of progress: Algorithmic efficiency and the falling cost of AI inference,”arXiv preprint arXiv:2511.23455, 2025. [Online]. Available: https://arxiv.org/abs/ 2511.23455
-
[15]
The emerging market for intelligence: Pricing, supply, and demand for LLMs,
M. Demirer, A. Fradkinet al., “The emerging market for intelligence: Pricing, supply, and demand for LLMs,” 2025, working paper. [Online]. Available: https://andreyfradkin.com/assets/LLM Demand 12 12 2025.pdf
work page 2025
-
[16]
C. Xiao, J. Caiet al., “Densing law of LLMs,”Nature Machine Intelli- gence, vol. 7, pp. 1823–1833, 2025
work page 2025
-
[18]
Efficient inference for edge large language models: A survey,
G. Cai, R. Tianet al., “Efficient inference for edge large language models: A survey,”Tsinghua Science and Technology, vol. 31, no. 3, pp. 1365– 1380, 2026
work page 2026
-
[19]
Hybrid LLM: Cost-efficient and quality- aware query routing,
D. Ding, A. Mallicket al., “Hybrid LLM: Cost-efficient and quality- aware query routing,” inProc. ICLR, 2024. [Online]. Available: https://openreview.net/forum?id=02f3mUtqnM
work page 2024
-
[20]
NVIDIA Aerial GPU hosted AI-on-5G,
A. Kelkar and C. Dick, “NVIDIA Aerial GPU hosted AI-on-5G,” inProc. IEEE 4th 5G World Forum (5GWF), 2021, pp. 64–69
work page 2021
-
[21]
O-RAN: Disrupting the vir- tualized RAN ecosystem,
A. Garcia-Saavedra and X. Costa-Perez, “O-RAN: Disrupting the vir- tualized RAN ecosystem,”IEEE Communications Standards Magazine, vol. 5, no. 4, pp. 96–103, 2021
work page 2021
-
[22]
Enabling the world’s first GPU-accelerated 5G Open RAN for NTT DOCOMO with NVIDIA Aerial,
NVIDIA, “Enabling the world’s first GPU-accelerated 5G Open RAN for NTT DOCOMO with NVIDIA Aerial,” 2023, accessed: 2025-12. [On- line]. Available: https://developer.nvidia.com/blog/enabling-the-worlds- first-gpu-accelerated-5g-open-ran-for-ntt-docomo-with-nvidia-aerial/
work page 2023
-
[23]
Aerial CUDA-accelerated RAN release 25-2,
——, “Aerial CUDA-accelerated RAN release 25-2,” 2025, accessed: 2025-12. [Online]. Available: https://docs.nvidia.com/aerial/ cuda-accelerated-ran/25-2/aerial-cuda-accelerated-ran.pdf
work page 2025
-
[24]
QCT VRB100 vRAN server specifications,
Quanta Cloud Technology, “QCT VRB100 vRAN server specifications,” 2024, vendor specifications; Accessed: 2025-12. [Online]. Available: https://www.qct.io/
work page 2024
-
[25]
Verified reference configuration for virtualized RAN on the HPE ProLiant DL110,
Intel and Hewlett Packard Enterprise, “Verified reference configuration for virtualized RAN on the HPE ProLiant DL110,” 2022, accessed: 2025-
work page 2022
-
[26]
[Online]. Available: https://builders.intel.com/docs/networkbuilders/ intel-hpe-verified-reference-configuration-for-virtualized-radio-access- networks-on-the-hpe-proliant-dl110-1653673153.pdf
-
[27]
Nvidia aerial gpu hosted ai-on-5g,
A. Kelkar and C. Dick, “Nvidia aerial gpu hosted ai-on-5g,” in2021 IEEE 4th 5G World Forum (5GWF). IEEE, 2021, pp. 64–69
work page 2021
-
[28]
Understanding 5G Performance on Hetero- geneous Computing Architectures,
C. Wang, H. Nieet al., “Understanding 5G Performance on Hetero- geneous Computing Architectures,”IEEE Communications Magazine, vol. 63, no. 3, pp. 107–113, March 2025
work page 2025
-
[29]
Intel accelerates 5G leadership with new products,
Intel Corporation, “Intel accelerates 5G leadership with new products,” 2023, accessed: 2025-12. [Online]. Available: https://www.intc.com/news-events/press-releases/detail/1606/ intel-accelerates-5g-leadership-with-new-products
work page 2023
-
[30]
Report ITU-R M.2412-0: Guidelines for evaluation of radio interface technologies for IMT-2020,
ITU-R, “Report ITU-R M.2412-0: Guidelines for evaluation of radio interface technologies for IMT-2020,” International Telecommunication Union, Tech. Rep., Oct. 2017, dense Urban-eMBB; Accessed: 2025-06. [Online]. Available: https://www.itu.int/dms pub/itu-r/opb/rep/R-REP- M.2412-2017-PDF-E.pdf
work page 2020
-
[31]
——, “Recommendation ITU-R M.2160-0: Framework and overall objectives of the future development of IMT for 2030 and beyond,” International Telecommunication Union, Tech. Rep., Nov. 2023, accessed: 2025-06. [Online]. Available: https://www.itu.int/dms pubrec/ itu-r/rec/m/R-REC-M.2160-0-202311-I!!PDF-E.pdf
work page 2030
-
[32]
