Recognition: 1 theorem link
· Lean TheoremBeyond Ground-Truth: Leveraging Image Quality Priors for Real-World Image Restoration
Pith reviewed 2026-05-14 00:02 UTC · model grok-4.3
The pith
Image quality priors from no-reference models can steer restoration past ground-truth averages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
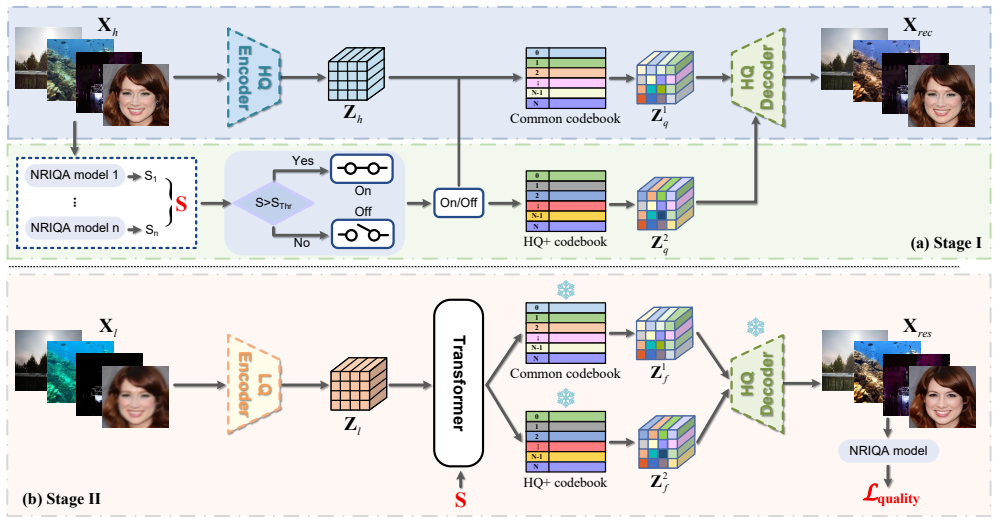
The IQPIR framework extracts an Image Quality Prior from pre-trained NR-IQA models and feeds it as a conditioning signal into a quality-conditioned Transformer, while a dual-branch codebook disentangles common structural features from high-quality attributes and a discrete representation optimization step prevents over-optimization artifacts, allowing the restored image to exceed the average perceptual quality of the ground-truth training set.
What carries the argument
Image Quality Prior (IQP) drawn from NR-IQA scores, used as a conditioning input to a Transformer inside a dual-branch codebook architecture with discrete optimization.
If this is right
- Existing restoration networks gain a plug-and-play quality boost by adding the conditioning branch without any structural redesign.
- Restored images can surpass the average perceptual fidelity present in the original training ground-truth.
- The dual-branch codebook keeps structural information intact while separately optimizing quality-sensitive attributes.
- Discrete optimization in the codebook avoids the artifact patterns typical of continuous latent-space training.
Where Pith is reading between the lines
- The same quality-prior conditioning could be tested on video restoration where frame-to-frame ground-truth is especially noisy.
- Combining the prior with semantic or scene-type signals might help in cases where quality and content are tightly coupled.
- Running the method on multiple independent NR-IQA models as an ensemble could reveal how sensitive the gains are to the choice of prior source.
Load-bearing premise
Pre-trained no-reference image quality assessment models supply reliable signals that reliably steer restoration toward maximal perceptual quality without adding new artifacts.
What would settle it
On a held-out set of real degraded images, if the IQP-guided outputs receive lower perceptual quality scores than a plain ground-truth-supervised baseline under the same architecture, the central claim is false.
