Recognition: 2 theorem links
· Lean TheoremC-TRAIL: A Commonsense World Framework for Trajectory Planning in Autonomous Driving
Pith reviewed 2026-05-13 23:24 UTC · model grok-4.3
The pith
C-TRAIL couples LLM commonsense with a dual-trust mechanism to guide trajectory planning in autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
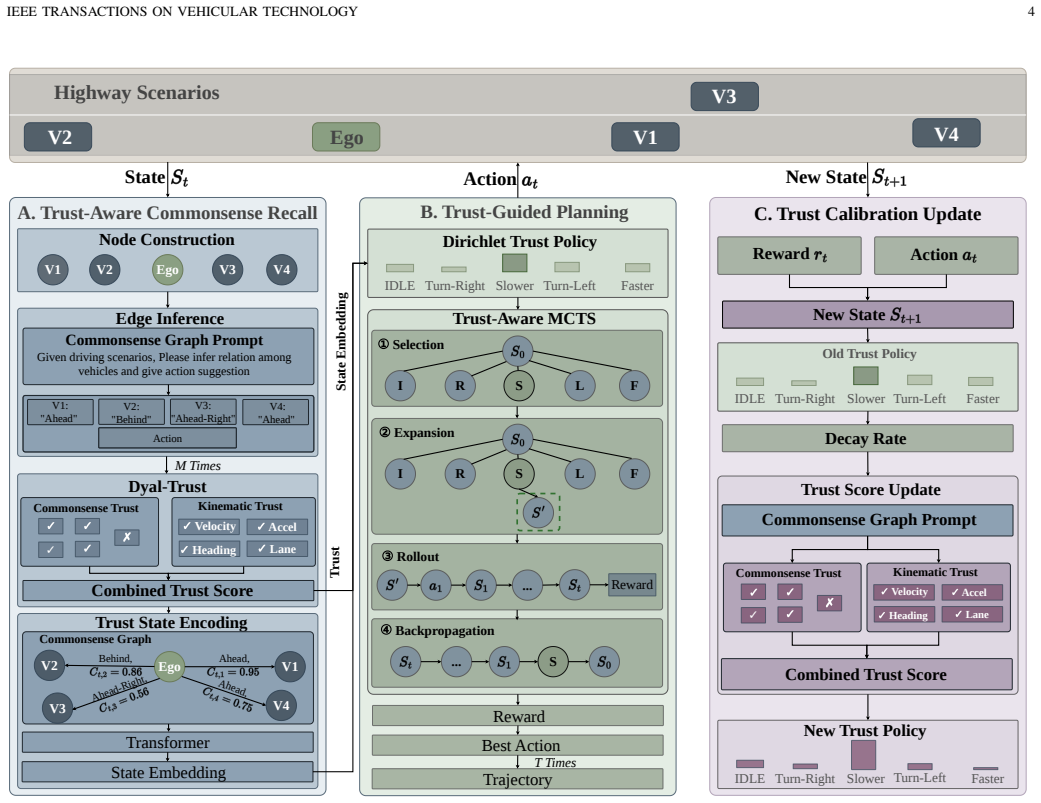
C-TRAIL is a framework built on a Commonsense World that couples LLM-derived commonsense with a trust mechanism to guide trajectory planning through a closed-loop Recall, Plan, and Update cycle. The Recall module queries an LLM for semantic relations and quantifies reliability via a dual-trust mechanism. The Plan module injects trust-weighted commonsense into Monte Carlo Tree Search through a Dirichlet trust policy. The Update module adaptively refines trust scores and policy parameters from environmental feedback.
What carries the argument
The dual-trust mechanism combined with a Dirichlet trust policy that weights LLM commonsense inside Monte Carlo Tree Search planning.
If this is right
- Reduces average displacement error by 40.2 percent on average across tested scenarios.
- Reduces final displacement error by 51.7 percent on average.
- Raises success rate by 16.9 percentage points on average.
- Maintains the gains on both simulated highway environments and real-world highD and rounD datasets.
Where Pith is reading between the lines
- The closed-loop trust adaptation could reduce the need for hand-crafted safety rules in other LLM-assisted control tasks.
- If the Dirichlet policy generalizes, similar weighting might improve reliability of LLM outputs in non-driving domains such as robotic manipulation.
- Longer-term operation might reveal whether repeated updates stabilize or drift under distribution shifts not present in the current evaluations.
