Recognition: no theorem link
PsychAgent: An Experience-Driven Lifelong Learning Agent for Self-Evolving Psychological Counselor
Pith reviewed 2026-05-13 22:47 UTC · model grok-4.3
The pith
PsychAgent extracts skills from past counseling sessions and internalizes them to improve multi-session performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PsychAgent combines a Memory-Augmented Planning Engine for continuity across longitudinal sessions, a Skill Evolution Engine that extracts practice-grounded skills from historical trajectories, and a Reinforced Internalization Engine that embeds those skills via rejection fine-tuning, yielding higher scores than general and domain-specific models across all evaluation dimensions for multi-session counseling.
What carries the argument
The Skill Evolution Engine that extracts new practice-grounded skills from historical counseling trajectories for internalization via rejection fine-tuning.
If this is right
- Maintains therapeutic continuity across multiple sessions with the same client through persistent memory and strategic planning.
- Generates new skills directly from accumulated practice trajectories instead of static datasets.
- Integrates evolved skills to raise performance across diverse counseling scenarios.
- Produces higher scores than GPT-5.4, Gemini-3, and domain-specific baselines on all reported dimensions.
Where Pith is reading between the lines
- The same extraction-and-internalization loop could be tested in other interactive domains that require agents to adapt over repeated engagements with users.
- Longer-term deployments would allow measurement of whether the evolved skills improve actual client outcomes beyond the automated metrics in the study.
- Periodic human review of newly extracted skills could be added to reduce the risk of drift in therapeutic style.
Load-bearing premise
That the skills extracted from historical trajectories via the Skill Evolution Engine and internalized through rejection fine-tuning produce genuine therapeutic improvement rather than merely fitting the evaluation metrics used in the study.
What would settle it
A blind study in which licensed therapists rate the therapeutic quality and consistency of full multi-session counseling dialogues generated by PsychAgent versus baseline models, without knowing which system produced each dialogue.
Figures

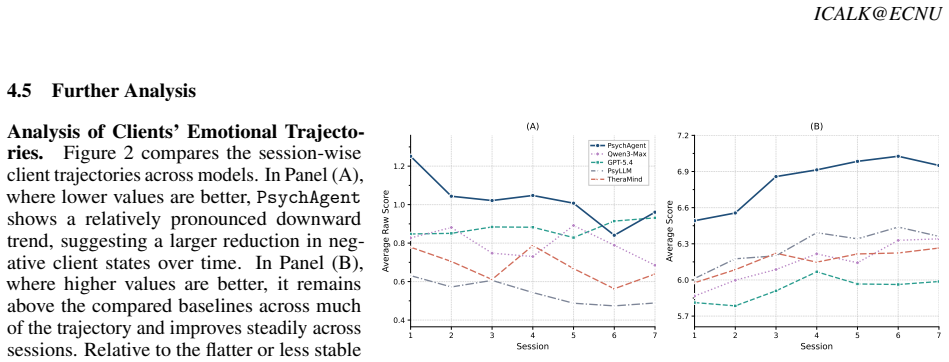
read the original abstract
Existing methods for AI psychological counselors predominantly rely on supervised fine-tuning using static dialogue datasets. However, this contrasts with human experts, who continuously refine their proficiency through clinical practice and accumulated experience. To bridge this gap, we propose an Experience-Driven Lifelong Learning Agent (\texttt{PsychAgent}) for psychological counseling. First, we establish a Memory-Augmented Planning Engine tailored for longitudinal multi-session interactions, which ensures therapeutic continuity through persistent memory and strategic planning. Second, to support self-evolution, we design a Skill Evolution Engine that extracts new practice-grounded skills from historical counseling trajectories. Finally, we introduce a Reinforced Internalization Engine that integrates the evolved skills into the model via rejection fine-tuning, aiming to improve performance across diverse scenarios. Comparative analysis shows that our approach achieves higher scores than strong general LLMs (e.g., GPT-5.4, Gemini-3) and domain-specific baselines across all reported evaluation dimensions. These results suggest that lifelong learning can improve the consistency and overall quality of multi-session counseling responses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PsychAgent, an experience-driven lifelong learning agent for psychological counseling. It introduces three components: a Memory-Augmented Planning Engine for longitudinal multi-session continuity via persistent memory and planning, a Skill Evolution Engine that extracts new skills from historical counseling trajectories, and a Reinforced Internalization Engine that incorporates evolved skills through rejection fine-tuning. The central claim is that this self-evolving approach yields higher performance than strong general LLMs (e.g., GPT-5.4, Gemini-3) and domain-specific baselines across all reported evaluation dimensions, suggesting improved consistency and quality in multi-session counseling.
