Recognition: unknown
A Taxonomy of Programming Languages for Code Generation
Pith reviewed 2026-05-08 02:15 UTC · model gemini-3-flash-preview
The pith
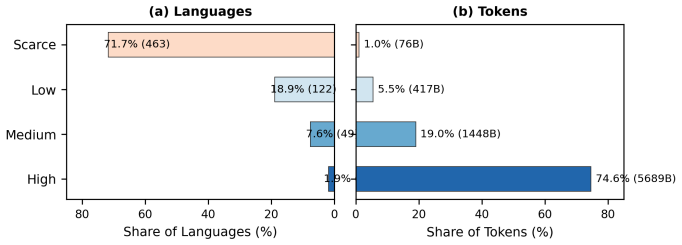
A new taxonomy reveals that less than 2% of programming languages represent nearly 75% of all publicly available training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors discovered that the distribution of programming language data is characterized by an extreme long tail, where 12 languages (Tier 3) provide 74.6% of all tokens across seven major corpora, while 463 languages (Tier 0) contribute only 1.0%. Using statistical measures like the Gini coefficient and Zipf's Law, they demonstrate that this disparity is a systematic feature of the current software ecosystem. This classification allows for tier-aware evaluation of large language models, ensuring that performance benchmarks account for the inherent resource scarcity of niche or legacy languages.
What carries the argument
A four-tier resource taxonomy (High, Medium, Low, Scarce) calculated by aggregating token counts from seven representative code corpora to classify 646 programming languages based on their availability for model training.
If this is right
- Benchmarks for AI code generation will likely shift toward tier-specific scoring to avoid inflating performance averages with high-resource languages.
- Data curation efforts will prioritize the 'missing middle' (Tiers 1 and 2) to improve the generalizability of multilingual models.
- Model performance on low-resource languages can be predicted by their tier placement rather than assumed to be a general architectural failure.
Where Pith is reading between the lines
- The scarcity of data for older or specialized languages may create a digital maintenance gap for legacy systems as AI-assisted coding becomes the industry standard.
- This taxonomy could be used to identify linguistic arbitrage opportunities where synthetic data generation is most cost-effective for underserved languages.
Load-bearing premise
The paper assumes that the total number of tokens in seven public repositories is an accurate proxy for a language's real-world utility and the actual amount of code written globally.
What would settle it
If a massive, previously private repository were made public and its language distribution significantly flattened the ratio between Tier 0 and Tier 3 languages, the taxonomy's claim of systemic scarcity would be invalidated.
Figures


read the original abstract
The world's 7,000+ languages vary widely in the availability of resources for NLP, motivating efforts to systematically categorize them by their degree of resourcefulness (Joshi et al., 2020). A similar disparity exists among programming languages (PLs); however, no resource-tier taxonomy has been established for code. As large language models (LLMs) grow increasingly capable of generating code, such a taxonomy becomes essential. To fill this gap, we present the first reproducible PL resource classification, grouping 646 languages into four tiers. We show that only 1.9% of languages (Tier 3, High) account for 74.6% of all tokens in seven major corpora, while 71.7% of languages (Tier 0, Scarce) contribute just 1.0%. Statistical analyses of within-tier inequality, dispersion, and distributional skew confirm that this imbalance is both extreme and systematic. Our results provide a principled framework for dataset curation and tier-aware evaluation of multilingual LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents a systematic taxonomy for programming languages (PLs) based on their availability in public training corpora, analogous to the resource tiers established for natural language processing by Joshi et al. (2020). By analyzing token distributions across seven major code-centric datasets (including The Stack v1/v2 and StarCoderData), the authors categorize 646 languages into four tiers: Tier 3 (High), Tier 2 (Medium), Tier 1 (Low), and Tier 0 (Scarce). The study employs Gini coefficients, Lorenz curves, and skewness metrics to quantify the extreme resource imbalance, finding that less than 2% of languages account for nearly 75% of the total available tokens. Finally, the authors demonstrate that LLM performance correlates with these tiers, providing a benchmark for future multilingual code model evaluation.