Figures




read the original abstract
Real-world image restoration aims to restore high-quality (HQ) images from degraded low-quality (LQ) inputs captured under uncontrolled conditions. Existing methods typically depend on ground-truth (GT) supervision, assuming that GT provides perfect reference quality. However, GT can still contain images with inconsistent perceptual fidelity, causing models to converge to the average quality level of the training data rather than achieving the highest perceptual quality attainable. To address these problems, we propose a novel framework, termed IQPIR, that introduces an Image Quality Prior (IQP)-extracted from pre-trained No-Reference Image Quality Assessment (NR-IQA) models-to guide the restoration process toward perceptually optimal outputs explicitly. Our approach synergistically integrates IQP with a learned codebook prior through three key mechanisms: (1) a quality-conditioned Transformer, where NR-IQA-derived scores serve as conditioning signals to steer the predicted representation toward maximal perceptual quality. This design provides a plug-and-play enhancement compatible with existing restoration architectures without structural modification; and (2) a dual-branch codebook structure, which disentangles common and HQ-specific features, ensuring a comprehensive representation of both generic structural information and quality-sensitive attributes; and (3) a discrete representation-based quality optimization strategy, which mitigates over-optimization effects commonly observed in continuous latent spaces. Extensive experiments on real-world image restoration demonstrate that our method not only surpasses cutting-edge methods but also serves as a generalizable quality-guided enhancement strategy for existing methods. The code is available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes IQPIR, a framework for real-world image restoration that extracts an Image Quality Prior (IQP) from pre-trained No-Reference Image Quality Assessment (NR-IQA) models to guide restoration beyond the average perceptual quality of ground-truth (GT) data. It integrates this prior via a quality-conditioned Transformer, a dual-branch codebook that disentangles generic and HQ-specific features, and a discrete representation-based optimization strategy to avoid over-optimization artifacts in continuous spaces. The approach is presented as a plug-and-play enhancement for existing architectures, with claims of outperforming state-of-the-art methods on real-world datasets.
Significance. If the empirical claims hold, the work could meaningfully shift restoration paradigms away from pure GT supervision toward explicit quality-prior guidance, offering a generalizable module that improves perceptual outcomes without architectural overhaul. The dual-branch codebook and discrete optimization ideas address known issues in latent-space restoration and could influence downstream tasks like enhancement and generation.
major comments (3)
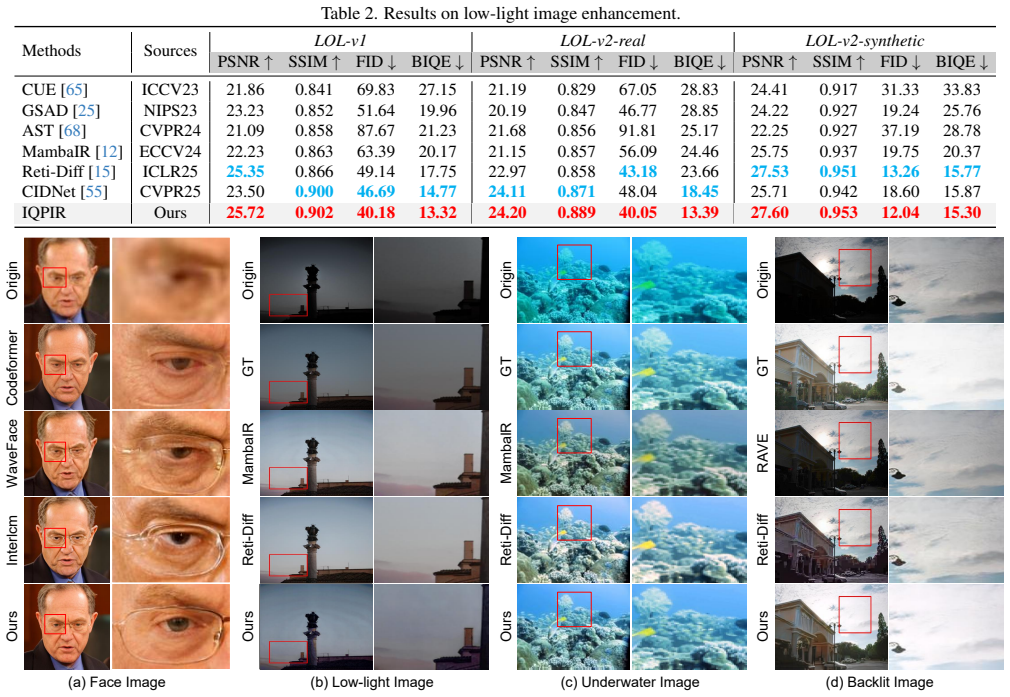
- [Abstract, §4] Abstract and §4 (Experiments): The central claim that the method 'surpasses cutting-edge methods' is unsupported by any reported quantitative metrics, PSNR/SSIM/LPIPS values, ablation tables, error bars, or dataset statistics in the abstract; without these, the superiority assertion cannot be evaluated and the plug-and-play enhancement claim remains unverified.