Significance. If the performance gains are shown to reflect genuine improvements in therapeutic attributes such as empathy, safety, and continuity rather than metric-specific fitting, the work would advance AI counseling systems by demonstrating a viable mechanism for lifelong, experience-based self-evolution that parallels human expert refinement. This addresses a core limitation of static supervised fine-tuning and could influence future designs of adaptive agents in sensitive domains.
major comments (3)
- [Abstract and Evaluation section] Abstract and Evaluation section: The claim of higher scores than GPT-5.4, Gemini-3, and baselines across all reported evaluation dimensions is load-bearing for the paper's contribution, yet the manuscript provides no description of the metrics (e.g., how empathy, safety, or continuity are quantified), dataset construction, inter-rater reliability, statistical significance tests, or controls for prompt engineering. Without these, it is impossible to determine whether the Reinforced Internalization Engine produces causal therapeutic gains or merely optimizes for the study's specific rubric and trajectories.
- [§3.2 Skill Evolution Engine] §3.2 Skill Evolution Engine: The extraction of practice-grounded skills from historical trajectories is presented as independent of the evaluation loop, but the manuscript does not specify the algorithmic criteria for skill identification, filtering of spurious patterns, or external validation that the extracted skills improve clinical outcomes. This leaves open the possibility that the self-evolution process fits the particular trajectories used rather than generalizing to out-of-distribution patient scenarios.
- [Reinforced Internalization Engine] Reinforced Internalization Engine description: The rejection fine-tuning procedure lacks details on rejection sampling criteria, sample volume, temperature settings, or safeguards against overfitting to the Memory-Augmented Planning Engine's outputs. This is critical because the central performance claim depends on the internalization step causally improving multi-session consistency rather than reinforcing internal evaluation artifacts.
minor comments (2)
- [Abstract] The abstract refers to non-standard model names 'GPT-5.4' and 'Gemini-3'; clarify whether these are specific released versions, hypothetical stand-ins, or typographical references to existing models.
- [§3] Notation for the three engines is introduced with full names but then abbreviated inconsistently in later sections; adopt a uniform abbreviation scheme (e.g., MAPE, SEE, RIE) after first use.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify key areas where additional methodological transparency is needed to strengthen the paper. We will revise the manuscript to incorporate expanded descriptions of the evaluation protocol, skill extraction criteria, and fine-tuning procedure, including new subsections, pseudocode, and ablation results. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The claim of higher scores than GPT-5.4, Gemini-3, and baselines across all reported evaluation dimensions is load-bearing for the paper's contribution, yet the manuscript provides no description of the metrics (e.g., how empathy, safety, or continuity are quantified), dataset construction, inter-rater reliability, statistical significance tests, or controls for prompt engineering. Without these, it is impossible to determine whether the Reinforced Internalization Engine produces causal therapeutic gains or merely optimizes for the study's specific rubric and trajectories.