Load-bearing premise
The dual-trust mechanism and Dirichlet trust policy accurately quantify LLM reliability without introducing new biases or instability in the closed-loop updates.
What would settle it
A controlled test on unseen driving scenarios in which the reported reductions in ADE and FDE disappear or trust scores become uncorrelated with planning success.
Figures






read the original abstract
Trajectory planning for autonomous driving increasingly leverages large language models (LLMs) for commonsense reasoning, yet LLM outputs are inherently unreliable, posing risks in safety-critical applications. We propose C-TRAIL, a framework built on a Commonsense World that couples LLM-derived commonsense with a trust mechanism to guide trajectory planning. C-TRAIL operates through a closed-loop Recall, Plan, and Update cycle: the Recall module queries an LLM for semantic relations and quantifies their reliability via a dual-trust mechanism; the Plan module injects trust-weighted commonsense into Monte Carlo Tree Search (MCTS) through a Dirichlet trust policy; and the Update module adaptively refines trust scores and policy parameters from environmental feedback. Experiments on four simulated scenarios in Highway-env and two real-world levelXData datasets (highD, rounD) show that C-TRAIL consistently outperforms state-of-the-art baselines, reducing ADE by 40.2%, FDE by 51.7%, and improving SR by 16.9 percentage points on average. The source code is available at https://github.com/ZhihongCui/CTRAIL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes C-TRAIL, a framework for trajectory planning in autonomous driving that integrates LLM-derived commonsense reasoning with a dual-trust mechanism and a Dirichlet trust policy within Monte Carlo Tree Search (MCTS). It operates via a closed-loop Recall-Plan-Update cycle and demonstrates improved performance on simulated and real-world datasets, with average reductions of 40.2% in Average Displacement Error (ADE), 51.7% in Final Displacement Error (FDE), and a 16.9 percentage point increase in Success Rate (SR) compared to baselines.
Significance. If the results hold, this work could advance the field by providing a method to mitigate the unreliability of LLMs in safety-critical trajectory planning for autonomous vehicles. The quantitative improvements are notable and suggest potential for more robust integration of commonsense knowledge in planning algorithms.
major comments (3)
- [Experiments] Experiments section: The reported performance gains (40.2% ADE reduction, 51.7% FDE reduction, 16.9 pp SR improvement) are presented without ablation studies that isolate the dual-trust mechanism and Dirichlet trust policy. This makes it unclear whether the improvements stem from the proposed trust components or from other aspects of the MCTS or scenario setup.
- [Update module] Update module description: No plots or analysis are provided showing how trust scores evolve relative to actual prediction errors, nor any evaluation of closed-loop stability under noisy or contradictory LLM outputs. This is essential to validate the core assumption that the trust mechanism accurately quantifies reliability without introducing bias or instability.
- [Experiments] Baseline comparisons: Details on the implementation, hyperparameter tuning, and statistical significance testing of the state-of-the-art baselines are insufficient to fully support the claimed superiority.
minor comments (2)
- [Introduction] The term 'Commonsense World' is introduced but its precise definition, construction, and differentiation from standard world models could be clarified earlier in the text.
- [Methodology] Ensure that all equations for the dual-trust scores and Dirichlet policy are accompanied by clear explanations of variables and their initialization.
Simulated Author's Rebuttal
We are grateful for the referee's thorough review and constructive feedback on our manuscript. We address each major comment point by point below, outlining our responses and the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported performance gains (40.2% ADE reduction, 51.7% FDE reduction, 16.9 pp SR improvement) are presented without ablation studies that isolate the dual-trust mechanism and Dirichlet trust policy. This makes it unclear whether the improvements stem from the proposed trust components or from other aspects of the MCTS or scenario setup.
Authors: We thank the referee for highlighting this important point. We agree that ablation studies are necessary to demonstrate the specific contributions of the dual-trust mechanism and the Dirichlet trust policy. In the revised version, we will add detailed ablation experiments that systematically remove or modify these components and report the resulting performance metrics. This will provide clear evidence that the observed improvements are attributable to the proposed trust mechanisms rather than other elements of the framework. revision: yes
-
Referee: [Update module] Update module description: No plots or analysis are provided showing how trust scores evolve relative to actual prediction errors, nor any evaluation of closed-loop stability under noisy or contradictory LLM outputs. This is essential to validate the core assumption that the trust mechanism accurately quantifies reliability without introducing bias or instability.
