Recognition: 1 theorem link
· Lean TheoremJAMMEval: A Refined Collection of Japanese Benchmarks for Reliable VLM Evaluation
Pith reviewed 2026-05-13 22:48 UTC · model grok-4.3
The pith
Two rounds of human annotation on seven Japanese VQA datasets produce benchmarks whose scores better track actual VLM capabilities and show lower variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
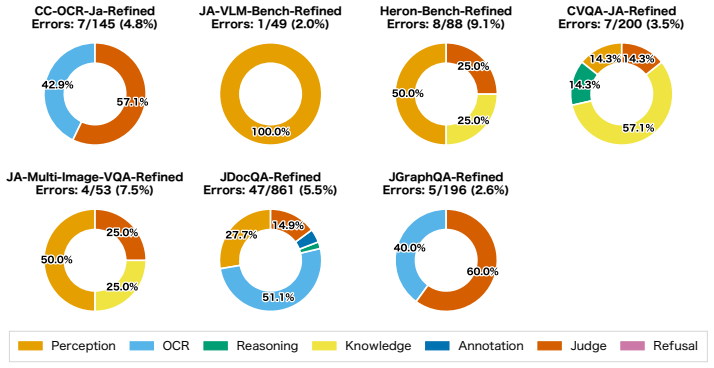
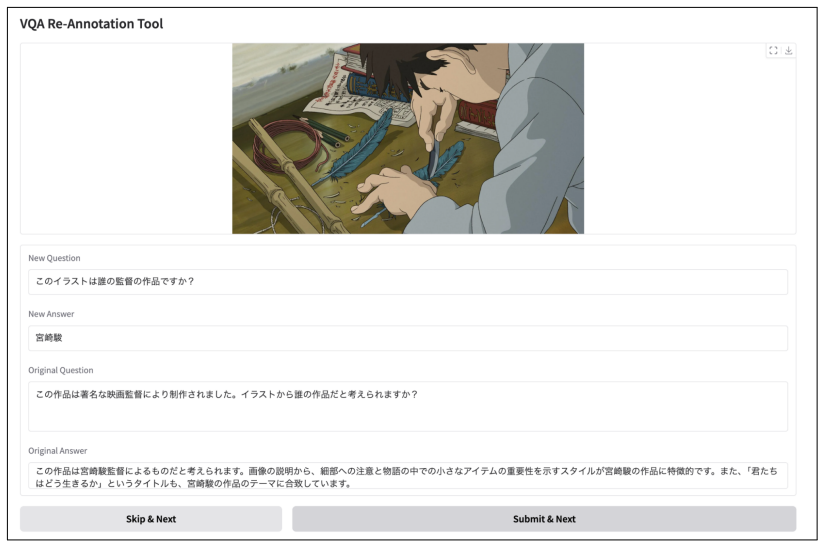
JAMMEval is a refined collection of Japanese benchmarks created by systematically improving seven existing VQA datasets through two rounds of human annotation that remove ambiguous questions, incorrect answers, and instances solvable without visual grounding. When open-weight and proprietary VLMs are evaluated on the resulting collection, the scores better reflect true model capability, display lower run-to-run variance, and distinguish models of different capability levels more effectively than the original datasets.
What carries the argument
JAMMEval, the collection obtained by applying two successive rounds of human annotation to correct flaws across seven Japanese VQA datasets.
If this is right
- Evaluation scores align more closely with actual VLM performance on Japanese visual question answering.
- Run-to-run variance decreases, yielding more stable and repeatable model comparisons.
- Models of differing capability levels separate more clearly in the resulting rankings.
- Analysis of recent VLMs on Japanese VQA becomes more trustworthy for guiding future development.
- The released dataset and code enable the community to adopt higher-quality Japanese evaluation standards.
Where Pith is reading between the lines
- The same annotation protocol could be applied to benchmarks in other languages to raise evaluation standards globally.
- JAMMEval could become a fixed reference set for tracking incremental gains in Japanese-specific VLM capabilities over successive model releases.
- Benchmark creators in any language may need to treat visual-grounding verification as a required step rather than an optional cleanup.
- Automated assistants trained on the annotation patterns could scale similar refinements to much larger collections with less manual effort.
Load-bearing premise
Two rounds of human annotation suffice to catch and fix every ambiguity, incorrect answer, and non-visual question without creating new systematic biases or missing subtle problems.
What would settle it
Repeated runs on the refined benchmarks that still show high score variance for the same model or fail to produce statistically significant differences between models previously known to differ in capability.
Figures









read the original abstract
Reliable evaluation is essential for the development of vision-language models (VLMs). However, Japanese VQA benchmarks have undergone far less iterative refinement than their English counterparts. As a result, many existing benchmarks contain issues such as ambiguous questions, incorrect answers, and instances that can be solved without visual grounding, undermining evaluation reliability and leading to misleading conclusions in model comparisons. To address these limitations, we introduce JAMMEval, a refined collection of Japanese benchmarks for reliable VLM evaluation. It is constructed by systematically refining seven existing Japanese benchmark datasets through two rounds of human annotation, improving both data quality and evaluation reliability. In our experiments, we evaluate open-weight and proprietary VLMs on JAMMEval and analyze the capabilities of recent models on Japanese VQA. We further demonstrate the effectiveness of our refinement by showing that the resulting benchmarks yield evaluation scores that better reflect model capability, exhibit lower run-to-run variance, and improve the ability to distinguish between models of different capability levels. We release our dataset and code to advance reliable evaluation of VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JAMMEval, a refined collection of seven existing Japanese VQA benchmarks constructed via two rounds of human annotation to remove ambiguous questions, incorrect answers, and non-visual instances. Experiments evaluate open-weight and proprietary VLMs on the refined set and claim that the resulting benchmarks produce scores that better reflect model capability, exhibit lower run-to-run variance, and improve separation between models of differing capability levels. The dataset and code are released.