- [§3.2] §3.2 (Quality-conditioned Transformer): The premise that NR-IQA scores from pre-trained models reliably steer outputs to maximal perceptual quality on real camera degradations is load-bearing but untested; no correlation analysis with human preference or alternative metrics (e.g., BRISQUE vs. MUSIQ) is shown to confirm the conditioning signal is faithful rather than mismatched to the target distribution.
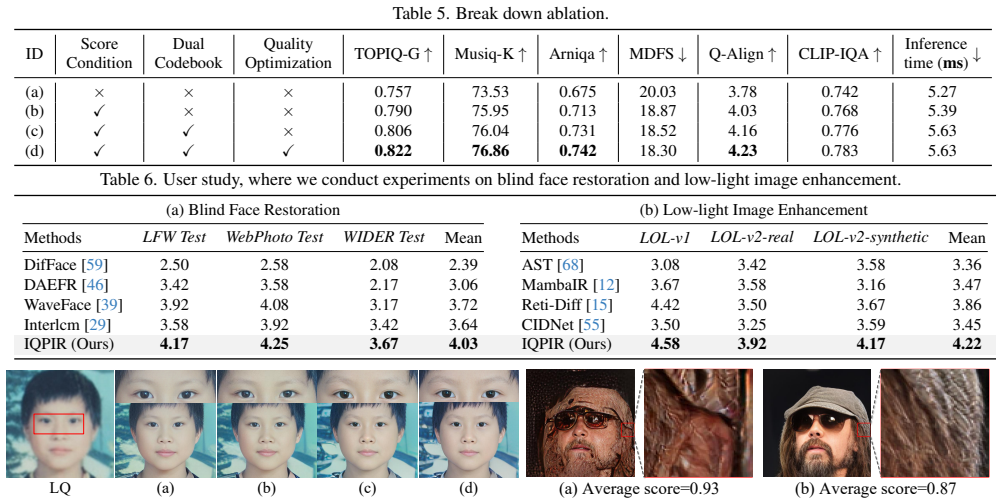
- [§3.3] §3.3 (Dual-branch codebook and discrete optimization): The claim that the discrete strategy 'mitigates over-optimization effects' lacks a concrete comparison (e.g., continuous vs. discrete latent ablation) or artifact analysis; without this, it is unclear whether the disentanglement actually preserves structural fidelity or merely trades one set of artifacts for quantization noise.
minor comments (2)
- [Abstract] Abstract: The acronym 'IQP' is introduced without an explicit expansion on first use, and the three key mechanisms are listed but not cross-referenced to specific subsections or equations.
- [§2] §2 (Related Work): The discussion of prior NR-IQA-guided restoration methods omits recent works on perceptual quality metrics in diffusion-based restoration, weakening the novelty positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which has helped us identify areas to strengthen the presentation and empirical support in our manuscript. We address each major comment point-by-point below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The central claim that the method 'surpasses cutting-edge methods' is unsupported by any reported quantitative metrics, PSNR/SSIM/LPIPS values, ablation tables, error bars, or dataset statistics in the abstract; without these, the superiority assertion cannot be evaluated and the plug-and-play enhancement claim remains unverified.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised version, we will add key metrics (e.g., average PSNR/SSIM/LPIPS gains on RealSR and DRealSR) directly into the abstract while retaining the high-level summary. Section 4 already contains the full tables, ablations, error bars, and dataset details; we will add explicit cross-references from the abstract to these results to verify both the superiority and plug-and-play claims. revision: yes
-
Referee: [§3.2] §3.2 (Quality-conditioned Transformer): The premise that NR-IQA scores from pre-trained models reliably steer outputs to maximal perceptual quality on real camera degradations is load-bearing but untested; no correlation analysis with human preference or alternative metrics (e.g., BRISQUE vs. MUSIQ) is shown to confirm the conditioning signal is faithful rather than mismatched to the target distribution.
