Recognition: no theorem link
Learn2Fold: Structured Origami Generation with World Model Planning
Pith reviewed 2026-05-16 08:35 UTC · model grok-4.3
The pith
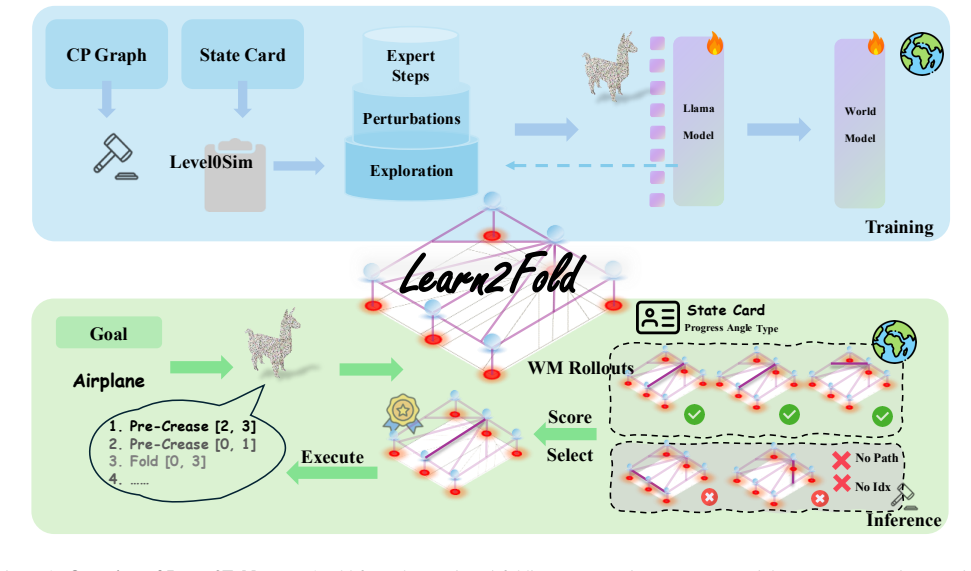
Learn2Fold generates physically valid origami folding sequences from text by using an LLM to propose programs and a learned graph world model to verify them in planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Learn2Fold formulates origami folding as conditional program induction over a crease-pattern graph. A large language model generates candidate folding programs from abstract text prompts, while a learned graph-structured world model serves as a differentiable surrogate simulator that predicts physical feasibility and failure modes before execution. Integrated within a lookahead planning loop, this produces robust sequences for complex and out-of-distribution patterns.
What carries the argument
The lookahead planning loop that treats the learned graph-structured world model as a differentiable surrogate simulator to score and filter folding programs proposed by the language model.
If this is right
- Folding sequences can be produced from sparse natural language without dense geometric specifications.
- Long-horizon sequences satisfy both high-level intent and hard physical constraints simultaneously.
- Performance holds for complex patterns and for patterns outside the training distribution.
- Spatial intelligence improves when symbolic proposal and grounded simulation operate together in a single loop.
Where Pith is reading between the lines
- The same proposal-and-verification split could transfer to other domains that combine language goals with strict physics, such as robotic assembly planning.
- Because the world model is differentiable, its predictions could support gradient-based refinement of folding paths in addition to discrete planning.
- Collecting simulation data from varied material properties might allow the world model to anticipate real-paper behaviors like slight stretching or tearing.
Load-bearing premise
The learned graph world model correctly forecasts whether any given folding program will collide or violate kinematic rules before the sequence is executed.
What would settle it
Running a planner-selected sequence in an independent rigid-body simulator and observing a collision or crease violation that the world model did not flag.
