Recognition: 2 theorem links
· Lean TheoremPLUME: Latent Reasoning Based Universal Multimodal Embedding
Pith reviewed 2026-05-13 21:45 UTC · model grok-4.3
The pith
Short latent-state rollouts replace explicit chain-of-thought in universal multimodal embedding and deliver over 30x faster inference while improving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PLUME advances universal multimodal embedding by replacing verbalized chain-of-thought rationales with a short autoregressive rollout of continuous latent states, steered by a semantic-anchor-guided transition adapter that selects different reasoning trajectories under a fixed computation budget; a progressive explicit-to-latent curriculum transfers the reasoning behavior from text generation into hidden-state computation during training, so that explicit CoT is eliminated at inference, yielding higher accuracy on MMEB-v2 with over 30 times faster inference.
What carries the argument
The semantic-anchor-guided transition adapter that steers a short autoregressive rollout of continuous latent states along task-appropriate reasoning trajectories under fixed compute.
If this is right
- Higher accuracy than explicit-CoT UME baselines across all 78 tasks in MMEB-v2.
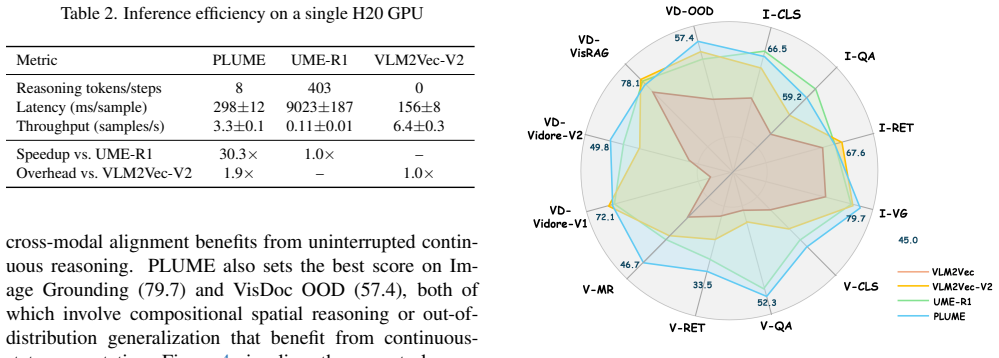
- Reasoning cost reduced from hundreds of generated tokens to fewer than 10 latent steps.
- Over 30 times faster inference at retrieval time.
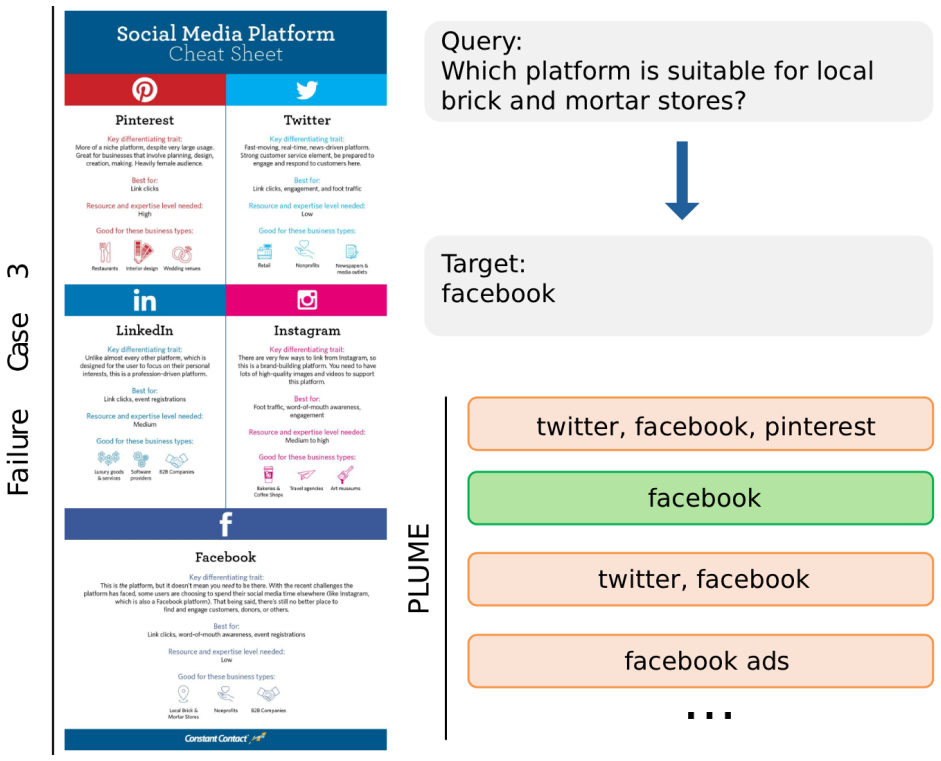
- Particular gains in video and visual-document retrieval where evidence is dense and hard to organize verbally.