Authors: This concern is well-taken. While the main experiments show perceptual gains from the MUSIQ-based conditioning, we did not previously report direct validation of the signal. In the revision we will add a correlation analysis (Pearson/Spearman) between the MUSIQ scores and human preference ratings on a subset of real-world degraded images, plus a brief comparison to BRISQUE to justify the choice of MUSIQ. These results will be placed in Section 3.2 or a new appendix. revision: yes
-
Referee: [§3.3] §3.3 (Dual-branch codebook and discrete optimization): The claim that the discrete strategy 'mitigates over-optimization effects' lacks a concrete comparison (e.g., continuous vs. discrete latent ablation) or artifact analysis; without this, it is unclear whether the disentanglement actually preserves structural fidelity or merely trades one set of artifacts for quantization noise.
Authors: We acknowledge the need for a direct head-to-head comparison. In the revised manuscript we will include an explicit ablation (continuous vs. discrete latent optimization) with both quantitative metrics and side-by-side visual artifact analysis. This will demonstrate that the dual-branch codebook plus discrete strategy reduces over-optimization artifacts while maintaining structural fidelity, rather than simply introducing quantization noise. revision: yes
Circularity Check
No circularity: external NR-IQA priors and architectural choices are independent
full rationale
The paper's core mechanisms rely on pre-trained external NR-IQA models to supply Image Quality Priors as conditioning signals, a dual-branch codebook for feature disentanglement, and discrete optimization to avoid continuous-space artifacts. None of these reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains; the priors are drawn from independent pre-trained networks rather than derived or fitted within the paper's own data or equations. No equations are presented that would allow a prediction to equal its input by construction, and no uniqueness theorems or ansatzes are imported via self-citation. The framework is described as a plug-and-play addition to existing architectures, with performance claims resting on experimental comparisons rather than internal logical closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained NR-IQA models provide quality scores that can reliably steer restoration networks toward maximal perceptual quality.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleara quality-conditioned Transformer, where NR-IQA-derived scores serve as conditioning signals... dual-branch codebook structure... discrete representation-based quality optimization strategy
Reference graph
Works this paper leans on
-
[1]
Arniqa: Learning distortion mani- fold for image quality assessment
Lorenzo Agnolucci, Leonardo Galteri, Marco Bertini, and Alberto Del Bimbo. Arniqa: Learning distortion mani- fold for image quality assessment. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 189–198, 2024. 6
work page 2024
-
[2]
Progressive semantic- aware style transformation for blind face restoration
Chaofeng Chen, Xiaoming Li, Lingbo Yang, Xianhui Lin, Lei Zhang, and Kwan-Yee K Wong. Progressive semantic- aware style transformation for blind face restoration. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11896–11905, 2021. 3
work page 2021
-
[3]
Chaofeng Chen, Jiadi Mo, Jingwen Hou, Haoning Wu, Liang Liao, Wenxiu Sun, Qiong Yan, and Weisi Lin. Topiq: A top-down approach from semantics to distortions for image quality assessment.IEEE Transactions on Image Processing,
-
[4]
Runmin Cong, Wenyu Yang, Wei Zhang, Chongyi Li, Chun- Le Guo, Qingming Huang, and Sam Kwong. Pugan: Physi- cal model-guided underwater image enhancement using gan with dual-discriminators.IEEE Transactions on Image Pro- cessing, 2023. 6
