Recognition: unknown
Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification
Pith reviewed 2026-05-14 00:38 UTC · model grok-4.3
The pith
A granular-ball coarsening algorithm reduces large graphs to subgraphs that let GCNs train faster via random sampling while preserving node classification accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a multi-granularity granular-ball graph coarsening step first collapses the original graph into a collection of balls whose time cost is linear in the number of nodes and edges; the balls then become the nodes of sampled subgraphs that serve as minibatches for GCN training, yielding both lower memory use and faster convergence without measurable loss in node-classification accuracy on large graphs.
What carries the argument
The multi-granularity granular-ball graph coarsening algorithm, which partitions nodes into balls at several scales to produce a reduced graph for subsequent random subgraph sampling.
If this is right
- The original graph scale drops adaptively, directly lowering the memory and arithmetic cost of each GCN layer.
- Coarsening time stays linear, so the preprocessing overhead remains small even as graphs grow.
- Random subgraph sampling on the coarsened balls supplies minibatches that still allow end-to-end gradient updates.
- Node classification accuracy stays competitive or better than prior large-graph GCN methods across tested datasets.
Where Pith is reading between the lines
- The same ball-based reduction could be tried on other message-passing architectures that currently rely on full-neighborhood aggregation.
- Because balls capture multiple resolutions at once, the approach may naturally handle graphs that contain both local clusters and long-range structure.
- One could test whether the linear-time property survives when the method is combined with additional feature-compression steps for graphs with very high-dimensional attributes.
Load-bearing premise
The coarsening into granular balls keeps enough of the original edges and node features that GCN layers trained only on the sampled subgraphs still recover accurate node embeddings.
What would settle it
Measure node-classification accuracy and wall-clock training time on a large benchmark graph when the method is applied versus when the same GCN is trained on the full un-coarsened graph or with an existing coarsening baseline; a drop larger than a few percentage points in accuracy at equal or higher speed would refute the claim.
Figures



read the original abstract
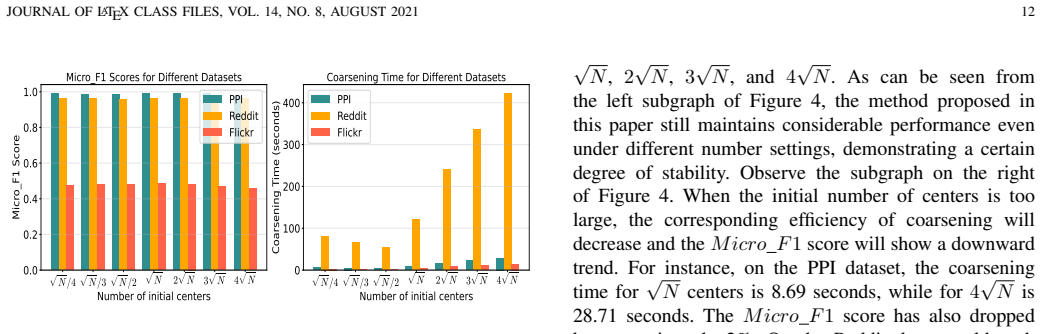
Graph Convolutional Network (GCN) is a model that can effectively handle graph data tasks and has been successfully applied. However, for large-scale graph datasets, GCN still faces the challenge of high computational overhead, especially when the number of convolutional layers in the graph is large. Currently, there are many advanced methods that use various sampling techniques or graph coarsening techniques to alleviate the inconvenience caused during training. However, among these methods, some ignore the multi-granularity information in the graph structure, and the time complexity of some coarsening methods is still relatively high. In response to these issues, based on our previous work, in this paper, we propose a new framework called Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification. Specifically, this method first uses a multi-granularity granular-ball graph coarsening algorithm to coarsen the original graph to obtain many subgraphs. The time complexity of this stage is linear and much lower than that of the exiting graph coarsening methods. Then, subgraphs composed of these granular-balls are randomly sampled to form minibatches for training GCN. Our algorithm can adaptively and significantly reduce the scale of the original graph, thereby enhancing the training efficiency and scalability of GCN. Ultimately, the experimental results of node classification on multiple datasets demonstrate that the method proposed in this paper exhibits superior performance. The code is available at https://anonymous.4open.science/r/1-141D/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a granular-ball graph coarsening framework for scaling GCN training on large graphs for node classification. It first applies a multi-granularity coarsening algorithm with claimed linear time complexity to produce subgraphs of granular balls, then randomly samples these subgraphs to form minibatches. The method is said to adaptively reduce graph scale while preserving sufficient information, yielding superior node classification performance on multiple datasets compared to prior sampling and coarsening approaches.
