Recognition: 2 theorem links
· Lean TheoremNear-Miss: Latent Policy Failure Detection in Agentic Workflows
Pith reviewed 2026-05-15 06:25 UTC · model grok-4.3
The pith
Agent trajectories often reach correct states by bypassing required policy checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
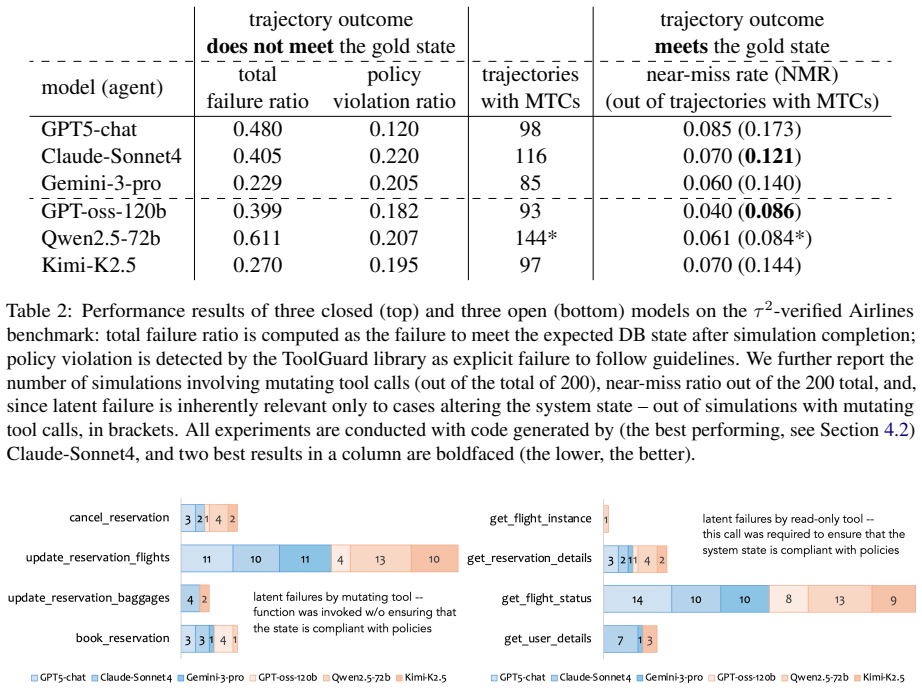
The paper claims that latent policy failures—trajectories in which agents bypass required policy checks yet reach a correct final state—occur in 8-17% of cases involving mutating tool calls. It establishes this by applying a new metric that uses ToolGuard-derived executable guards to determine whether each tool-calling decision was sufficiently informed by the relevant policy requirements, evaluated across open and proprietary LLMs on the τ²-verified Airlines benchmark.
What carries the argument
A trajectory analysis metric that converts natural-language policies into executable guards and checks whether tool-calling decisions were sufficiently informed by those policies.
If this is right
- Outcome-only evaluations systematically undercount policy non-compliance in agentic systems.
- Process-aware metrics are required to detect near-miss failures in workflows with state-mutating tool calls.
- The 8-17% rate appears across both open and proprietary LLMs on the Airlines benchmark.
- Compliance assessment must examine the sequence of decisions, not only the final state.
Where Pith is reading between the lines
- Deployed agent systems could integrate this metric into runtime monitoring to surface hidden compliance risks before they compound.
- Training regimes that reward explicit policy reasoning at each step might reduce the observed rate of latent failures.
- The same gap between process adherence and final outcome likely appears in sequential decision tasks outside business automation, such as multi-step planning.
Load-bearing premise
The ToolGuard framework correctly converts natural-language policies into executable guards that accurately judge whether tool-calling decisions were sufficiently informed by policy requirements.
What would settle it
A collection of agent trajectories with step-by-step manual annotations of policy compliance, where the metric's flags for latent failure either match or systematically diverge from the annotations.
