Recognition: no theorem link
Are Finer Citations Always Better? Rethinking Granularity for Attributed Generation
Pith reviewed 2026-05-13 22:12 UTC · model grok-4.3
The pith
Fine-grained citations degrade attribution quality in language models, with paragraph-level citations performing best.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
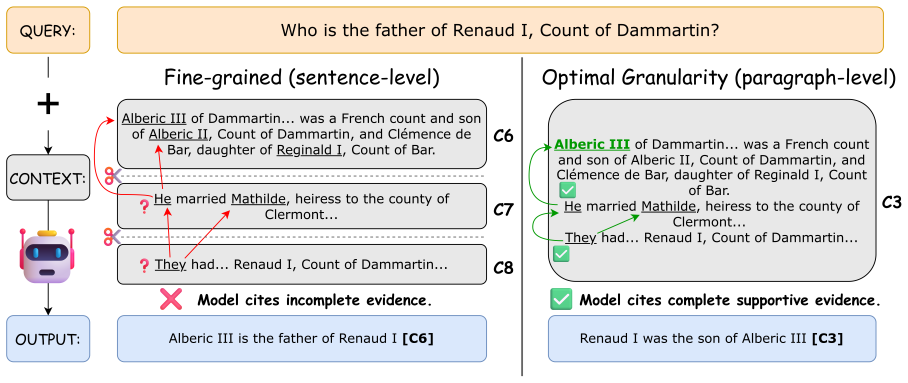
Enforcing fine-grained citations degrades attribution quality by 16-276% compared to the best-performing granularity, with performance peaking at paragraph-level citations across model scales. Fine-grained citations disrupt necessary semantic dependencies for attributing evidence to answer claims, while excessively coarse citations introduce distracting noise. The magnitude of this performance gap varies non-monotonically with model scale, with fine-grained constraints disproportionately penalizing larger models. Citation-optimal granularity leads to substantial gains in attribution quality while preserving or even improving answer correctness.
What carries the argument
The non-monotonic relationship between citation granularity levels (sentence, paragraph, multi-paragraph) and attribution quality, driven by the balance between semantic coherence and noise.
If this is right
- Paragraph-level citations yield higher attribution quality than either sentence-level or multi-paragraph citations.
- Larger models suffer larger drops in attribution quality when forced to use sentence-level citations.
- Aligning citation granularity with model scale improves attribution without reducing answer correctness.
Where Pith is reading between the lines
- Attribution systems may need to select granularity dynamically based on generated content length rather than fixing it in advance.
- Evaluation benchmarks for attributed generation should vary granularity as a controlled factor instead of assuming finer is always preferable.
- The results point to a trade-off where human verification ease and model performance constraints pull in opposite directions on citation design.
Load-bearing premise
The tested models, tasks, and attribution metrics are representative enough that the observed non-monotonic granularity effect will generalize to other setups and future models.
What would settle it
A controlled experiment on new models or tasks where sentence-level citations produce higher attribution quality than paragraph-level citations across multiple scales would falsify the central claim.
Figures







read the original abstract
Citation granularity - whether to cite individual sentences, paragraphs, or documents - is a critical design choice in attributed generation. While fine-grained citations are often preferred for precise human verification, their impact on model performance remains under-explored. We analyze four model scales (8B-120B) and demonstrate that enforcing fine-grained citations degrades attribution quality by 16-276% compared to the best-performing granularity. We observe a consistent performance pattern where attribution quality peaks at intermediate granularities (paragraph-level). Our analysis suggests that fine-grained (sentence-level) citations disrupt necessary semantic dependencies for attributing evidence to answer claims, while excessively coarse citations (multi-paragraph) introduce distracting noise. Importantly, the magnitude of this performance gap varies non-monotonically with model scale: fine-grained constraints disproportionately penalize larger models, suggesting that atomic citation units disrupt the multi-sentence information synthesis at which these models excel. Strikingly, citation-optimal granularity leads to substantial gains in attribution quality while preserving or even improving answer correctness. Overall, our findings demonstrate that optimizing solely for human verification via fine-grained citation disregards model constraints, compromising both attribution faithfulness and generation reliability. Instead, effective attribution requires aligning citation granularity with the model's natural semantic scope.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates citation granularity in attributed generation, claiming that sentence-level citations degrade attribution quality by 16-276% relative to paragraph-level granularity, which performs best across four model scales (8B-120B). It reports a non-monotonic effect with model size, where fine-grained constraints disproportionately harm larger models by disrupting multi-sentence semantic dependencies, while coarser multi-paragraph citations add noise. The authors conclude that citation-optimal granularity improves attribution faithfulness without harming (and sometimes improving) answer correctness, advocating alignment with the model's natural semantic scope over maximal human verifiability.