work page 2023
-
[5]
Lizhen Deng, Chunming He, Guoxia Xu, Hu Zhu, and Hao Wang. Pcgan: A noise robust conditional generative ad- versarial network for one shot learning.IEEE transactions on intelligent transportation systems, 23(12):25249–25258,
-
[6]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021. 3
work page 2021
-
[7]
Chengyu Fang, Chunming He, Fengyang Xiao, Yulun Zhang, Longxiang Tang, Yuelin Zhang, Kai Li, and Xiu Li. Real-world image dehazing with coherence-based label gen- erator and cooperative unfolding network.NeurIPS, pages arXiv–2406, 2024. 3
work page 2024
-
[8]
Rave: Residual vector embedding for clip-guided backlit im- age enhancement
Tatiana Gaintseva, Martin Benning, and Gregory Slabaugh. Rave: Residual vector embedding for clip-guided backlit im- age enhancement. InECCV, pages 412–428. Springer, 2024. 6
work page 2024
-
[9]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. InInternational Conference on Machine Learning, pages 10835–10866. PMLR, 2023. 4
work page 2023
-
[10]
Vqfr: Blind face restoration with vector-quantized dictionary and parallel de- coder
Yuchao Gu, Xintao Wang, Liangbin Xie, Chao Dong, Gen Li, Ying Shan, and Ming-Ming Cheng. Vqfr: Blind face restoration with vector-quantized dictionary and parallel de- coder. InEuropean Conference on Computer Vision, pages 126–143. Springer, 2022. 1, 3
work page 2022
-
[11]
Underwater ranker: Learn which is better and how to be better
Chunle Guo, Ruiqi Wu, Xin Jin, Linghao Han, Weidong Zhang, Zhi Chai, and Chongyi Li. Underwater ranker: Learn which is better and how to be better. InProceedings of the AAAI conference on artificial intelligence, pages 702–709,
-
[12]
Mambair: A simple baseline for im- age restoration with state-space model
Hang Guo, Jinmin Li, Tao Dai, Zhihao Ouyang, Xudong Ren, and Shu-Tao Xia. Mambair: A simple baseline for im- age restoration with state-space model. InECCV, 2024. 6, 7
work page 2024
-
[13]
Hqg- net: Unpaired medical image enhancement with high-quality guidance.TNNLS, 2023
Chunming He, Kai Li, Guoxia Xu, Jiangpeng Yan, Longx- iang Tang, Yulun Zhang, Yaowei Wang, and Xiu Li. Hqg- net: Unpaired medical image enhancement with high-quality guidance.TNNLS, 2023. 3
work page 2023
-
[14]
Degradation- resistant unfolding network for heterogeneous image fusion
Chunming He, Kai Li, and Yulun Zhang. Degradation- resistant unfolding network for heterogeneous image fusion. InICCV, pages 611–621, 2023. 3
work page 2023
-
[15]
Chunming He, Chengyu Fang, Yulun Zhang, Kai Li, Longx- iang Tang, Chenyu You, Fengyang Xiao, Zhenhua Guo, and Xiu Li. Reti-diff: Illumination degradation image restoration with retinex-based latent diffusion model.ICLR, 2025. 3, 6, 7, 8
work page 2025
-
[16]
Seg- ment concealed object with incomplete supervision.IEEE Trans
Chunming He, Kai Li, Yachao Zhang, Ziyun Yang, Longxi- ang Tang, Yulun Zhang, Linghe Kong, and Sina Farsiu. Seg- ment concealed object with incomplete supervision.IEEE Trans. Pattern Anal. Mach. Intell., 2025. 3
work page 2025
-
[17]
Chunming He, Fengyang Xiao, Rihan Zhang, Chengyu Fang, Deng-Ping Fan, and Sina Farsiu. Reversible unfold- ing network for concealed visual perception with generative refinement.arXiv preprint arXiv:2508.15027, 2025. 3
-
[18]
Chunming He, Rihan Zhang, Fengyang Xiao, Chengyu Fang, Longxiang Tang, Yulun Zhang, and Sina Farsiu. Unfoldir: Rethinking deep unfolding network in illu- mination degradation image restoration.arXiv preprint arXiv:2505.06683, 2025. 3
-
[19]
Run: Reversible unfolding network for concealed object segmentation.ICML, 2025
Chunming He, Rihan Zhang, Fengyang Xiao, Chenyu Fang, Longxiang Tang, Yulun Zhang, Linghe Kong, Deng-Ping Fan, Kai Li, and Sina Farsiu. Run: Reversible unfolding network for concealed object segmentation.ICML, 2025. 3
