Recognition: 2 theorem links
· Lean TheoremTabPFN-3: Technical Report
Pith reviewed 2026-05-15 06:01 UTC · model grok-4.3
The pith
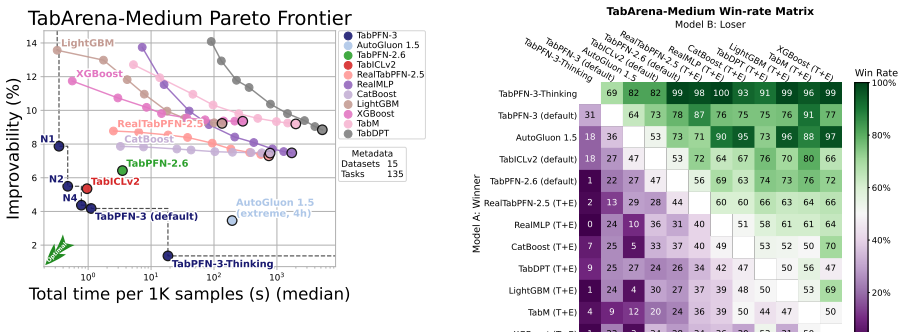
TabPFN-3 outperforms all tuned and ensembled models on the TabArena tabular benchmark with a single forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TabPFN-3 achieves state-of-the-art performance on tabular prediction tasks by scaling a transformer-based foundation model pretrained on synthetic data. On the TabArena benchmark, a single forward pass surpasses all other models including tuned and ensembled baselines, while dominating the speed-performance trade-off. The TabPFN-3-Plus variant, leveraging test-time compute, further improves results by over 200 Elo points overall and 420 on large subsets, outperforming AutoGluon while being ten times faster. The approach extends to new domains with new state-of-the-art results on relational benchmarks and tabular-text tasks, all while being up to twenty times faster than its predecessor and s
What carries the argument
Synthetic pretraining combined with test-time compute scaling in a transformer architecture for tabular data.
If this is right
- Beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M rows and 200 features.
- Ranks first on datasets with many classes.
- Achieves new SOTA on RelBenchV1 for relational data.
- Provides SOTA on TabSTAR for tabular-text data via TabPFN-3-Plus.
- Enables up to 120x faster SHAP-value computation and ranks 2nd on fev-bench via TabPFN-TS-3.
Where Pith is reading between the lines
- The reliance on synthetic data may allow the model to avoid privacy issues associated with real data training.
- Test-time scaling opens the door to further performance improvements by allocating more compute during prediction without retraining.
- The speed gains could make foundation models practical for real-time tabular applications where traditional methods were too slow.
- Integration improvements suggest easier adoption in existing pipelines for time-series and interpretability tasks.
Load-bearing premise
The synthetic data used for pretraining sufficiently represents the distribution of real-world tabular datasets to enable strong generalization.
What would settle it
Evaluating TabPFN-3 on a large collection of previously unseen real-world tabular datasets collected after the model's release to check if the performance margins hold.
