Recognition: 2 theorem links
· Lean TheoremTask-Centric Personalized Federated Fine-Tuning of Language Models
Pith reviewed 2026-05-14 21:22 UTC · model grok-4.3
The pith
Task-centric clustering of adapters lets federated language models handle multiple tasks without interference and generalize to unseen ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
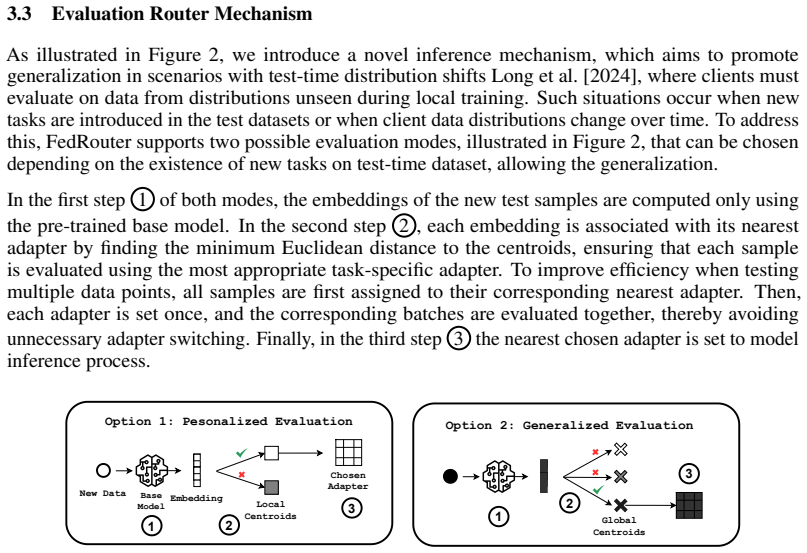
FedRouter is a clustering-based personalized federated learning method that associates adapters with specific tasks using a local clustering step on each client's data samples and a global clustering step that groups similar adapters from different clients, together with an evaluation router that routes unseen test samples to the most suitable adapter on the basis of the created clusters. This task-centric design produces models that remain resilient when clients train on multiple interfering distributions and that generalize better to tasks never seen during local training.
What carries the argument
FedRouter's dual clustering (local association of adapters with task samples on each client, global merging of similar adapters across clients) plus the evaluation router that selects the best adapter for test samples according to cluster membership.
If this is right
- Client models remain accurate even when a single client's data contains multiple interfering task distributions.
- Performance on tasks absent from any client's training data rises substantially relative to prior personalized federated approaches.
- Task-specific adapters can be reused across clients that share the same underlying task.
- The overall system avoids the accuracy drop that normally occurs when federated averaging mixes heterogeneous task signals.
Where Pith is reading between the lines
- The same local-plus-global clustering pattern could be applied to federated settings outside language models, such as vision or sensor data, whenever task interference is the dominant failure mode.
- Dynamic insertion of new tasks would require only the creation and clustering of additional adapters rather than retraining the entire collection.
- Task identity rather than client identity may be the more stable organizing principle for personalization whenever data distributions shift over time.
Load-bearing premise
The local and global clustering steps can reliably group adapters with distinct tasks without significant overlap or misassignment, and the router will correctly send test samples to the matching adapter.
What would settle it
A controlled test in which the clustering produces mixed clusters containing samples from different tasks and the router assigns a substantial fraction of test samples to the wrong adapter, after which measured accuracy falls to or below the level of standard client-centric baselines.
Figures






read the original abstract
Federated Learning (FL) has emerged as a promising technique for training language models on distributed and private datasets of diverse tasks. However, aggregating models trained on heterogeneous tasks often degrades the overall performance of individual clients. To address this issue, Personalized FL (pFL) aims to create models tailored for each client's data distribution. Although these approaches improve local performance, they usually lack robustness in two aspects: (i) generalization: when clients must make predictions on unseen tasks, or face changes in their data distributions, and (ii) intra-client tasks interference: when a single client's data contains multiple distributions that may interfere with each other during local training. To tackle these two challenges, we propose FedRouter, a clustering-based pFL that builds specialized models for each task rather than for each client. FedRouter uses adapters to personalize models by employing two clustering mechanisms to associate adapters with specific tasks. A local clustering that associate adapters with task data samples and a global one that associates similar adapters from different clients to construct task-centric personalized models. Additionally, we propose an evaluation router mechanism that routes test samples to the best adapter based on the created clusters. Experiments comparing our method with existing approaches across a multitask dataset, FedRouter demonstrate strong resilience in these challenging scenarios performing up to 6.1% relatively better under tasks interference and up to 136% relative improvement under generalization evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FedRouter, a clustering-based personalized federated learning method for fine-tuning language models with adapters. It performs local clustering to associate adapters with task-specific data samples within each client and global clustering to merge similar adapters across clients into task-centric models. An evaluation router then directs test samples to the appropriate adapter. On a multitask dataset, the approach is claimed to deliver up to 6.1% relative improvement in resilience to intra-client task interference and up to 136% relative improvement in generalization compared with existing personalized FL baselines.