work page 2025
-
[20]
Gcfsr: a generative and controllable face super resolution method without facial and gan priors
Jingwen He, Wu Shi, Kai Chen, Lean Fu, and Chao Dong. Gcfsr: a generative and controllable face super resolution method without facial and gan priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1889–1898, 2022. 3
work page 2022
-
[21]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 6
work page 2017
-
[22]
Peng Hu, Chunming He, Lei Xu, Jingduo Tian, Sina Farsiu, Yulun Zhang, Pei Liu, and Xiu Li. Iqpfr: An image quality prior for blind face restoration and beyond.arXiv preprint arXiv:2503.09294, 2025. 3
-
[23]
Xiaobin Hu, Wenqi Ren, Jiaolong Yang, Xiaochun Cao, David Wipf, Bjoern Menze, Xin Tong, and Hongbin Zha. Face restoration via plug-and-play 3d facial priors.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(12):8910–8926, 2021. 3
work page 2021
-
[24]
Labeled faces in the wild: A database forstudying face recognition in unconstrained environments
Gary B Huang, Marwan Mattar, Tamara Berg, and Eric Learned-Miller. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. InWorkshop on faces in’Real-Life’Images: detection, align- ment, and recognition, 2008. 6
work page 2008
-
[25]
Global structure-aware diffusion pro- cess for low-light image enhancement
HOU Jinhui, Zhiyu Zhu, Junhui Hou, LIU Hui, Huanqiang Zeng, and Hui Yuan. Global structure-aware diffusion pro- cess for low-light image enhancement. InNeurIPS, 2023. 6
work page 2023
-
[26]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 3
work page 2019
-
[27]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5148–5157, 2021. 5, 6
work page 2021
-
[28]
Chongyi Li, Chunle Guo, Wenqi Ren, Runmin Cong, Junhui Hou, Sam Kwong, and Dacheng Tao. An underwater image enhancement benchmark dataset and beyond.IEEE Trans- actions on Image Processing, 29:4376–4389, 2019. 6
work page 2019
-
[29]
Senmao Li, Kai Wang, Joost van de Weijer, Fahad Shahbaz Khan, Chun-Le Guo, Shiqi Yang, Yaxing Wang, Jian Yang, and Ming-Ming Cheng. Interlcm: Low-quality images as intermediate states of latent consistency models for effective blind face restoration.ICLR, 2025. 3, 5, 7
work page 2025
-
[30]
Learning warped guidance for blind face restoration
Xiaoming Li, Ming Liu, Yuting Ye, Wangmeng Zuo, Liang Lin, and Ruigang Yang. Learning warped guidance for blind face restoration. InProceedings of the European conference on computer vision (ECCV), pages 272–289, 2018. 3
work page 2018
-
[31]
Blind face restoration via deep multi-scale component dictionaries
Xiaoming Li, Chaofeng Chen, Shangchen Zhou, Xianhui Lin, Wangmeng Zuo, and Lei Zhang. Blind face restoration via deep multi-scale component dictionaries. InEuropean conference on computer vision, pages 399–415. Springer,
-
[32]
Enhanced blind face restoration with multi-exemplar images and adaptive spatial feature fusion
Xiaoming Li, Wenyu Li, Dongwei Ren, Hongzhi Zhang, Meng Wang, and Wangmeng Zuo. Enhanced blind face restoration with multi-exemplar images and adaptive spatial feature fusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2706– 2715, 2020. 1, 3
work page 2020
-
[33]
Iterative prompt learning for unsupervised backlit image enhancement
Zhexin Liang, Chongyi Li, Shangchen Zhou, Ruicheng Feng, and Chen Change Loy. Iterative prompt learning for unsupervised backlit image enhancement. InICCV, pages 8094–8103, 2023. 6, 7
work page 2023
-
[34]
Diff- bir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diff- bir: Toward blind image restoration with generative diffusion prior. InEuropean Conference on Computer Vision, pages 430–448. Springer, 2024. 3
work page 2024
-
[35]
Risheng Liu, Long Ma, Jiaao Zhang, Xin Fan, and Zhongx- uan Luo. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In CVPR, pages 10561–10570, 2021. 8
