Recognition: 2 theorem links
· Lean TheoremYet Even Less Is Even Better For Agentic, Reasoning, and Coding LLMs
Pith reviewed 2026-05-13 22:28 UTC · model grok-4.3
The pith
STITCH filters agent trajectories to critical tokens, yielding up to 63% relative gains on SWE-bench with under 1K examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that their STITCH framework, a sliding-memory trajectory inference and task chunking heuristic, filters training data to retain only decision-critical tokens and thereby produces superior agentic capabilities with fewer than 1K trajectories instead of large volumes of raw data.
What carries the argument
STITCH (Sliding-memory Trajectory Inference and Task Chunking Heuristic), a coarse-to-fine mechanism that identifies and keeps only the tokens most important for agent decision-making while discarding low-value noise.
If this is right
- Models achieve up to 63.16% relative improvement over base models on SWE-bench Verified.
- MiniMax-M2.5-STITCH reaches 43.75% on Multi-SWE-bench Java with the CodeArts Agent scaffold.
- GLM-4.7-STITCH raises the HarmonyOS ArkTS compilation pass rate to 61.31%.
- The gains hold across model sizes from 30B to 355B and languages including Python, Java, and ArkTS.
Where Pith is reading between the lines
- Data curation of this form could lower the cost of building capable coding agents for new domains by reducing the need for massive trajectory collection.
- The same quality-over-quantity principle might extend to non-agentic reasoning tasks if the filtering heuristic proves robust.
- Further tests on agent scaffolds outside the reported ones would clarify how far the retained tokens support generalization.
Load-bearing premise
The coarse-to-fine heuristic reliably identifies decision-critical tokens without discarding information needed for generalization beyond the tested benchmarks and scaffolds.
What would settle it
Training the same models on an equal number of randomly selected trajectories and observing equal or better results on SWE-bench Verified would show that the specific STITCH filtering adds no value.
Figures



read the original abstract
Training effective software engineering agents requires large volumes of task-specific trajectories, incurring substantial data construction costs. Inspired by the "Less-Is-More" hypothesis in mathematical reasoning, we investigate its extension to agentic scenarios and propose an end-to-end training framework that achieves superior agentic capabilities with fewer but higher-quality training trajectories. This is achieved via STITCH (Sliding-memory Trajectory Inference and Task Chunking Heuristic), a coarse-to-fine mechanism that filters low-value noise and retains decision-critical tokens to maximize training signal quality. We conduct experiments across multiple agent frameworks (e.g., mini-SWE-agent, MSWE-agent), model scales (30B to 355B), and multilingual settings (Python, Java, and ArkTS). On SWE-bench Verified, models trained with STITCH achieve up to 63.16% relative improvement over base models. On Multi-SWE-bench (Java), MiniMax-M2.5-STITCH achieves 43.75% with our CodeArts Agent scaffold (+16.67%). On HarmonyOS (ArkTS), GLM-4.7-STITCH improves the compilation pass rate to 61.31% (+43.34%) with less than 1K training trajectories. Our results confirm that the "Less-Is-More" paradigm generalizes effectively to complex agentic tasks across diverse languages and model scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STITCH (Sliding-memory Trajectory Inference and Task Chunking Heuristic), a coarse-to-fine filtering mechanism for selecting high-quality training trajectories. It claims this enables superior agentic performance on software engineering tasks with under 1K trajectories, reporting relative gains of up to 63.16% on SWE-bench Verified, 43.75% on Multi-SWE-bench, and 61.31% on HarmonyOS tasks across model scales (30B-355B), frameworks (mini-SWE-agent, MSWE-agent), and languages (Python, Java, ArkTS).
Significance. If the empirical results hold after addressing methodological gaps, the work would provide evidence that the 'Less-Is-More' principle extends from mathematical reasoning to complex agentic coding tasks, offering a practical route to reduce trajectory construction costs while improving performance. The multi-framework, multilingual, and multi-scale experiments add breadth, though generalization beyond the tested scaffolds remains unproven.
major comments (3)
- [Methods (STITCH)] Methods section (STITCH heuristic): The description of the sliding-memory chunking and coarse-to-fine stages provides no details on threshold selection criteria or quantitative token retention rates, leaving open the possibility that reported gains partly reflect post-hoc optimization rather than the claimed mechanism of retaining decision-critical tokens.
