Recognition: 2 theorem links
· Lean TheoremTemporal Logic Control of Nonlinear Stochastic Systems with Online Performance Optimization
Pith reviewed 2026-05-13 21:44 UTC · model grok-4.3
The pith
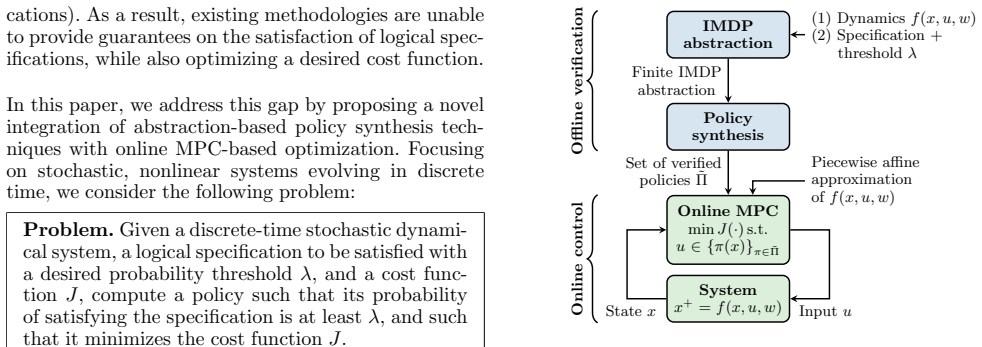
Nonlinear stochastic systems gain control policies from an IMDP abstraction that form a verified set, letting online optimizers like MPC tune performance without losing the minimum satisfaction probability for temporal logic specs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We construct an interval MDP abstraction of a nonlinear stochastic system that returns a set of policies, each satisfying a temporal logic specification with a minimum probability. Any policy chosen from this set at runtime preserves the same minimum probability, so an arbitrary online optimizer (for example MPC) can be applied to minimize a separate cost function while the original probabilistic guarantee is retained.
What carries the argument
The verified policy set produced by the IMDP abstraction, which any online selector can draw from without dropping below the collective satisfaction probability.
If this is right
- Any online algorithm such as MPC can now optimize a cost independent of the temporal logic specification.
- The closed-loop performance improves relative to single-policy abstractions while the satisfaction probability bound is preserved.
- The method applies directly to safety-critical autonomous systems modeled as nonlinear stochastic dynamics.
- The abstraction step and the online optimization step can be performed separately.
Where Pith is reading between the lines
- The same set-construction idea could be tested on hybrid or continuous-time stochastic models to see whether the policy collection remains tractable.
- Reducing the size of the policy set while keeping the probability guarantee might further improve online computation speed.
- Comparing the method against robust-MDP or chance-constraint approaches on the same benchmarks would quantify how much extra flexibility the set provides.
Load-bearing premise
The online optimizer is restricted to choosing only policies inside the abstracted set and never selects actions outside it.
What would settle it
Run the closed-loop system with the online MPC and record whether the observed frequency of specification satisfaction falls below the minimum probability promised for the entire policy set.
Figures





read the original abstract
The deployment of autonomous systems in safety-critical environments requires control policies that guarantee satisfaction of complex control specifications. These systems are commonly modeled as nonlinear discrete-time stochastic systems. A~popular approach to computing a policy that provably satisfies a complex control specification is to construct a finite-state abstraction, often represented as a Markov decision process (MDP) with intervals of transition probabilities, i.e., an interval MDP (IMDP). However, existing abstraction techniques compute a \emph{single policy}, thus leaving no room for online cost or performance optimization, e.g., of energy consumption. To overcome this limitation, we propose a novel IMDP abstraction technique that yields a \emph{set of policies}, each of which satisfies the control specification with a certain minimum probability. We can thus use any online control algorithm to search through this set of verified policies while retaining the guaranteed satisfaction probability of the entire policy set. In particular, we employ model predictive control (MPC) to minimize a desired cost function that is independent of the control specification considered in the abstraction. Our experiments demonstrate that our approach yields better control performance than state-of-the-art single-policy abstraction techniques, with a small degradation of the guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel IMDP abstraction for nonlinear discrete-time stochastic systems that computes a set of policies, each satisfying a temporal logic specification with a minimum probability. This enables online algorithms such as MPC to optimize a performance cost (independent of the specification) by searching within the verified set while preserving the overall satisfaction probability guarantee. Experiments report improved performance over single-policy abstraction baselines with only small degradation in guarantees.