work page 2021
-
[36]
Yuen Peng Loh and Chee Seng Chan. Getting to know low- light images with the exclusively dark dataset.Computer Vision and Image Understanding, 178:30–42, 2019. 8
work page 2019
-
[37]
Cheng Ma, Zhenyu Jiang, Yongming Rao, Jiwen Lu, and Jie Zhou. Deep face super-resolution with iterative collabora- tion between attentive recovery and landmark estimation. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 5569–5578, 2020. 1, 3
work page 2020
-
[38]
Toward fast, flexible, and robust low-light image enhancement
Long Ma, Tengyu Ma, Risheng Liu, Xin Fan, and Zhongx- uan Luo. Toward fast, flexible, and robust low-light image enhancement. InCVPR, pages 5637–5646, 2022. 8
work page 2022
-
[39]
Waveface: Authentic face restoration with efficient frequency recovery
Yunqi Miao, Jiankang Deng, and Jungong Han. Waveface: Authentic face restoration with efficient frequency recovery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6583–6592, 2024. 5, 7
work page 2024
-
[40]
Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. No-reference image quality assessment in the spatial domain.IEEE Transactions on image processing, 21(12): 4695–4708, 2012. 5
work page 2012
-
[41]
A two- step framework for constructing blind image quality indices
Anush Krishna Moorthy and Alan Conrad Bovik. A two- step framework for constructing blind image quality indices. IEEE Signal processing letters, 17(5):513–516, 2010. 6
work page 2010
-
[42]
Zhangkai Ni, Yue Liu, Keyan Ding, Wenhan Yang, Hanli Wang, and Shiqi Wang. Opinion-unaware blind image qual- ity assessment using multi-scale deep feature statistics.IEEE Transactions on Multimedia, 2024. 6
work page 2024
-
[43]
Karen Panetta, Chen Gao, and Sos Agaian. Human-visual- system-inspired underwater image quality measures.IEEE Journal of Oceanic Engineering, 41(3):541–551, 2015. 6
work page 2015
-
[44]
Data-efficient image quality assessment with attention-panel decoder
Guanyi Qin, Runze Hu, Yutao Liu, Xiawu Zheng, Haotian Liu, Xiu Li, and Yan Zhang. Data-efficient image quality assessment with attention-panel decoder. InAAAI, pages 2091–2100, 2023. 3
work page 2091
-
[45]
Shaolin Su, Hanhe Lin, Vlad Hosu, Oliver Wiedemann, Jin- qiu Sun, Yu Zhu, Hantao Liu, Yanning Zhang, and Dietmar Saupe. Going the extra mile in face image quality assess- ment: A novel database and model.IEEE Transactions on Multimedia, 2023. 5
work page 2023
-
[46]
Dual associated encoder for face restoration
Yu-Ju Tsai, Yu-Lun Liu, Lu Qi, Kelvin CK Chan, and Ming- Hsuan Yang. Dual associated encoder for face restoration. ICLR, 2024. 1, 3, 5, 7
work page 2024
-
[47]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 2555–2563, 2023. 5, 6
work page 2023
-
[48]
To- wards real-world blind face restoration with generative fa- cial prior
Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. To- wards real-world blind face restoration with generative fa- cial prior. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 1, 3, 6
work page 2021
-
[49]
Restoreformer: High-quality blind face restoration from undegraded key-value pairs
Zhouxia Wang, Jiawei Zhang, Runjian Chen, Wenping Wang, and Ping Luo. Restoreformer: High-quality blind face restoration from undegraded key-value pairs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 17512–17521, 2022. 1, 5
work page 2022
-
[50]
Dr2: Diffusion-based robust degradation remover for blind face restoration
Zhixin Wang, Ziying Zhang, Xiaoyun Zhang, Huangjie Zheng, Mingyuan Zhou, Ya Zhang, and Yanfeng Wang. Dr2: Diffusion-based robust degradation remover for blind face restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1704– 1713, 2023. 1, 3, 5
work page 2023
-
[51]
Deep retinex decomposition for low-light enhancement
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560, 2018. 6
-
[52]