Significance. If the empirical results hold and the coarsening demonstrably preserves neighborhood and feature information, the work would provide a practical, low-complexity alternative to existing GNN scalability techniques such as Cluster-GCN or GraphSAGE sampling. The linear-time coarsening step and adaptive reduction are potential strengths for very large graphs where full-graph training is infeasible.
major comments (2)
- The abstract asserts linear time complexity and superior performance, yet supplies no quantitative metrics, runtime tables, accuracy deltas, dataset sizes (e.g., number of nodes/edges), or baseline comparisons. Without these in the results section, the central empirical claim cannot be evaluated and may depend on unstated post-hoc choices of granularity levels or sampling ratios.
- The multi-granularity granular-ball coarsening step (described after the abstract) does not specify whether ball-center selection or node assignment incorporates label information or homophily. If driven solely by feature density or structural clustering, heterogeneous neighborhoods will be collapsed; random subgraph sampling will then amplify any resulting label inconsistency, directly undermining the claim that accuracy is maintained or improved.
minor comments (2)
- The abstract references 'our previous work' without citation; the related-work section should explicitly distinguish the new multi-granularity extension from that prior method.
- Notation for inter-ball edge weights and the random-sampling procedure should be formalized with pseudocode or equations to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment in detail below and have made revisions to improve clarity and completeness where needed.
read point-by-point responses
-
Referee: The abstract asserts linear time complexity and superior performance, yet supplies no quantitative metrics, runtime tables, accuracy deltas, dataset sizes (e.g., number of nodes/edges), or baseline comparisons. Without these in the results section, the central empirical claim cannot be evaluated and may depend on unstated post-hoc choices of granularity levels or sampling ratios.
Authors: The results section of the manuscript already includes runtime tables, accuracy comparisons, dataset statistics (node/edge counts for Cora, CiteSeer, PubMed, ogbn-arxiv, etc.), and baseline evaluations against sampling and coarsening methods. However, we agree the abstract would benefit from explicit quantitative highlights. We have revised the abstract to incorporate key metrics: linear O(n) time complexity, specific accuracy improvements (e.g., +1.2% to +3.8% over GraphSAGE and Cluster-GCN), and dataset sizes. Granularity levels are set adaptively via a fixed density threshold, and sampling ratios are held constant across runs; we added a dedicated paragraph in Section 3.3 explaining parameter selection to eliminate any ambiguity about post-hoc tuning. revision: yes
-
Referee: The multi-granularity granular-ball coarsening step (described after the abstract) does not specify whether ball-center selection or node assignment incorporates label information or homophily. If driven solely by feature density or structural clustering, heterogeneous neighborhoods will be collapsed; random subgraph sampling will then amplify any resulting label inconsistency, directly undermining the claim that accuracy is maintained or improved.
Authors: The coarsening procedure is entirely unsupervised and uses only node features and local structural density for center selection and assignment, as inherited from our prior granular-ball framework; no label information is involved at any stage to avoid leakage. We have now explicitly stated this in the revised Section 3.1. While feature-based grouping can in principle mix labels, our multi-granularity design and subsequent experiments demonstrate that intra-ball label consistency remains high on the evaluated homophilous datasets. We added a new paragraph and an ablation table quantifying label agreement within granular balls before and after coarsening, showing that random subgraph sampling on the coarsened graph does not degrade accuracy relative to baselines. revision: partial
Circularity Check
Minor self-citation to prior granular-ball coarsening work; central algorithmic claims rest on experiments rather than self-referential derivation
specific steps
-
self citation load bearing
[Abstract]
"based on our previous work, in this paper, we propose a new framework called Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification. Specifically, this method first uses a multi-granularity granular-ball graph coarsening algorithm to coarsen the original graph to obtain many subgraphs. The time complexity of this stage is linear and much lower than that of the exiting graph coarsening methods."
