Recognition: 3 theorem links
· Lean TheoremUsing predefined vector systems to speed up neural network multimillion class classification
Pith reviewed 2026-05-13 22:47 UTC · model grok-4.3
The pith
Predefined vector systems let neural networks classify millions of classes in constant time by matching latent space to cluster centers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
If the NN latent space geometry is known and possesses specific properties, label prediction complexity can be reduced from O(n) to O(1) by associating it with closest cluster center search in a vector system used as target for latent space configuration; this is achieved simply by finding indexes of several largest and lowest values in the embedding vector.
What carries the argument
Predefined vector system as target for latent space configuration (LSC), where label prediction reduces to O(1) closest cluster center search via indices of max and min values in the embedding vector.
If this is right
- Label prediction runs in constant time independent of the number of classes.
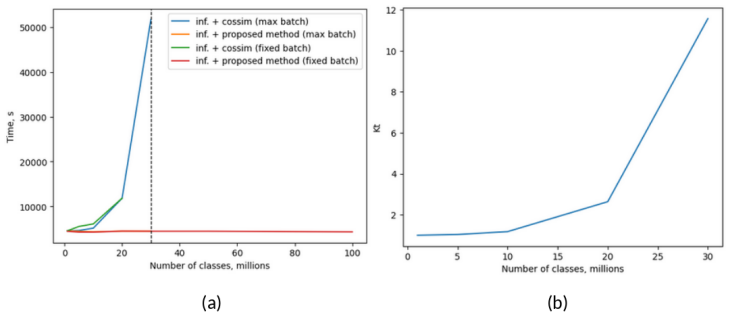
- Overall inference accelerates by up to 11.6 times on tested datasets.
- Training accuracy remains unchanged from conventional methods.
- The same embedding can indicate whether an input likely belongs to an unseen class.
Where Pith is reading between the lines
- The method could extend to streaming settings where new classes appear over time without retraining the entire output layer.
- It may allow hybrid systems that combine the fast vector lookup with occasional full-model verification for high-stakes decisions.
- If the vector system can be updated online, the approach might support lifelong learning without the usual output-layer growth cost.
Load-bearing premise
The neural network's latent space geometry is known in advance and has the specific structure needed to map label prediction to a constant-time search over the predefined vector system's cluster centers.
What would settle it
Run the method on a dataset with several million classes, measure end-to-end inference time against standard softmax or prototype cosine similarity, and check whether accuracy stays identical while total speedup reaches the claimed factor.
Figures

read the original abstract
Label prediction in neural networks (NNs) has O(n) complexity proportional to the number of classes. This holds true for classification using fully connected layers and cosine similarity with some set of class prototypes. In this paper we show that if NN latent space (LS) geometry is known and possesses specific properties, label prediction complexity can be significantly reduced. This is achieved by associating label prediction with the O(1) complexity closest cluster center search in a vector system used as target for latent space configuration (LSC). The proposed method only requires finding indexes of several largest and lowest values in the embedding vector making it extremely computationally efficient. We show that the proposed method does not change NN training accuracy computational results. We also measure the time required by different computational stages of NN inference and label prediction on multiple datasets. The experiments show that the proposed method allows to achieve up to 11.6 times overall acceleration over conventional methods. Furthermore, the proposed method has unique properties which allow to predict the existence of new classes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by configuring a neural network's latent space to match a predefined vector system with specific geometric properties, label prediction for multimillion-class problems can be reduced from O(n) to O(1) complexity via simple max/min index lookups on the embedding vector. It reports that this yields up to 11.6× overall inference acceleration over standard fully-connected or prototype-based methods while leaving training accuracy unchanged, and that the approach enables prediction of new classes.
Significance. If the central claims are substantiated, the work would offer a practical route to constant-time classification at extreme scale, with direct relevance to large-vocabulary image, text, or recommendation systems; the new-class prediction property would additionally be of interest for open-set and continual-learning settings.
major comments (2)
- [Abstract] Abstract and method description: the claim that training accuracy remains unchanged rests on an unshown construction for the vector system and an unproven guarantee that any NN latent space can be forced into the required geometry at multimillion-class scale without representational loss; no derivation, error bounds, or training procedure is supplied.
- [Experiments] Experiments section: the reported 11.6× speedup and accuracy invariance are presented as measured results, yet no details are given on how the vector system is generated or enforced, no ablation on embedding dimension versus class count, and no statistical error analysis or baseline implementation details that would allow reproduction or verification of the O(1) lookup.
minor comments (2)
- Notation for the vector system and latent-space configuration (LSC) should be introduced with explicit definitions and an illustrative low-dimensional example.
- The manuscript would benefit from a clear statement of the precise assumptions on latent-space geometry that are required for the O(1) index-lookup property to hold.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that the current manuscript would benefit from expanded technical details on the vector system construction and experimental reproducibility. We will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the claim that training accuracy remains unchanged rests on an unshown construction for the vector system and an unproven guarantee that any NN latent space can be forced into the required geometry at multimillion-class scale without representational loss; no derivation, error bounds, or training procedure is supplied.