Q-align: Teaching lmms for visual scoring via discrete text-defined levels.ICLR, 2024
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.ICLR, 2024. 5, 6
work page 2024
-
[53]
Diffir: Efficient diffusion model for image restoration
Bin Xia, Yulun Zhang, Shiyin Wang, Yitong Wang, Xing- long Wu, Yapeng Tian, Wenming Yang, and Luc Van Gool. Diffir: Efficient diffusion model for image restoration. In ICCV, 2023. 6
work page 2023
-
[54]
Snr-aware low-light image enhancement
Xiaogang Xu, Ruixing Wang, Chi-Wing Fu, and Jiaya Jia. Snr-aware low-light image enhancement. InCVPR, pages 17714–17724, 2022. 8
work page 2022
-
[55]
You only need one color space: An efficient network for low-light image enhancement.CVPR, 2025
Qingsen Yan, Yixu Feng, Cheng Zhang, Pei Wang, Peng Wu, Wei Dong, Jinqiu Sun, and Yanning Zhang. You only need one color space: An efficient network for low-light image enhancement.CVPR, 2025. 6, 7, 8
work page 2025
-
[56]
Miao Yang and Arcot Sowmya. An underwater color im- age quality evaluation metric.IEEE Transactions on Image Processing, 24(12):6062–6071, 2015. 6
work page 2015
-
[57]
Wenhan Yang, Wenjing Wang, Haofeng Huang, Shiqi Wang, and Jiaying Liu. Sparse gradient regularized deep retinex network for robust low-light image enhancement.IEEE Transactions on Image Processing, 30:2072–2086, 2021. 6
work page 2072
-
[58]
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild. InCVPR, pages 25669–25680, 2024. 3
work page 2024
-
[59]
Zongsheng Yue and Chen Change Loy. Difface: Blind face restoration with diffused error contraction.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2024. 2, 5, 6, 7
work page 2024
-
[60]
Dual adversarial network: Toward real-world noise removal and noise generation
Zongsheng Yue, Qian Zhao, Lei Zhang, and Deyu Meng. Dual adversarial network: Toward real-world noise removal and noise generation. InECCV, pages 41–58, 2020. 3
work page 2020
-
[61]
Learning enriched features for real image restoration and enhancement
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Learning enriched features for real image restoration and enhancement. InECCV, pages 492–511. Springer, 2020. 8
work page 2020
-
[62]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InCVPR, pages 5728–5739, 2022. 8
work page 2022
-
[63]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 7
work page 2018
-
[64]
Towards authentic face restora- tion with iterative diffusion models and beyond.ICCV, 2023
Yang Zhao, Tingbo Hou, Yu-Chuan Su, Xuhui Jia Li, Matthias Grundmann, et al. Towards authentic face restora- tion with iterative diffusion models and beyond.ICCV, 2023. 1, 3
work page 2023
-
[65]
Empowering low- light image enhancer through customized learnable priors
Naishan Zheng, Man Zhou, Yanmeng Dong, Xiangyu Rui, Jie Huang, Chongyi Li, and Feng Zhao. Empowering low- light image enhancer through customized learnable priors. In ICCV, pages 12559–12569, 2023. 6
work page 2023
-
[66]
Jingchun Zhou, Qian Liu, Qiuping Jiang, Wenqi Ren, Kin- Man Lam, and Weishi Zhang. Underwater camera: Improv- ing visual perception via adaptive dark pixel prior and color correction.International Journal of Computer Vision, pages 1–19, 2023. 6
work page 2023
-
[67]
Shangchen Zhou, Kelvin Chan, Chongyi Li, and Chen Change Loy. Towards robust blind face restora- tion with codebook lookup transformer.Advances in Neural Information Processing Systems, 35:30599–30611, 2022. 1, 3, 5, 6, 8
work page 2022
-
[68]
Adapt or perish: Adaptive sparse transformer with attentive feature refinement for image restoration
Shihao Zhou, Duosheng Chen, Jinshan Pan, Jinglei Shi, and Jufeng Yang. Adapt or perish: Adaptive sparse transformer with attentive feature refinement for image restoration. In CVPR, pages 2952–2963, 2024. 6, 7
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.