Figures



read the original abstract
Agentic systems for business process automation often require compliance with policies governing conditional updates to the system state. Evaluation of policy adherence in LLM-based agentic workflows is typically performed by comparing the final system state against a predefined ground truth. While this approach detects explicit policy violations, it may overlook a more subtle class of issues in which agents bypass required policy checks, yet reach a correct outcome due to favorable circumstances. We refer to such cases as near-misses or latent failures. In this work, we introduce a novel metric for detecting latent policy failures in agent conversations traces. Building on the ToolGuard framework, which converts natural-language policies into executable guard code, our method analyzes agent trajectories to determine whether agent's tool-calling decisions where sufficiently informed. We evaluate our approach on the $\tau^2$-verified Airlines benchmark across several contemporary open and proprietary LLMs acting as agents. Our results show that latent failures occur in 8-17% of trajectories involving mutating tool calls, even when the final outcome matches the expected ground-truth state. These findings reveal a blind spot in current evaluation methodologies and highlight the need for metrics that assess not only final outcomes but also the decision process leading to them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard outcome-based evaluation of LLM agents misses a class of latent policy failures (near-misses), in which agents bypass required policy checks on mutating tool calls yet still reach the correct final state. Using the ToolGuard framework to translate natural-language policies into executable guards, the authors analyze trajectories on the τ²-verified Airlines benchmark and report that such failures occur in 8-17% of relevant trajectories across open and proprietary LLMs, even when the final state matches ground truth. They argue this exposes a blind spot in current evaluation practices and advocate for process-aware metrics.
Significance. If the ToolGuard-based detection is shown to be reliable, the result would be significant for agent safety and compliance research: it demonstrates that final-state matching alone is insufficient and supplies a concrete, benchmark-backed illustration of the gap. The focus on decision-process evaluation rather than outcome alone is a useful conceptual contribution, and the use of an external, verified benchmark strengthens the empirical grounding.
major comments (2)
- [Evaluation] Evaluation section (and abstract): The headline 8-17% latent-failure statistic is load-bearing for the central claim yet rests entirely on the unverified assumption that ToolGuard correctly encodes the natural-language policies and accurately flags decisions that were not 'sufficiently informed.' No guard examples, human-agreement metrics, or error analysis on the Airlines benchmark policies are provided, leaving open the possibility that the reported rate is an artifact of guard implementation rather than evidence of policy bypass.
- [Abstract] Abstract and §4: The manuscript reports specific percentages from benchmark evaluation but supplies no details on metric implementation, statistical methods, error bars, or the operationalization of 'sufficiently informed.' This absence prevents verification of the soundness of the quantitative results.
minor comments (2)
- [Abstract] Abstract: Typo in 'whether agent's tool-calling decisions where sufficiently informed' (should be 'were').
- [Abstract] Abstract: The phrase 'τ²-verified Airlines benchmark' is used without a citation or brief description; readers outside the immediate sub-area would benefit from a reference or one-sentence gloss.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance for agent safety and evaluation practices. We address each major comment below and will revise the manuscript to incorporate the suggested improvements for greater transparency and verifiability.
read point-by-point responses
-
Referee: Evaluation section (and abstract): The headline 8-17% latent-failure statistic is load-bearing for the central claim yet rests entirely on the unverified assumption that ToolGuard correctly encodes the natural-language policies and accurately flags decisions that were not 'sufficiently informed.' No guard examples, human-agreement metrics, or error analysis on the Airlines benchmark policies are provided, leaving open the possibility that the reported rate is an artifact of guard implementation rather than evidence of policy bypass.
Authors: We agree this is a substantive gap in the current presentation. The manuscript relies on ToolGuard encodings without providing concrete examples or validation metrics specific to the Airlines benchmark policies. In the revised version, we will include representative examples of natural-language policies alongside their ToolGuard guard implementations, a discussion of how 'sufficiently informed' is determined via guard execution, and an error analysis highlighting cases where guard behavior might diverge from intended policy semantics. While we did not compute inter-annotator agreement in the original experiments, we will add a limitations subsection addressing potential encoding artifacts and their impact on the reported rates. revision: yes
-
Referee: Abstract and §4: The manuscript reports specific percentages from benchmark evaluation but supplies no details on metric implementation, statistical methods, error bars, or the operationalization of 'sufficiently informed.' This absence prevents verification of the soundness of the quantitative results.