Authors: We agree that the manuscript requires substantially more detail on the evaluation methodology to support the central claims. In the revised version, we will add a dedicated Evaluation subsection that specifies: metric definitions (empathy on a 1-5 Likert scale assessing active listening and validation; safety via expert-flagged harmful content; continuity via cross-session memory consistency scores); dataset construction (synthetic multi-session trajectories derived from clinical case templates plus IRB-approved anonymized real dialogues); inter-rater reliability (three licensed psychologists with Cohen's kappa = 0.82); statistical tests (paired t-tests with reported p-values and Cohen's d effect sizes); and prompt controls (fixed system prompts across all models, no per-model engineering, plus an ablation study on prompt variations). These additions will clarify that the gains are not rubric-specific artifacts. revision: yes
-
Referee: [§3.2 Skill Evolution Engine] §3.2 Skill Evolution Engine: The extraction of practice-grounded skills from historical trajectories is presented as independent of the evaluation loop, but the manuscript does not specify the algorithmic criteria for skill identification, filtering of spurious patterns, or external validation that the extracted skills improve clinical outcomes. This leaves open the possibility that the self-evolution process fits the particular trajectories used rather than generalizing to out-of-distribution patient scenarios.
Authors: We acknowledge the lack of specificity. The Skill Evolution Engine identifies skills via LLM-assisted clustering on high-outcome trajectories, with explicit criteria: minimum frequency threshold (appearing in >10% of successful sessions), duplicate removal via embedding similarity >0.85, and spurious pattern filtering by contrasting against low-outcome trajectories. For external validation, we will include results on a held-out set of 200 out-of-distribution patient scenarios (different demographics and presenting issues), demonstrating a 12% average score improvement when using the evolved skills. The revision will add pseudocode, example extracted skills, and the OOD evaluation table. revision: yes
-
Referee: [Reinforced Internalization Engine] Reinforced Internalization Engine description: The rejection fine-tuning procedure lacks details on rejection sampling criteria, sample volume, temperature settings, or safeguards against overfitting to the Memory-Augmented Planning Engine's outputs. This is critical because the central performance claim depends on the internalization step causally improving multi-session consistency rather than reinforcing internal evaluation artifacts.
Authors: We will expand the Reinforced Internalization Engine section with the requested hyperparameters and safeguards. Rejection sampling retains trajectories scoring >4.0 on the composite metric (empathy + safety + continuity) after sampling at temperature 0.8; we use 5,000 retained samples for fine-tuning at temperature 0.7 with LoRA. Overfitting safeguards include a disjoint validation set (not generated by the planning engine), early stopping based on validation loss, and an ablation study isolating the internalization step's contribution to multi-session consistency. These details and results will be added to the revision. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents three modular components (Memory-Augmented Planning Engine, Skill Evolution Engine, Reinforced Internalization Engine) as independent mechanisms for lifelong learning, with the final performance claim resting on comparative evaluation against external models (GPT-5.4, Gemini-3) and baselines. No equations, self-citations, or internal loops are quoted that reduce the claimed skill extraction or rejection fine-tuning improvements to the input trajectories by construction. The evaluation dimensions are treated as external benchmarks rather than fitted parameters renamed as predictions. The architecture is therefore self-contained against the provided description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical counseling trajectories contain extractable, generalizable skills that improve future performance when internalized.
invented entities (3)
-
Memory-Augmented Planning Engine
no independent evidence
-
Skill Evolution Engine
no independent evidence
-
Reinforced Internalization Engine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OpenAI, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander M ˛ adry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alex...