Figures









































read the original abstract
Tabular data underpins most high-value prediction problems in science and industry, and TabPFN has driven the foundation model revolution for this modality. Designed with feedback from our users, TabPFN-3 builds on this foundation to scale state-of-the-art performance to datasets with 1M training rows and substantially reduce training and inference time. Pretrained exclusively on synthetic data from our prior, TabPFN-3 dramatically pushes the frontier of tabular prediction and brings substantial gains on time series, relational, and tabular-text data. On the standard tabular benchmark TabArena, a forward pass of TabPFN-3 outperforms all other models, including tuned and ensembled baselines, by a significant margin, and pareto-dominates the speed/performance frontier. On more diverse datasets, TabPFN-3 ranks first on datasets with many classes, and beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M training rows and 200 features. TabPFN-3 introduces test-time compute scaling to tabular foundation models. Our API offering TabPFN-3-Plus (Thinking) exploits this to beat all non-TabPFN models by over 200 Elo on TabArena, rising to 420 Elo on the largest data subset, and outperforms AutoGluon 1.5 extreme while being 10x faster, without using LLMs, real data, internet search or any other model besides TabPFN. TabPFN-3 extends the capabilities of our models, enabling SOTA prediction on relational data (new SOTA foundation model on RelBenchV1) and tabular-text data (SOTA on TabSTAR via TabPFN-3-Plus); and improves existing integrations: a specialized checkpoint, TabPFN-TS-3, ranks 2nd on the time-series benchmark fev-bench, and SHAP-value computation is up to 120x faster. TabPFN-3 achieves this performance while being up to 20x faster than TabPFN-2.5. In addition, a reduced KV cache and row-chunking scale to 1M rows on one H100 with fast inference speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TabPFN-3, a scaled tabular foundation model pretrained exclusively on synthetic data from prior work. It claims a single forward pass outperforms all tuned and ensembled baselines on the TabArena benchmark while Pareto-dominating the speed-performance frontier; TabPFN-3-Plus (Thinking) achieves >200 Elo gains (up to 420 on large subsets) over non-TabPFN models, beats AutoGluon 1.5 extreme at 10x speed, and delivers new SOTAs on RelBenchV1 (relational) and TabSTAR (tabular-text) plus second place on fev-bench (time-series). Additional engineering claims include up to 20x speedups over TabPFN-2.5, 120x faster SHAP, and scaling to 1 M rows on one H100 via reduced KV cache and row chunking.
Significance. If the empirical results hold after rigorous validation, the work would represent a meaningful advance for tabular foundation models by demonstrating that synthetic pretraining plus test-time compute scaling can surpass heavily tuned gradient-boosted trees and AutoML systems on public benchmarks while delivering substantial inference speed-ups and cross-modal extensions. The reported ability to handle up to 1 M rows without real-data fine-tuning would be practically significant for industry deployments.
major comments (2)
- [Abstract] Abstract and Experimental Results: The headline claims of 'significant margin' outperformance on TabArena and 200–420 Elo gains for TabPFN-3-Plus are presented without error bars, statistical significance tests, exact train/test splits, or ablation studies on the synthetic generator, rendering the margins unverifiable from the provided information.
- [Pretraining Methodology] Pretraining section: The statement that pretraining uses 'exclusively synthetic data from our prior' lacks any decontamination protocol, held-out real-data validation set, or ablation freezing the generator before benchmark exposure; without these, the reported superiority over tuned baselines on TabArena risks circularity if the generator's feature/label/missingness distributions were calibrated to the evaluation suites.
minor comments (1)
- [Abstract] Clarify the precise mechanism of 'test-time compute scaling' in TabPFN-3-Plus (Thinking) and confirm it uses only TabPFN internals with no external models or search.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our technical report. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the presentation of our results without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experimental Results: The headline claims of 'significant margin' outperformance on TabArena and 200–420 Elo gains for TabPFN-3-Plus are presented without error bars, statistical significance tests, exact train/test splits, or ablation studies on the synthetic generator, rendering the margins unverifiable from the provided information.
Authors: We agree that additional statistical details would improve verifiability. In the revised manuscript we have added error bars (standard deviation over 10 independent runs with different random seeds) to all TabArena metrics, included Wilcoxon signed-rank tests confirming significance (p < 0.01 for the headline margins), explicitly cited the exact TabArena train/test splits per the benchmark protocol, and inserted an appendix ablation varying the synthetic generator's key hyperparameters while measuring downstream Elo impact. revision: yes
-
Referee: [Pretraining Methodology] Pretraining section: The statement that pretraining uses 'exclusively synthetic data from our prior' lacks any decontamination protocol, held-out real-data validation set, or ablation freezing the generator before benchmark exposure; without these, the reported superiority over tuned baselines on TabArena risks circularity if the generator's feature/label/missingness distributions were calibrated to the evaluation suites.