- A training curriculum that gradually removes explicit rationales while preserving their benefit in hidden states.
Where Pith is reading between the lines
- The same latent-rollout pattern could be applied to other multimodal tasks that currently rely on generated explanations, such as visual question answering or captioning.
- Because the latent states remain continuous, they may support finer-grained similarity comparisons than discrete token sequences allow.
- Scaling the number of latent steps modestly might further close any remaining gap on tasks that benefit from longer explicit reasoning.
- The curriculum approach offers a general recipe for distilling slow explicit reasoning into fast hidden-state computation in other language-model families.
Load-bearing premise
A short sequence of continuous latent states can encode the same complex query-intent inference that explicit verbalized chain-of-thought produces, without discarding essential multimodal evidence.
What would settle it
On any MMEB-v2 task where explicit-CoT baselines currently lead, replace the latent rollout with an oracle that forces the model to output the same verbal rationales used by the baselines and measure whether accuracy drops below the latent-only result.
Figures











read the original abstract
Universal multimodal embedding (UME) maps heterogeneous inputs into a shared retrieval space with a single model. Recent approaches improve UME by generating explicit chain-of-thought (CoT) rationales before extracting embeddings, enabling multimodal large language models to better infer complex query intent. However, explicit CoT incurs substantial inference overhead and can compress rich multimodal evidence into a narrow textual bottleneck. We propose PLUME, a latent reasoning framework that advances UME by replacing verbalized CoT with a short autoregressive rollout of continuous latent states. To support diverse multimodal queries, PLUME further introduces a semantic-anchor-guided transition adapter that steers latent rollout along different reasoning trajectories under the same fixed computation budget. To stabilize training, PLUME adopts a progressive explicit-to-latent curriculum that uses verbalized reasoning only as a temporary training scaffold and gradually transfers this behavior into hidden-state computation, eliminating explicit CoT at inference. On the 78-task MMEB-v2 benchmark, PLUME outperforms strong explicit-CoT UME baselines while reducing reasoning from hundreds of generated tokens to fewer than 10 latent steps, delivering over 30x faster inference. PLUME is especially well suited to retrieval settings where relevant evidence is dense, structurally complex, and difficult to organize through verbalized intermediate rationales, such as video and visual document retrieval. These results show that structured latent computation can preserve the benefits of intermediate reasoning without the overhead of explicit rationale generation, providing a stronger and more efficient paradigm for practical retrieval systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PLUME, a latent reasoning framework for universal multimodal embedding (UME) that replaces explicit chain-of-thought (CoT) rationales with short autoregressive rollouts of continuous latent states. It introduces a semantic-anchor-guided transition adapter to steer these rollouts under a fixed computation budget and uses a progressive explicit-to-latent curriculum to transfer reasoning behavior from verbalized scaffolds to hidden-state computation during training. On the 78-task MMEB-v2 benchmark, PLUME is claimed to outperform strong explicit-CoT UME baselines while reducing reasoning from hundreds of tokens to fewer than 10 latent steps, yielding over 30x faster inference, with particular advantages for dense-evidence tasks such as video and visual document retrieval.