Significance. If the annotation refinements are shown to be robust and free of new systematic biases, JAMMEval would fill a clear gap in reliable non-English VLM evaluation and could serve as a standard reference for Japanese-language vision-language tasks. The release of artifacts strengthens reproducibility.
major comments (2)
- [§3] §3 (Benchmark Construction): The two-round human annotation process is presented as exhaustive for removing ambiguities, incorrect answers, and non-visual questions, yet no inter-annotator agreement metrics, counts or typology of edits performed, or change statistics are reported. Without these, it is impossible to verify that the observed reductions in variance and gains in model separability are not artifacts of the particular annotators or post-hoc selection.
- [§4.3] §4.3 (Evaluation Analysis): The claims that JAMMEval yields lower run-to-run variance and sharper model distinctions rest on empirical comparisons, but the manuscript provides no statistical tests, confidence intervals, or control experiments (e.g., re-annotation by an independent third party) to establish that the improvements are significant and not driven by the specific annotation choices.
minor comments (1)
- [Abstract / §1] The abstract and §1 would benefit from a brief quantitative summary (e.g., number of instances removed or modified per dataset) to give readers an immediate sense of the scale of refinement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating the revisions we will make to strengthen the transparency and statistical rigor of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The two-round human annotation process is presented as exhaustive for removing ambiguities, incorrect answers, and non-visual questions, yet no inter-annotator agreement metrics, counts or typology of edits performed, or change statistics are reported. Without these, it is impossible to verify that the observed reductions in variance and gains in model separability are not artifacts of the particular annotators or post-hoc selection.
Authors: We agree that inter-annotator agreement metrics and detailed edit statistics are necessary to substantiate the annotation process. In the revised manuscript we will report Cohen’s kappa (and percentage agreement) for both annotation rounds, together with a typology and counts of issues addressed (ambiguous questions, incorrect answers, non-visual instances). These additions will allow readers to assess whether the observed improvements are robust rather than annotator-specific. revision: yes
-
Referee: [§4.3] §4.3 (Evaluation Analysis): The claims that JAMMEval yields lower run-to-run variance and sharper model distinctions rest on empirical comparisons, but the manuscript provides no statistical tests, confidence intervals, or control experiments (e.g., re-annotation by an independent third party) to establish that the improvements are significant and not driven by the specific annotation choices.
Authors: We acknowledge the value of formal statistical support. We will add bootstrap confidence intervals for the variance reductions and apply appropriate tests (Levene’s test for variance homogeneity and permutation tests for separability metrics) to quantify significance. A full independent third-party re-annotation is not feasible at this stage; we will explicitly note this limitation and list it as future work. revision: partial
- Independent third-party re-annotation of the full benchmark collection as a control experiment
Circularity Check
No circularity: empirical dataset refinement with independent evaluation
full rationale
The paper performs two rounds of human annotation on existing Japanese VQA benchmarks to remove ambiguous, incorrect, or non-visual items, then directly measures resulting improvements in score stability, variance, and model separability via standard VLM evaluations. No equations, fitted parameters, or derivations are present. The central claim rests on observable experimental outcomes rather than any self-definition, self-citation chain, or renamed input. This is standard empirical dataset work with released artifacts and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators can reliably identify ambiguous questions, incorrect answers, and instances solvable without visual grounding
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct JAMMEval by refining seven existing Japanese VQA benchmarks through two rounds of manual review and re-annotation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild
URLhttps://arxiv.org/abs/1906.02569. Takuya Akiba, Makoto Shing, Yujin Tang, Qi Sun, and David Ha. Evolutionary optimization of model merging recipes.Nature Machine Intelligence, 2025. URL https://doi.org/10.1038/ s42256-024-00975-8. Anthropic. Demystifying evals for ai agents. https://www.anthropic.com/engineering/ demystifying-evals-for-ai-agents, 2026....
work page Pith review arXiv 1906
-
[2]
Accessed: 2026-02-19. Kaixin Li, Meng Ziyang, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: GUI grounding for professional high-resolution computer use. InWorkshop on Reasoning and Planning for Large Language Models, 2025. URL https: //openreview.net/forum?id=XaKNDIAHas. 10 Haotian Liu, Chunyuan Li, Qing...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
URLhttps://openreview.net/forum?id=tN61DTr4Ed. Zhibo Yang, Jun Tang, Zhaohai Li, Pengfei Wang, Jianqiang Wan, Humen Zhong, Xuejing Liu, Mingkun Yang, Peng Wang, Shuai Bai, LianWen Jin, and Junyang Lin. CC-OCR: A comprehensive and challenging ocr benchmark for evaluating large multimodal models in literacy. arXiv preprint arXiv:2412.02210, 2024. URLhttps:/...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.