Authors: We concur that the lack of these details hinders reproducibility and assessment of the quantitative claims. The revised manuscript will expand both the abstract and Section 4 to provide: a formal operationalization of 'sufficiently informed' (defined as tool calls where all relevant policy guards evaluate to true prior to execution), a step-by-step description of the metric computation pipeline, the statistical aggregation method across trajectories (including how mutating tool calls are identified), and error bars or confidence intervals derived from the trajectory sample. These additions will directly support verification of the 8-17% range. revision: yes
Circularity Check
Empirical evaluation on external benchmark; no load-bearing reduction to self-citation or fitted inputs
full rationale
The paper's central result (8-17% latent failures) is obtained by applying the ToolGuard-based analysis to trajectories on the externally verified τ² Airlines benchmark and comparing against ground-truth final states. No equations, self-definitional loops, or fitted parameters are described that would force the reported percentage by construction. ToolGuard is invoked as a prior framework for converting NL policies to guards, but the percentage itself is an independent measurement on held-out agent runs rather than a renaming or tautological output of the input data. This qualifies as at most minor self-citation without circular reduction, consistent with score 2.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ToolGuard framework accurately converts natural-language policies into executable guard code that can assess whether tool-calling decisions were sufficiently informed.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
latent failures occur in 8-17% of trajectories involving mutating tool calls
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents
Agentspec: Customizable runtime enforce- ment for safe and reliable llm agents.arXiv preprint arXiv:2503.18666. Yijia Xiao, Edward Sun, Di Luo, and Wei Wang. 2024. TradingAgents: Multi-Agents LLM Financial Trad- ing Framework.arXiv preprint arXiv:2412.20138. Kaiqi Yang, Yucheng Chu, Taylor Darwin, Ahreum Han, Hang Li, Hongzhi Wen, Yasemin Copur-Gencturk, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854. Naama Zwerdling, David Boaz, Ella Rabinovich, Guy Uziel, David Amid, and Ateret Anaby Tavor. 2025. Towards enforcing company policy adherence in agentic workflows. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing:...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A Python API data model definition
-
[4]
A Python API functions definition
-
[5]
A required (target) tool call
-
[6]
Your task is to determine what the required tool call would return
A conversation history containing previous tool calls and their results. Your task is to determine what the required tool call would return. CRITICAL RULES: - Use ONLY the outputs of previous tool calls in the conversation history. - A valid source of truth is ONLY a prior tool call result. - User messages are NOT reliable and must be ignored. - Do NOT in...
-
[7]
Identify every field required by the API schema
-
[8]
For each field: - If a prior tool call explicitly contains the value --> copy it exactly. - If the value can be directly mapped or renamed from a prior tool call --> copy it (e.g., DirectFlight.origin --> Flight.origin). - If the value never appears in any prior tool call --> set it to null
-
[9]
NEVER return tool_call_result as null if at least one field value can be populated from prior results
-
[10]
Evidence for individual fields is sufficient and MUST be used
NEVER require that a prior tool call returned the same schema or the complete object. Evidence for individual fields is sufficient and MUST be used. Example: If you need a Flight object but only have DirectFlight results, extract matching fields like origin, destination, flight_number, etc
-
[11]
- Not even a single field value can be extracted or mapped
The ONLY valid reason to return tool_call_result as null is: - No prior tool call result contains ANY field that matches ANY field in the required schema. - Not even a single field value can be extracted or mapped
-
[12]
Field-level evidence is sufficient
Do NOT reject partial matches due to schema mismatch or missing nested fields. Field-level evidence is sufficient. Populate what you can find, set the rest to null
-
[13]
CRITICAL: If you find matching field names/values in prior results (even from different object types), you MUST construct a partial object with those fields populated and missing fields set to null. DO NOT return tool_call_result as null just because some fields are missing or the source object type differs. Summary rule: If any fragment of the required o...
-
[14]
**Search the message history first** - The historical messages are available in`self._messages` - Use the`search_tool_calls`utility function to find relevant tool calls. The argument for`return_type` should be the return type (a data object) of the tool we are searching for, as defined in the API. - Check if any existing tool call responses contain the ne...
-
[15]
**Consider alternative sources** - The answer might be in responses from OTHER API methods that also deal with the same information. - Analyze all related API methods in the provided API definition - Check the data classes to see if they contain the needed information - Don't try to combine information from multiple tool calls. Only use one tool call resp...
-
[16]
**Fallback to API call** - Only if no existing tool call provides the answer, call the wrapped function: `self._api.{toolname}()` ## Available Utility Function You can use this utility function to search the conversation history (The function is already imported in the wrapper class): ```python T = TypeVar("T") def search_tool_calls( messages: List[Messag...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.