Significance. If the central performance claims hold under rigorous verification, the work would be significant for practical multimodal retrieval systems by showing that structured latent computation can preserve intermediate reasoning benefits without explicit token generation overhead. It extends existing multimodal models with targeted components and targets a clear efficiency gap in current UME approaches.
major comments (3)
- [Methods] Methods section (description of semantic-anchor-guided transition adapter): The claim that the adapter steers the autoregressive latent rollout through equivalent reasoning trajectories to explicit CoT is load-bearing for the headline result, yet no ablation is described that disables the adapter while keeping the same latent rollout length, model backbone, and training budget to isolate its contribution versus architectural side-effects.
- [Experiments] Experiments section (MMEB-v2 results and ablations): The outperformance on 78 tasks with <10 latent steps is presented without probing of hidden-state evolution, similarity to verbalized rationales, or isolating ablations on the transition adapter; this leaves open whether gains arise from latent reasoning per se or from training dynamics, especially on dense-evidence tasks.
- [Training] Training curriculum subsection: The progressive explicit-to-latent curriculum is described as gradually transferring behavior to hidden-state computation, but no details on the schedule, transition losses, or performance curves during the shift are provided to confirm that explicit CoT is fully eliminated at inference without performance degradation.
minor comments (2)
- [Abstract and Experiments] The abstract and main text should include explicit details on the exact data splits, task composition of the 78-task MMEB-v2 benchmark, and baseline implementations for full reproducibility.
- [Methods] Notation for latent states, the transition adapter, and the number of latent steps should be formalized with equations to clarify the autoregressive rollout process.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Methods] Methods section (description of semantic-anchor-guided transition adapter): The claim that the adapter steers the autoregressive latent rollout through equivalent reasoning trajectories to explicit CoT is load-bearing for the headline result, yet no ablation is described that disables the adapter while keeping the same latent rollout length, model backbone, and training budget to isolate its contribution versus architectural side-effects.
Authors: We agree that an explicit ablation isolating the transition adapter is necessary to substantiate its role. In the revised manuscript we will add this ablation: the adapter is removed while preserving identical latent rollout length, backbone, and training budget, allowing direct comparison of performance and trajectory alignment with the full model. revision: yes
-
Referee: [Experiments] Experiments section (MMEB-v2 results and ablations): The outperformance on 78 tasks with <10 latent steps is presented without probing of hidden-state evolution, similarity to verbalized rationales, or isolating ablations on the transition adapter; this leaves open whether gains arise from latent reasoning per se or from training dynamics, especially on dense-evidence tasks.
Authors: We will expand the experiments section with (i) quantitative and qualitative probes of hidden-state evolution across the latent rollout steps, (ii) similarity metrics between latent trajectories and corresponding explicit CoT rationales, and (iii) the adapter ablation described above. These additions will clarify that the observed gains derive from the latent reasoning mechanism rather than training artifacts, with particular attention to dense-evidence tasks. revision: yes
-
Referee: [Training] Training curriculum subsection: The progressive explicit-to-latent curriculum is described as gradually transferring behavior to hidden-state computation, but no details on the schedule, transition losses, or performance curves during the shift are provided to confirm that explicit CoT is fully eliminated at inference without performance degradation.
Authors: We will revise the training curriculum subsection to report the exact schedule (number of epochs per stage and mixing ratios), the formulation of the transition losses, and training curves that track both explicit-CoT and latent-only performance throughout the curriculum. These details will demonstrate that explicit CoT is fully removed at inference while performance is preserved or improved. revision: yes
Circularity Check
No circularity: method presented as empirical architectural extension without self-referential derivations
full rationale
The paper introduces PLUME as a latent-reasoning replacement for explicit CoT in UME, using a semantic-anchor-guided transition adapter and progressive curriculum, but presents no equations, fitted-parameter predictions, or uniqueness theorems that reduce the claimed benchmark gains to quantities defined inside the same work. Results on MMEB-v2 are reported as direct empirical outcomes of the added components rather than derived predictions. No self-citations are used to justify load-bearing premises, and the approach is framed as building on existing multimodal models with independent training stabilizations. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of latent steps
axioms (1)
- domain assumption Autoregressive evolution of continuous hidden states can perform the same intent-inference function as explicit chain-of-thought text generation.
invented entities (1)
-
semantic-anchor-guided transition adapter
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Breath1024.leanperiod8, neutral8, flipAt512 echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The latent rollout length is set to K=8... reducing reasoning from hundreds of generated tokens to fewer than 10 latent steps... semantic-anchor-guided transition adapter that steers latent rollout along different reasoning trajectories under the same fixed computation budget.
