Recognition: 2 theorem links
· Lean TheoremLA-Sign: Looped Transformers with Geometry-aware Alignment for Skeleton-based Sign Language Recognition
Pith reviewed 2026-05-14 21:06 UTC · model grok-4.3
The pith
Recurrent looping in transformers with Poincaré alignment refines skeletal motion features for sign language recognition using shared parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
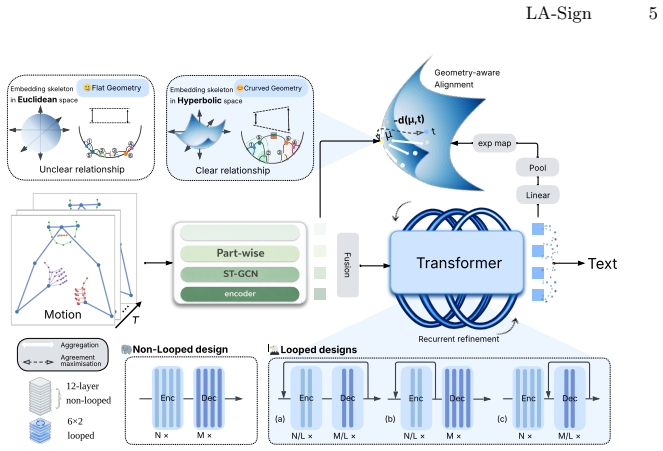
LA-Sign replaces stacked layers with looped encoder-decoder transformers that repeatedly revisit latent representations under shared weights, combined with a geometry-aware contrastive objective that projects skeletal and textual features into adaptive Poincaré space to encourage multi-scale semantic organization, delivering state-of-the-art isolated sign language recognition on WLASL and MSASL benchmarks.
What carries the argument
Looped encoder-decoder transformer with adaptive Poincaré alignment, which performs recurrent refinement of multi-scale motion representations under shared parameters while organizing features in hyperbolic space.
Load-bearing premise
Repeated passes through shared transformer parameters produce stable progressive refinement of representations rather than redundancy or optimization instability.
What would settle it
Training curves or ablation results on WLASL showing performance plateaus or degrades after a small number of loops would indicate the recurrence adds no new information.
Figures



read the original abstract
Skeleton-based isolated sign language recognition (ISLR) demands fine-grained understanding of articulated motion across multiple spatial scales, from subtle finger movements to global body dynamics. Existing approaches typically rely on deep feed-forward architectures, which increase model capacity but lack mechanisms for recurrent refinement and structured representation. We propose LA-Sign, a looped transformer framework with geometry-aware alignment for ISLR. Instead of stacking deeper layers, LA-Sign derives its depth from recurrence, repeatedly revisiting latent representations to progressively refine motion understanding under shared parameters. To further regularise this refinement process, we present a geometry-aware contrastive objective that projects skeletal and textual features into an adaptive hyperbolic space, encouraging multi-scale semantic organisation. We study three looping designs and multiple geometric manifolds, demonstrating that encoder-decoder looping combined with adaptive Poincare alignment yields the strongest performance. Extensive experiments on WLASL and MSASL benchmarks show that LA-Sign achieves state-of-the-art results while using fewer unique layers, highlighting the effectiveness of recurrent latent refinement and geometry-aware representation learning for sign language recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LA-Sign, a looped transformer framework for skeleton-based isolated sign language recognition (ISLR). Depth is obtained via recurrence with shared encoder-decoder parameters rather than layer stacking; a geometry-aware contrastive objective projects skeletal and textual features into an adaptive hyperbolic (Poincaré) space to encourage multi-scale semantic organization. Three looping designs are studied, with encoder-decoder looping plus adaptive Poincaré alignment reported as strongest; the method claims state-of-the-art results on WLASL and MSASL while using fewer unique layers.