Figures







read the original abstract
The ability to transform a flat sheet into a complex three-dimensional structure is a fundamental test of physical intelligence. Unlike cloth manipulation, origami is governed by strict geometric axioms and hard kinematic constraints, where a single invalid crease or collision can invalidate the entire folding sequence. As a result, origami demands long-horizon constructive reasoning that jointly satisfies precise physical laws and high-level semantic intent. Existing approaches fall into two disjoint paradigms: optimization-based methods enforce physical validity but require dense, precisely specified inputs, making them unsuitable for sparse natural language descriptions, while generative foundation models excel at semantic and perceptual synthesis yet fail to produce long-horizon, physics-consistent folding processes. Consequently, generating valid origami folding sequences directly from text remains an open challenge. To address this gap, we introduce Learn2Fold, a neuro-symbolic framework that formulates origami folding as conditional program induction over a crease-pattern graph. Our key insight is to decouple semantic proposal from physical verification. A large language model generates candidate folding programs from abstract text prompts, while a learned graph-structured world model serves as a differentiable surrogate simulator that predicts physical feasibility and failure modes before execution. Integrated within a lookahead planning loop, Learn2Fold enables robust generation of physically valid folding sequences for complex and out-of-distribution patterns, demonstrating that effective spatial intelligence arises from the synergy between symbolic reasoning and grounded physical simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Learn2Fold, a neuro-symbolic framework for generating origami folding sequences from text prompts. It decouples semantic proposal (LLM-generated candidate folding programs over a crease-pattern graph) from physical verification (a learned graph-structured world model acting as a differentiable surrogate simulator) inside a lookahead planning loop, claiming this enables robust, physically valid sequences for complex and out-of-distribution patterns.
Significance. If the central claims are substantiated, the work would be significant for neuro-symbolic AI and physical reasoning, showing how LLM-based symbolic planning can be grounded via learned simulators to satisfy hard kinematic and collision constraints in long-horizon tasks. This could influence robotics, automated fabrication, and spatial intelligence more broadly by providing a template for combining generative models with differentiable world models.
major comments (3)
- [Abstract] Abstract: The central claim that Learn2Fold 'enables robust generation of physically valid folding sequences for complex and out-of-distribution patterns' is unsupported by any quantitative results, success rates, prediction-error metrics, ablation studies, or comparisons to baselines; the manuscript supplies only a high-level description of the architecture.
- [Abstract] The description of the graph-structured world model as an accurate differentiable surrogate simulator lacks any architecture details, training regime, loss formulation, or validation against ground-truth physics simulators (e.g., prediction error on collisions or kinematic violations), especially for the claimed OOD crease patterns.
- [Abstract] No experimental section or results are present to demonstrate that the lookahead planning loop successfully filters invalid LLM-proposed programs or that the synergy between symbolic reasoning and the world model improves physical validity over either component alone.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential significance of Learn2Fold for neuro-symbolic physical reasoning. We acknowledge that the submitted manuscript provides only a high-level architectural description and lacks the quantitative experiments, implementation details, and validation results needed to substantiate the central claims. We will revise the manuscript to address these gaps by adding a full experimental section, detailed world-model specifications, and supporting metrics.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Learn2Fold 'enables robust generation of physically valid folding sequences for complex and out-of-distribution patterns' is unsupported by any quantitative results, success rates, prediction-error metrics, ablation studies, or comparisons to baselines; the manuscript supplies only a high-level description of the architecture.
Authors: We agree that the current manuscript does not include quantitative support for the claims made in the abstract. In the revised version we will add a dedicated Experiments section reporting success rates on in-distribution and out-of-distribution crease patterns, comparisons against direct LLM program generation and optimization baselines, ablation studies isolating the contribution of the world model and the lookahead loop, and metrics such as physical validity rate, collision-free sequence percentage, and average planning horizon achieved. revision: yes
-
Referee: [Abstract] The description of the graph-structured world model as an accurate differentiable surrogate simulator lacks any architecture details, training regime, loss formulation, or validation against ground-truth physics simulators (e.g., prediction error on collisions or kinematic violations), especially for the claimed OOD crease patterns.