-
IndisputableMonolith/Foundation/ArrowOfTime.leanz_monotone_absolute, arrow_from_z echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
PLUME internalizes reasoning for UME into a compact latent process inside the MLLM... short autoregressive rollout of continuous latent states... progressive explicit-to-latent curriculum
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
LatentRouter: Can We Choose the Right Multimodal Model Before Seeing Its Answer?
LatentRouter routes image-question queries to the best MLLM by predicting counterfactual performance via latent communication between learned query capsules and model capability tokens.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Yoshua Bengio, J ´erˆome Louradour, Ronan Collobert, and Ja- son Weston. Curriculum learning. InProceedings of the 26th International Conference on Machine Learning, pages 41–48. ACM, 2009. 6
work page 2009
-
[3]
Haonan Chen, Hong Liu, Yuping Luo, Liang Wang, Nan Yang, Furu Wei, and Zhicheng Dou. Moca: Modality-aware continual pre-training makes better bidirectional multimodal embeddings.arXiv preprint arXiv:2506.23115, 2025. 3
-
[4]
Xinghao Chen, Anhao Zhao, Heming Xia, Xuan Lu, Han- lin Wang, Yanjun Chen, Wei Zhang, Jian Wang, Wenjie Li, and Xiaoyu Shen. Reasoning beyond language: A compre- hensive survey on latent chain-of-thought reasoning.CoRR, abs/2505.16782, 2025. 2, 3
-
[5]
Xuanming Cui, Jianpeng Cheng, Hong-you Chen, Satya Narayan Shukla, Abhijeet Awasthi, Xichen Pan, Chaitanya Ahuja, Shlok Kumar Mishra, Yonghuan Yang, Jun Xiao, et al. Think then embed: Generative con- text improves multimodal embedding.arXiv preprint arXiv:2510.05014, 2025. 2, 3, 7
-
[6]
ColPali: Efficient Document Retrieval with Vision Language Models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, C ´eline Hudelot, and Pierre Colombo. Col- pali: Efficient document retrieval with vision language mod- els.arXiv preprint arXiv:2407.01449, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[7]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with sim- ple and efficient sparsity.ArXiv, abs/2101.03961, 2021. 5
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. InIn- ternational Conference on Learning Representations (ICLR),
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Tiancheng Gu, Kaicheng Yang, Ziyong Feng, Xingjun Wang, Yanzhao Zhang, Dingkun Long, Yingda Chen, Wei- dong Cai, and Jiankang Deng. Breaking the modality barrier: Universal embedding learning with multimodal llms.arXiv preprint arXiv:2504.17432, 2025. 3
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large lan- guage models to reason in a continuous latent space.CoRR, abs/2412.06769, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Xiangzhao Hao, Shijie Wang, Tianyu Yang, Tianyue Wang, Haiyun Guo, and Jinqiao Wang. Trace: Task-adaptive rea- soning and representation learning for universal multimodal retrieval, 2026. 2, 3
work page 2026
-
[14]
Gaussian error linear units (gelus).arXiv: Learning, 2016
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv: Learning, 2016. 5
work page 2016
-
[15]
Unsupervised dense information retrieval with con- trastive learning.Trans
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebas- tian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with con- trastive learning.Trans. Mach. Learn. Res., 2022, 2022. 6
work page 2022
-
[16]
Kalervo J ¨arvelin and Jaana Kek ¨al¨ainen. Cumulated gain- based evaluation of ir techniques.ACM Transactions on In- formation Systems (TOIS), 20(4):422–446, 2002. 7
work page 2002
-
[17]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR,
-
[18]
Haonan Jiang, Yuji Wang, Yongjie Zhu, Xin Lu, Wenyu Qin, Meng Wang, Pengfei Wan, and Yansong Tang. Embed- rl: Reinforcement learning for reasoning-driven multimodal embeddings.arXiv preprint arXiv:2602.13823, 2026. 3
-
[19]
E5-V: universal embeddings with multi- modal large language models
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, and Fuzhen Zhuang. E5-v: Universal embeddings with multimodal large language models.arXiv preprint arXiv:2407.12580, 2024. 2, 3
- [20]
-
[21]
Laser: Internal- izing explicit reasoning into latent space for dense retrieval,
Jiajie Jin, Yanzhao Zhang, Mingxin Li, Dingkun Long, Pengjun Xie, Yutao Zhu, and Zhicheng Dou. Laser: Internal- izing explicit reasoning into latent space for dense retrieval,
-
