Recognition: unknown
Survival In-Context: Amortized Bayesian Survival Analysis via Prior-Fitted Networks
Pith reviewed 2026-05-14 21:10 UTC · model grok-4.3
The pith
A model pretrained only on synthetic survival data delivers Bayesian individualized predictions in one forward pass on real datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
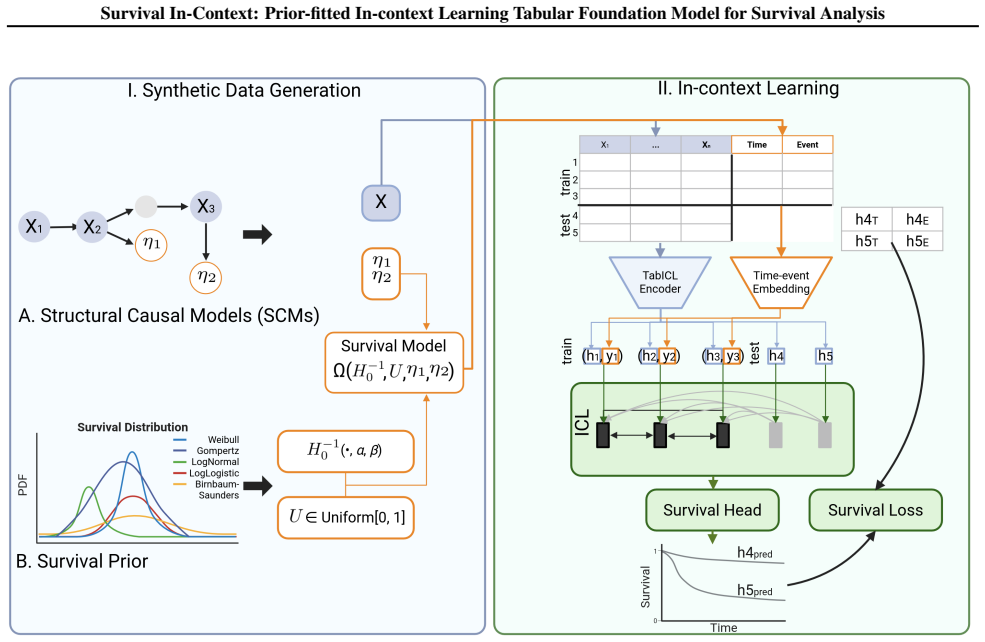
Survival In-Context (SIC) is a prior-fitted network trained exclusively on synthetic survival datasets drawn from a controllable generative process. The training objective makes SIC approximate the posterior predictive distribution under that synthetic prior, so that, at test time, feeding a new tabular dataset into the model produces individualized survival curves in a single forward pass.
What carries the argument
The synthetic survival data generation framework that explicitly controls covariate distributions, time-to-event distributions, and censoring mechanisms; this framework supplies the training distribution for the prior-fitted in-context learner.
If this is right
- Survival prediction becomes possible for new tabular datasets without collecting large labeled cohorts or running gradient updates.
- Performance advantages appear most clearly in the small- and medium-data regimes typical of clinical studies.
- The same pretrained weights can be applied across different medical domains as long as the tabular format matches the synthetic prior.
- Uncertainty quantification is obtained directly from the posterior predictive approximation rather than from post-hoc methods.
Where Pith is reading between the lines
- The approach could be applied to other censored or time-to-event problems such as reliability engineering or customer churn if suitable synthetic priors are defined.
- Extending the synthetic prior to include missing-data mechanisms might allow the model to handle incomplete covariates without separate imputation steps.
- Because inference is amortized, repeated queries on the same patient cohort become cheap, enabling real-time risk monitoring as new observations arrive.
Load-bearing premise
The distributions of covariates, event times, and censoring patterns in the synthetic prior are close enough to those in real medical survival data that the amortized inference transfers without task-specific adaptation.
What would settle it
On a collection of real survival datasets never seen during pretraining, SIC would need to produce systematically worse calibration or discrimination metrics than a well-tuned Cox model or a task-specific deep survival network trained from scratch.