Significance. If the performance claims and refinement mechanism hold, the work would be significant for parameter-efficient modeling of articulated motion, showing that recurrent application of shared weights combined with hyperbolic geometry can outperform deeper feed-forward transformers on fine-grained recognition tasks and offering a template for other pose- or video-based sequence problems.
major comments (3)
- [Experimental Evaluation] Experimental Evaluation section: the SOTA claims on WLASL and MSASL are unsupported by any reported protocol, baseline details, error bars, ablation statistics, or statistical significance tests, leaving the central performance assertion unverifiable from the manuscript text.
- [Looped Transformer Design] Looped Transformer Design (and associated analysis): the claim that repeated application of shared parameters produces progressive, stable refinement of multi-scale motion representations lacks direct evidence such as layer-wise representation similarity, gradient-norm trajectories across loops, or an ablation that isolates loop count from total FLOPs; without this, the efficiency and refinement narrative cannot be substantiated.
- [Geometry-aware Alignment] Geometry-aware Alignment objective: the adaptive curvature parameter and its effect on multi-scale organization are introduced without ablation against Euclidean contrastive baselines or analysis of optimization stability, which is load-bearing for the geometry-aware contribution.
minor comments (2)
- [Abstract] The abstract states that three looping designs were studied but does not name or briefly characterize them; this should be added for immediate clarity.
- [Notation and Preliminaries] Notation for loop count and hyperbolic curvature should be introduced once and used consistently in equations and text.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each major comment below and commit to revising the manuscript to enhance clarity and support for our claims.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: the SOTA claims on WLASL and MSASL are unsupported by any reported protocol, baseline details, error bars, ablation statistics, or statistical significance tests, leaving the central performance assertion unverifiable from the manuscript text.
Authors: We agree with the referee that additional details are required to make the SOTA claims verifiable. In the revised manuscript, we will provide a detailed description of the evaluation protocols used for WLASL and MSASL, including data splits and preprocessing steps. We will list all compared baselines with their original references and implementation details. Furthermore, we will report results with error bars from at least 3 independent runs, include comprehensive ablation studies with statistics, and perform statistical significance tests to support the performance improvements. revision: yes
-
Referee: [Looped Transformer Design] Looped Transformer Design (and associated analysis): the claim that repeated application of shared parameters produces progressive, stable refinement of multi-scale motion representations lacks direct evidence such as layer-wise representation similarity, gradient-norm trajectories across loops, or an ablation that isolates loop count from total FLOPs; without this, the efficiency and refinement narrative cannot be substantiated.
Authors: The referee correctly points out the lack of direct evidence for the refinement process. While our experiments compare different looping designs, we will add in the revision direct analyses including: cosine similarity between representations at different loop iterations to show progressive refinement, plots of gradient norms across loops to demonstrate stability, and an ablation where we fix the total computational budget (FLOPs) and vary the number of loops to isolate the effect of recurrence from parameter count. revision: yes
-
Referee: [Geometry-aware Alignment] Geometry-aware Alignment objective: the adaptive curvature parameter and its effect on multi-scale organization are introduced without ablation against Euclidean contrastive baselines or analysis of optimization stability, which is load-bearing for the geometry-aware contribution.
Authors: We acknowledge that the manuscript would benefit from more ablations on the geometry-aware objective. In the revised version, we will add experiments comparing the adaptive Poincaré alignment against standard Euclidean contrastive losses (such as InfoNCE in Euclidean space) on the same backbone. We will also analyze the effect of the adaptive curvature by reporting performance for fixed curvature values and include training loss curves and convergence metrics to address optimization stability. revision: yes
Circularity Check
No significant circularity in the proposed looped transformer and hyperbolic alignment framework
full rationale
The paper introduces a new looped transformer architecture (encoder-decoder recurrence with shared parameters) and a geometry-aware contrastive objective projecting features into adaptive hyperbolic space. These are presented as novel design choices, with performance claims resting on empirical results from external public benchmarks (WLASL, MSASL) rather than any self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or derivations in the provided text reduce by construction to their own inputs; the looping and alignment mechanisms are validated through ablation studies on looping designs and manifolds, keeping the central claims independent of circular reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- loop count
- hyperbolic curvature parameter
axioms (2)
- domain assumption Shared-parameter recurrence can progressively refine latent motion representations without instability.