Authors: The generator was developed and frozen in prior work before TabArena and the other cited benchmarks existed, so no direct calibration occurred. We have added a new subsection to the Pretraining section that (1) describes the decontamination protocol (Kolmogorov-Smirnov tests on held-out real tabular samples to confirm distribution mismatch), (2) references a held-out real-data validation set used during generator development, and (3) reports an ablation in which the generator parameters are frozen prior to any benchmark exposure, showing that TabPFN-3 performance remains essentially unchanged. revision: yes
Circularity Check
Minor self-citation to prior synthetic generator; benchmark results remain externally validated
full rationale
The paper reports empirical wins on independent public benchmarks (TabArena, RelBenchV1, fev-bench) after pretraining exclusively on synthetic data referenced to prior work. No equations, fitted parameters, or derivations reduce the claimed Elo margins, speedups, or Pareto dominance to quantities defined by the evaluation suites themselves. The single self-reference to 'our prior' for the data generator is present but does not carry the load-bearing justification for the performance numbers, which rest on external test sets.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pretrained exclusively on synthetic data from our prior... Structural Causal Model (SCM) prior
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage architecture: Feature distribution embedding... Feature aggregation... In-context learning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, Frank Hutter, et al. Tabarena: A living benchmark for machine learning on tabular data.arXiv preprint arXiv:2506.16791, 2025
-
[2]
Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander Smola. Autogluon-tabular: Robust and accurate automl for structured data.arXiv preprint arXiv:2003.06505, 2020
-
[3]
Katharine E Henry, David N Hager, Peter J Pronovost, and Suchi Saria. A targeted real-time early warning score (trewscore) for septic shock.Science translational medicine, 7(299):299ra122–299ra122, 2015
work page 2015
-
[4]
Mimic-iii, a freely accessible critical care database.Scientific data, 3(1):1–9, 2016
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. Mimic-iii, a freely accessible critical care database.Scientific data, 3(1):1–9, 2016
work page 2016
-
[5]
Yaakov Ophir, Refael Tikochinski, Christa SC Asterhan, Itay Sisso, and Roi Reichart. Deep neural networks detect suicide risk from textual facebook posts.Scientific reports, 10(1):16685, 2020
work page 2020
-
[6]
Hussein A Abdou and John Pointon. Credit scoring, statistical techniques and evaluation criteria: a review of the literature.Intelligent systems in accounting, finance and management, 18(2-3):59–88, 2011
work page 2011
-
[7]
Amir E Khandani, Adlar J Kim, and Andrew W Lo. Consumer credit-risk models via machine- learning algorithms.Journal of Banking & Finance, 34(11):2767–2787, 2010
work page 2010
-
[8]
Stefan Lessmann, Bart Baesens, Hsin-Vonn Seow, and Lyn C Thomas. Benchmarking state-of- the-art classification algorithms for credit scoring: An update of research.European journal of operational research, 247(1):124–136, 2015
work page 2015
-
[9]
Thyago P Carvalho, Fabrízzio AAMN Soares, Roberto Vita, Roberto da P Francisco, João P Basto, and Symone GS Alcalá. A systematic literature review of machine learning methods applied to predictive maintenance.Computers & industrial engineering, 137:106024, 2019
work page 2019
-
[10]
