Recognition: 2 theorem links
· Lean TheoremSemantic Richness or Geometric Reasoning? The Fragility of VLM's Visual Invariance
Pith reviewed 2026-05-13 22:21 UTC · model grok-4.3
The pith
Vision-language models fail to maintain object identity under basic rotations, scaling, and translations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
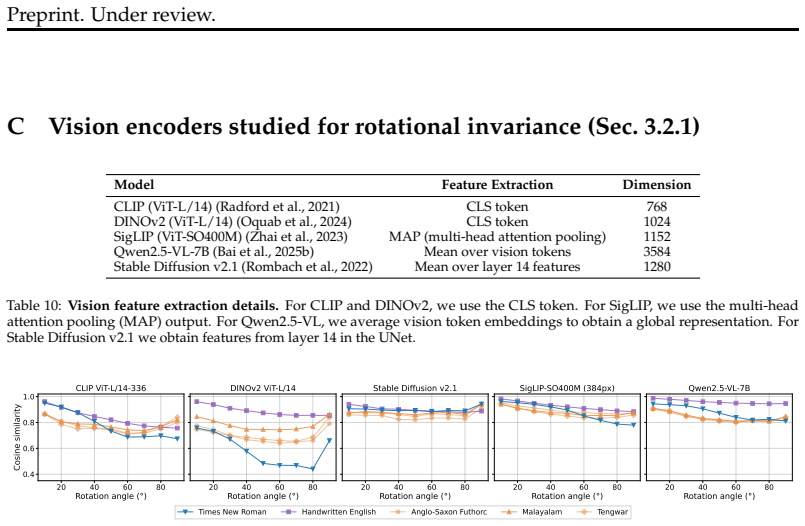
State-of-the-art VLMs exhibit systematic failures at a fundamental level: insufficient spatial invariance and equivariance to reliably determine object identity under rotations, scaling, and translations. Performance drops sharply as semantic content becomes sparse, and this pattern holds across symbolic sketches, natural photographs, abstract art, model architectures, capacities, and prompting strategies.
What carries the argument
Systematic evaluation of VLMs on controlled geometric transformations across multiple visual domains to measure drops in object identity accuracy.
If this is right
- VLMs display a gap between semantic understanding and spatial reasoning that persists regardless of architecture or model size.
- Semantic sparsity causes sharper accuracy losses when images undergo geometric changes.
- Current prompting strategies do not mitigate the lack of invariance and equivariance.
- Future multimodal systems require stronger geometric grounding to close this gap.
Where Pith is reading between the lines
- Models could incorporate explicit geometric consistency objectives during training to reduce reliance on semantic cues.
- Tasks like robotic manipulation or scene navigation may require auxiliary checks beyond standard VLM outputs.
- The same fragility pattern could appear in other vision-language benchmarks that assume stable object representations.
Load-bearing premise
The observed performance drops under geometric transformations directly reflect missing geometric reasoning rather than artifacts from prompting, dataset biases, or evaluation metrics.
What would settle it
A controlled test showing that multiple VLMs maintain high accuracy on object identification tasks after applying varied rotations, scalings, and translations to the same images would contradict the central claim.
Figures
















read the original abstract
This work investigates the fundamental fragility of state-of-the-art Vision-Language Models (VLMs) under basic geometric transformations. While modern VLMs excel at semantic tasks such as recognizing objects in canonical orientations and describing complex scenes, they exhibit systematic failures at a more fundamental level: lack of robust spatial invariance and equivariance required to reliably determine object identity under simple rotations, scaling, and identity transformations. We demonstrate this limitation through a systematic evaluation across diverse visual domains, including symbolic sketches, natural photographs, and abstract art. Performance drops sharply as semantic content becomes sparse, and this behavior is observed across architectures, model capacities, and prompting strategies. Overall, our results reveal a systematic gap between semantic understanding and spatial reasoning in current VLMs, highlighting the need for stronger geometric grounding in future multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that state-of-the-art VLMs lack robust spatial invariance and equivariance, as evidenced by sharp performance drops under simple geometric transformations (rotations, scaling, identity changes) across symbolic sketches, natural photographs, and abstract art. These failures are reported to intensify when semantic content is sparse and to persist across architectures, model sizes, and prompting strategies, revealing a fundamental gap between semantic understanding and geometric reasoning in current VLMs.
Significance. If the observed performance patterns can be shown to isolate geometric reasoning deficits rather than distribution shifts or metric artifacts, the result would be significant for the field: it would provide concrete empirical motivation for incorporating explicit geometric grounding into VLM training and architectures, moving beyond reliance on semantic richness alone.
major comments (1)
- [Abstract] Abstract: the central interpretation—that performance drops demonstrate missing spatial invariance/equivariance at the reasoning level—depends on the unshown assumption that the chosen transformations, prompts, and success metrics isolate geometric structure from confounds such as patch-tokenization changes, feature-distribution shifts, or description variability. No quantitative controls (e.g., embedding-distance comparisons pre/post-transform or ablation on metric choice) are described, leaving the claim vulnerable to alternative explanations.
minor comments (2)
- [Title] Title: the possessive 'VLM's' should be 'VLMs'' to match the plural usage throughout the abstract.
- [Abstract] Abstract: the phrase 'identity transformations' is ambiguous; clarify whether it refers to translations, reflections, or another class of geometric operations.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The concern about potential confounds is well-taken, and we address it directly below while clarifying the design choices in our evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central interpretation—that performance drops demonstrate missing spatial invariance/equivariance at the reasoning level—depends on the unshown assumption that the chosen transformations, prompts, and success metrics isolate geometric structure from confounds such as patch-tokenization changes, feature-distribution shifts, or description variability. No quantitative controls (e.g., embedding-distance comparisons pre/post-transform or ablation on metric choice) are described, leaving the claim vulnerable to alternative explanations.
Authors: We agree that explicit controls would further isolate geometric deficits from alternative explanations. Our multi-domain design (symbolic sketches, natural photos, abstract art) and consistent degradation patterns across architectures, sizes, and prompts were intended to mitigate domain-specific confounds, as tokenization or distribution shifts would be expected to vary substantially across these visual regimes rather than produce the observed uniform fragility tied to semantic sparsity. Nevertheless, we will add quantitative controls in the revision: (1) cosine-distance comparisons of image embeddings (from the vision encoder) pre- and post-transformation to quantify feature-distribution shifts, and (2) an ablation on success metrics (exact-match accuracy versus CLIP-based semantic similarity) reported in a new supplementary section. These additions will be presented alongside the main results to strengthen the geometric-reasoning interpretation. revision: partial
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential steps
full rationale
The paper is an empirical evaluation study that measures VLM performance drops under geometric transformations across domains, architectures, and prompting strategies. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text or abstract. All claims rest on direct observational patterns that are externally falsifiable via replication on the same models and transformations, with no reduction of results to definitions or prior author work by construction. This is the standard non-circular outcome for benchmark-style empirical papers.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
performance drops sharply as semantic content becomes sparse... models rely on semantic recognition as a shortcut rather than genuine transformation reasoning
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the apparent invariance observed in real-world images is not just because of geometric reasoning, but rather a byproduct of dataset familiarity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
, " * write output.state after.block = add.period write
ENTRY address author booktitle chapter doi edition editor eid howpublished institution journal key month note number organization pages publisher school series title type url volume year label INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := #2 'after.sentence := #3 '...
-
[3]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize ":" * " " *...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.