Authors: We acknowledge this gap in the current manuscript. To address it, we will include new figures and analysis in the revised paper that plot the evolution of trust scores against actual prediction errors across multiple scenarios. Additionally, we will conduct and report experiments assessing the closed-loop stability when the LLM provides noisy or contradictory outputs. These additions will help validate the robustness of the trust mechanism. revision: yes
-
Referee: [Experiments] Baseline comparisons: Details on the implementation, hyperparameter tuning, and statistical significance testing of the state-of-the-art baselines are insufficient to fully support the claimed superiority.
Authors: We agree that more details are needed for reproducibility and to substantiate the claims. In the revision, we will expand the experimental section with full implementation details for all baselines, including the specific hyperparameters used and the tuning methodology. We will also perform and report statistical significance tests (such as paired t-tests) on the performance differences to confirm the superiority of C-TRAIL. revision: yes
Circularity Check
No significant circularity; empirical claims rest on held-out evaluation
full rationale
The manuscript describes an engineering framework (Recall-Plan-Update cycle with dual-trust and Dirichlet policy) whose central results are reported performance deltas on four simulated Highway-env scenarios plus two external real-world datasets (highD, rounD). No derivation step is shown to reduce by construction to its own fitted inputs; trust scores are explicitly updated from environmental feedback rather than being self-referential. No self-citation load-bearing uniqueness theorem, ansatz smuggling, or renaming of known results appears in the provided architecture. The performance numbers are therefore treated as independent empirical measurements rather than tautological outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- trust parameters and Dirichlet policy coefficients
axioms (1)
- domain assumption LLM outputs contain usable semantic relations that can be quantified for reliability via a dual-trust mechanism
invented entities (1)
-
Commonsense World
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (Jcost uniqueness, Aczél classification)washburn_uniqueness_aczel unclearTrust-Aware Commonsense Recall ... dual-trust mechanism ... Dirichlet trust policy ... Trust Calibration Update
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearclosed-loop Recall, Plan, and Update cycle
Reference graph
Works this paper leans on
-
[1]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wanget al., “Planning-oriented autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
work page 2023
-
[2]
Planning and tracking control of full drive-by-wire electric vehicles in unstructured scenario,
G. Chen, M. Hua, W. Liu, J. Wang, S. Song, C. Liu, L. Yang, S. Liao, and X. Xia, “Planning and tracking control of full drive-by-wire electric vehicles in unstructured scenario,”Proceedings of the Institution of Mechanical Engineers, vol. 238, no. 13, pp. 3941–3956, 2024
work page 2024
-
[3]
H. Li, P. Chen, G. Yu, B. Zhou, Y . Li, and Y . Liao, “Trajectory planning for autonomous driving in unstructured scenarios based on deep learning and quadratic optimization,”IEEE Transactions on Vehicular Technology, vol. 73, no. 4, pp. 4886–4903, 2023
work page 2023
-
[4]
A framework for predicting trajec- tories using global and local information,
W. Groves, E. Nunes, and M. Gini, “A framework for predicting trajec- tories using global and local information,” inProceedings of the 11th ACM Conference on Computing Frontiers, 2014, pp. 1–10
work page 2014
-
[5]
A cognition-inspired trajectory prediction method for vehicles in interactive scenarios,
S. Xie, J. Li, and J. Wang, “A cognition-inspired trajectory prediction method for vehicles in interactive scenarios,”IET Intelligent Transport Systems, vol. 17, no. 8, pp. 1544–1559, 2023
work page 2023
-
[6]
Predicting long-term human behaviors in discrete representations via physics-guided diffusion,
Z. Zhang, A. Li, A. Lim, and M. Chen, “Predicting long-term human behaviors in discrete representations via physics-guided diffusion,”arXiv preprint arXiv:2405.19528, 2024
-
[7]