Jovani Dalzochio, Rafael Kunst, Edison Pignaton, Alecio Binotto, Srijnan Sanyal, Jose Favilla, and Jorge Barbosa. Machine learning and reasoning for predictive maintenance in industry 4.0: Current status and challenges.Computers in industry, 123:103298, 2020
work page 2020
-
[11]
Pierre Baldi, Peter Sadowski, and Daniel Whiteson. Searching for exotic particles in high-energy physics with deep learning.Nature communications, 5(1):4308, 2014
work page 2014
-
[12]
Alexander Dunn, Qi Wang, Alex Ganose, Daniel Dopp, and Anubhav Jain. Benchmarking materials property prediction methods: the matbench test set and automatminer reference algorithm.npj Computational Materials, 6(1):138, 2020
work page 2020
-
[13]
Tabular data: Deep learning is not all you need.Information fusion, 81:84–90, 2022
Ravid Shwartz-Ziv and Amitai Armon. Tabular data: Deep learning is not all you need.Information fusion, 81:84–90, 2022
work page 2022
-
[14]
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35: 507–520, 2022
work page 2022
-
[15]
Tabrepo: A large scale repository of tabular model evaluations and its automl applications
David Salinas and Nick Erickson. Tabrepo: A large scale repository of tabular model evaluations and its automl applications. InAutoML Conference 2024 (ABCD Track), 2024
work page 2024
-
[16]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second.arXiv preprint arXiv:2207.01848, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025. ISSN 1476-4687. doi: 10.1038/ s41586-024-08328-6. URLhttps://doi.org/10.1038/s41586-024-08328-6. 25
-
[18]
Tabpfn-2.5: Advancing the state of the art in tabular foundation models, 2025
Léo Grinsztajn, Klemens Flöge, Oscar Key, Brendan Roof Felix Birkel, Phil Jund, Benjamin Jäger, Adrian Hayler, Dominik Safaric, Felix Jablonski Simone Alessi, Mihir Manium, Rosen Yu, Anurag Garg, Jake Robertson, Shi Bin (Liam) Hoo, Vladyslav Moroshan, Magnus Bühler, Lennart Purucker, Clara Cornu, Lilly Charlotte Wehrhahn, Alessandro Bonetto, Sauraj Gambhi...
work page 2025
-
[19]
Shi Bin Hoo, Samuel Müller, David Salinas, and Frank Hutter. The tabular foundation model tabpfn outperforms specialized time series forecasting models based on simple features. InNeurIPS Workshop on Time Series in the Age of Large Models, 2024
work page 2024
-
[20]
Do-pfn: In-context learning for causal effect estimation.arXiv preprint arXiv:2506.06039, 2025
Jake Robertson, Arik Reuter, Siyuan Guo, Noah Hollmann, Frank Hutter, and Bernhard Schölkopf. Do-pfn: In-context learning for causal effect estimation.arXiv preprint arXiv:2506.06039, 2025
-
[21]
Vahid Balazadeh, Hamidreza Kamkari, Valentin Thomas, Benson Li, Junwei Ma, Jesse C. Cresswell, and Rahul G. Krishnan. Causalpfn: Amortized causal effect estimation via in-context learning,
- [22]
-
[23]
Foundation models for causal inference via prior-data fitted networks, 2025
Yuchen Ma, Dennis Frauen, Emil Javurek, and Stefan Feuerriegel. Foundation models for causal inference via prior-data fitted networks, 2025. URLhttps://arxiv.org/abs/2506.10914
-
[24]
RosenTing-YingYu, CyrilPicard, andFaezAhmed. Git-bo: High-dimensionalbayesianoptimization with tabular foundation models.arXiv preprint arXiv:2505.20685, 2025. doi: 10.48550/arXiv.2505. 20685. URLhttps://arxiv.org/abs/2505.20685
-
[25]
Adrian Hayler, Xingyue Huang, İsmail İlkan Ceylan, Michael Bronstein, and Ben Finkelshtein. Bringing graphs to the table: Zero-shot node classification via tabular foundation models.arXiv preprint arXiv:2509.07143, 2025. doi: 10.48550/arXiv.2509.07143. URLhttps://arxiv.org/abs/ 2509.07143
-
[26]
Turning tabular foundation models into graph foundation models, 2025
Dmitry Eremeev, Gleb Bazhenov, Oleg Platonov, Artem Babenko, and Liudmila Prokhorenkova. Turning tabular foundation models into graph foundation models, 2025. URLhttps://arxiv.org/ abs/2508.20906