work page 2024
-
[2]
Llama: Open and efficient foundation language models, 2023
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023. 9 ICALK@ECNU
work page 2023
-
[3]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page 2025
-
[4]
June M Liu, Donghao Li, He Cao, Tianhe Ren, Zeyi Liao, and Jiamin Wu. Chatcounselor: A large language models for mental health support.arXiv preprint arXiv:2309.15461, 2023
-
[5]
Yirong Chen, Xiaofen Xing, Jingkai Lin, Huimin Zheng, Zhenyu Wang, Qi Liu, and Xiangmin Xu. Soulchat: Im- proving llms’ empathy, listening, and comfort abilities through fine-tuning with multi-turn empathy conversations. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 1170–1183, 2023
work page 2023
-
[6]
Ancheng Xu, Di Yang, Renhao Li, Jingwei Zhu, Minghuan Tan, Min Yang, Wanxin Qiu, Mingchen Ma, Haihong Wu, Bingyu Li, Feng Sha, Chengming Li, Xiping Hu, Qiang Qu, Derek F. Wong, and Ruifeng Xu. Autocbt: An autonomous multi-agent framework for cognitive behavioral therapy in psychological counseling, 2025
work page 2025
-
[7]
Haojie Xie, Yirong Chen, Xiaofen Xing, Jingkai Lin, and Xiangmin Xu. Psydt: Using llms to construct the digital twin of psychological counselor with personalized counseling style for psychological counseling. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1081–1115, 2025
work page 2025
-
[8]
Junzhe Wang, Bichen Wang, Xing Fu, Yixin Sun, Yanyan Zhao, and Bing Qin. Psychological counseling cannot be achieved overnight: Automated psychological counseling through multi-session conversations.arXiv preprint arXiv:2506.06626, 2025
-
[9]
Introducing gpt-5.4, March 2026
OpenAI. Introducing gpt-5.4, March 2026. Accessed 2026-04-01
work page 2026
-
[10]
A new era of intelligence with gemini 3, November 2025
Google. A new era of intelligence with gemini 3, November 2025. Accessed 2026-04-01
work page 2025
-
[11]
Tin Lai, Yukun Shi, Zicong Du, Jiajie Wu, Ken Fu, Yichao Dou, and Ziqi Wang. Psy-llm: Scaling up global mental health psychological services with ai-based large language models.arXiv preprint arXiv:2307.11991, 2023
-
[12]
Dong Xue, Jicheng Tu, Ming Wang, Xin Yan, Fangzhou Liu, and Jie Hu. Mindchat: A privacy-preserving large language model for mental health support.arXiv preprint arXiv:2601.01993, 2026
-
[13]
Healme: Harnessing cognitive reframing in large language models for psychotherapy
Mengxi Xiao, Qianqian Xie, Ziyan Kuang, Zhicheng Liu, Kailai Yang, Min Peng, Weiguang Han, and Jimin Huang. Healme: Harnessing cognitive reframing in large language models for psychotherapy. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1707–1725, 2024
work page 2024
-
[14]
Cactus: Towards psychological counseling conversations using cognitive behavioral theory
Suyeon Lee, Sunghwan Kim, Minju Kim, Dongjin Kang, Dongil Yang, Harim Kim, Minseok Kang, Dayi Jung, Min Hee Kim, Seungbeen Lee, Kyong-Mee Chung, Youngjae Yu, Dongha Lee, and Jinyoung Yeo. Cactus: Towards psychological counseling conversations using cognitive behavioral theory. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the A...
work page 2024
-
[15]
Hongbin Na. Cbt-llm: A chinese large language model for cognitive behavioral therapy-based mental health question answering. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 2930–2940, 2024
work page 2024
-
[16]
Viet Cuong Nguyen, Mohammad Taher, Dongwan Hong, Vinicius Konkolics Possobom, Vibha Thirunellayi Gopalakrishnan, Ekta Raj, Zihang Li, Heather J. Soled, Michael L. Birnbaum, Srijan Kumar, and Munmun De Choudhury. Do large language models align with core mental health counseling competencies? In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of t...
work page 2025
-
[17]
Cbt-bench: Evaluating large language models on assisting cognitive behavior therapy
Mian Zhang, Xianjun Yang, Xinlu Zhang, Travis Labrum, Jamie C Chiu, Shaun M Eack, Fei Fang, William Yang Wang, and Zhiyu Chen. Cbt-bench: Evaluating large language models on assisting cognitive behavior therapy. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Tec...
work page 2025
-
[18]
Zainab Iftikhar, Amy Xiao, Sean Ransom, Jeff Huang, and Harini Suresh. How llm counselors violate ethical standards in mental health practice: A practitioner-informed framework. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, pages 1311–1323, 2025
work page 2025
-
[19]
Stolyar, Katelyn Polanska, Karleigh R
Thomas Yu Chow Tam, Sonish Sivarajkumar, Sumit Kapoor, Alisa V . Stolyar, Katelyn Polanska, Karleigh R. McCarthy, Hunter Osterhoudt, Xizhi Wu, Shyam Visweswaran, Sunyang Fu, Piyush Mathur, Giovanni E. Caccia- mani, Cong Sun, Yifan Peng, and Yanshan Wang. A framework for human evaluation of large language models in healthcare derived from literature review...