- domain assumption Hyperbolic space organizes hierarchical multi-scale semantics more effectively than Euclidean space for skeleton-text pairs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
LA-Sign derives its depth from recurrence, repeatedly revisiting latent representations to progressively refine motion understanding under shared parameters... geometry-aware contrastive objective that projects skeletal and textual features into an adaptive hyperbolic space
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We study three looping designs... encoder-decoder looping combined with adaptive Poincaré alignment yields the strongest performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the national academy of sciences79(8), 2554–2558 (1982)
Neural networks and physical systems with emergent collective computational abil- ities. Proceedings of the national academy of sciences79(8), 2554–2558 (1982)
1982
-
[2]
Advances in Neural Information Processing Systems 35, 20232–20242 (2022)
Bansal, A., Schwarzschild, A., Borgnia, E., Emam, Z., Huang, F., Goldblum, M., Goldstein, T.: End-to-end algorithm synthesis with recurrent networks: Extrapo- lation without overthinking. Advances in Neural Information Processing Systems 35, 20232–20242 (2022)
2022
-
[3]
Riemannian Adaptive Optimization Methods
Bécigneul, G., Ganea, O.E.: Riemannian adaptive optimization methods. arXiv preprint arXiv:1810.00760 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6299–6308 (2017)
2017
-
[5]
IEEE Transactions on Cognitive and Developmental Systems15(2), 602–614 (2022)
Chen, J., Zhao, C., Wang, Q., Meng, H.: Hmanet: Hyperbolic manifold aware network for skeleton-based action recognition. IEEE Transactions on Cognitive and Developmental Systems15(2), 602–614 (2022)
2022
-
[6]
Chen, Y., Shang, J., Zhang, Z., Xie, Y., Sheng, J., Liu, T., Wang, S., Sun, Y., Wu, H., Wang, H.: Inner thinking transformer: Leveraging dynamic depth scaling to foster adaptive internal thinking. arXiv preprint arXiv:2502.13842 (2025)
-
[7]
Advances in Neural Information Processing Sys- tems37, 28589–28614 (2024)
Csordás, R., Irie, K., Schmidhuber, J., Potts, C., Manning, C.D.: Moeut: Mixture- of-experts universal transformers. Advances in Neural Information Processing Sys- tems37, 28589–28614 (2024)
2024
-
[8]
Dehghani, M., Gouws, S., Vinyals, O., Uszkoreit, J., Kaiser, Ł.: Universal trans- formers. arXiv preprint arXiv:1807.03819 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
In: International Conference on Machine Learning
Desai, K., Nickel, M., Rajpurohit, T., Johnson, J., Vedantam, S.R.: Hyperbolic image-text representations. In: International Conference on Machine Learning. pp. 7694–7731. PMLR (2023)
2023
-
[10]
Psychology Press (2001)
Emmorey, K.: Language, cognition, and the brain: Insights from sign language research. Psychology Press (2001)
2001
-
[11]
arXiv preprint arXiv:2409.15647 (2024)
Fan, Y., Du, Y., Ramchandran, K., Lee, K.: Looped transformers for length gen- eralization. arXiv preprint arXiv:2409.15647 (2024)
-
[12]
In: 2007 IEEE conference on computer vision and pattern recognition
Farhadi, A., Forsyth, D., White, R.: Transfer learning in sign language. In: 2007 IEEE conference on computer vision and pattern recognition. pp. 1–8. IEEE (2007)
2007
-
[13]
In: 2003 IEEE International SOI Conference
Fillbrandt, H., Akyol, S., Kraiss, K.F.: Extraction of 3d hand shape and posture from image sequences for sign language recognition. In: 2003 IEEE International SOI Conference. Proceedings (Cat. No. 03CH37443). pp. 181–186. IEEE (2003)
2003
-
[14]