-
[27]
Interpretable machine learning for tabpfn
David Rundel, Julius Kobialka, Constantin von Crailsheim, Matthias Feurer, Thomas Nagler, and David Rügamer. Interpretable machine learning for tabpfn. InWorld Conference on Explainable Artificial Intelligence, pages 465–476. Springer, 2024
work page 2024
-
[28]
Han-Jia Ye, Si-Yang Liu, and Wei-Lun Harry Chao. A closer look at tabpfn v2: Understanding its strengths and extending its capabilities.Advances in Neural Information Processing Systems, 38: 135605–135637, 2026
work page 2026
-
[29]
Gradient free deep reinforcement learning with tabpfn.arXiv preprint arXiv:2509.11259, 2025
David Schiff, Ofir Lindenbaum, and Yonathan Efroni. Gradient free deep reinforcement learning with tabpfn.arXiv preprint arXiv:2509.11259, 2025. doi: 10.48550/arXiv.2509.11259. URL https://arxiv.org/abs/2509.11259
-
[30]
TabICL: A tabular foundation model for in-context learning on large data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A tabular foundation model for in-context learning on large data. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=0VvD1PmNzM
work page 2025
-
[31]
TabICLv2: A better, faster, scalable, and open tabular foundation model
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICLv2: A better, faster, scalable, and open tabular foundation model. InInternational Conference on Machine Learning, 2026
work page 2026
- [32]
-
[33]
Better by default: Strong pre-tuned mlps and boosted trees on tabular data
David Holzmüller, Léo Grinsztajn, and Ingo Steinwart. Better by default: Strong pre-tuned mlps and boosted trees on tabular data. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ul- rich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Process- ing Systems 38: Annual Conference on Neural Information Proce...
work page 2024
-
[34]
FlashAttention-3: fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: fast and accurate attention with asynchrony and low-precision. InProceed- ings of the 38th International Conference on Neural Information Processing Systems, NeurIPS ’24, Red Hook, NY, USA, 2024. Curran Associates Inc. ISBN 9798331314385
work page 2024
-
[35]
shapiq: Shapley interactions for machine learning
Maximilian Muschalik, Hubert Baniecki, Fabian Fumagalli, Patrick Kolpaczki, Barbara Hammer, and Eyke Hüllermeier. shapiq: Shapley interactions for machine learning. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=knxGmi6SJi
work page 2024
- [36]
-
[37]
Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, Huai-Hong Yin, Tao Zhou, Jun-Peng Jiang, and Han-Jia Ye. Talent: A tabular analytics and learning toolbox.Journal of Machine Learning Research, 26 (226):1–16, 2025. URLhttp://jmlr.org/papers/v26/25-0512.html
work page 2025
-
[38]
TabSTAR: A Tabular Foundation Model for Tabular Data with Text Fields
Alan Arazi, Eilam Shapira, and Roi Reichart. TabSTAR: A Tabular Foundation Model for Tabular Data with Text Fields. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Information Processing Systems, volume 38, pages 172108–172161. Curran Associates, Inc., 2025. URLhttps://proceedings.neurips.cc/p...
work page 2025
-
[39]
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: unbiased boosting with categorical features.Advances in neural information processing systems, 31, 2018
work page 2018
-
[40]
Lightgbm: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qi- wei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vish- wanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems 30, pages 3146–3154. Curran Associates, ...