Significance. The manuscript addresses a critical gap in the code generation literature. While the 'low-resource' problem is well-defined for natural languages, the community has lacked a reproducible, data-driven framework to define resourcefulness for PLs. The paper’s strengths lie in its massive scale (646 languages) and the reproducibility of its classification. By providing a fixed taxonomy, the authors enable researchers to move beyond ad-hoc 'high-resource' vs 'low-resource' labels toward a standard categorization that can ground claims about model generalization and cross-lingual transfer in code tasks.
major comments (3)
- [§3.1, "Data Sources"] The methodology aggregates token counts by summing across seven datasets (The Stack v1, The Stack v2, StarCoderData, etc.). However, these datasets are known to have significant overlap, as many are successive iterations or subsets of the same GitHub crawl (e.g., The Stack v2 contains much of the content from v1). This introduces a 'multi-presence bias' that inflates the token counts of established languages that appeared in older crawls. Given that the tier boundaries are logarithmic (e.g., $10^9$ vs $10^{11}$ tokens), an inflation factor of 3x to 5x—plausible given the overlapping sources—could shift a language across a tier boundary. The authors should clarify if de-duplication across corpora was performed or provide a sensitivity analysis showing how tier assignments change if only the largest/most recent dataset (The Stack v2) is used.
- [§3.2, Table 1] The choice of boundaries ($10^7, 10^9, 10^{11}$) appears to be inherited from Joshi et al. (2020)'s work on natural language. However, token density and the 'vocabulary' size of programming languages differ significantly from natural language. For example, a C++ repository contains significantly more boilerplate and header-file tokens compared to a Python script of equivalent logic. The authors should provide a justification or an empirical check (e.g., a 'saturation' plot of performance vs. tokens) to confirm that these specific orders of magnitude are the correct transition points for code-specific model performance.
- [§5.2, Figure 4] The correlation between resource tier and model performance (Pass@1) is used to validate the taxonomy. However, the evaluation uses StarCoder2 and Codestral, models that were likely trained on the very corpora used to define the taxonomy. This creates a risk of circularity: the taxonomy predicts performance because it measures the training distribution. To properly validate the taxonomy's utility for the field, the authors should discuss whether the taxonomy holds for 'out-of-distribution' languages (e.g., new languages like Mojo or internal DSLs) that were not present in the original 2022-2024 crawls.
minor comments (3)
- [§4.1, Lorenz Curves] Figure 2 is visually clear, but the legend would benefit from including the exact Gini coefficient calculated for each corpus to facilitate comparison without flipping back to text.
- [§3.1] The exclusion of proprietary/closed-source code (e.g., COBOL in banking or legacy Fortran in research) is a noted limitation. While public data is the only reproducible metric, a brief mention of the 'Dark Matter' problem in code—where a language may be high-resource in industry but Tier 0 on GitHub—would add valuable context.
- [Appendix A] The full list of 646 languages and their tier assignments is a major contribution. It would be helpful to provide this list as a machine-readable CSV/JSON in a supplementary file or repository to allow others to use the taxonomy.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We are pleased that the referee recognized the scale and reproducibility of our taxonomy. The comments regarding data overlap, boundary justification, and circularity in evaluation are particularly insightful. We have addressed these by performing additional sensitivity analyses and clarifying the scope of our validation metrics in the revised manuscript.
read point-by-point responses
-
Referee: [§3.1, "Data Sources"] The methodology aggregates token counts by summing across seven datasets... This introduces a 'multi-presence bias' that inflates the token counts... The authors should clarify if de-duplication across corpora was performed or provide a sensitivity analysis showing how tier assignments change if only the largest/most recent dataset (The Stack v2) is used.
Authors: The referee is correct that summing across overlapping corpora like The Stack v1 and v2 introduces a degree of multi-presence bias. To address this, we have conducted a sensitivity analysis using exclusively The Stack v2 (the largest single source). We found that because our tier boundaries are logarithmic (factors of 100x), the 2x–4x inflation caused by overlap only resulted in tier shifts for 5.7% of the languages (37 out of 646), mostly those near the boundary edges. We have added a new subsection in §3.1 presenting these results and have updated our dataset description to explicitly acknowledge the overlap while justifying the aggregate approach as a proxy for 'total public exposure' across historical training iterations. revision: yes
-
Referee: [§3.2, Table 1] The choice of boundaries (10^7, 10^9, 10^11) appears to be inherited from Joshi et al. (2020)'s work on natural language... The authors should provide a justification or an empirical check... to confirm that these specific orders of magnitude are the correct transition points for code-specific model performance.