arXiv preprint arXiv:2506.00129 (2025)
Fish, E., Bowden, R.: Geo-sign: Hyperbolic contrastive regularisation for geomet- rically aware sign language translation. arXiv preprint arXiv:2506.00129 (2025)
-
[15]
Advances in neural information processing systems31(2018)
Ganea, O., Bécigneul, G., Hofmann, T.: Hyperbolic neural networks. Advances in neural information processing systems31(2018)
2018
-
[16]
Gatmiry, K., Saunshi, N., Reddi, S.J., Jegelka, S., Kumar, S.: Can looped trans- formers learn to implement multi-step gradient descent for in-context learning? In: International Conference on Machine Learning. pp. 15130–15152. PMLR (2024)
2024
-
[17]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Geiping, J., McLeish, S., Jain, N., Kirchenbauer, J., Singh, S., Bartoldson, B.R., Kailkhura, B., Bhatele, A., Goldstein, T.: Scaling up test-time compute with latent LA-Sign 21 reasoning: A recurrent depth approach. CoRRabs/2502.05171(February 2025), https://doi.org/10.48550/arXiv.2502.05171
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.05171 2025
-
[18]
In: Chaud- huri, K., Salakhutdinov, R
Gelada, C., Kumar, S., Buckman, J., Nachum, O., Bellemare, M.G.: DeepMDP: Learning continuous latent space models for representation learning. In: Chaud- huri, K., Salakhutdinov, R. (eds.) Proceedings of the 36th International Confer- ence on Machine Learning. Proceedings of Machine Learning Research, vol. 97, pp. 2170–2179. PMLR (09–15 Jun 2019),https://...
2019
-
[19]
Giannou, A., Rajput, S., Sohn, J.y., Lee, K., Lee, J.D., Papailiopoulos, D.: Looped transformersasprogrammablecomputers.In:InternationalConferenceonMachine Learning. pp. 11398–11442. PMLR (2023)
2023
-
[20]
In: Proceedings of the IEEE international conference on computer vision workshops
Hara, K., Kataoka, H., Satoh, Y.: Learning spatio-temporal features with 3d resid- ual networks for action recognition. In: Proceedings of the IEEE international conference on computer vision workshops. pp. 3154–3160 (2017)
2017
-
[21]
Nature Reviews Methods Primers4(1), 82 (2024)
Healy, J., McInnes, L.: Uniform manifold approximation and projection. Nature Reviews Methods Primers4(1), 82 (2024)
2024
-
[22]
IEEE Transactions on Pattern Anal- ysis and Machine Intelligence45(9), 11221–11239 (2023)
Hu, H., Zhao, W., Zhou, W., Li, H.: Signbert+: Hand-model-aware self-supervised pre-training for sign language understanding. IEEE Transactions on Pattern Anal- ysis and Machine Intelligence45(9), 11221–11239 (2023)
2023
-
[23]
In: Proceedings of the IEEE/CVF international conference on computer vision
Hu, H., Zhao, W., Zhou, W., Wang, Y., Li, H.: Signbert: pre-training of hand- model-aware representation for sign language recognition. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11087–11096 (2021)
2021
-
[24]
In: Pro- ceedings of the AAAI conference on artificial intelligence
Hu, H., Zhou, W., Li, H.: Hand-model-aware sign language recognition. In: Pro- ceedings of the AAAI conference on artificial intelligence. vol. 35, pp. 1558–1566 (2021)
2021
-
[25]
ACM transactions on multimedia computing, commu- nications, and applications (TOMM)17(3), 1–19 (2021)
Hu, H., Zhou, W., Pu, J., Li, H.: Global-local enhancement network for nmf-aware sign language recognition. ACM transactions on multimedia computing, commu- nications, and applications (TOMM)17(3), 1–19 (2021)
2021
-
[26]
Advances in neural information processing systems35, 33248–33261 (2022)
Hutchins, D., Schlag, I., Wu, Y., Dyer, E., Neyshabur, B.: Block-recurrent trans- formers. Advances in neural information processing systems35, 33248–33261 (2022)