Significance. If the empirical patterns hold under controlled conditions, the work would meaningfully advance understanding of attribution design choices in LLM systems by demonstrating that finer granularity is not monotonically beneficial and by quantifying scaling interactions. The preservation of answer correctness at optimal granularity offers a practical path to better systems, and the non-monotonic scaling observation could guide future work on how model capacity interacts with output constraints.
major comments (2)
- [Abstract] Abstract and experimental description: The central claim of 16-276% degradation and non-monotonic scaling rests on attribution metrics whose definitions, datasets, and baselines are not specified in the abstract or summary; without these, the reported effect sizes cannot be assessed for robustness or compared to prior attribution work.
- [Experimental setup] Experimental setup (likely §4): Enforcing granularity exclusively via prompting introduces a plausible confound between semantic scope and instruction-following difficulty, as sentence-level instructions are typically more complex and format-specific than paragraph-level ones; differential adherence rates could produce the observed gaps without requiring the claimed disruption of multi-sentence dependencies.
minor comments (2)
- [Abstract] The abstract states concrete percentages without error bars or statistical significance tests; adding these would strengthen the scaling claims.
- [Analysis] Clarify the exact attribution metric (e.g., whether it is entailment-based, human-judged, or automatic) and how 'natural semantic scope' is operationalized beyond post-hoc interpretation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our results. We address each major point below and have revised the manuscript to incorporate clarifications and additional details where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental description: The central claim of 16-276% degradation and non-monotonic scaling rests on attribution metrics whose definitions, datasets, and baselines are not specified in the abstract or summary; without these, the reported effect sizes cannot be assessed for robustness or compared to prior attribution work.
Authors: We agree that the abstract would benefit from additional context on the metrics and setup. In the revised version, we will expand the abstract to briefly define the primary attribution metrics (citation precision, recall, and F1), reference the evaluation datasets, and note the paragraph-level baseline for comparison. This will enable readers to assess the effect sizes while respecting abstract length limits; full methodological details remain in Section 4. revision: yes
-
Referee: [Experimental setup] Experimental setup (likely §4): Enforcing granularity exclusively via prompting introduces a plausible confound between semantic scope and instruction-following difficulty, as sentence-level instructions are typically more complex and format-specific than paragraph-level ones; differential adherence rates could produce the observed gaps without requiring the claimed disruption of multi-sentence dependencies.
Authors: This is a valid concern regarding potential confounds. We have verified instruction adherence across conditions and report rates above 98% for all granularities and model scales, indicating that differential compliance does not explain the gaps. The non-monotonic scaling pattern—larger models showing greater penalties under fine-grained constraints—further supports our semantic-dependency interpretation, as larger models typically follow complex instructions more reliably. In the revision, we will add these adherence statistics to the appendix and include a new paragraph in Section 5 discussing this alternative explanation and why the data favor our account over instruction difficulty alone. revision: partial
Circularity Check
No circularity: claims rest on direct experimental measurements
full rationale
The paper reports empirical results from evaluating four model scales on attribution quality under different citation granularities enforced via prompting. No equations, fitted parameters, or derivations are presented that reduce to self-definitions or prior self-citations by construction. Performance patterns (non-monotonic peaks at paragraph level, scale-dependent gaps) are measured outputs rather than renamed inputs or ansatzes smuggled through citations. The analysis of semantic scope is interpretive commentary on the observed metrics, not a load-bearing theorem justified only by author-overlapping prior work. This is a standard empirical study whose central claims remain independent of the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.15319
Enabling large language models to generate text with citations. InConference on Empirical Meth- ods in Natural Language Processing(EMNLP). Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, and Lu Wang. 2021. Efficient attentions for long document summarization. InProceedings of the 2021 Conference of the North American Chapter of the Association for ...