The linear-time multi-granularity coarsening step and its information-preservation properties for subsequent GCN training are invoked from the authors' prior work without re-derivation here; the scalability and accuracy claims therefore inherit their justification from that self-citation, even though the present paper supplies new experimental validation of the combined pipeline.
full rationale
The paper describes an algorithmic pipeline (multi-granularity granular-ball coarsening followed by random subgraph sampling for GCN minibatches) whose performance is asserted via experiments on multiple datasets. The sole self-reference appears in the abstract as the source of the coarsening routine, but no equations, uniqueness theorems, or fitted parameters are shown to reduce the claimed linear time complexity or accuracy preservation to that citation by construction. The end-to-end node-classification results supply independent empirical content, keeping circularity low and non-load-bearing for the overall contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Generalizing graph neural networks on out-of-distribution graphs,
S. Fan, X. Wang, C. Shi, P. Cui, and B. Wang, “Generalizing graph neural networks on out-of-distribution graphs,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
work page 2023
-
[2]
Arbitrary- order proximity preserved network embedding,
Z. Zhang, P. Cui, X. Wang, J. Pei, X. Yao, and W. Zhu, “Arbitrary- order proximity preserved network embedding,” inProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018, pp. 2778–2786
work page 2018
-
[3]
Parallel and distributed graph neural networks: An in-depth concurrency analysis,
M. Besta and T. Hoefler, “Parallel and distributed graph neural networks: An in-depth concurrency analysis,”IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 2024
work page 2024
-
[4]
Es-gnn: Generalizing graph neural networks beyond homophily with edge splitting,
J. Guo, K. Huang, R. Zhang, and X. Yi, “Es-gnn: Generalizing graph neural networks beyond homophily with edge splitting,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[5]
A survey of graph neural networks in real world: Imbalance, noise, privacy and ood challenges,
W. Ju, S. Yi, Y . Wang, Z. Xiao, Z. Mao, H. Li, Y . Gu, Y . Qin, N. Yin, S. Wanget al., “A survey of graph neural networks in real world: Imbalance, noise, privacy and ood challenges,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[6]
Improving social network embedding via new second-order continuous graph neural networks,
Y . Zhang, S. Gao, J. Pei, and H. Huang, “Improving social network embedding via new second-order continuous graph neural networks,” inProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, 2022, pp. 2515–2523
work page 2022
-
[7]
Non-euclidean mixture model for social network embedding,
R. Iyer, Y . Wang, W. Wang, and Y . Sun, “Non-euclidean mixture model for social network embedding,”Advances in Neural Information Processing Systems, vol. 37, pp. 111 464–111 488, 2024
work page 2024
-
[8]
Lgb: Language model and graph neural network-driven social bot detection,
M. Zhou, D. Zhang, Y . Wang, Y .-a. Geng, Y . Dong, and J. Tang, “Lgb: Language model and graph neural network-driven social bot detection,” IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[9]
Efficient correlated subgraph searches for ai-powered drug discovery,
H. Shiokawa, Y . Naoi, and S. Matsugu, “Efficient correlated subgraph searches for ai-powered drug discovery,” inProceedings of the Thirty- Third International Joint Conference on Artificial Intelligence. p, 2024, pp. 2351–2361
work page 2024
-
[10]
Graph neural networks for recommender system,
C. Gao, X. Wang, X. He, and Y . Li, “Graph neural networks for recommender system,” inProceedings of the fifteenth ACM international conference on web search and data mining, 2022, pp. 1623–1625
work page 2022
-
[11]
Noise- enhanced graph contrastive learning for multimodal recommendation systems,