Exploring the limitations of behavior cloning for autonomous driving,
F. Codevilla, E. Santana, A. M. L ´opez, and A. Gaidon, “Exploring the limitations of behavior cloning for autonomous driving,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9329–9338
work page 2019
-
[8]
Motion planning for autonomous driving: The state of the art and future perspectives,
S. Teng, X. Hu, P. Deng, B. Li, Y . Li, Y . Ai, D. Yang, L. Li, Z. Xuanyuan, F. Zhuet al., “Motion planning for autonomous driving: The state of the art and future perspectives,”IEEE Transactions on Intelligent Vehicles, vol. 8, no. 6, pp. 3692–3711, 2023
work page 2023
-
[9]
The cognitive map in humans: spatial navigation and beyond,
R. A. Epstein, E. Z. Patai, J. B. Julian, and H. J. Spiers, “The cognitive map in humans: spatial navigation and beyond,”Nature neuroscience, vol. 20, no. 11, pp. 1504–1513, 2017
work page 2017
-
[10]
Replay shapes abstract cognitive maps for efficient social navigation,
J.-Y . Son, M.-L. Vives, A. Bhandari, and O. FeldmanHall, “Replay shapes abstract cognitive maps for efficient social navigation,”Nature Human Behaviour, vol. 8, no. 11, pp. 2156–2167, 2024
work page 2024
-
[11]
Trial and error: Exploration-based trajectory optimization for llm agents,
Y . Song, D. Yin, X. Yue, J. Huang, S. Li, and B. Y . Lin, “Trial and error: Exploration-based trajectory optimization for llm agents,”arXiv preprint arXiv:2403.02502, 2024
-
[12]
imotion-llm: Motion prediction instruction tuning,
A. Felemban, E. M. Bakr, X. Shen, J. Ding, A. Mohamed, and M. Elho- seiny, “imotion-llm: Motion prediction instruction tuning,”arXiv preprint arXiv:2406.06211, 2024
-
[13]
X. Li, Y . Sun, J. Lin, L. Li, T. Feng, and S. Yin, “The synergy of seeing and saying: Revolutionary advances in multi-modality medical vision- language large models,”Artificial Intelligence Science and Engineering, vol. 1, no. 2, pp. 79–97, 2025
work page 2025
-
[14]
DyBooster: Leveraging large language model as booster for dynamic recommendation,
H. Tang, X. Sun, S. Wu, Z. Cui, G. Xu, and Q. Li, “DyBooster: Leveraging large language model as booster for dynamic recommendation,”Expert Systems with Applications, vol. 286, p. 128080, 2025. IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY 13
work page 2025
-
[15]
B. Peng, M. Galley, P. He, H. Cheng, Y . Xie, Y . Hu, Q. Huang, L. Liden, Z. Yu, W. Chenet al., “Check your facts and try again: Improving large language models with external knowledge and automated feedback,” arXiv preprint arXiv:2302.12813, 2023
-
[16]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qinet al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2025
work page 2025
-
[17]
Q*: Improving multi-step reasoning for llms with deliberative planning,
C. Wang, Y . Deng, Z. Lyu, L. Zeng, J. He, S. Yan, and B. An, “Q*: Improving multi-step reasoning for llms with deliberative planning,” arXiv preprint arXiv:2406.14283, 2024
-
[18]
Embodied agent interface: Benchmark- ing llms for embodied decision making,
M. Li, S. Zhao, Q. Wang, K. Wang, Y . Zhou, S. Srivastava, C. Gokmen, T. Lee, E. L. Li, R. Zhanget al., “Embodied agent interface: Benchmark- ing llms for embodied decision making,”Advances in Neural Information Processing Systems, vol. 37, pp. 100 428–100 534, 2024
work page 2024
-
[19]
Adaplanner: Adaptive planning from feedback with language models,
H. Sun, Y . Zhuang, L. Kong, B. Dai, and C. Zhang, “Adaplanner: Adaptive planning from feedback with language models,”Advances in neural information processing systems, vol. 36, pp. 58 202–58 245, 2023
work page 2023
-
[20]
L. Pan, M. Saxon, W. Xu, D. Nathani, X. Wang, and W. Y . Wang, “Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies,”arXiv preprint arXiv:2308.03188, 2023
-
[21]
Integrating llms with its: Recent advances, potentials, challenges, and future directions,
D. Mahmud, H. Hajmohamed, S. Almentheri, S. Alqaydi, L. Aldhaheri, R. A. Khalil, and N. Saeed, “Integrating llms with its: Recent advances, potentials, challenges, and future directions,”IEEE Transactions on Intelligent Transportation Systems, 2025
work page 2025
-
[22]
O. Zheng, M. Abdel-Aty, D. Wang, C. Wang, and S. Ding, “Trafficsafe- tygpt: Tuning a pre-trained large language model to a domain-specific expert in transportation safety,”arXiv preprint arXiv:2307.15311, 2023
-
[23]