work page 2017
-
[41]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016
work page 2016
-
[42]
Tabm: Advancing tabular deep learning with parameter-efficient ensembling
Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. Tabm: Advancing tabular deep learning with parameter-efficient ensembling. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=Sd4wYYOhmY
work page 2025
-
[43]
Revisiting nearest neighbor for tabular data: A deep tabular baseline two decades later
Han-Jia Ye, Huai-Hong Yin, De-Chuan Zhan, and Wei-Lun Chao. Revisiting nearest neighbor for tabular data: A deep tabular baseline two decades later. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=JytL2MrlLT
work page 2025
-
[44]
xRFM: Accurate, scalable, and interpretable feature learning models for tabular data
Daniel Beaglehole, David Holzmüller, Adityanarayanan Radhakrishnan, and Mikhail Belkin. xrfm: Accurate, scalable, and interpretable feature learning models for tabular data, 2025. URLhttps: //arxiv.org/abs/2508.10053
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Hamidreza Kamkari, Alex Labach, Jesse C. Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L. Caterini, and Maksims Volkovs. Tabdpt: Scaling tabular foundation models on real data, 2025. URLhttps://arxiv.org/abs/2410.18164
-
[46]
Xingxuan Zhang, Gang Ren, Han Yu, Hao Yuan, Hui Wang, Jiansheng Li, Jiayun Wu, Lang Mo, Li Mao, Mingchao Hao, Ningbo Dai, Renzhe Xu, Shuyang Li, Tianyang Zhang, Yue He, Yuanrui Wang, Yunjia Zhang, Zijing Xu, Dongzhe Li, Fang Gao, Hao Zou, Jiandong Liu, Jiashuo Liu, Jiawei Xu, Kaijie Cheng, Kehan Li, Linjun Zhou, Qing Li, Shaohua Fan, Xiaoyu Lin, Xinyan Ha...
-
[47]
Xiyuan Zhang, Danielle C. Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W. Mahoney, Cuixiong Hu, Huzefa Rangwala, George Karypis, and Bernie Wang. Mitra: Mixed synthetic priors for enhancing tabular foundation models. InThe Thirty-ninth Annual Conference on Neural Information Proc...
work page 2025
-
[48]
Xingjian Shi, Jonas Mueller, Nick Erickson, Mu Li, and Alexander J Smola. Benchmarking multimodal automl for tabular data with text fields.arXiv preprint arXiv:2111.02705, 2021
-
[49]
Léo Grinsztajn, Edouard Oyallon, Myung Jun Kim, and Gaël Varoquaux. Vectorizing string entries for data processing on tables: when are larger language models better?arXiv preprint arXiv:2312.09634, 2023
-
[50]
Carte: pretraining and transfer for tabular learning.arXiv preprint arXiv:2402.16785, 2024
Myung Jun Kim, Léo Grinsztajn, and Gaël Varoquaux. Carte: pretraining and transfer for tabular learning.arXiv preprint arXiv:2402.16785, 2024
-
[51]
Regression quantiles.Econometrica, 46(1):33–50, 1978
Roger Koenker and Gilbert Bassett. Regression quantiles.Econometrica, 46(1):33–50, 1978. ISSN 00129682, 14680262. URLhttp://www.jstor.org/stable/1913643
-
[52]
Quantile regression forests.Journal of Machine Learning Research, 7:983–999, 2006
Nicolai Meinshausen. Quantile regression forests.Journal of Machine Learning Research, 7:983–999, 2006
work page 2006
-
[53]
F., Turkmen, C., Stella, L., Erickson, N., Guerron, P., Bohlke-Schneider, M., and Wang, Y
Oleksandr Shchur, Abdul Fatir Ansari, Caner Turkmen, Lorenzo Stella, Nick Erickson, Pablo Guerron, Michael Bohlke-Schneider, and Yuyang Wang. fev-bench: A realistic benchmark for time series forecasting.arXiv preprint arXiv:2509.26468, 2025
-
[54]
Chronos-2: From Univariate to Universal Forecasting
Abdul Fatir Ansari, Oleksandr Shchur, Jaris Küken, Andreas Auer, Boran Han, Pedro Mercado, Syama Sundar Rangapuram, Huibin Shen, Lorenzo Stella, Xiyuan Zhang, Mononito Goswami, Shubham Kapoor, Danielle C. Maddix, Pablo Guerron, Tony Hu, Junming Yin, Nick Erickson, Prateek Mutalik Desai, Hao Wang, Huzefa Rangwala, George Karypis, Yuyang Wang, and Michael B...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Tirex: Zero-shot forecasting across long and short horizons with enhanced in-context learning
Andreas Auer, Patrick Podest, Daniel Klotz, Sebastian Böck, Günter Klambauer, and Sepp Hochreiter. TiRex: Zero-Shot Forecasting Across Long and Short Horizons with Enhanced In- Context Learning. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://arxiv.org/abs/2505.23719
-
[56]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine ...