Authors: We will add an explicit subsection detailing the construction of the predefined vector system (including its geometric properties such as orthogonal cluster centers and value-index encoding), a derivation showing how the latent space is forced into this geometry via a modified loss term, error bounds on representational capacity, and the full training procedure. This will substantiate that accuracy is preserved at multimillion-class scale. revision: yes
-
Referee: [Experiments] Experiments section: the reported 11.6× speedup and accuracy invariance are presented as measured results, yet no details are given on how the vector system is generated or enforced, no ablation on embedding dimension versus class count, and no statistical error analysis or baseline implementation details that would allow reproduction or verification of the O(1) lookup.
Authors: We will expand the experiments section with: (i) the exact algorithm and parameters for generating and enforcing the vector system, (ii) ablations on embedding dimension versus class count (up to multimillion scale), (iii) statistical error bars (mean and std over 5 runs), and (iv) full baseline implementation details (framework, hardware, and O(1) lookup code). This will enable full reproduction and verification. revision: yes
Circularity Check
No circularity detected; derivation relies on external vector-system configuration without self-referential reduction
full rationale
The paper's central claim is that configuring NN latent space to a predefined vector system reduces label prediction to O(1) index extraction of largest/lowest values, yielding up to 11.6x speedup with unchanged accuracy and new-class prediction capability. No equations, fitting procedures, or self-citations are described that would make the speedup, accuracy invariance, or new-class property equivalent to the inputs by construction. The method is presented as an empirical configuration choice whose geometry is assumed realizable, with results measured on external datasets; the derivation chain does not reduce any prediction to a fitted parameter renamed as output or to a self-citation load-bearing premise. This is the normal case of a self-contained proposal whose validity rests on external verification rather than internal redefinition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective, embed_strictMono_of_one_lt, LogicNat recovery theorem echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
if NN latent space geometry is known and possesses specific properties, label prediction complexity can be significantly reduced... by associating label prediction with the O(1) complexity closest cluster center search in a vector system used as target for latent space configuration (LSC)... finding indexes of several largest and lowest values in the embedding vector
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel, Jcost uniqueness refines?
refinesRelation between the paper passage and the cited Recognition theorem.
Theorem 1... arg max cossim(v,w) = f(w) where f places 1 at m largest coordinates and -1 at k smallest
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking, SphereAdmitsCircleLinking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
vector systems... V^{2 2}_n ... nvects = n(n-1)(n-2)(n-3)/4 ... ndim ~ n_classes^{1/4}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cosface: Large margin cosine loss for deep face recognition,
H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu, “Cosface: Large margin cosine loss for deep face recognition,” 2018. [Online]. Available: https://arxiv.org/abs/1801.09414
-
[2]
A discriminative feature learning approach for deep face recognition,
Y. Wen, K. Zhang, Z. Li, and Y. Qiao, “A discriminative feature learning approach for deep face recognition,” inECCV 2016, 2016, pp. 499–515. 11
work page 2016
-
[3]
N. Gabdullin, “Using predefined vector systems as latent space configuration for neural network supervised training on data with arbitrarily large number of classes,” 2025. [Online]. Available: https://arxiv.org/abs/2510.04090
-
[4]
I. V. Netay, “Series of quasi-uniform scatterings with fast search, root systems and neural network classifications,” 2025. [Online]. Available: https://arxiv.org/abs/2512.04865
-
[5]
Latent space configuration for improved generalization in supervised autoencoder neural networks,
N. Gabdullin, “Latent space configuration for improved generalization in supervised autoencoder neural networks,” 2025. [Online]. Available: https://arxiv.org/abs/2402.08441
-
[6]
N. Gabdullin, “Exploring possible vector systems for faster training of neural networks with preconfigured latent spaces,” 2025. [Online]. Available: https://arxiv.org/abs/2512.07509
-
[7]
Prototypical networks for few-shot learning,
J. Snell, K. Swersky, and R. S. Zemel, “Prototypical networks for few-shot learning,”
-
[8]
Available: https://arxiv.org/abs/1703.05175
[Online]. Available: https://arxiv.org/abs/1703.05175
-
[9]
torch.topk — pytorch 2.0 documentation,
PyTorch, “torch.topk — pytorch 2.0 documentation,” https://docs.pytorch.org/docs/ stable/generated/torch.topk.html, accessed: 2026-03-31
work page 2026
-
[10]
Practicalandoptimal lsh for angular distance,
A.Andoni, P.Indyk, T.Laarhoven, I.Razenshteyn, andL.Schmidt, “Practicalandoptimal lsh for angular distance,” 2015. [Online]. Available: https://arxiv.org/abs/1509.02897
-
[11]
Billion-scale similarity search with GPUs
J. Johnson, M. Douze, and H. Jégou, “Billion-scale similarity search with gpus,” 2017. [Online]. Available: https://arxiv.org/abs/1702.08734
work page Pith review arXiv 2017
-
[12]
Y. A. Malkov and D. A. Yashunin, “Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs,” 2018. [Online]. Available: https://arxiv.org/abs/1603.09320
-
[13]
Product quantization for nearest neighbor search,
H. Jégou, M. Douze, and C. Schmid, “Product quantization for nearest neighbor search,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 1, pp. 117–128, 2011
work page 2011
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021. [Online]. Available: https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Measuring the Intrinsic Dimension of Objective Landscapes
C. Li, H. Farkhoor, R. Liu, and J. Yosinski, “Measuring the intrinsic dimension of objective landscapes,” 2018. [Online]. Available: https://arxiv.org/abs/1804.08838 12
work page Pith review arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.