2022
-
[27]
arXiv e-prints pp
Jiang, S., Sun, B., Wang, L., Bai, Y., Li, K., Fu, Y.: Sign language recognition via skeleton-aware multi-model ensemble. arXiv e-prints pp. arXiv–2110 (2021)
2021
-
[28]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Jiang, S., Sun, B., Wang, L., Bai, Y., Li, K., Fu, Y.: Skeleton aware multi-modal sign language recognition. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 3413–3423 (2021)
2021
-
[29]
arXiv preprint arXiv:2303.07399 (2023)
Jiang, T., Lu, P., Zhang, L., Ma, N., Han, R., Lyu, C., Li, Y., Chen, K.: Rtm- pose: Real-time multi-person pose estimation based on mmpose. arXiv preprint arXiv:2303.07399 (2023)
-
[30]
BMVC (2019)
Joze, H.R.V., Koller, O.: Ms-asl: A large-scale data set and benchmark for under- standing american sign language. BMVC (2019)
2019
-
[31]
Khrulkov, V., Mirvakhabova, L., Ustinova, E., Oseledets, I., Lempitsky, V.: Hyper- bolicimageembeddings.In:ProceedingsoftheIEEE/CVFconferenceoncomputer vision and pattern recognition. pp. 6418–6428 (2020)
2020
-
[32]
International Journal of Computer Vision126(12), 1311–1325 (2018)
Koller,O.,Zargaran,S.,Ney,H.,Bowden,R.:Deepsign:Enablingrobuststatistical continuous sign language recognition via hybrid cnn-hmms. International Journal of Computer Vision126(12), 1311–1325 (2018)
2018
-
[33]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., Soricut, R.: Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942 (2019) 22 Muxin Pu, Mei Kuan Lim, Chun Yong Chong, and Chen Change Loy
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[34]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Li, D., Rodriguez, C., Yu, X., Li, H.: Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 1459– 1469 (2020)
2020
-
[35]
In: Proceedings of the AAAI conference on artificial intelligence
Li, D., Xu, C., Liu, L., Zhong, Y., Wang, R., Petersson, L., Li, H.: Transcribing natural languages for the deaf via neural editing programs. In: Proceedings of the AAAI conference on artificial intelligence. vol. 36, pp. 11991–11999 (2022)
2022
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, D., Yu, X., Xu, C., Petersson, L., Li, H.: Transferring cross-domain knowledge for video sign language recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6205–6214 (2020)
2020
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, J., Wang, J., Tan, C., Lian, N., Chen, L., Wang, Y., Zhang, M., Xia, S.T., Chen, B.: Enhancing partially relevant video retrieval with hyperbolic learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23074–23084 (2025)
2025
-
[38]
arXiv preprint arXiv:2502.05869 (2025)
Li, Y., Qu, H., Liu, M., Liu, J., Cai, Y.: Hyliformer: Hyperbolic linear attention for skeleton-based human action recognition. arXiv preprint arXiv:2502.05869 (2025)
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, Y., Chen, X., Li, H., Pu, X., Jin, P., Ren, Y.: Vsnet: Focusing on the linguistic characteristics of sign language. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 24320–24330 (June 2025)
2025
-
[40]
In: The Thirteenth International Conference on Learning Representations
Li, Z., Zhou, W., Zhao, W., Wu, K., Hu, H., Li, H.: Uni-sign: Toward unified sign language understanding at scale. In: The Thirteenth International Conference on Learning Representations
-
[41]
The Thirteenth International Conference on Learning Representations (2025)
Li, Z., Zhou, W., Zhao, W., Wu, K., Hu, H., Li, H.: Uni-sign: Toward unified sign language understanding at scale. The Thirteenth International Conference on Learning Representations (2025)
2025
-