work page 2024
-
[57]
KumoRFM-2: Scaling Foundation Models for Relational Learning
Valter Hudovernik, Federico López, Vid Kocijan, Akihiro Nitta, Jan Eric Lenssen, Jure Leskovec, and Matthias Fey. Kumorfm-2: Scaling foundation models for relational learning, 2026. URL https://arxiv.org/abs/2604.12596
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Relgnn: Composite message passing for relational deep learning, 2025
Tianlang Chen, Charilaos Kanatsoulis, and Jure Leskovec. Relgnn: Composite message passing for relational deep learning, 2025. URLhttps://arxiv.org/abs/2502.06784
-
[59]
Inductive Representation Learning on Large Graphs
William L. Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large graphs, 2018. URLhttps://arxiv.org/abs/1706.02216
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[60]
Kanatsoulis, Rishi Puri, Matthias Fey, and Jure Leskovec
Vijay Prakash Dwivedi, Sri Jaladi, Yangyi Shen, Federico López, Charilaos I. Kanatsoulis, Rishi Puri, Matthias Fey, and Jure Leskovec. Relational graph transformer, 2026. URLhttps://arxiv. org/abs/2505.10960
-
[61]
Kumorfm: A foundation model for in-context learning on relational data.Kumo.ai, 2025
Matthias Fey, Vid Kocijan, Federico Lopez, Jan Eric Lenssen, and Jure Leskovec. Kumorfm: A foundation model for in-context learning on relational data.Kumo.ai, 2025. URL https: //kumo.ai/research/kumo_relational_foundation_model.pdf. 28
work page 2025
-
[62]
Griffin: Towards a graph-centric relational database foundation model, 2025
Yanbo Wang, Xiyuan Wang, Quan Gan, Minjie Wang, Qibin Yang, David Wipf, and Muhan Zhang. Griffin: Towards a graph-centric relational database foundation model, 2025. URL https://arxiv.org/abs/2505.05568
-
[63]
Re- lational transformer: Toward zero-shot foundation models for relational data, 2026
Rishabh Ranjan, Valter Hudovernik, Mark Znidar, Charilaos Kanatsoulis, Roshan Upendra, Mahmoud Mohammadi, Joe Meyer, Tom Palczewski, Carlos Guestrin, and Jure Leskovec. Re- lational transformer: Toward zero-shot foundation models for relational data, 2026. URL https://arxiv.org/abs/2510.06377
-
[64]
Rdblearn: Simple in-context prediction over relational databases, 2026
Yanlin Zhang, Linjie Xu, Quan Gan, David Wipf, and Minjie Wang. Rdblearn: Simple in-context prediction over relational databases, 2026. URLhttps://arxiv.org/abs/2602.18495
-
[65]
Lenssen, Yiwen Yuan, Zecheng Zhang, Xinwei He, and Jure Leskovec
Joshua Robinson, Rishabh Ranjan, Weihua Hu, Kexin Huang, Jiaqi Han, Alejandro Dobles, Matthias Fey, Jan E. Lenssen, Yiwen Yuan, Zecheng Zhang, Xinwei He, and Jure Leskovec. Relbench: A benchmark for deep learning on relational databases, 2024. URLhttps://arxiv.org/abs/2407. 20060
work page 2024
-
[66]
Sören R. Künzel, Jasjeet S. Sekhon, Peter J. Bickel, and Bin Yu. Metalearners for estimating heterogeneous treatment effects using machine learning.Proceedings of the National Academy of Sciences, 116(10):4156–4165, 2019
work page 2019
-
[67]
Irina Elisova Maksim Shevchenko. User guide for uplift modeling and casual inference.https: //www.uplift-modeling.com/en/latest/user_guide/index.html, 2020