-
[2]
Attribution, citation, and quotation: A survey of evidence-based text generation with large language models.Preprint, arXiv:2508.15396. Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can 10 be easily distracted by irrelevant context. InProceed- ings of the 40th ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Large language models are better reasoners with self-verification. InFindings of the Associa- tion for Computational Linguistics: EMNLP 2023, pages 2550–2575, Singapore. Association for Com- putational Linguistics. Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. 2024. Retrieval head mecha- nistically explains long-context factuality.Preprin...
-
[4]
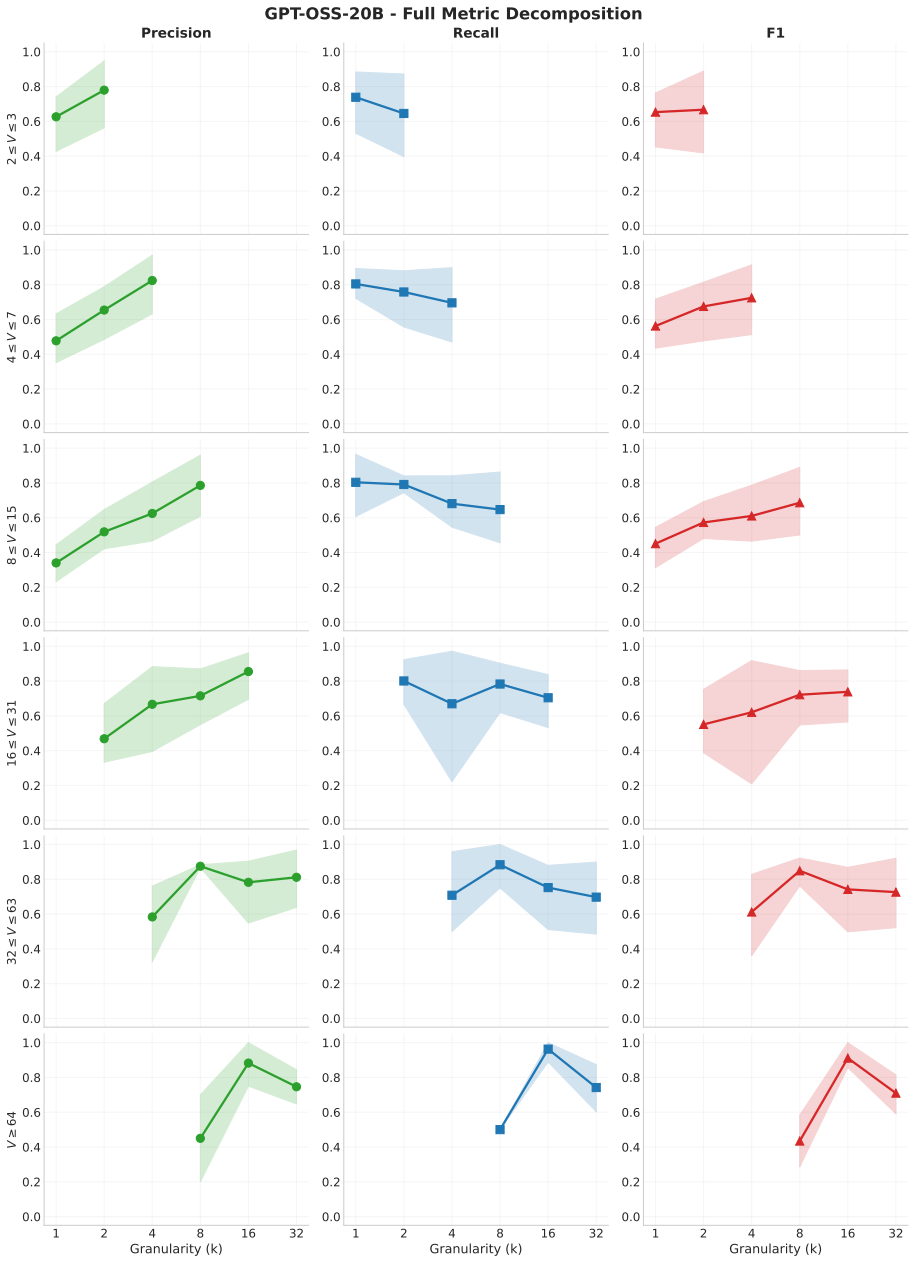
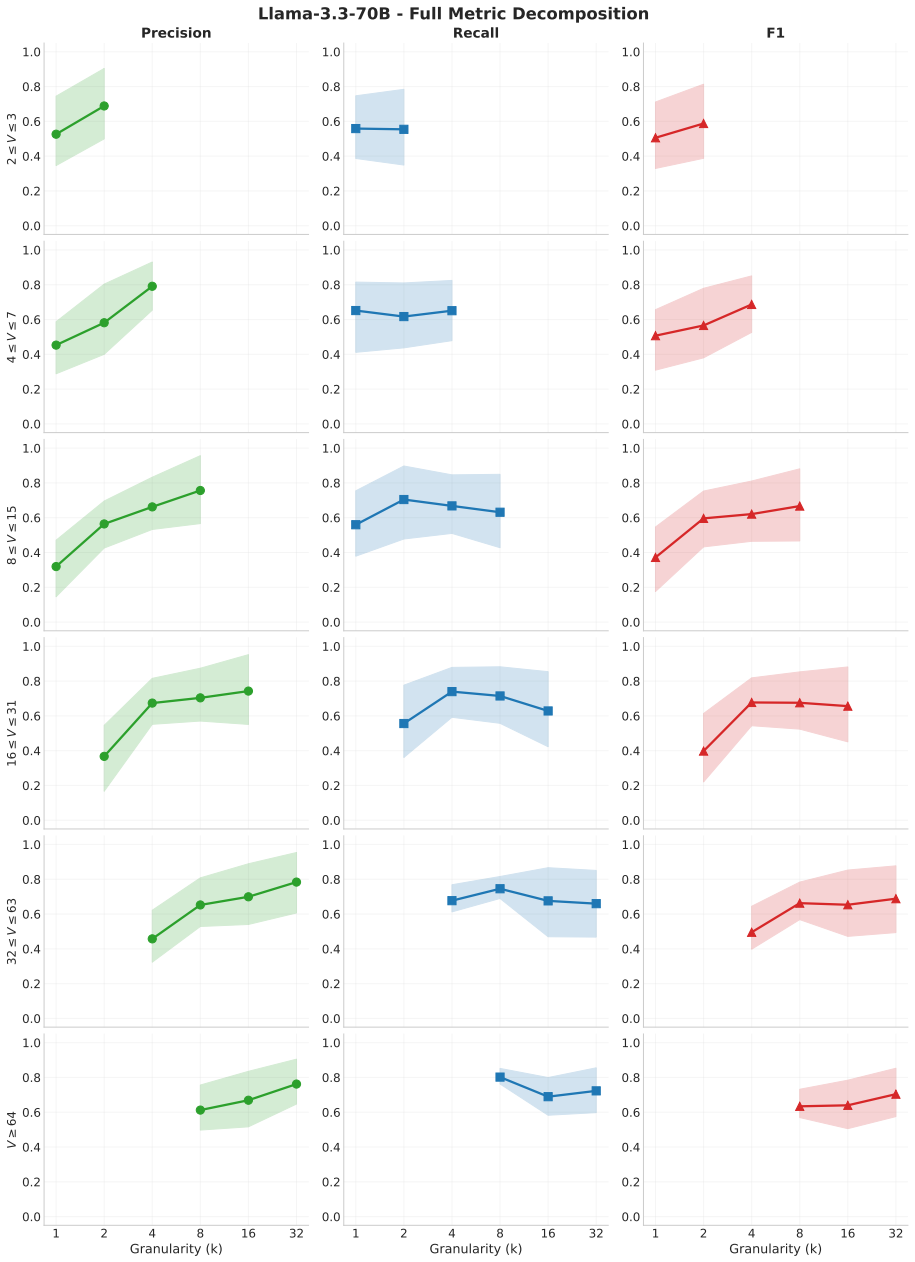
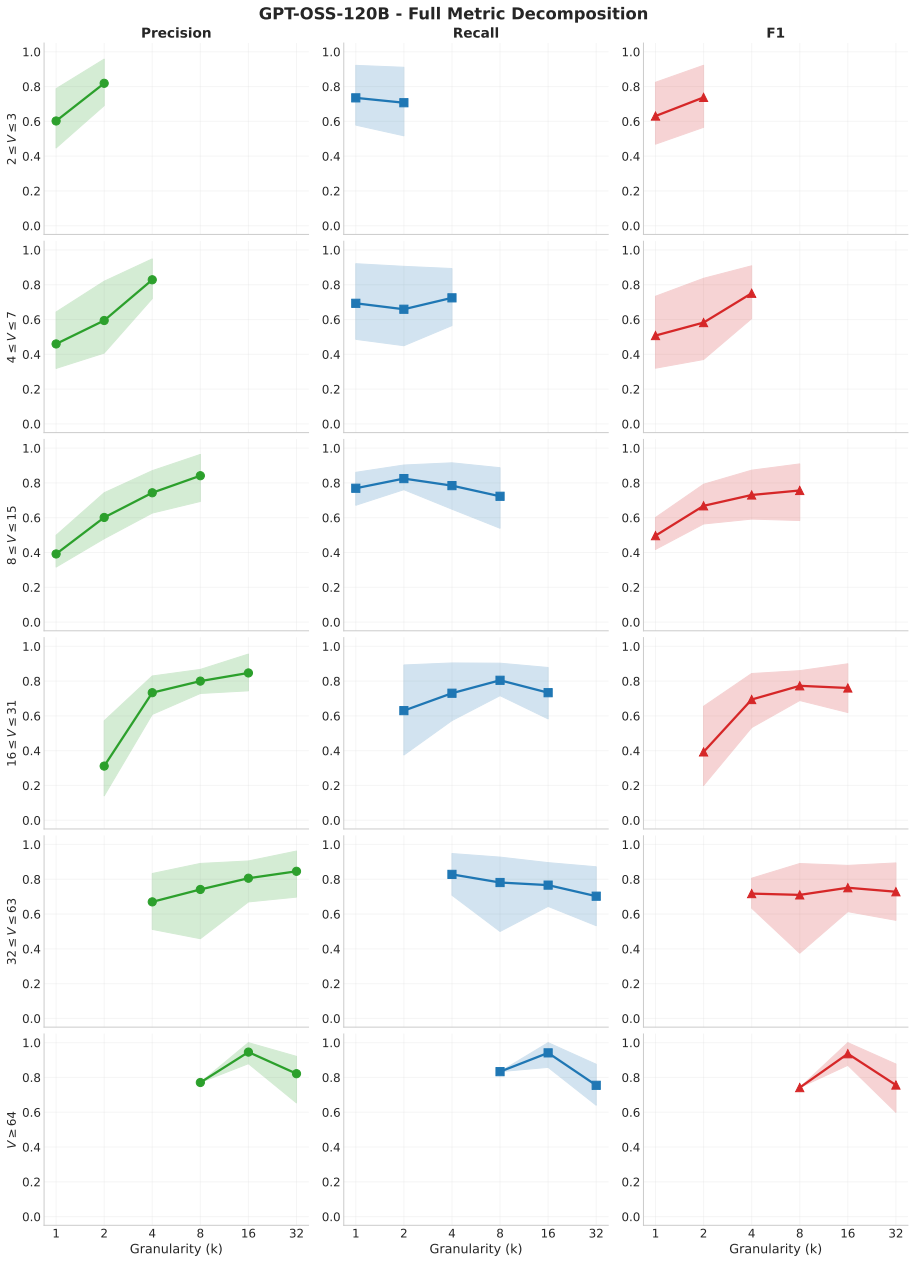
Precision Monotonicity:Does precision strictly increase (or stay flat) as granularity becomes coarser? This indicatesBoundary Tolerance
-
[5]
Recall Peak & Decline:At what granularity (k) does recall peak, and does it decline at the coarsest settings? This indicatesSignal Dilution. Universality.Precision monotonicity holds in 94% (15/16) of cases. The recall "peak-and- decline" pattern also holds in 94% (15/16) of cases, confirming that signal dilution is a robust phe- nomenon. We exclude extre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.