Authors: We accept this criticism. The submitted text only sketches the world model at a conceptual level. The revision will expand the Methods section with the precise GNN architecture (layer types, message-passing scheme, node/edge feature dimensions), the training dataset construction from a ground-truth rigid-body simulator, the composite loss (state-prediction MSE plus collision and constraint-violation terms), and quantitative validation curves showing prediction error on both held-out and OOD crease patterns. revision: yes
-
Referee: [Abstract] No experimental section or results are present to demonstrate that the lookahead planning loop successfully filters invalid LLM-proposed programs or that the synergy between symbolic reasoning and the world model improves physical validity over either component alone.
Authors: We concur that the manuscript contains no empirical demonstration of the planning loop's filtering effect or of the neuro-symbolic synergy. In the revised paper we will include controlled experiments that measure (i) the fraction of LLM-proposed programs rejected by the world-model verifier, (ii) end-to-end success rates with and without the verifier, and (iii) success rates with and without the lookahead search, thereby quantifying the incremental benefit of each component. revision: yes
Circularity Check
No circularity: framework uses external LLM and separately trained simulator
full rationale
The paper describes a neuro-symbolic architecture that decouples LLM-based program proposal from a learned graph world model acting as surrogate simulator. No equations, self-definitions, or fitted parameters are presented that reduce any claimed prediction or feasibility output to the inputs by construction. The central result (robust OOD folding sequences) is framed as an empirical outcome of the combined system rather than a mathematical identity or self-citation chain. This matches the default expectation of a non-circular paper whose claims rest on external components and training rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Origami is governed by strict geometric axioms and hard kinematic constraints where a single invalid crease or collision invalidates the sequence.
invented entities (1)
-
graph-structured world model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Christensen, Hao Su, Jiajun Wu, and Yunzhu Li
Bo Ai, Stephen Tian, Haochen Shi, Yixuan Wang, Tobias Pfaff, Cheston Tan, Henrik I. Christensen, Hao Su, Jiajun Wu, and Yunzhu Li. A review of learning-based dynamics models for robotic manipulation.Science Robotics, 10(106): eadt1497, 2025. 4
work page 2025
-
[2]
Guided open vocabulary image captioning with constrained beam search
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. Guided open vocabulary image captioning with constrained beam search. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Pro- cessing, pages 936–945, Copenhagen, Denmark, 2017. As- sociation for Computational Linguistics. 3
work page 2017
-
[3]
The complexity of flat origami
Marshall Bern and Barry Hayes. The complexity of flat origami. InProceedings of the Seventh Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 175–183. Society for Industrial and Applied Mathematics, 1996. 3
work page 1996
-
[4]
Genie: Gen- erative interactive environments, 2024
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker- Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder S...
work page 2024
-
[5]
Ge- nie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Ge- nie: Generative interactive environments. InForty-first Inter- national Conference on Machine Learning, 2024. 5
work page 2024
-
[6]
Zhaoxi Chen, Guangcong Wang, and Ziwei Liu. Scene- dreamer: Unbounded 3d scene generation from 2d image collections.IEEE transactions on pattern analysis and ma- chine intelligence, 45(12):15562–15576, 2023. 2
work page 2023
-
[7]
Cambridge Uni- versity Press, 2007
Erik D Demaine and Joseph O’Rourke.Geometric Folding Algorithms: Linkages, Origami, Polyhedra. Cambridge Uni- versity Press, 2007. 3
work page 2007
-
[8]