work page 2020
-
[68]
Realcause: Realistic causal inference benchmarking.CoRR, abs/2011.15007, 2020
Brady Neal, Chin-Wei Huang, and Sunand Raghupathi. Realcause: Realistic causal inference benchmarking.CoRR, abs/2011.15007, 2020. URLhttps://arxiv.org/abs/2011.15007
-
[69]
Afonso Lourenço, João Gama, Eric P. Xing, and Goreti Marreiros. In-context learning of evolving data streams with tabular foundational models.arXiv preprint arXiv:2502.16840, 2025. doi: 10.48550/arXiv.2502.16840. URLhttps://arxiv.org/abs/2502.16840
-
[70]
Time: Tabpfn-integrated multimodal engine for robust tabular-image learning, 2025
Jiaqi Luo, Yuan Yuan, and Shixin Xu. Time: Tabpfn-integrated multimodal engine for robust tabular-image learning, 2025. URLhttps://arxiv.org/abs/2506.00813
-
[71]
Predictive Maintenance for Rail Networks: Hitachi Rail Case Study
Prior Labs. Predictive Maintenance for Rail Networks: Hitachi Rail Case Study. https:// priorlabs.ai/case-studies/hitachi, 2026. Accessed May 2026
work page 2026
-
[72]
Credit Decisioning at Creditplus Bank: Case Study
Prior Labs. Credit Decisioning at Creditplus Bank: Case Study. https://priorlabs.ai/ case-studies/credit-plus, 2026. Accessed May 2026
work page 2026
-
[73]
Clinical Decision Support with Oxford Cancer Analytics: Case Study
Prior Labs. Clinical Decision Support with Oxford Cancer Analytics: Case Study. https:// priorlabs.ai/case-studies/oxcan, 2026. Accessed May 2026
work page 2026
-
[74]
Paul W Holland. Statistics and causal inference.Journal of the American Statistical Association, 81(396):945–960, 1986
work page 1986
-
[75]
Arpad E Elo. The proposed uscf rating system, its development, theory, and applications.Chess life, 22(8):242–247, 1967
work page 1967
-
[76]
Chatbot arena: An open platform for evaluating llms by human preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[77]
Maksim A. Terpilowski. scikit-posthocs: Pairwise multiple comparison tests in python.Journal of Open Source Software, 4(36):1169, 2019. doi: 10.21105/joss.01169. URLhttps://doi.org/10. 21105/joss.01169
-
[78]
Dan-Ni Wu, Joey Jen, Erickson Fajiculay, Min-Fen Hsu, Ming-Chu Chang, Jen-Chen Yeh, Karen Sargsyan, Juozas Kupcinskas, Jurgita Skieceviciene, Ruta Steponaitiene, Egidijus Morkunas, Greta Gedgaudiene, Chao-Ping Hsu, Yu-Ting Chang, and Chun-Mei Hu. Panmetai - a high performance tabular foundation model for accurate pancreatic cancer diagnosis via nmr metabo...
-
[79]
Asif Adil and Stephanie Hurwitz. Deep learning models enable healthy donor management through prediction of mobilization success.Transplantation and Cellular Therapy, 32:S3, 2026. doi: 10.1016/j.jtct.2026.02.016. URLhttps://doi.org/10.1016/j.jtct.2026.02.016
-
[80]
Hongxin Zheng, Wenxin Gan, Yizi Liu, Shuyu Duan, Kun Li, Gongping Li, Yanqiu Xue, and Yu Xie. Differentiation between psychotic and non-psychotic major depression by the tabular prior-data fitted network.Journal of Affective Disorders, 403:121454, 2026. doi: 10.1016/j.jad.2026.121454. URLhttps://doi.org/10.1016/j.jad.2026.121454
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.