——, “Report ITU-R M.2410-0: Minimum requirements related to technical performance for IMT-2020 radio interface(s),” International Telecommunication Union, Tech. Rep., Nov. 2017, accessed: 2025-06. [Online]. Available: https://www.itu.int/pub/R-REP-M.2410
work page 2020
-
[33]
A multi-source dataset of urban life in the city of Milan and the Province of Trentino,
G. Barlacchi, M. De Nadaiet al., “A multi-source dataset of urban life in the city of Milan and the Province of Trentino,”Scientific Data, vol. 2, p. 150055, 2015. [Online]. Available: https://doi.org/10.1038/sdata.2015.55
-
[34]
BurstGPT: A real-world workload dataset to optimize LLM serving systems,
Y . Wang, Y . Chenet al., “BurstGPT: A real-world workload dataset to optimize LLM serving systems,”arXiv preprint arXiv:2401.17644, 2024. [Online]. Available: https://arxiv.org/abs/2401.17644
-
[35]
Claude vs. ChatGPT statistics 2026: Head-to-head numbers behind the AI battle,
R. A. Lee, “Claude vs. ChatGPT statistics 2026: Head-to-head numbers behind the AI battle,” 2025, 2.5–3B prompts/day, 190.6M DAU; Accessed: 2025-10. [Online]. Available: https://sqmagazine.co.uk/ claude-vs-chatgpt-statistics/
work page 2026
-
[36]
Resident population and population density – municipality of Milan,
ISTAT, “Resident population and population density – municipality of Milan,” 2024, population density≈7 500/km 2; Accessed: 2025-06. [Online]. Available: https://www.istat.it/en/
work page 2024
-
[37]
The state of mobile internet con- nectivity 2024,
GSMA Intelligence, “The state of mobile internet con- nectivity 2024,” 2024, accessed: 2025-06. [Online]. Avail- able: https://data.gsmaintelligence.com/research/research/research-2024/ the-state-of-mobile-internet-connectivity-2024
work page 2024
-
[38]
J. Lorincz and Z. Klarin, “A comprehensive analysis of the impact of an increase in user devices on the long-term energy efficiency of 5G networks,”Smart Cities, vol. 7, no. 6, pp. 3616–3657, 2024. [Online]. Available: https://www.mdpi.com/2624-6511/7/6/140
work page 2024
-
[39]
ITU-R WP 5D, “Preliminary draft new report ITU-R M.[IMT- 2030.TECH PERF REQ]: Minimum requirements related to technical performance for IMT-2030 radio interface(s),” International Telecommu- nication Union, Tech. Rep., 2024, working document; Accessed: 2025- 06
work page 2030
-
[40]
TS 38.214: NR; physical layer procedures for data (release 18),
3GPP, “TS 38.214: NR; physical layer procedures for data (release 18),” 3rd Generation Partnership Project, Tech. Rep., 2024, accessed: 2025-06. [Online]. Available: https://www.3gpp.org/dynareport/38214.htm
work page 2024
-
[41]
2024 global data center sur- vey: Report,
Uptime Institute, “2024 global data center sur- vey: Report,” 2024, accessed: 2025-06. [Online]. Avail- able: https://datacenter.uptimeinstitute.com/rs/711-RIA-145/images/ 2024.GlobalDataCenterSurvey.Report.pdf
work page 2024
-
[42]
Eurostat, “Electricity price statistics,” 2024, household and industrial prices; 0.3291 EUR/kWh; Accessed: 2025-06. [Online]. Avail- able: https://ec.europa.eu/eurostat/statistics-explained/index.php?title= Electricity price statistics
work page 2024
-
[43]
Ericsson, “Ericsson mobility report,” Tech. Rep., November 2025, accessed: February 23, 2026. [Online]. Available: https://www.ericsson.com/4aca6f/assets/local/reports-papers/mobility- report/documents/2025/ericsson-mobility-report-november-2025.pdf
work page 2025
-
[44]
LLM performance leaderboard: Model and API provider benchmarks,
Artificial Analysis, “LLM performance leaderboard: Model and API provider benchmarks,” 2024, accessed: 2025-06. [Online]. Available: https://artificialanalysis.ai/leaderboards/models
work page 2024
-
[45]
Performance characterization of expert router for scalable LLM inference,
J. Pichlmeier, P. Ross, and A. Luckow, “Performance characterization of expert router for scalable LLM inference,” inarXiv preprint arXiv:2404.15153, 2024. [Online]. Available: https://arxiv.org/abs/ 2404.15153
-
[46]
Together AI – inference pricing,
Together AI, “Together AI – inference pricing,” 2024, llama 3.3 70B: $0.88/Mtok; Accessed: 2025-06. [Online]. Available: https: //www.together.ai/pricing
work page 2024
-
[47]
Generative ai practices, literacy, and divides: An empirical analysis in the italian context,
B. Savoldi, G. Attanasioet al., “Generative ai practices, literacy, and divides: An empirical analysis in the italian context,” 2025. [Online]. Available: https://arxiv.org/abs/2512.03671
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.