[42]
In: Proceedings of the IEEE/CVF international conference on computer vision
Lin, J., Gan, C., Han, S.: Tsm: Temporal shift module for efficient video under- standing. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7083–7093 (2019)
2019
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, Y., He, Z., Han, K.: Hyperbolic category discovery. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9891–9900 (2025)
2025
-
[44]
Glossa8(1), 1–40 (2023)
Lutzenberger, H., Mudd, K., Stamp, R., Schembri, A.: The social structure of signing communities and lexical variation: A cross-linguistic comparison of three unrelated sign languages. Glossa8(1), 1–40 (2023)
2023
-
[45]
Oxford handbook of deaf studies, language, and educa- tion2, 267–280 (2010)
Meir, I., Sandler, W., Padden, C., Aronoff, M., Marschark, M., Spencer, P.E.: Emerging sign languages. Oxford handbook of deaf studies, language, and educa- tion2, 267–280 (2010)
2010
-
[46]
Advances in Neural Information Processing Systems33, 15871–15884 (2020)
Mohaghegh Dolatabadi, H., Erfani, S., Leckie, C.: Advflow: Inconspicuous black- box adversarial attacks using normalizing flows. Advances in Neural Information Processing Systems33, 15871–15884 (2020)
2020
-
[47]
Advances in neural information processing systems30(2017)
Nickel, M., Kiela, D.: Poincaré embeddings for learning hierarchical representa- tions. Advances in neural information processing systems30(2017)
2017
-
[48]
IEEE Transactions on Pattern Analysis & Machine Intelligence27(06), 873–891 (2005)
Ong, S.C., Ranganath, S.: Automatic sign language analysis: A survey and the future beyond lexical meaning. IEEE Transactions on Pattern Analysis & Machine Intelligence27(06), 873–891 (2005)
2005
-
[49]
Journal of Machine Learning Research22(75), 1–35 (2021)
Pérez, J., Barceló, P., Marinkovic, J.: Attention is turing-complete. Journal of Machine Learning Research22(75), 1–35 (2021)
2021
-
[50]
On the Turing Completeness of Modern Neural Network Architectures
Pérez, J., Marinković, J., Barceló, P.: On the turing completeness of modern neural network architectures. arXiv preprint arXiv:1901.03429 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[51]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Pu, M., Lim, M.K., Chong, C.Y.: Siformer: Feature-isolated transformer for effi- cient skeleton-based sign language recognition. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 9387–9396 (2024) LA-Sign 23
2024
-
[52]
Expert Systems with Applications164, 113794 (2021)
Rastgoo, R., Kiani, K., Escalera, S.: Sign language recognition: A deep survey. Expert Systems with Applications164, 113794 (2021)
2021
-
[53]
In: The Thirteenth International Conferenceon LearningRepresentations(2025),https://openreview.net/forum? id=din0lGfZFd
Saunshi, N., Dikkala, N., Li, Z., Kumar, S., Reddi, S.J.: Reasoning with latent thoughts: On the power of looped transformers. In: The Thirteenth International Conferenceon LearningRepresentations(2025),https://openreview.net/forum? id=din0lGfZFd
2025
-
[54]
arXiv preprint arXiv:2108.06011 (2021)
Schwarzschild, A., Borgnia, E., Gupta, A., Bansal, A., Emam, Z., Huang, F., Gold- blum, M., Goldstein, T.: Datasets for studying generalization from easy to hard examples. arXiv preprint arXiv:2108.06011 (2021)
-
[55]
Advances in Neural Information Processing Systems34, 6695–6706 (2021)
Schwarzschild, A., Borgnia, E., Gupta, A., Huang, F., Vishkin, U., Goldblum, M., Goldstein,T.:Canyoulearnanalgorithm?generalizingfromeasytohardproblems with recurrent networks. Advances in Neural Information Processing Systems34, 6695–6706 (2021)