Significance. If the central claim on probability preservation holds, the result is significant: it extends existing IMDP techniques to support online performance optimization without sacrificing formal probabilistic guarantees, addressing a practical limitation of single-policy abstractions in safety-critical stochastic control.
major comments (2)
- [Abstract and online optimization description] The central claim (abstract) that any online control algorithm can search the verified policy set while retaining the minimum satisfaction probability requires an explicit mechanism to restrict the optimizer (e.g., MPC) to policies inside the set. Standard MPC optimizes a cost over the original nonlinear dynamics without such constraints; the manuscript provides no indication that the policy set is encoded as enforceable constraints (linear, convex, or otherwise) that survive insertion into the online quadratic program.
- [IMDP abstraction and policy set construction] The abstraction must provably ensure that every policy selectable by the online optimizer induces a trajectory whose satisfaction probability is at least the certified minimum for the entire set. No details are given on how the set construction (IMDP abstraction) encodes admissible policies in a form that prevents selection of out-of-set controls, which is load-bearing for the guarantee.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of how the verified policy set interfaces with online optimizers, and we address each point below with clarifications and commitments to revision.
read point-by-point responses
-
Referee: [Abstract and online optimization description] The central claim (abstract) that any online control algorithm can search the verified policy set while retaining the minimum satisfaction probability requires an explicit mechanism to restrict the optimizer (e.g., MPC) to policies inside the set. Standard MPC optimizes a cost over the original nonlinear dynamics without such constraints; the manuscript provides no indication that the policy set is encoded as enforceable constraints (linear, convex, or otherwise) that survive insertion into the online quadratic program.
Authors: We agree that an explicit restriction mechanism is required for the guarantee to hold in practice. The manuscript constructs the policy set as all control mappings that respect the IMDP interval transitions and achieve the minimum satisfaction probability under the abstraction. For online use, this set is intended to be enforced by restricting the MPC decision variables to the admissible controls at each abstract state (e.g., via state-dependent lookup or parametric constraints derived from the abstraction). While the current text describes the set construction and states that MPC searches within it, we acknowledge insufficient detail on the encoding. We will revise by adding a dedicated subsection on constraint formulation, including how the admissible set is represented to remain compatible with the quadratic program (linear or convex where possible) and a brief example of insertion into the MPC optimization. revision: yes
-
Referee: [IMDP abstraction and policy set construction] The abstraction must provably ensure that every policy selectable by the online optimizer induces a trajectory whose satisfaction probability is at least the certified minimum for the entire set. No details are given on how the set construction (IMDP abstraction) encodes admissible policies in a form that prevents selection of out-of-set controls, which is load-bearing for the guarantee.
Authors: The IMDP abstraction computes the set by solving a reachability problem over interval probabilities, yielding all policies whose induced abstract trajectories satisfy the specification with probability at least the certified minimum; any concrete policy chosen from this set therefore inherits the guarantee by construction of the abstraction. The admissible controls are encoded as the control choices at each abstract state that keep the interval transition probabilities within the satisfying bounds. To prevent out-of-set selections, the online optimizer is restricted to these controls. We will revise the manuscript to include an expanded description of the set representation (e.g., as a state-to-control-set mapping) together with a short argument showing that every selectable policy remains inside the certified set, thereby closing the gap noted by the referee. revision: yes
Circularity Check
Minor self-citation present but derivation remains independent and non-circular
full rationale