Significance. If the clustering steps can be shown to produce reliable task separation, FedRouter would meaningfully advance personalized federated learning for heterogeneous language-model workloads by moving from client-centric to task-centric personalization. This directly targets two practical failure modes—task interference within a client and poor generalization to unseen tasks—while retaining the parameter efficiency of adapters. Successful validation could influence both algorithmic design and evaluation practices in federated LLM fine-tuning.
major comments (3)
- [§3 (Method)] §3 (Method): The local and global clustering mechanisms are load-bearing for the central claim, yet the manuscript provides no specification of the clustering algorithm, distance metric, or rule for choosing the number of clusters. Without these details it is impossible to determine whether the clusters reliably isolate distinct tasks or whether the evaluation router can avoid misassignment.
- [§4 (Experiments)] §4 (Experiments): No quantitative diagnostics of clustering quality (cluster purity, silhouette score, or misassignment rate) are reported on the labeled multitask benchmark. The headline gains (6.1 % interference resilience, 136 % generalization) rest on the assumption that clustering correctly partitions tasks; absent these checks the improvements could be artifacts of favorable partitioning rather than the proposed mechanisms.
- [Abstract and §4] Abstract and §4: The reported relative gains omit statistical significance, number of runs, and variance; it is also unclear whether the “best adapter” was selected post-hoc, which would inflate the numbers and undermine the cross-method comparison.
minor comments (1)
- [Abstract] Abstract: The final sentence contains a grammatical error and unclear phrasing (“across a multitask dataset, FedRouter demonstrate…”). It should be revised for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving clarity, reproducibility, and rigor. We will revise the manuscript to address each point as outlined below.
read point-by-point responses
-
Referee: [§3 (Method)] §3 (Method): The local and global clustering mechanisms are load-bearing for the central claim, yet the manuscript provides no specification of the clustering algorithm, distance metric, or rule for choosing the number of clusters. Without these details it is impossible to determine whether the clusters reliably isolate distinct tasks or whether the evaluation router can avoid misassignment.
Authors: We agree that the current manuscript lacks explicit implementation details for the clustering steps. In the revised version, we will add a dedicated paragraph in §3 specifying that both local and global clustering use the K-means algorithm applied to task embeddings, with cosine similarity as the distance metric. The number of clusters for global clustering will be set to the known number of tasks in the benchmark, while local clustering will use the elbow method on the within-cluster sum of squares to select the number per client. We will also include pseudocode for the full procedure and the exact hyperparameter values used. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): No quantitative diagnostics of clustering quality (cluster purity, silhouette score, or misassignment rate) are reported on the labeled multitask benchmark. The headline gains (6.1 % interference resilience, 136 % generalization) rest on the assumption that clustering correctly partitions tasks; absent these checks the improvements could be artifacts of favorable partitioning rather than the proposed mechanisms.
Authors: We acknowledge that reporting clustering quality metrics would strengthen the validation of the core mechanism. In the revised manuscript, we will add a new table in §4 reporting cluster purity (computed against ground-truth task labels), average silhouette scores, and misassignment rates across clients. These diagnostics will be computed on the labeled multitask benchmark and will demonstrate high purity and low misassignment, supporting that the reported gains arise from effective task separation rather than incidental partitioning. revision: yes
-
Referee: [Abstract and §4] Abstract and §4: The reported relative gains omit statistical significance, number of runs, and variance; it is also unclear whether the “best adapter” was selected post-hoc, which would inflate the numbers and undermine the cross-method comparison.