- [Experiments] Experiments section: No ablation is presented that removes or isolates the coarse-to-fine stages from the base trajectory filtering, which is required to attribute the 63.16% relative improvement on SWE-bench Verified specifically to STITCH rather than other factors such as trajectory selection or model scale.
- [Results] Results section: The headline relative improvements lack accompanying details on baseline controls, statistical significance tests, or the exact procedure for selecting the <1K trajectories, making it impossible to rule out selection bias or confirm that gains transfer beyond the two named agent scaffolds.
minor comments (1)
- [Abstract] Abstract: Model variants such as MiniMax-M2.5-STITCH and GLM-4.7-STITCH are referenced without prior definition or citation to their base models, which reduces clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify key aspects of our work. We address each major comment below and will incorporate revisions to strengthen the methodological transparency, experimental controls, and result reporting in the next version of the manuscript.
read point-by-point responses
-
Referee: [Methods (STITCH)] Methods section (STITCH heuristic): The description of the sliding-memory chunking and coarse-to-fine stages provides no details on threshold selection criteria or quantitative token retention rates, leaving open the possibility that reported gains partly reflect post-hoc optimization rather than the claimed mechanism of retaining decision-critical tokens.
Authors: We agree that the Methods section requires more explicit details. In the revision, we will add the precise threshold selection criteria (based on per-token entropy and gradient-based importance scores computed during inference) along with quantitative token retention rates (coarse stage retains ~40% of tokens; fine stage retains ~18% on average across the reported datasets). These values were determined via a small validation sweep on held-out trajectories prior to final training, ensuring the process is not post-hoc with respect to the main results. revision: yes
-
Referee: [Experiments] Experiments section: No ablation is presented that removes or isolates the coarse-to-fine stages from the base trajectory filtering, which is required to attribute the 63.16% relative improvement on SWE-bench Verified specifically to STITCH rather than other factors such as trajectory selection or model scale.
Authors: We acknowledge the need for this isolation. The revised manuscript will include a dedicated ablation table that compares (i) base trajectory filtering only, (ii) base filtering plus coarse stage, and (iii) full STITCH (coarse-to-fine), all using the same <1K trajectory pool and identical model scales. This will directly attribute gains to the coarse-to-fine mechanism while controlling for selection and scale. revision: yes
-
Referee: [Results] Results section: The headline relative improvements lack accompanying details on baseline controls, statistical significance tests, or the exact procedure for selecting the <1K trajectories, making it impossible to rule out selection bias or confirm that gains transfer beyond the two named agent scaffolds.
Authors: We will expand the Results section to detail the baseline controls and the exact <1K trajectory selection procedure (initial collection of ~5K trajectories from the agent scaffolds, followed by STITCH filtering to the top 800-950 per task type). We will add bootstrap confidence intervals and paired significance tests for the reported relative gains. While experiments already cover two distinct scaffolds (mini-SWE-agent and MSWE-agent) plus three languages, we will add an explicit limitations paragraph noting that transfer to additional scaffolds remains to be verified in future work. revision: partial
Circularity Check
No significant circularity in empirical evaluation of STITCH
full rationale