Survey on factuality in large language models: Knowledge, retrieval and domain-specificity,
C. Wang, X. Liu, Y . Yue, X. Tang, T. Zhang, C. Jiayang, Y . Yao, W. Gao, X. Hu, Z. Qiet al., “Survey on factuality in large language models: Knowledge, retrieval and domain-specificity,”arXiv preprint arXiv:2310.07521, 2023
-
[24]
Do as i can, not as i say: Grounding language in robotic affordances,
A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julianet al., “Do as i can, not as i say: Grounding language in robotic affordances,” inConference on robot learning. PMLR, 2023, pp. 287–318
work page 2023
-
[25]
Ask me anything: A simple strategy for prompting language models,
S. Arora, A. Narayan, M. F. Chen, L. Orr, N. Guha, K. Bhatia, I. Chami, F. Sala, and C. R ´e, “Ask me anything: A simple strategy for prompting language models,”arXiv preprint arXiv:2210.02441, 2022
-
[26]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch, “Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,” inInternational conference on machine learning. PMLR, 2022, pp. 9118–9147
work page 2022
-
[27]
Mastering the game of go without human knowledge,
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Boltonet al., “Mastering the game of go without human knowledge,”nature, vol. 550, no. 7676, pp. 354–359, 2017
work page 2017
-
[28]
L. Guan, K. Valmeekam, S. Sreedharan, and S. Kambhampati, “Lever- aging pre-trained large language models to construct and utilize world models for model-based task planning,”Advances in Neural Information Processing Systems, vol. 36, pp. 79 081–79 094, 2023
work page 2023
-
[29]
Llm-planner: Few-shot grounded planning for embodied agents with large language models,
C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y . Su, “Llm-planner: Few-shot grounded planning for embodied agents with large language models,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 2998–3009
work page 2023
-
[30]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 9493–9500
work page 2023
-
[31]
Mastering atari, go, chess and shogi by planning with a learned model,
J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lockhart, D. Hassabis, T. Graepelet al., “Mastering atari, go, chess and shogi by planning with a learned model,” Nature, vol. 588, no. 7839, pp. 604–609, 2020
work page 2020
-
[32]
Human-level play in the game of diplomacy by combining language models with strategic reasoning,
M. F. A. R. D. T. (FAIR)†, A. Bakhtin, N. Brown, E. Dinan, G. Farina, C. Flaherty, D. Fried, A. Goff, J. Gray, H. Huet al., “Human-level play in the game of diplomacy by combining language models with strategic reasoning,”Science, vol. 378, no. 6624, pp. 1067–1074, 2022
work page 2022
-
[33]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model,
F. Liu, X. Tong, M. Yuan, X. Lin, F. Luo, Z. Wang, Z. Lu, and Q. Zhang, “Evolution of heuristics: Towards efficient automatic algorithm design using large language model,”arXiv preprint arXiv:2401.02051, 2024
-
[34]
Prompt, plan, perform: Llm-based humanoid control via quantized imitation learning,
J. Sun, Q. Zhang, Y . Duan, X. Jiang, C. Cheng, and R. Xu, “Prompt, plan, perform: Llm-based humanoid control via quantized imitation learning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 16 236–16 242
work page 2024
-
[35]
Guiding pretraining in reinforcement learning with large language models,
Y . Du, O. Watkins, Z. Wang, C. Colas, T. Darrell, P. Abbeel, A. Gupta, and J. Andreas, “Guiding pretraining in reinforcement learning with large language models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 8657–8677
work page 2023
-
[36]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,”arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Tidybot: Personalized robot assis- tance with large language models,
J. Wu, R. Antonova, A. Kan, M. Lepert, A. Zeng, S. Song, J. Bohg, S. Rusinkiewicz, and T. Funkhouser, “Tidybot: Personalized robot assis- tance with large language models,”Autonomous Robots, vol. 47, no. 8, pp. 1087–1102, 2023
work page 2023
-
[38]
Large language models-guided dynamic adaptation for temporal knowledge graph reasoning,
J. Wang, S. Kai, L. Luo, W. Wei, Y . Hu, A. W.-C. Liew, S. Pan, and B. Yin, “Large language models-guided dynamic adaptation for temporal knowledge graph reasoning,”Advances in Neural Information Processing Systems, vol. 37, pp. 8384–8410, 2024