Figures




read the original abstract
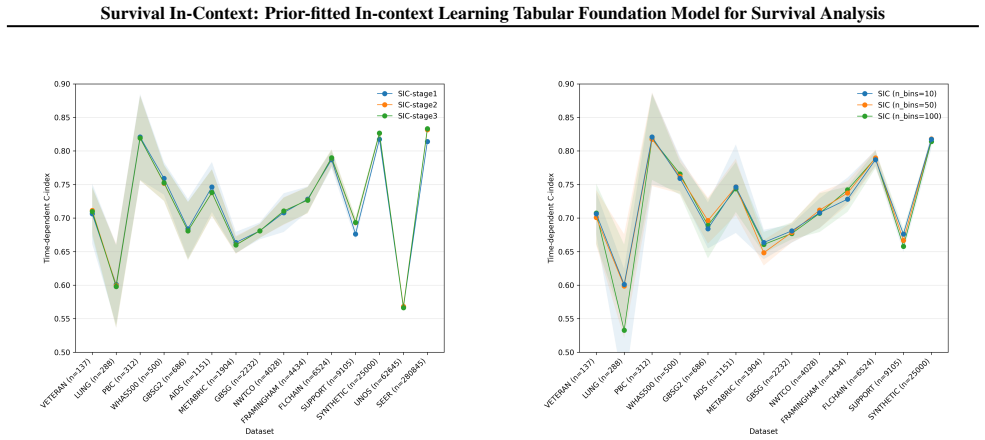
Survival analysis is crucial for many medical applications, but remains challenging for modern machine learning due to limited data, censoring, and the heterogeneity of tabular covariates. While the prior-fitted paradigm, which relies on pretraining models on large collections of synthetic datasets, has recently facilitated tabular foundation models for classification and regression, its suitability for time-to-event modeling remains unclear. We propose a flexible survival data generation framework that defines a rich survival prior with explicit control over covariates and time-event distributions. Building on this prior, we introduce Survival In-Context (SIC), a prior-fitted in-context learning model for survival analysis that is pretrained exclusively on synthetic data. SIC is trained to approximate Bayesian posterior predictive inference under the synthetic survival prior, enabling individualized survival prediction in a single forward pass, requiring no task-specific training or hyperparameter tuning. Across a broad evaluation on real-world survival datasets, SIC achieves competitive or superior performance compared to classical and deep survival models, particularly in small and medium-sized data regimes, highlighting the promise of a prior-fitted paradigm for survival analysis. The code and pretrained models will be made available upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Survival In-Context (SIC), a prior-fitted in-context learning model for survival analysis pretrained exclusively on synthetic data from a flexible survival prior that controls covariates and time-event distributions. SIC is trained to approximate Bayesian posterior predictive inference under this prior, enabling individualized survival predictions in a single forward pass with no task-specific training or hyperparameter tuning. The authors claim that across real-world survival datasets, SIC achieves competitive or superior performance relative to classical and deep survival models, especially in small- and medium-sized data regimes.
Significance. If the central claim holds, the work would establish a viable prior-fitted paradigm for survival analysis, offering amortized Bayesian inference that sidesteps per-task optimization and is particularly useful in data-limited medical settings. The explicit synthetic prior framework and planned release of code and pretrained models would strengthen reproducibility and enable follow-on work on tabular time-to-event foundation models.
major comments (2)
- [Abstract] Abstract: the claim of 'competitive or superior performance' on real-world datasets is presented without any specifics on the number of datasets, sample sizes, metrics (e.g., concordance index, integrated Brier score), statistical tests, or baseline implementations. This absence is load-bearing for the performance claim and prevents assessment of robustness or possible post-hoc selection.