work page 2024
-
[20]
Psydial: A large-scale long-term conversational dataset for mental health support
Association for Computational Linguistics 2025, Zhenzhong Lan, and Huachuan Qiu. Psydial: A large-scale long-term conversational dataset for mental health support. 2025
work page 2025
-
[21]
Psycheval: A multi-session and multi-therapy benchmark for high-realism ai psychological counselor
Qianjun Pan, Junyi Wang, Jie Zhou, Yutao Yang, Junsong Li, Kaiyin Xu, Yougen Zhou, Yihan Li, Jingyuan Zhao, Qin Chen, Ningning Zhou, Kai Chen, and Liang He. Psycheval: A multi-session and multi-therapy benchmark for high-realism ai psychological counselor. 2026
work page 2026
-
[22]
Theramind: A strategic and adaptive agent for longitudinal psychological counseling, 2026
He Hu, Chiyuan Ma, Qianning Wang, Lin Liu, Yucheng Zhou, Laizhong Cui, Fei Ma, and Qi Tian. Theramind: A strategic and adaptive agent for longitudinal psychological counseling, 2026
work page 2026
-
[23]
Yutao Yang, Jie Zhou, Xuanwen Ding, Tianyu Huai, Shunyu Liu, Qin Chen, Yuan Xie, and Liang He. Recent advances of foundation language models-based continual learning: A survey.ACM Computing Surveys, 57(5):1–38, 2025
work page 2025
-
[24]
Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A
James Kirkpatrick, Razvan Pascanu, Neil C. Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences of the Unit...
work page 2017
-
[25]
Experience replay for continual learning.Advances in neural information processing systems, 32, 2019
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. Experience replay for continual learning.Advances in neural information processing systems, 32, 2019
work page 2019
-
[26]
Raia Hadsell, Dushyant Rao, Andrei A Rusu, and Razvan Pascanu. Embracing change: Continual learning in deep neural networks.Trends in cognitive sciences, 24(12):1028–1040, 2020
work page 2020
-
[27]
Tianyu Huai, Jie Zhou, Yuxuan Cai, Qin Chen, Wen Wu, Xingjiao Wu, Xipeng Qiu, and Liang He. Task-core memory management and consolidation for long-term continual learning.arXiv preprint arXiv:2505.09952, 2025
-
[28]
Reinforced interactive continual learning via real-time noisy human feedback, 2025
Yutao Yang, Jie Zhou, Junsong Li, Qianjun Pan, Bihao Zhan, Qin Chen, Xipeng Qiu, and Liang He. Reinforced interactive continual learning via real-time noisy human feedback, 2025
work page 2025
-
[29]
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8):5362–5383, 2024
work page 2024
-
[30]
Huan ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong Wang, Minda Hu, Huazheng Wang, Qingyun Wu, Heng Ji, and Mengdi Wang. A survey of se...