Authors: We apologize for the incomplete reporting in the current draft. All experiments were run over 5 independent trials with different random seeds; we will update both the abstract and §4 to report mean performance together with standard deviation. We will also add paired t-test p-values to establish statistical significance of the improvements. The adapter assignment is performed by the evaluation router using proximity to cluster centroids (as defined in §3), not by post-hoc selection of the best adapter; we will add an explicit statement clarifying this and confirming that the same routing logic is applied consistently in the comparisons. revision: yes
Circularity Check
No significant circularity; method is a novel algorithmic construction
full rationale
The paper introduces FedRouter as a new clustering-based pFL algorithm that associates adapters with tasks via local and global clustering plus an evaluation router. No equations, fitted parameters, or derivation steps are shown that reduce by construction to the paper's own inputs or self-citations. Claims rest on empirical comparisons rather than a self-referential chain; clustering is presented as an independent design choice without load-bearing self-citation or renaming of prior results. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FedRouter uses adapters to personalize models by employing two clustering mechanisms to associate adapters with specific tasks. A local clustering that associate adapters with task data samples and a global one that associates similar adapters from different clients to construct task-centric personalized models.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
each embedding is associated with its nearest adapter by finding the minimum Euclidean distance to the centroids
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Weiming Zhuang, Chen Chen, and Lingjuan Lyu. When foundation model meets federated learning: Motivations, challenges, and future directions.arXiv preprint arXiv:2306.15546,
-
[2]
Worldwide federated training of language models.arXiv preprint arXiv:2405.14446,
Alex Iacob, Lorenzo Sani, Bill Marino, Preslav Aleksandrov, William F Shen, and Nicholas Donald Lane. Worldwide federated training of language models.arXiv preprint arXiv:2405.14446,
-
[3]
URL https://openreview.net/forum? id=AQgYcfg5EI. Lingling Xu, Haoran Xie, Si-Zhao Joe Qin, Xiaohui Tao, and Fu Lee Wang. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment.arXiv preprint arXiv:2312.12148,
-
[4]
Towards building the federatedgpt: Federated instruction tuning
Jianyi Zhang, Saeed Vahidian, Martin Kuo, Chunyuan Li, Ruiyi Zhang, Tong Yu, Guoyin Wang, and Yiran Chen. Towards building the federatedgpt: Federated instruction tuning. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6915–6919. IEEE,
work page 2024
-
[5]
Improving lora in privacy-preserving federated learning.arXiv preprint arXiv:2403.12313,
Youbang Sun, Zitao Li, Yaliang Li, and Bolin Ding. Improving lora in privacy-preserving federated learning.arXiv preprint arXiv:2403.12313,
-
[6]
Selective aggregation for low-rank adaptation in federated learning.arXiv preprint arXiv:2410.01463,
Pengxin Guo, Shuang Zeng, Yanran Wang, Huijie Fan, Feifei Wang, and Liangqiong Qu. Selective aggregation for low-rank adaptation in federated learning.arXiv preprint arXiv:2410.01463,
-
[7]
Multi-task learning with deep neural networks: A survey.arXiv preprint arXiv:2009.09796,
Michael Crawshaw. Multi-task learning with deep neural networks: A survey.arXiv preprint arXiv:2009.09796,
-
[8]
Gabriel U. Talasso, Allan M. de Souza, Luiz F. Bittencourt, Eduardo Cerqueira, Antonio A. F. Loureiro, and Leandro A. Villas. Fedsccs: Hierarchical clustering with multiple models for federated learning. InICC 2024 - IEEE International Conference on Communications, pages 3280–3285,
work page 2024
-
[9]
doi: 10.1109/ICC51166.2024.10622346. Gabriel U Talasso, Allan M de Souza, Luis FG Gonzalez, Eduardo Cerqueira, Antonio AF Loureiro, and Leandro A Villas. Leveraging federated learning for multilingual and private language models via model clustering. In2025 3rd International Conference on Federated Learning Technologies and Applications (FLTA), pages 25–32. IEEE,
-
[10]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Flower: A friendly federated learning research framework.arXiv preprint arXiv:2007.14390,
Daniel J Beutel, Taner Topal, Akhil Mathur, Xinchi Qiu, Javier Fernandez-Marques, Yan Gao, Lorenzo Sani, Kwing Hei Li, Titouan Parcollet, Pedro Porto Buarque De Gusmão, et al. Flower: A friendly federated learning research framework.arXiv preprint arXiv:2007.14390,
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.