- [Method / Experiments] Method and Experiments sections: the assertion that SIC approximates Bayesian posterior predictive inference under the synthetic prior requires direct verification on held-out synthetic tasks (e.g., calibration plots, KL divergence to MCMC, or posterior predictive checks). No such evidence is provided; without it, real-data gains could arise from a strong non-Bayesian predictor rather than amortized Bayesian inference, undermining the central modeling claim.
minor comments (1)
- The synthetic data generation framework is described as 'flexible' and 'rich' but lacks a concise summary table of the prior hyperparameters and their ranges; adding this would improve clarity for readers attempting to reproduce or extend the prior.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for strengthening the presentation of results and the central modeling claim. We address each point below and commit to revisions that directly incorporate the suggested clarifications and verifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'competitive or superior performance' on real-world datasets is presented without any specifics on the number of datasets, sample sizes, metrics (e.g., concordance index, integrated Brier score), statistical tests, or baseline implementations. This absence is load-bearing for the performance claim and prevents assessment of robustness or possible post-hoc selection.
Authors: We agree that the abstract is too high-level and should include concrete details to support the performance claims. In the revised version we will expand the abstract to state that evaluations were performed on 12 real-world survival datasets spanning sample sizes from 50 to 2000 observations, using concordance index and integrated Brier score as primary metrics, with comparisons against Cox proportional hazards, random survival forests, DeepSurv, and other deep baselines, and with statistical significance assessed via paired Wilcoxon tests. These specifics will be drawn directly from the experimental section without changing the underlying results. revision: yes
-
Referee: [Method / Experiments] Method and Experiments sections: the assertion that SIC approximates Bayesian posterior predictive inference under the synthetic prior requires direct verification on held-out synthetic tasks (e.g., calibration plots, KL divergence to MCMC, or posterior predictive checks). No such evidence is provided; without it, real-data gains could arise from a strong non-Bayesian predictor rather than amortized Bayesian inference, undermining the central modeling claim.
Authors: We acknowledge that the manuscript currently lacks explicit verification that the trained model approximates the Bayesian posterior predictive on held-out synthetic data. While the training procedure is explicitly designed to minimize the expected negative log-likelihood under the synthetic prior (thereby targeting the posterior predictive), we did not report calibration or MCMC comparisons in the submitted version. In the revision we will add a dedicated subsection with results on held-out synthetic tasks, including reliability diagrams for predicted survival probabilities, posterior predictive checks on event-time distributions, and, for smaller synthetic problems, KL divergence to MCMC reference posteriors. These additions will directly test whether performance gains stem from amortized Bayesian inference. revision: yes
Circularity Check
No circularity: training objective and real-data evaluation remain independent
full rationale
The paper explicitly defines a synthetic survival prior, generates datasets from it, and trains SIC via a meta-learning objective to approximate the posterior predictive under that prior. This is a standard supervised training setup whose success is not presupposed by definition. Evaluation occurs on separate real-world datasets whose distributions are not part of the training inputs, so reported performance gains cannot be reduced to a tautology or self-fit. No equation, claim, or self-citation in the provided text equates a derived result to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters controlling the synthetic survival prior
axioms (1)
- domain assumption Censoring is non-informative given covariates
invented entities (1)
-
flexible survival data generation framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
TabPFN-3: Technical Report
TabPFN-3 delivers state-of-the-art tabular prediction performance on benchmarks up to 1M rows, is up to 20x faster than prior versions, and introduces test-time scaling that beats non-TabPFN models by hundreds of Elo points.
Reference graph
Works this paper leans on
-
[1]
URL https://onlinelibrary.wiley. com/doi/abs/10.1002/sim.5452. Bender, R., Augustin, T., and Blettner, M. Gen- erating survival times to simulate cox proportional hazards models.Statistics in Medicine, 24(11): 1713–1723, 2005. doi: https://doi.org/10.1002/sim
-
[2]
On the Opportunities and Risks of Foundation Models
URL https://onlinelibrary.wiley. com/doi/abs/10.1002/sim.2059. Beran, R. Nonparametric regression with randomly cen- sored survival data.Technical report, University of Cali- fornia, Berkeley, 01 1981. Bommasani, R., Hudson, D. A., Adeli, E., Altman, R. B., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosse- lut, A., Brunskill, E., Brynjolfsson, E....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1002/sim.2059 2059
-
[3]
cc/paper_files/paper/2020/file/ 1457c0d6bfcb4967418bfb8ac142f64a-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ 1457c0d6bfcb4967418bfb8ac142f64a-Paper. pdf. Chen, G. Nearest neighbor and kernel survival analysis: Nonasymptotic error bounds and strong consistency rates. In Chaudhuri, K. and Salakhutdinov, R. (eds.),Proceed- ings of the 36th International Conference on Machine Learning, volume 97 ofProc...