K. Shi, Y . Zhang, M. Zhang, K. Xiao, X. Hou, and Z. Li, “Noise- enhanced graph contrastive learning for multimodal recommendation systems,”Knowledge-Based Systems, p. 113766, 2025
work page 2025
-
[12]
Improved diversity-promoting collaborative metric learning for recommendation,
S. Bao, Q. Xu, Z. Yang, Y . He, X. Cao, and Q. Huang, “Improved diversity-promoting collaborative metric learning for recommendation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[13]
A survey of knowledge graph reasoning on graph types: Static, dynamic, and multi-modal,
K. Liang, L. Meng, M. Liu, Y . Liu, W. Tu, S. Wang, S. Zhou, X. Liu, F. Sun, and K. He, “A survey of knowledge graph reasoning on graph types: Static, dynamic, and multi-modal,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 9456–9478, 2024
work page 2024
-
[14]
Improved deep embedded clustering with local structure preservation
X. Guo, L. Gao, X. Liu, and J. Yin, “Improved deep embedded clustering with local structure preservation.” inIjcai, vol. 17, 2017, pp. 1753–1759
work page 2017
-
[15]
A comprehensive survey on graph neural networks,
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu, “A comprehensive survey on graph neural networks,”IEEE transactions on neural networks and learning systems, vol. 32, no. 1, pp. 4–24, 2020
work page 2020
-
[16]
Spectral networks and locally connected networks on graphs,
J. Bruna, W. Zaremba, A. Szlam, and Y . LeCun, “Spectral networks and locally connected networks on graphs,”arXiv preprint arXiv:1312.6203, 2013
-
[17]
Semi-Supervised Classification with Graph Convolutional Networks
T. Kipf, “Semi-supervised classification with graph convolutional net- works,”arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
Simplifying graph convolutional networks,
F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, and K. Weinberger, “Simplifying graph convolutional networks,” inInternational conference on machine learning. Pmlr, 2019, pp. 6861–6871
work page 2019
-
[19]
Structural deep clustering network,
D. Bo, X. Wang, C. Shi, M. Zhu, E. Lu, and P. Cui, “Structural deep clustering network,” inProceedings of the web conference 2020, 2020, pp. 1400–1410
work page 2020
-
[20]
J. Xu, Z. Chen, W. Wang, X. Hu, S.-W. Kim, and E. C. Ngai, “Cohesion: Composite graph convolutional network with dual-stage fusion for multimodal recommendation,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2025, pp. 1830–1839
work page 2025
-
[21]
W. Zhang, L. Zhang, J. Han, H. Liu, Y . Fu, J. Zhou, Y . Mei, and H. Xiong, “Irregular traffic time series forecasting based on asyn- chronous spatio-temporal graph convolutional networks,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 4302–4313
work page 2024
-
[22]
Inductive representation learning on large graphs,
W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[23]
Stochastic training of graph convolutional networks with variance reduction,
J. Chen, J. Zhu, and L. Song, “Stochastic training of graph convolutional networks with variance reduction,” inInternational Conference on Machine Learning. PMLR, 2018, pp. 942–950
work page 2018
-
[24]
Fastgcn: Fast learning with graph convo- lutional networks via importance sampling,
J. Chen, T. Ma, and C. Xiao, “Fastgcn: Fast learning with graph convo- lutional networks via importance sampling,” inInternational Conference on Learning Representations, 2018
work page 2018
-
[25]
Adaptive sampling towards fast graph representation learning,
W. Huang, T. Zhang, Y . Rong, and J. Huang, “Adaptive sampling towards fast graph representation learning,”Advances in neural information processing systems, vol. 31, 2018
work page 2018
-
[26]
Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks,
W.-L. Chiang, X. Liu, S. Si, Y . Li, S. Bengio, and C.-J. Hsieh, “Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks,” inProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 257–266
work page 2019
-
[27]
Graph- saint: Graph sampling based inductive learning method,