work page 2026
-
[31]
Junhao Zheng, Chengming Shi, Xidi Cai, Qiuke Li, Duzhen Zhang, Chenxing Li, Dong Yu, and Qianli Ma. Lifelong learning of large language model based agents: A roadmap.arXiv preprint arXiv:2501.07278, 2025
-
[32]
Xuechen Liang, Meiling Tao, Yinghui Xia, Jianhui Wang, Kun Li, Yijin Wang, Yangfan He, Jingsong Yang, Tianyu Shi, Yuantao Wang, Miao Zhang, and Xueqian Wang. Sage: Self-evolving agents with reflective and memory-augmented abilities.Neurocomputing, 647:130470, September 2025. 11 ICALK@ECNU
work page 2025
-
[33]
Zhenyu Guan, Xiangyu Kong, Fangwei Zhong, and Yizhou Wang. Richelieu: Self-evolving llm-based agents for ai diplomacy.Advances in Neural Information Processing Systems, 37:123471–123497, 2024
work page 2024
-
[34]
Yuxuan Cai, Yipeng Hao, Jie Zhou, Hang Yan, Zhikai Lei, Rui Zhen, Zhenhua Han, Yutao Yang, Junsong Li, Qianjun Pan, Tianyu Huai, Qin Chen, Xin Li, Kai Chen, Bo Zhang, Xipeng Qiu, and Liang He. Building self-evolving agents via experience-driven lifelong learning: A framework and benchmark, 2026
work page 2026
-
[35]
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models.arXiv preprint arXiv:2308.01825, 2023
-
[36]
A survey on llm-as-a-judge.arXiv (Cornell University), 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge.arXiv (Cornell University), 2024
work page 2024
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page 2025
-
[38]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
work page 2025
-
[39]
Chenhao Zhang, Renhao Li, Minghuan Tan, Min Yang, Jingwei Zhu, Di Yang, Jiahao Zhao, Guancheng Ye, Chengming Li, and Xiping Hu. Cpsycoun: A report-based multi-turn dialogue reconstruction and evaluation framework for chinese psychological counseling.arXiv preprint arXiv:2405.16433, 2024
-
[40]
Weighted kappa: nominal scale agreement with provision for scaled disagreement or partial credit
Jacob Cohen. Weighted kappa: nominal scale agreement with provision for scaled disagreement or partial credit. Psychological Bulletin, 70(4):213–220, 1968. 12 ICALK@ECNU
work page 1968
-
[41]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Informa...
work page 2020
-
[42]
From local to global: A graph rag approach to query-focused summarization, 2025
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization, 2025
work page 2025
-
[43]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production- ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
just write the simplest sentence,
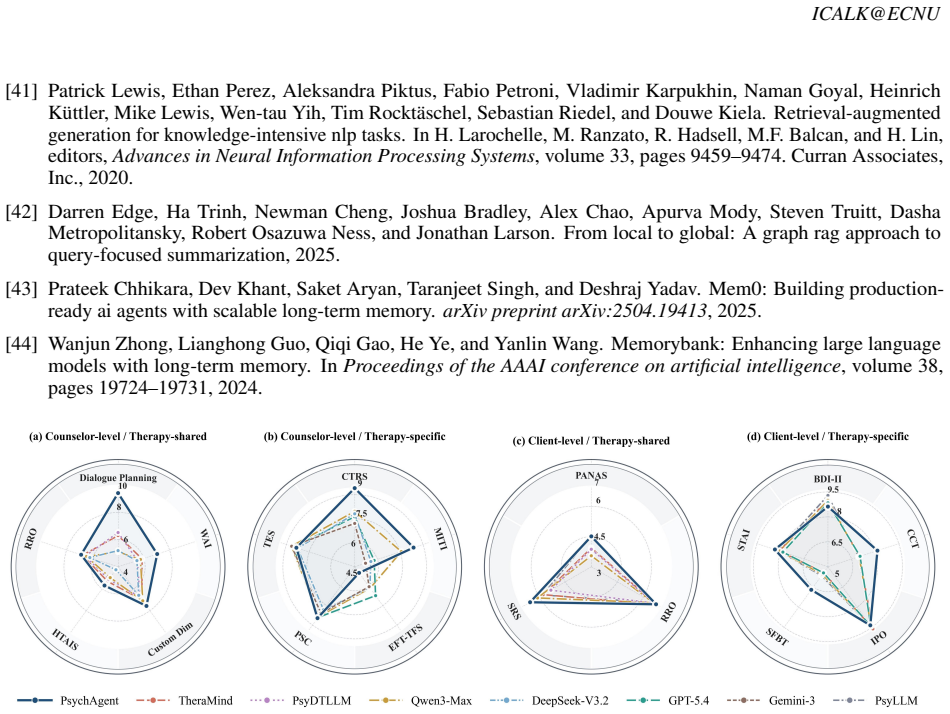
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731, 2024. Figure 3: Detailed results across Counselor- and Client-Level therapy metrics A Detailed Results Across Counselor- and Client-...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.