2020
-
[4]
URL https://proceedings.mlr.press/ v126/chen20a.html. Chen, G. H. A general framework for visualizing embed- ding spaces of neural survival analysis models based on angular infor- mation. In Mortazavi, B. J., Sarker, T., Beam, A., and Ho, J. C. (eds.),Proceedings of the Conference on Health, Inference, and Learning, volume 209 ofProceedings of Machine Lea...
-
[5]
Journal of Open Source Software , author =
URL https://proceedings.mlr.press/ v151/danks22a.html. Davidson-Pilon, C. lifelines: survival analysis in python. Journal of Open Source Software, 4(40):1317, 2019. doi: 10.21105/joss.01317. URL https://doi.org/10. 21105/joss.01317. Demarqui, F.survstan: Fitting Survival Regression Mod- els via ’Stan’, 2025. URL https://github.com/ fndemarqui/survstan. R ...
-
[6]
URL https://openreview.net/forum? id=jZqCqpCLdU. Etezadi-Amoli, J. and Ciampi, A. Extended haz- ard regression for censored survival data with covari- ates: A spline approximation for the baseline hazard function.Biometrics, 43(1):181–192, 1987. ISSN 0006341X, 15410420. URL http://www.jstor. org/stable/2531958. Gardner, J. P., Perdomo, J. C., and Schmidt,...
work page internal anchor Pith review doi:10.48550/arxiv 1987
-
[7]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
URL https://openreview.net/forum? id=cp5PvcI6w8_. Hollmann, N., M ¨uller, S., Purucker, L., Krishnakumar, A., K ¨orfer, M., Hoo, S., Schirrmeister, R., and Hutter, F. Accurate predictions on small data with a tabular foundation model.Nature, 637:319–326, 01 2025. doi: 10.1038/s41586-024-08328-6. Hoo, S. B., M ¨uller, S., Salinas, D., and Hutter, F. The ta...
-
[8]
URL https://openreview.net/forum? id=QV4P8Csw17. Kleinbaum, D. G. and Klein, M.Survival Analysis: A Self-Learning Text. Statistics for Biology and Health. Springer, New York, 3 edition, 2012. ISBN 978-1-4419- 6645-2. doi: 10.1007/978-1-4419-6646-9. URL https: //doi.org/10.1007/978-1-4419-6646-9. Knottenbelt, W., McGough, W., Wray, R., Zhang, W. Z., Liu, J...
-
[9]
URL https://onlinelibrary.wiley. com/doi/abs/10.1002/cnr2.1210. e1210 CNR2-19-0011.R2. Kvamme, H., Borgan, Ø., and Scheel, I. Time-to-event prediction with neural networks and cox regres- sion.ArXiv, abs/1907.00825, 2019. URL https: //api.semanticscholar.org/CorpusID: 195767074. Leao, J., Leiva, V ., Saulo, H., and Tomazella, V . Birnbaum–saunders frailty...
-
[10]
URL https://openreview.net/forum? id=pIZxEOZCId. Mikhael, P. G., Wohlwend, J., Yala, A., Karstens, L., Xi- ang, J., Takigami, A. K., Bourgouin, P. P., Chan, P., Mrah, S., Amayri, W., Juan, Y .-H., Yang, C.-T., Wan, Y .-L., Lin, G., Sequist, L. V ., Fintelmann, F. J., and Barzilay, R. Sybil: A validated deep learning model to predict future lung cancer ris...