H. Zeng, H. Zhou, A. Srivastava, R. Kannan, and V . Prasanna, “Graph- saint: Graph sampling based inductive learning method,” inInternational Conference on Learning Representations, 2020
work page 2020
-
[28]
Graph con- densation for graph neural networks,
W. Jin, L. Zhao, S. Zhang, Y . Liu, J. Tang, and N. Shah, “Graph con- densation for graph neural networks,”arXiv preprint arXiv:2110.07580, 2021
-
[29]
Scaling up graph neural networks via graph coarsening,
Z. Huang, S. Zhang, C. Xi, T. Liu, and M. Zhou, “Scaling up graph neural networks via graph coarsening,” inProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, 2021, pp. 675–684
work page 2021
-
[30]
Graph pooling via coarsened graph info- max,
Y . Pang, Y . Zhao, and D. Li, “Graph pooling via coarsened graph info- max,” inProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, 2021, pp. 2177– 2181
work page 2021
-
[31]
Graph coarsening via supervised granular-ball for scalable graph neural network training,
S. Xia, X. Ma, Z. Liu, C. Liu, S. Zhao, and G. Wang, “Graph coarsening via supervised granular-ball for scalable graph neural network training,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 12, 2025, pp. 12 872–12 880
work page 2025
-
[32]
Gbgc: Efficient and adaptive graph coarsening via granular-ball computing,
S. Xia, G. Wang, G. Xu, S. Zhao, and G. Wang, “Gbgc: Efficient and adaptive graph coarsening via granular-ball computing,” inInternational Joint Conference on Artificial Intelligence, 2025
work page 2025
-
[33]
A fast and high quality multilevel scheme for partitioning irregular graphs,
G. Karypis and V . Kumar, “A fast and high quality multilevel scheme for partitioning irregular graphs,”SIAM Journal on scientific Computing, vol. 20, no. 1, pp. 359–392, 1998
work page 1998
-
[34]
Graph convolutional neural networks for web-scale rec- ommender systems,
R. Ying, R. He, K. Chen, P. Eksombatchai, W. L. Hamilton, and J. Leskovec, “Graph convolutional neural networks for web-scale rec- ommender systems,” inProceedings of the 24th ACM SIGKDD inter- national conference on knowledge discovery & data mining, 2018, pp. 974–983
work page 2018
-
[35]
Featured graph coarsening with similarity guarantees,
M. Kumar, A. Sharma, S. Saxena, and S. Kumar, “Featured graph coarsening with similarity guarantees,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 17 953–17 975
work page 2023
-
[36]
Condensing graphs via one-step gradient matching,
W. Jin, X. Tang, H. Jiang, Z. Li, D. Zhang, J. Tang, and B. Yin, “Condensing graphs via one-step gradient matching,” inProceedings JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 15 of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 720–730
work page 2021
-
[37]
Graph coarsening via convolution matching for scalable graph neural network training,
C. Dickens, E. Huang, A. Reganti, J. Zhu, K. Subbian, and D. Koutra, “Graph coarsening via convolution matching for scalable graph neural network training,” inCompanion Proceedings of the ACM Web Confer- ence 2024, 2024, pp. 1502–1510
work page 2024
-
[38]
Topological structure in visual perception,
L. Chen, “Topological structure in visual perception,”Science, vol. 218, no. 4573, pp. 699–700, 1982
work page 1982
-
[39]
S. Xia, G. Wang, and X. Gao, “Granular ball computing: an efficient, robust, and interpretable adaptive multi-granularity representation and computation method,”arXiv preprint arXiv:2304.11171, 2023
-
[40]
Ballkk-means: Fast adaptive clustering with no bounds,
S. Xia, D. Peng, D. Meng, C. Zhang, G. Wang, E. Giem, W. Wei, and Z. Chen, “Ballkk-means: Fast adaptive clustering with no bounds,” IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 1, pp. 87–99, 2020
work page 2020
-
[41]
Gbrs: A unified granular-ball learning model of pawlak rough set and neighborhood rough set,
S. Xia, C. Wang, G. Wang, X. Gao, W. Ding, J. Yu, Y . Zhai, and Z. Chen, “Gbrs: A unified granular-ball learning model of pawlak rough set and neighborhood rough set,”IEEE Transactions on Neural Networks and Learning Systems, 2023