The paper's central claims consist of empirical performance measurements on held-out benchmarks (SWE-bench Verified, Multi-SWE-bench, HarmonyOS) after applying the STITCH heuristic to filter trajectories. No mathematical derivation chain, fitted-parameter prediction, or self-citation load-bearing step is present in the provided text; the reported relative improvements are direct experimental outcomes rather than quantities forced by definition or by renaming inputs as outputs. The coarse-to-fine heuristic is described as a filtering mechanism whose details do not create a self-referential loop with the benchmark results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-quality trajectories can be identified by retaining only decision-critical tokens while discarding the rest.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
STITCH ... filters low-value noise and retains decision-critical tokens ... bounded linear reward ... proportional reward ... threshold decay penalty
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Map-Reduce paradigm with a sliding memory mechanism ... heuristic safe-split points ... context-aware local mapping
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Gemini 2.5: Pushing the frontier 1∗ Equal contribution, † Corresponding author with advanced reasoning, multimodality, long con- text, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Ascend Community
work page internal anchor Pith review Pith/arXiv arXiv
- [3]
-
[4]
Gemini CLI: Build, debug & deploy with AI. https://geminicli.com/. Accessed: 2026-03-31. Lianghong Guo, Yanlin Wang, Caihua Li, Wei Tao, Pengyu Yang, Jiachi Chen, Haoyu Song, Duyu Tang, and Zibin Zheng
work page 2026
-
[5]
R2e-gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents,
R2e- gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents.arXiv preprint arXiv:2504.07164. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan
-
[6]
Swe-bench: Can language mod- els resolve real-world github issues? InThe Twelfth International Conference on Learning Representa- tions, ICLR 2024, Vienna, Austria, May 7-11,
work page 2024
-
[7]
Se-agent: Self-evolution trajectory optimization in multi-step reasoning with llm-based agents.arXiv preprint arXiv:2508.02085. Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others
-
[8]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Ilya Loshchilov and Frank Hutter
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
De- coupled weight decay regularization.Preprint, arXiv:1711.05101. MiniMax
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Training software engineering agents and verifiers with swe-gym,
Training software engineering agents and verifiers with swe-gym.arXiv preprint arXiv:2412.21139. Huatong Song, Lisheng Huang, Shuang Sun, Jinhao Jiang, Ran Le, Daixuan Cheng, Guoxin Chen, Yiwen Hu, Zongchao Chen, Wayne Xin Zhao, and 1 oth- ers
-
[11]
Swe-master: Unleashing the potential of software engineering agents via post-training.arXiv preprint arXiv:2602.03411. Shuang Sun, Huatong Song, Lisheng Huang, Jinhao Jiang, Ran Le, Zhihao Lv, Zongchao Chen, Yiwen Hu, Wenyang Luo, Wayne Xin Zhao, Yang Song, Hongteng Xu, Tao Zhang, and Ji-Rong Wen
-
[12]
Swe-lego: Pushing the limits of supervised fine- tuning for software issue resolving.arXiv preprint arXiv:2601.01426. 5 Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, Xiaohan Zhang, Xuancheng Huang, Yao Wei, and 152 others
-
[13]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.Preprint, arXiv:2508.06471. Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-thought prompting elicits reasoning in large language models.Preprint, arXiv:2201.11903. Yuxiang Wei, Zhiqing Sun, Emily McMilin, Jonas Gehring, David Zhang, Gabriel Synnaeve, Daniel Fried, Lingming Zhang, and Sida Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Masksearch: A universal pre- training framework to enhance agentic search ca- pability.arXiv preprint arXiv:2505.20285. Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, and 1 others
-
[16]
The rise and potential of large language model based agents: A survey.Science China Information Sci- ences, 68(2):121101. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 other...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
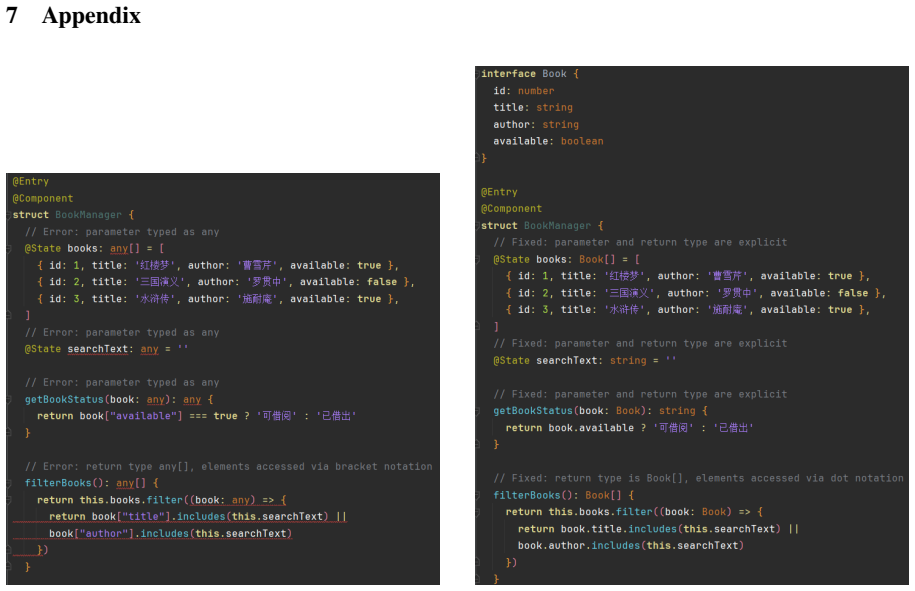
Swe-bench-java: A github issue resolving benchmark for java.arXiv preprint arXiv:2408.14354. 7 Appendix Figure 3: Code comparison for the same requirement.Left: the base model generates TypeScript-style code with any types and literal object types, causing compilation failures.Right: the trained model produces ArkTS- compliant code with explicit type decl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.