-
[11]
org/CorpusID:251467802
URL https://api.semanticscholar. org/CorpusID:251467802. M¨uller, S., Hollmann, N., Arango, S. P., Grabocka, J., and Hutter, F. Transformers can do bayesian inference. In International Conference on Learning Representations,
-
[12]
M¨uller, S., Reuter, A., Hollmann, N., R ¨ugamer, D., and Hutter, F
URL https://openreview.net/forum? id=KSugKcbNf9. M¨uller, S., Reuter, A., Hollmann, N., R ¨ugamer, D., and Hutter, F. Position: The future of bayesian predic- tion is prior-fitted. InForty-second International Con- ference on Machine Learning Position Paper Track,
-
[13]
Nagler, T
URL https://openreview.net/forum? id=5Hpm74b1Ga. Nagler, T. Statistical foundations of prior-data fitted net- works. In Krause, A., Brunskill, E., Cho, K., En- gelhardt, B., Sabato, S., and Scarlett, J. (eds.),Pro- ceedings of the 40th International Conference on Ma- chine Learning, volume 202 ofProceedings of Machine Learning Research, pp. 25660–25676. P...
-
[14]
Nagpal, C., Li, X., and Dubrawski, A
URL https://proceedings.mlr.press/ v202/nagler23a.html. Nagpal, C., Li, X., and Dubrawski, A. Deep survival ma- chines: Fully parametric survival regression and repre- sentation learning for censored data with competing risks. IEEE Journal of Biomedical and Health Informatics, 25 (8):3163–3175, 2021. doi: 10.1109/JBHI.2021.3052441. Norcliffe, A., Cebere, ...
-
[15]
URL https://proceedings.mlr.press/ v206/norcliffe23a.html. Norman, P. A., Li, W., Jiang, W., and Chen, B. E. Deep- aft: A nonlinear accelerated failure time model with artificial neural network.Statistics in Medicine, 43 (19):3689–3701, 2024. doi: https://doi.org/10.1002/sim. 10152. URL https://onlinelibrary.wiley. com/doi/abs/10.1002/sim.10152. Pearl, J....
work page doi:10.1002/sim 2024
-
[16]
Ranganath, R., Perotte, A., Elhadad, N., and Blei, D
URL https://proceedings.mlr.press/ v139/radford21a.html. Ranganath, R., Perotte, A., Elhadad, N., and Blei, D. Deep survival analysis. In Doshi-Velez, F., Fackler, J., Kale, D., Wallace, B., and Wiens, J. (eds.),Proceedings of the 1st Machine Learning for Healthcare Conference, volume 56 ofProceedings of Machine Learning Research, pp. 101– 114, Northeaste...
2016
-
[17]
Seletkov, D., Starck, S., Erdur, A
URL https://openreview.net/forum? id=OaNbl9b56B. Seletkov, D., Starck, S., Erdur, A. C., Zhang, Y ., Rueckert, D., and Braren, R. Whole-body representation learning for competing preclinical disease risk assessment. In Wu, S., Shabestari, B., and Xing, L. (eds.),Applications of Medical Artificial Intelligence, pp. 184–194, Cham, 2026. Springer Nature Swit...
2026
-
[18]
Tang, W., Ma, J., Mei, Q., and Zhu, J
URL https://openreview.net/forum? id=XCQzwpR9jE. Tang, W., Ma, J., Mei, Q., and Zhu, J. Soden: A scal- able continuous-time survival model through ordinary differential equation networks.Journal of Machine Learning Research, 23(34):1–29, 2022. URL http: //jmlr.org/papers/v23/20-900.html. Tesfay, B., Getinet, T., and Derso, E. A. Survival analysis of time ...
-
[19]
Zhu, H., Xia, X., Yu, C., Adnan, A., Liu, S., and Du, Y
URL https://proceedings.mlr.press/ v202/zhu23k.html. Zhu, H., Xia, X., Yu, C., Adnan, A., Liu, S., and Du, Y . Application of weibull model for survival of patients with gastric cancer.BMC gastroenterology, 11:1, 01 2011. doi: 10.1186/1471-230X-11-1. Zupan, B., Demsar, J., Kattan, M. W., Beck, J., and Bratko, I. Machine learning for survival analysis: a c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.