work page 2023
-
[42]
Gbsvm: an efficient and robust support vector machine framework via granular- ball computing,
S. Xia, X. Lian, G. Wang, X. Gao, J. Chen, and X. Peng, “Gbsvm: an efficient and robust support vector machine framework via granular- ball computing,”IEEE Transactions on Neural Networks and Learning Systems, 2024
work page 2024
-
[43]
Unlock the cognitive generalization of deep reinforcement learning via granular ball representation,
J. Liu, J. Hao, Y . Ma, and S. Xia, “Unlock the cognitive generalization of deep reinforcement learning via granular ball representation,” inForty- first International Conference on Machine Learning, 2024
work page 2024
-
[44]
J. Xie, Y . Cheng, S. Xia, C. Hua, G. Wang, and X. Gao, “Aw-gbgae: an adaptive weighted graph autoencoder based on granular-balls for general data clustering,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[45]
Efficient quantum approxi- mate knn algorithm via granular-ball computing,
S. Xia, X. Tian, S. Yuan, and J. D.Deng, “Efficient quantum approxi- mate knn algorithm via granular-ball computing,” inInternational Joint Conference on Artificial Intelligence, 2025
work page 2025
-
[46]
Granular-ball-induced mul- tiple kernel k-means,
S. Xia, Y . Wang, L. Shen, and G. Wang, “Granular-ball-induced mul- tiple kernel k-means,” inInternational Joint Conference on Artificial Intelligence, 2025
work page 2025
-
[47]
An adaptive multi-granularity graph representation of image via granular- ball computing,
S. Xia, D. Dai, F. Chen, L. Yang, G. Wang, G. Wang, and X. Gao, “An adaptive multi-granularity graph representation of image via granular- ball computing,”IEEE Transactions on Image Processing, 2025
work page 2025
-
[48]
Rectified linear units improve restricted boltz- mann machines,
V . Nair and G. E. Hinton, “Rectified linear units improve restricted boltz- mann machines,” inProceedings of the 27th International Conference on Machine Learning, 2010, pp. 807–814
work page 2010
-
[49]
A new internal index based on density core for clustering validation,
J. Xie, Z. Xiong, Q. Dai, X. Wang, and Y . Zhang, “A new internal index based on density core for clustering validation,”Information Sciences, vol. 506, pp. 346–365, 2020
work page 2020
-
[50]
The upper bound of the optimal number of clusters in fuzzy clustering,
J. Yu and Q. Cheng, “The upper bound of the optimal number of clusters in fuzzy clustering,”Science in China Series: Information Sciences, vol. 44, pp. 119–125, 2001
work page 2001
-
[51]
Graph coarsening with neural net- works,
C. Cai, D. Wang, and Y . Wang, “Graph coarsening with neural net- works,”arXiv preprint arXiv:2102.01350, 2021
-
[52]
Relaxation-based coarsening and multiscale graph organization,
D. Ron, I. Safro, and A. Brandt, “Relaxation-based coarsening and multiscale graph organization,”Multiscale Modeling & Simulation, vol. 9, no. 1, pp. 407–423, 2011
work page 2011
-
[53]
Graph reduction with spectral and cut guarantees,
A. Loukas, “Graph reduction with spectral and cut guarantees,”Journal of Machine Learning Research, vol. 20, no. 116, pp. 1–42, 2019
work page 2019
-
[54]
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y . Ben- gio, “Graph attention networks,”arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[55]
Graph coarsening with preserved spectral properties,
Y . Jin, A. Loukas, and J. JaJa, “Graph coarsening with preserved spectral properties,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2020, pp. 4452–4462
work page 2020
-
[56]
A gromov-wasserstein geo- metric view of spectrum-preserving graph coarsening,
Y . Chen, R. Yao, Y . Yang, and J. Chen, “A gromov-wasserstein geo- metric view of spectrum-preserving graph coarsening,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 5257–5281. Guan Wangreceived her master’s degree from Chongqing University of Posts and Telecommuni- cations in 2024. She is currently a doctoral student in the School of ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.