The paper extends standard IMDP abstraction methods to produce a set of policies rather than a single policy, allowing online optimization (e.g., MPC) while preserving a minimum satisfaction probability. No derivation step reduces by construction to its own inputs, fitted parameters renamed as predictions, or self-referential definitions. Existing IMDP techniques are cited as background; the novelty lies in the set-based output and its integration with online control, which is presented as a direct construction without load-bearing self-citation chains or uniqueness theorems imported from the authors' prior work. The central claim is self-contained against the abstraction procedure described and does not collapse to renaming known results or smuggling ansatzes via citation. This yields a low circularity score consistent with normal extension of prior methods.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Nonlinear discrete-time stochastic systems can be soundly abstracted to interval MDPs preserving probabilistic satisfaction of temporal logic specifications
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
novel IMDP abstraction technique that yields a set of policies, each of which satisfies the control specification with a certain minimum probability... employ model predictive control (MPC) to minimize a desired cost function
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
probabilistic alternating simulation relation (PASR) ... set-valued interface function F_set
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
M. Alshiekh, R. Bloem, R. Ehlers, B. K¨ onighofer, S. Niekum, and U. Topcu. Safe reinforcement learning via shielding. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2669–2678, 2018
work page 2018
-
[4]
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada. Control barrier function based quadratic programs for safety critical systems.IEEE Transactions on Automatic Control, 62:3861– 3876, 2017
work page 2017
-
[5]
K. J. ˚Astr¨ om.Introduction to Stochastic Control Theory. Courier Corporation, 2012
work page 2012
-
[6]
T. Badings and A Abate. Probabilistic alternating simulations for policy synthesis in uncertain stochastic dynamical systems. In2025 IEEE 64th Conference on Decision and Control (CDC), pages 3919–3924, 2025
work page 2025
-
[7]
T. Badings, W. Koops, S. Junges, and N. Jansen. Policy verification in stochastic dynamical systems using logarithmic neural certificates. InComputer Aided Verification, pages 349–375. Springer, 2025
work page 2025
-
[8]
T. Badings, L. Romao, A. Abate, D. Parker, H. A. Poonawala, M. Stoelinga, and N. Jansen. Robust control for dynamical systems with non-Gaussian noise via formal abstractions. Journal of Artificial Intelligence Research, 76:341–391, 2023
work page 2023
- [9]
- [10]
-
[11]
A. Bemporad and M. Morari. Control of systems integrating logic, dynamics, and constraints.Automatica, 35:407–427, 1999
work page 1999
-
[12]
D. P. Bertsekas and S. E. Shreve.Stochastic Optimal Control: The Discrete-Time Case. Athena Scientific, 1996
work page 1996
-
[13]
S. Carr, N. Jansen, S. Junges, and U. Topcu. Safe reinforcement learning via shielding under partial observability. InProceedings of the AAAI Conference on Artificial Intelligence, pages 14748–14756, 2023
work page 2023
-
[14]
N. Cauchi, L. Laurenti, M. Lahijanian, A. Abate, M. Kwiatkowska, and L. Cardelli. Efficiency through uncertainty: scalable formal synthesis for stochastic hybrid systems. InProceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, pages 240–251, 2019
work page 2019
-
[15]
A. Clark. Control barrier functions for stochastic systems. Automatica, 130:1–9, 2021
work page 2021
- [16]
-
[17]
W. H. Fleming and R. Rishel.Deterministic and Stochastic Optimal Control. Springer, 2012
work page 2012
-
[18]
A. Girard and G. J. Pappas. Hierarchical control system design using approximate simulation.Automatica, 45:566– 571, 2009
work page 2009
-
[19]
I. Gracia and M. Lahijanian. Beyond interval MDPs: Tight and efficient abstractions of stochastic systems. https://doi.org/10.48550/arXiv.2507.02213, 2025
- [20]
-
[21]
Gurobi Optimizer Reference Manual, 2025
Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual, 2025
work page 2025
-
[22]
S. Haesaert and S. Soudjani. Robust dynamic programming for temporal logic control of stochastic systems.IEEE Transactions on Automatic Control, 66:2496–2511, 2021
work page 2021
-
[23]
S. Haesaert, S. E. Z. Soudjani, and A. Abate. Verification of general Markov decision processes by approximate similarity relations and policy refinement.SIAM Journal on Control and Optimization, 55:2333–2367, 2017
work page 2017
-
[24]
W. P. M. H. Heemels, B. De Schutter, and A. Bemporad. Equivalence of hybrid dynamical models.Automatica, 37:1085–1091, 2001
work page 2001
- [25]
-
[26]
T. A. Henzinger, K. Mallik, P. Sadeghi, and D. ˇZikeli´ c. Supermartingale certificates for quantitative omega-regular verification and control. InComputer Aided Verification, pages 29–55. Springer, 2025
work page 2025
- [27]
-
[28]
K. C. Hsu, H. Hu, and J. F. Fisac. The safety filter: A unified view of safety-critical control in autonomous systems.Annual Review of Control, Robotics, and Autonomous Systems, 7:47– 72, 2024
work page 2024
-
[29]
G. N. Iyengar. Robust dynamic programming.Mathematics of Operations Research, 30:257–280, 2005
work page 2005
-
[30]
J. Jackson, L. Laurenti, E. Frew, and M. Lahijanian. Strategy synthesis for partially-known switched stochastic systems. In Proceedings of the 24th International Conference on Hybrid Systems: Computation and Control, pages 1–11, 2021
work page 2021
- [31]
-
[32]