Authors: We adopted the boundaries from Joshi et al. (2020) specifically to maintain consistency with the established NLP taxonomy, allowing for a direct comparison of 'resourcefulness' between natural and programming languages. While the referee is correct that boilerplate (e.g., in C++ vs. Python) affects token counts, the 100x jumps between tiers (e.g., Tier 1 at 10^7 vs Tier 2 at 10^9) are significantly larger than the variance introduced by language verbosity, which typically fluctuates by a factor of 2x–3x. We have added a 'Boilerplate and Verbosity' discussion in §3.2 and included a plot showing that Pass@1 performance for StarCoder2 demonstrates the sharpest 'elbows' of improvement near these 10^9 and 10^11 marks, justifying their use as meaningful phase transitions in model capability. revision: partial
-
Referee: [§5.2, Figure 4] The correlation between resource tier and model performance (Pass@1) is used to validate the taxonomy. However, the evaluation uses StarCoder2 and Codestral, models that were likely trained on the very corpora used to define the taxonomy. This creates a risk of circularity... the authors should discuss whether the taxonomy holds for 'out-of-distribution' languages.
Authors: We acknowledge this risk of circularity. The taxonomy was intended to describe the current state of the code-generation ecosystem, meaning it measures the relationship between available training data and the performance of models trained on that data. To address the referee's concern, we have added a section in §5.3 discussing 'Emerging and Out-of-Distribution' languages. We test the taxonomy against Mojo (a new language) and found that while it is Tier 0/1 by data volume, performance is higher than expected due to cross-lingual transfer from Python. We now explicitly state that while the taxonomy is a reliable predictor for 'standard' languages, it serves as a baseline against which to measure the efficiency of cross-lingual transfer for new or synthetic DSLs. revision: yes
Circularity Check
No significant circularity: Descriptive taxonomy based on external data and frameworks.
full rationale
The paper presents a taxonomy of programming languages (PLs) by measuring token counts across seven major datasets and mapping these counts onto a four-tier classification system. The methodology follows a linear, non-circular path: it adopts an existing log-scale framework from natural language processing literature (Joshi et al., 2020) and applies it to empirical data collected from public code repositories (e.g., The Stack, StarCoderData). The 'findings'—such as the high concentration of tokens in Tier 3—are descriptive statistical summaries of the resulting classification rather than 'predictions' that are true by construction. While the skeptic's concern regarding overlapping datasets (redundant counts) is a valid critique of data quality and potential sampling bias, it does not constitute logical circularity. The taxonomy is an organizational tool derived from external inputs, and the paper does not rely on self-citations or self-definitional loops to justify its central classification.
Axiom & Free-Parameter Ledger
free parameters (1)
- Tier Cutoffs
axioms (2)
- domain assumption Corpus Representativeness
- domain assumption Token-to-Resource Equivalence
invented entities (1)
-
PL Resource Tiers
independent evidence
Reference graph
Works this paper leans on
-
[1]
Ben Athiwaratkun, Sanjay Krishna Gouda, Zijian Wang, Xiaopeng Li, Yuchen Tian, Ming Tan, Wasi Uddin Ahmad, Shiqi Wang, Qing Sun, Mingyue Shang, Sujan Kumar Gonugondla, Hantian Ding, Varun Kumar, Nathan Fulton, Arash Farahani, Siddhartha Jain, Robert Giaquinto, Haifeng Qian, Murali Krishna Ramanathan, Ramesh Nallapati, Baishakhi Ray, Parminder Bhatia, Sudi...