2021
-
[56]
Science305(5691), 1779– 1782 (2004)
Senghas, A., Kita, S., Ozyurek, A.: Children creating core properties of language: Evidence from an emerging sign language in nicaragua. Science305(5691), 1779– 1782 (2004)
2004
-
[57]
IEEE Sensors Journal20(17), 10032–10044 (2020)
Sengupta, A., Jin, F., Zhang, R., Cao, S.: mm-pose: Real-time human skeletal posture estimation using mmwave radars and cnns. IEEE Sensors Journal20(17), 10032–10044 (2020)
2020
-
[58]
ACM Transactions on Multimedia Computing, Communications and Applications20(7), 1–19 (2024)
Shen, X., Zheng, Z., Yang, Y.: Stepnet: Spatial-temporal part-aware network for isolated sign language recognition. ACM Transactions on Multimedia Computing, Communications and Applications20(7), 1–19 (2024)
2024
-
[59]
In: European Conference on Computer Vision
Shen, Z., Liu, Z., Xing, E.: Sliced recursive transformer. In: European Conference on Computer Vision. pp. 727–744. Springer (2022)
2022
-
[60]
arXiv preprint arXiv:2006.08210 (2020)
Shimizu, R., Mukuta, Y., Harada, T.: Hyperbolic neural networks++. arXiv preprint arXiv:2006.08210 (2020)
-
[61]
Starner, T.E.: Visual recognition of american sign language using hidden markov models. Tech. rep. (1995)
1995
-
[62]
Advances in neural information processing systems21(2008)
Sutskever, I., Hinton, G.E., Taylor, G.W.: The recurrent temporal restricted boltz- mann machine. Advances in neural information processing systems21(2008)
2008
-
[63]
arXiv preprint arXiv:2012.13563 (2020)
Wang, T., Zhang, X., Sun, J.: Implicit feature pyramid network for object detec- tion. arXiv preprint arXiv:2012.13563 (2020)
-
[64]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, K., Li, Z., Zhao, W., Hu, H., Zhou, W., Li, H.: Cross-modal consistency learning for sign language recognition. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4078–4087 (2025)
2025
-
[65]
Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., Raffel, C.: mT5: A massively multilingual pre-trained text-to-text transformer. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 483–498. Association for Computational Li...
-
[66]
In: Proceedings of the AAAI conference on ar- tificial intelligence
Yan, S., Xiong, Y., Lin, D.: Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of the AAAI conference on ar- tificial intelligence. vol. 32 (2018)
2018
-
[67]
In: Workshop on Efficient Systems for Foundation Models @ ICML2023 (2023),https://openreview.net/forum?id=XpVoUnPuYV
Yang, L., Lee, K., Nowak, R.D., Papailiopoulos, D.: Looped transformers are better at learning learning algorithms. In: Workshop on Efficient Systems for Foundation Models @ ICML2023 (2023),https://openreview.net/forum?id=XpVoUnPuYV
2023
-
[68]
In: 2016 IEEE international conference on multimedia and expo (ICME)
Zhang, J., Zhou, W., Xie, C., Pu, J., Li, H.: Chinese sign language recognition with adaptive hmm. In: 2016 IEEE international conference on multimedia and expo (ICME). pp. 1–6. IEEE (2016) 24 Muxin Pu, Mei Kuan Lim, Chun Yong Chong, and Chen Change Loy
2016
-
[69]
In: Proceedings of the AAAI conference on artificial intelligence
Zhao,W.,Hu,H.,Zhou,W.,Shi,J.,Li,H.:Best:Bertpre-trainingforsignlanguage recognition with coupling tokenization. In: Proceedings of the AAAI conference on artificial intelligence. vol. 37, pp. 3597–3605 (2023)
2023
-
[70]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Zuo, R., Wei, F., Mak, B.: Natural language-assisted sign language recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 14890–14900 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.