work page 2024
-
[39]
{dLoRA}: Dynamically orchestrating requests and adapters for {LoRA}{LLM} serving,
B. Wu, R. Zhu, Z. Zhang, P. Sun, X. Liu, and X. Jin, “ {dLoRA}: Dynamically orchestrating requests and adapters for {LoRA}{LLM} serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 911–927
work page 2024
-
[40]
Model-agnostic dual-side online fairness learning for dynamic recommendation,
H. Tang, S. Wu, Z. Cui, Y . Li, G. Xu, and Q. Li, “Model-agnostic dual-side online fairness learning for dynamic recommendation,”IEEE Transactions on Knowledge and Data Engineering, vol. 37, no. 5, pp. 2727–2742, 2025
work page 2025
-
[41]
ieta: A robust and scalable incremental learning framework for time-of-arrival estimation,
J. Han, H. Liu, S. Liu, X. Chen, N. Tan, H. Chai, and H. Xiong, “ieta: A robust and scalable incremental learning framework for time-of-arrival estimation,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 4100–4111
work page 2023
-
[42]
Agent-pro: Learning to evolve via policy-level reflection and optimization,
W. Zhang, K. Tang, H. Wu, M. Wang, Y . Shen, G. Hou, Z. Tan, P. Li, Y . Zhuang, and W. Lu, “Agent-pro: Learning to evolve via policy-level reflection and optimization,”arXiv preprint arXiv:2402.17574, 2024
-
[43]
Learning from good trajectories in offline multi-agent reinforcement learning,
Q. Tian, K. Kuang, F. Liu, and B. Wang, “Learning from good trajectories in offline multi-agent reinforcement learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 10, 2023, pp. 11 672– 11 680
work page 2023
-
[44]
Optimal impulse control and impulse game for continuous-time deterministic systems: A review,
C. Li and W. Wang, “Optimal impulse control and impulse game for continuous-time deterministic systems: A review,”Artificial Intelligence Science and Engineering, vol. 1, no. 3, pp. 208–219, 2025
work page 2025
-
[45]
A general rein- forcement learning algorithm that masters chess, shogi, and go through self-play,
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepelet al., “A general rein- forcement learning algorithm that masters chess, shogi, and go through self-play,”Science, vol. 362, no. 6419, pp. 1140–1144, 2018
work page 2018
-
[46]
An environment for autonomous driving decision-making,
E. Leurent, “An environment for autonomous driving decision-making,” https://github.com/eleurent/highway-env, 2018
work page 2018
-
[47]
L. Wen, D. Fu, X. Li, X. Cai, T. Ma, P. Cai, M. Dou, B. Shi, L. He, and Y . Qiao, “Dilu: A knowledge-driven approach to autonomous driving with large language models,”arXiv preprint arXiv:2309.16292, 2023
-
[48]
A survey on multimodal large language models for autonomous driving,
C. Cui, Y . Ma, X. Cao, W. Ye, Y . Zhou, K. Liang, J. Chen, J. Lu, Z. Yang, K.-D. Liaoet al., “A survey on multimodal large language models for autonomous driving,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 958–979
work page 2024
-
[49]
A graph representation for autonomous driving,
Z. Xi and G. Sukthankar, “A graph representation for autonomous driving,” inThe 36th Conference on Neural Information Processing Systems Workshop, vol. 7, no. 8, 2022, p. 9
work page 2022
-
[50]
R. Krajewski, J. Bock, L. Kloeker, and L. Eckstein, “The highd dataset: A drone dataset of naturalistic vehicle trajectories on german highways for validation of highly automated driving systems,” in2018 21st International Conference on Intelligent Transportation Systems (ITSC), 2018, pp. 2118–2125
work page 2018
-
[51]
The round dataset: A drone dataset of road user trajectories at roundabouts in germany,
R. Krajewski, T. Moers, J. Bock, L. Vater, and L. Eckstein, “The round dataset: A drone dataset of road user trajectories at roundabouts in germany,” in2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), 2020, pp. 1–6
work page 2020
-
[52]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovskiet al., “Human-level control through deep reinforcement learning,”Nature, vol. 518, no. 7540, pp. 529–533, 2015
work page 2015
-
[53]
Inverse reinforcement learning optimal control for takagi-sugeno fuzzy systems,
W. Song and S. Tong, “Inverse reinforcement learning optimal control for takagi-sugeno fuzzy systems,”Artificial Intelligence Science and Engineering, vol. 1, no. 2, pp. 134–146, 2025
work page 2025
-
[54]