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. Get3d: A generative model of high quality 3d tex- tured shapes learned from images.Advances in neural infor- mation processing systems, 35:31841–31854, 2022. 2
work page 2022
-
[9]
Fast, interactive origami simulation using gpu compute shaders
Amanda Ghassaei, Erik D Demaine, and Neil Gershen- feld. Fast, interactive origami simulation using gpu compute shaders. InProceedings of the 7th International Meeting on Origami in Science, Mathematics and Education (OSME7), pages 1151–1166, 2018. 3
work page 2018
-
[10]
Learning latent dynamics for planning from pixels, 2019
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Ville- gas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels, 2019. 4
work page 2019
-
[11]
Dream to control: Learning behaviors by la- tent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Moham- mad Norouzi. Dream to control: Learning behaviors by la- tent imagination. InInternational Conference on Learning Representations (ICLR), 2020. 4
work page 2020
-
[12]
Can He, Lingxiao Meng, Zhirui Sun, Jiankun Wang, and Max Q. H. Meng. Fabricfolding: Learning efficient fabric folding without expert demonstrations, 2023. 2
work page 2023
-
[13]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022. 12
work page 2022
-
[14]
Vistav2: World imagination for indoor vision-and-language navigation, 2025
Yanjia Huang, Xianshun Jiang, Xiangbo Gao, Mingyang Wu, and Zhengzhong Tu. Vistav2: World imagination for indoor vision-and-language navigation, 2025. 2, 4
work page 2025
-
[15]
Thomas C. Hull. The combinatorics of flat folds: A sur- vey. InOrigami 3: Third International Meeting of Origami Science, Mathematics, and Education, pages 29–38. A K Pe- ters, 2002. 3
work page 2002
-
[16]
Image genera- tion from scene graphs, 2018
Justin Johnson, Agrim Gupta, and Li Fei-Fei. Image genera- tion from scene graphs, 2018. 3
work page 2018
-
[17]
Yushi Lan, Fangzhou Hong, Shangchen Zhou, Shuai Yang, Xuyi Meng, Yongwei Chen, Zhaoyang Lyu, Bo Dai, Xin- gang Pan, and Chen Change Loy. Ln3diff++: Scalable latent neural fields diffusion for speedy 3d generation.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, page 1–18, 2025. 2
work page 2025
-
[18]
Robert J Lang.Origami Design Secrets: Mathematical Methods for an Ancient Art. CRC Press, 2 edition, 2011. 2, 4
work page 2011
-
[19]
Learning fabric manipulation in the real world with human videos
Robert Lee, Jad Abou-Chakra, Fangyi Zhang, and Peter Corke. Learning fabric manipulation in the real world with human videos. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 3124–3130. IEEE,
-
[20]
Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets, 2025
Weiyu Li, Xuanyang Zhang, Zheng Sun, Di Qi, Hao Li, Wei Cheng, Weiwei Cai, Shihao Wu, Jiarui Liu, Zihao Wang, Xiao Chen, Feipeng Tian, Jianxiong Pan, Zeming Li, Gang Yu, Xiangyu Zhang, Daxin Jiang, and Ping Tan. Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets, 2025. 2
work page 2025
-
[21]
Folding deformable objects using predictive simulation and trajectory optimization
Yinxiao Li, Yonghao Yue, Danfei Xu, Eitan Grinspun, and Peter K Allen. Folding deformable objects using predictive simulation and trajectory optimization. In2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6000–6006. IEEE, 2015. 2
work page 2015
-
[22]
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.arXiv preprint arXiv:2502.06608, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[23]
Yiming Liu, Lijun Han, Enlin Gu, and Hesheng Wang. Learning a general model: Folding clothing with topologi- cal dynamics.arXiv preprint arXiv:2504.20720, 2025. 2
-
[24]
Yunlong Liu, Shuyang Li, Pengyuan Liu, Yu Zhang, and Rudi Stouffs. From pixels to predicates structur- ing urban perception with scene graphs.arXiv preprint arXiv:2512.19221, 2025. 3
-
[25]
Yuanxun Lu, Jingyang Zhang, Shiwei Li, Tian Fang, David McKinnon, Yanghai Tsin, Long Quan, Xun Cao, and Yao Yao. Direct2. 5: Diverse text-to-3d generation via multi-view 2.5 d diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8744– 8753, 2024. 2
work page 2024
-
[26]