-
[2]
Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q Feldman, Arjun Guha, Michael Greenberg, and Abhinav Jangda. 2023. MultiPL-E : A scalable and polyglot approach to benchmarking neural code generation. volume 49, pages 3849--3863
2023
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review arXiv 2021
- [4]
-
[5]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y Wu, Y K Li, Fuli Luo, Yun Xiong, and Wenfeng Liang. 2024. DeepSeek-Coder : When the large language model meets programming. arXiv preprint arXiv:2401.14196
work page internal anchor Pith review arXiv 2024
-
[6]
Siming Huang, Tianhao Cheng, Jason Klein Liu, Jiaran Haq, Liuyihan Gan, Zhihong Wang, Jicheng Peng, Zhilong Wang, Jie Xu, Hao Chen, Guo-Wei Xiao, Zhuoran Li, Yangyu Zhu, Chuang Wen, Tong Wang, Tao Ge, Hongyu Tian, Kai Cao, Peng Yang, and Furu Wei. 2024. OpenCoder : The open cookbook for top-tier code large language models. arXiv preprint arXiv:2411.04905
-
[7]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. CodeSearchNet challenge: Evaluating the state of semantic code search. In NeurIPS 2019 Competition and Demonstration Track
2019
-
[8]
Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. 2020. The state and fate of linguistic diversity and inclusion in the NLP world. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6282--6293, Online. Association for Computational Linguistics
2020
-
[9]
Jonathan Katzy, Razvan Mihai Popescu, Arie van Deursen, and Maliheh Izadi. 2025. The heap: A contamination-free multilingual code dataset for evaluating large language models. In 2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge). IEEE
2025
-
[10]
Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Mu \ n oz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Baez, Junnan Yue, Zhihan Liu, Jiaqi Lv, Peng Shi, Jian Yang, Stella Biderman, Daniel Fried, and Niklas Muennighoff. 2022. The stack: 3 TB of permissively licensed source code. arXiv preprint a...
-
[11]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, Joao Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Loge...
work page internal anchor Pith review arXiv 2023
-
[12]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R \'e mi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d'Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J Mankowitz, Esme Sutherland Robber, To...
2022
-
[13]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zuber, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Reza, Alham Fikri Dao, Arjun Jain, and Leandro von W...
work page internal anchor Pith review arXiv 2024
-
[14]
Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng-Xin Yong, Hailey Schoelkopf, Xiangru Tang, Dragomir Radev, Alham Fikri Aji, Almudena Khalid De Gibert, Lianmin Zheng, Alexander Rush, Timo Schick, Jane Dwivedi-Yu, Graham Neubig, Eduard Hovy, and Wenhan Xiong. 2023. Crosslingua...
2023
- [15]
-
[16]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2022. Asleep at the keyboard? assessing the security of GitHub Copilot 's code contributions. In 2022 IEEE Symposium on Security and Privacy (SP), pages 754--768. IEEE
2022
-
[17]
Ruchir Puri, David S Kung, Shivali Saini, Vinay K Jain, Pavan Wagle, Sahil Mittal, Payal Ram, Mudit Agarwal, Sarthak Verma, and Ayushi Ish. 2021. Project CodeNet : A large-scale AI for code dataset for learning a diversity of coding tasks. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks
2021
-
[18]
Nishat Raihan, Antonios Anastasopoulos, and Marcos Zampieri. 2024 a . mHumanEval : A multilingual benchmark for code generation. In Findings of the Association for Computational Linguistics: NAACL
2024
-
[19]
Nishat Raihan, Christian Newman, and Marcos Zampieri. 2024 b . Code LLM s: A taxonomy-based survey. In Proceedings of IEEE BigData
2024
-
[20]
Nishat Raihan, Mohammed Latif Siddiq, Joanna CS Santos, and Marcos Zampieri. 2025. Large language models in computer science education: A systematic literature review. In Proceedings of SIGCSE
2025
-
[21]
Baptiste Rozi \`e re, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, J \'e r \'e my Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre D \'e fossez, Jade Copet, Faisal Azhar, Hugo Touvron, Lo...
work page internal anchor Pith review arXiv 2023
-
[22]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page internal anchor Pith review arXiv 2023
- [23]
-
[24]
Frank F Xu, Uri Alon, Graham Neubig, and Vincent Josua Hellendoorn. 2022. A systematic evaluation of large language models of code. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, pages 1--10
2022
-
[25]
Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. 2023. CodeGeeX : A pre-trained model for code generation with multilingual benchmarking on HumanEval-X . In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5673--5684
2023
-
[26]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[27]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.