Efficient selectivity and backup operators in monte-carlo tree search,
R. Coulom, “Efficient selectivity and backup operators in monte-carlo tree search,” inInternational Conference on Computers and Games. Springer, 2006, pp. 72–83
work page 2006
-
[55]
MH-GIN: Multi-scale heterogeneous graph-based imputation network for AIS data,
H. Liu, T. Li, Y . He, K. Torp, Y . Li, and C. S. Jensen, “MH-GIN: Multi-scale heterogeneous graph-based imputation network for AIS data,” Proceedings of the VLDB Endowment, vol. 19, no. 2, pp. 170–182, 2025
work page 2025
-
[56]
Can language beat numerical regression? language-based multimodal trajectory prediction,
I. Bae, J. Lee, and H.-G. Jeon, “Can language beat numerical regression? language-based multimodal trajectory prediction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 753–766. IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY 14
work page 2024
-
[57]
Languagempc: Large language models as deci- sion makers for autonomous driving,
H. Sha, Y . Mu, Y . Jiang, L. Chen, C. Xu, P. Luo, S. E. Li, M. Tomizuka, W. Zhan, and M. Ding, “Languagempc: Large language models as deci- sion makers for autonomous driving,”arXiv preprint arXiv:2310.03026, 2023
-
[58]
Gpt-driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415,
J. Mao, Y . Qian, H. Zhao, and Y . Wang, “Gpt-driver: Learning to drive with gpt,”arXiv preprint arXiv:2310.01415, 2023
-
[59]
Humanlike driving: Empirical decision- making system for autonomous vehicles,
L. Li, K. Ota, and M. Dong, “Humanlike driving: Empirical decision- making system for autonomous vehicles,”IEEE Transactions on Vehic- ular Technology, vol. 67, no. 8, pp. 6814–6823, 2018
work page 2018
-
[60]
” my agent understands me better
Y . Hou, H. Tamoto, and H. Miyashita, “” my agent understands me better”: Integrating dynamic human-like memory recall and consolidation in llm- based agents,” inExtended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2024, pp. 1–7
work page 2024
-
[61]
Lc-llm: Explainable lane-change intention and trajectory predictions with large language models,
M. Peng, X. Guo, X. Chen, M. Zhu, K. Chen, X. Wang, Y . Wanget al., “Lc-llm: Explainable lane-change intention and trajectory predictions with large language models,”arXiv preprint arXiv:2403.18344, 2024
-
[62]
Monte carlo tree search for behavior planning in autonomous driving,
Q. Wen, Z. Gong, L. Zhou, and Z. Zhang, “Monte carlo tree search for behavior planning in autonomous driving,” in2024 IEEE International Symposium on Safety Security Rescue Robotics (SSRR). IEEE, 2024
work page 2024
-
[63]
Mbappe: Mcts-built-around prediction for planning explicitly,
R. Chekroun, T. Gilles, M. Toromanoff, S. Hornauer, and F. Moutarde, “Mbappe: Mcts-built-around prediction for planning explicitly,” in2024 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2024, pp. 2062–2069
work page 2024
-
[64]
Interpretable goal-based prediction and planning for autonomous driving,
S. V . Albrecht, C. Brewitt, J. Wilhelm, B. Gyevnar, F. Eiras, M. Dobre, and S. Ramamoorthy, “Interpretable goal-based prediction and planning for autonomous driving,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 1043–1049
work page 2021
-
[65]
X. Liu, M. Zhang, and E. Rogers, “Trajectory tracking control for autonomous underwater vehicles based on fuzzy re-planning of a local desired trajectory,”IEEE Transactions on Vehicular Technology, vol. 68, no. 12, pp. 11 657–11 667, 2019
work page 2019
-
[66]
Z. Li, P. Zhao, C. Jiang, W. Huang, and H. Liang, “A learning-based model predictive trajectory planning controller for automated driving in unstructured dynamic environments,”IEEE Transactions on Vehicular Technology, vol. 71, no. 6, pp. 5944–5959, 2022
work page 2022
-
[67]
CARLA: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “CARLA: An open urban driving simulator,” inConference on Robot Learning (CoRL), 2017, pp. 1–16
work page 2017
-
[68]
H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolber, A. Lang, L. Fletcher, O. Beijbom, and S. Omari, “nuPlan: A closed-loop ML- based planning benchmark for autonomous vehicles,”arXiv preprint arXiv:2106.11810, 2021. Zhihong Cuiis currently a postdoc at the University of Oslo, Norway. She has received her PhD from Shandong University in 2024 supervised...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.