Jeremy Maitin-Shepard, Marco Cusumano-Towner, Jinna Lei, and Pieter Abbeel. Cloth grasp point detection based on multiple-view geometric cues with application to robotic towel folding. In2010 IEEE International Conference on Robotics and Automation, pages 2308–2315, 2010. 2
work page 2010
-
[27]
Gimin Nam, Mariem Khlifi, Andrew Rodriguez, Alberto Tono, Linqi Zhou, and Paul Guerrero. 3d-ldm: Neural im- plicit 3d shape generation with latent diffusion models.arXiv preprint arXiv:2212.00842, 2022. 2
-
[28]
Generating physically sta- ble and buildable brick structures from text
Ava Pun, Kangle Deng, Ruixuan Liu, Deva Ramanan, Changliu Liu, and Jun-Yan Zhu. Generating physically sta- ble and buildable brick structures from text. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 14798–14809, 2025. 3, 7, 12
work page 2025
-
[29]
Offline reinforcement learning from images with latent space models, 2020
Rafael Rafailov, Tianhe Yu, Aravind Rajeswaran, and Chelsea Finn. Offline reinforcement learning from images with latent space models, 2020. 4
work page 2020
-
[30]
Hierarchical text-conditional image gener- ation with clip latents, 2022
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents, 2022. 2
work page 2022
-
[31]
Avid: Adapting video diffusion models to world models,
Marc Rigter, Tarun Gupta, Agrin Hilmkil, and Chao Ma. Avid: Adapting video diffusion models to world models,
-
[32]
High-resolution image syn- thesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models, 2022. 2
work page 2022
-
[33]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Tomohiro Tachi. Simulation of rigid origami. InOrigami 4: Fourth International Meeting of Origami Science, Math- ematics, and Education, pages 175–187. AK Peters/CRC Press, 2009. 3, 4
work page 2009
-
[35]
Freeform variations of origami.Journal for Geometry and Graphics, 14(2):203–215, 2010
Tomohiro Tachi. Freeform variations of origami.Journal for Geometry and Graphics, 14(2):203–215, 2010. 2, 3
work page 2010
-
[36]
Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control, 2023
ByteDance Seed Team. Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control, 2023. 2
work page 2023
-
[37]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Gemini robotics: Bringing ai into the physical world, 2025
Gemini Robotics Team. Gemini robotics: Bringing ai into the physical world, 2025. 2
work page 2025
- [39]
- [40]
-
[41]
Tongxuan Tian, Haoyang Li, Bo Ai, Xiaodi Yuan, Zhiao Huang, and Hao Su. Diffusion dynamics models with gener- ative state estimation for cloth manipulation.arXiv preprint arXiv:2503.11999, 2025. 2
-
[42]
Vikram V oleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. Sv3d: Novel multi-view syn- thesis and 3d generation from a single image using latent video diffusion. InEuropean Conference on Computer Vi- sion, pages 439–457. Springer, 2024. 2
work page 2024
-
[43]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.Advances in neural information processing systems, 36: 8406–8441, 2023. 2
work page 2023
-
[44]
Scene graph generation by iterative message passing
Danfei Xu, Yuke Zhu, Christopher B Choy, and Li Fei-Fei. Scene graph generation by iterative message passing. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition, pages 5410–5419, 2017. 3
work page 2017
-
[45]
Control image captioning spatially and tempo- rally
Kun Yan, Lei Ji, Huaishao Luo, Ming Zhou, Nan Duan, and Shuai Ma. Control image captioning spatially and tempo- rally. InProceedings of the 59th Annual Meeting of the As- sociation for Computational Linguistics and the 11th Inter- national Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 2014–2025, Online, 2021. Association f...
work page 2014
-
[46]
Vision-language models for vision tasks: A survey, 2024
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey, 2024. 2 Appendix A. More Model and Implementation Details Learn2Foldis implemented as a neuro-symbolic planning system over a canonicalized crease-pattern graph represen- tation. Given a high-level semantic goal and the current origami state, the sys...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.