Kallenberg.Foundations of Modern Probability
O. Kallenberg.Foundations of Modern Probability. Springer, third edition, 2021
work page 2021
-
[33]
M. Krstic. Inverse optimal safety filters.IEEE Transactions on Automatic Control, 69:16–31, 2024
work page 2024
-
[34]
P. R. Kumar and P. Varaiya.Stochastic Systems: Estimation, Identification, and Adaptive Control. SIAM, 2015
work page 2015
-
[35]
M. Kwiatkowska, G. Norman, and D. Parker. PRISM 4.0: Verification of probabilistic real-time systems. InComputer Aided Verification, pages 585–591. Springer, 2011
work page 2011
-
[36]
M. Lahijanian, S. B. Andersson, and C. Belta. Formal verification and synthesis for discrete-time stochastic systems.IEEE Transactions on Automatic Control, 60:2031– 2045, 2015
work page 2031
-
[37]
A. Lavaei. Abstraction-based synthesis of stochastic hybrid systems. InProceedings of the 27th ACM International Conference on Hybrid Systems: Computation and Control (HSCC), pages 1–11, 2024. 14
work page 2024
- [38]
- [39]
-
[40]
F. B. Mathiesen, S. Haesaert, and L. Laurenti. Scalable control synthesis for stochastic systems via structural IMDP abstractions. InProceedings of the 28th ACM International Conference on Hybrid Systems: Computation and Control, pages 1–12, 2025
work page 2025
-
[41]
A. Mesbah. Stochastic model predictive control: An overview and perspectives for future research.IEEE Control Systems Magazine, 36:30–44, 2016
work page 2016
-
[42]
A. W. Moore. Efficient memory-based learning for robot control. Technical report, University of Cambridge, Computer Laboratory, 1990
work page 1990
-
[43]
M. M. Morato and M. S. Felix. Data science and model predictive control: A survey of recent advances on data-driven MPC algorithms.Journal of Process Control, 144:1–17, 2024
work page 2024
- [44]
- [45]
-
[46]
A. Nilim and L. El Ghaoui. Robust control of Markov decision processes with uncertain transition matrices.Operations Research, 53:780–798, 2005
work page 2005
-
[47]
A. Pnueli. The temporal logic of programs. In18th Annual Symposium on Foundations of Computer Science (SFCS 1977), pages 46–57, 1977
work page 1977
- [48]
-
[49]
Y. Qin, M. Cao, and B. D. O. Anderson. Lyapunov criterion for stochastic systems and its applications in distributed computation.IEEE Transactions on Automatic Control, 65:546–560, 2020
work page 2020
-
[50]
J. B. Rawlings, D. Q. Mayne, and M. Diehl.Model Predictive Control: Theory, Computation, and Design. Nob Hill Publishing, second edition, 2017
work page 2017
- [51]
-
[52]
A. Riccardi, T. Badings, L. Laurenti, A. Abate, and B. De Schutter. Code for publication: Temporal Logic Control of Nonlinear Stochastic Systems with Online Performance Optimization. https://www.doi.org/10.4121/631b574d-40e8- 4951-b3ac-e304e3f34b13, 2026
-
[53]
A. Riccardi, L. Laurenti, and B. De Schutter. Partitioning techniques for non-centralized predictive control: A systematic review and novel theoretical insights.Annual Reviews in Control, 61:1–41, 2026
work page 2026
-
[54]
R. Scattolini. Architectures for distributed and hierarchical model predictive control – A review.Journal of Process Control, 19:723–731, 2009
work page 2009
-
[55]
R. Segala and N. A. Lynch. Probabilistic simulations for probabilistic processes.Nordic Journal of Computing, 2:250– 237, 1995
work page 1995
-
[56]
B. Siciliano, L. Sciavicco, L. Villani, and G. Oriolo.Robotics: Modelling, Planning and Control. Springer, 2009
work page 2009
-
[57]
E. Sontag. Nonlinear regulation: The piecewise linear approach.IEEE Transactions on Automatic Control, 26:346– 358, 1981
work page 1981
- [58]
-
[59]
Tabuada.Verification and Control of Hybrid Systems: A Symbolic Approach
P. Tabuada.Verification and Control of Hybrid Systems: A Symbolic Approach. Springer, 2009
work page 2009
-
[60]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goul˜ ao, A. Kallinteris, M. Krimmel, A. KG, R. Perez-Vicente, A. Pierr´ e, S. Schulhoff, J. J. Tai, H. Tan, and O. G. Younis. Gymnasium: A standard interface for reinforcement learning environments. https://doi.org/10.48550/arXiv.2407.17032, 2025
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.17032 2025
-
[61]
B. Van Huijgevoort, O. Sch¨ on, S. Soudjani, and S. Haesaert. SySCoRe: Synthesis via stochastic coupling relations. In Proceedings of the 26th ACM International Conference on Hybrid Systems: Computation and Control, pages 1–11, 2023
work page 2023
-
[62]
K. P. Wabersich and M. N. Zeilinger. A predictive safety filter for learning-based control of constrained nonlinear dynamical systems.Automatica, 129:1–13, 2021
work page 2021
-
[63]
E. M. Wolff, U. Topcu, and R. M. Murray. Robust control of uncertain Markov decision processes with temporal logic specifications. In2012 IEEE 51st IEEE Conference on Decision and Control (CDC), pages 3372–3379, 2012
work page 2012
-
[64]
D. ˇZikeli´ c, M. Lechner, T. A. Henzinger, and K. Chatterjee. Learning control policies for stochastic systems with reach- avoid guarantees. InProceedings of the AAAI Conference on Artificial Intelligence, pages 11926–11935, 2023. 15
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.