[22]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InPro- 10 ceedings of the 29th Symposium on Operating Systems Prin- ciples, SOSP 2023, Koblenz, Germany, October 23-26, 2023, pages 611–626. ACM, 2023. 5
work page 2023
-
[23]
Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, and Jinsong Su. Llave: Large language and vision embedding models with hardness-weighted contrastive learning.arXiv preprint arXiv:2503.04812, 2025. 3
-
[24]
Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, and Jin- song Su. Ume-r1: Exploring reasoning-driven generative multimodal embeddings.arXiv preprint arXiv:2511.00405,
-
[25]
Nv- embed: Improved techniques for training llms as generalist embedding models
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nv- embed: Improved techniques for training llms as generalist embedding models. InThe Thirteenth International Confer- ence on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. 3
work page 2025
-
[26]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 3
work page 2023
-
[28]
arXiv preprint arXiv:2411.02571 , year=
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. Mm-embed: Universal multimodal retrieval with multimodal llms.arXiv preprint arXiv:2411.02571, 2024. 2, 3
-
[29]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1
work page 2023
-
[30]
Lamra: Large multimodal model as your advanced retrieval assistant
Yikun Liu, Yajie Zhang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Lamra: Large multimodal model as your advanced retrieval assistant. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4015–4025, 2025. 3, 7
work page 2025
-
[31]
arXiv preprint arXiv:2507.04590 , year=
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, et al. Vlm2vec-v2: Advancing multimodal em- bedding for videos, images, and visual documents.arXiv preprint arXiv:2507.04590, 2025. 1, 3, 7, 8
-
[32]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 3, 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [33]
-
[34]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 3
work page 2021
-
[35]
Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer, 2017
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer, 2017. 5
work page 2017
-
[36]
Codi: Compressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. CODI: compressing chain-of- thought into continuous space via self-distillation.CoRR, abs/2502.21074, 2025. 2, 3
-
[37]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeural Information Processing Systems, 2017. 5
work page 2017
-
[38]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre- training.CoRR, abs/2212.03533, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Improving text embeddings with large language models
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Ran- gan Majumder, and Furu Wei. Improving text embeddings with large language models. InProceedings of the 62nd An- nual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), ACL 2024, Bangkok, Thai- land, August 11-16, 2024, pages 11897–11916. Association for Computational ...
work page 2024
-
[40]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 1, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reason- ing in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Uniir: Train- ing and benchmarking universal multimodal information re- trievers
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. Uniir: Train- ing and benchmarking universal multimodal information re- trievers. InEuropean Conference on Computer Vision, pages 387–404. Springer, 2024. 3
work page 2024
-
[43]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 2, 3
work page 2022
-
[44]
C-pack: Packed resources for general chinese embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C-pack: Packed resources for general chinese embeddings. InProceedings of the 47th In- ternational ACM SIGIR Conference on Research and Devel- opment in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, pages 641–649. ACM, 2024. 3
work page 2024
-
[45]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087– 2098, 2025. 3
work page 2087
-
[46]
Tianyu Yang, ChenWei He, Xiangzhao Hao, Tianyue Wang, Jiarui Guo, Haiyun Guo, Leigang Qu, Jinqiao Wang, and Tat-Seng Chua. Recall: Recalibrating capability degradation for mllm-based composed image retrieval.arXiv preprint arXiv:2602.01639, 2026. 2 11
-
[47]
Recall: Recalibrating capability degradation for mllm-based composed image retrieval, 2026
Tianyu Yang, Chenwei He, Xiangzhao Hao, Tianyue Wang, Jiarui Guo, Haiyun Guo, Leigang Qu, Jinqiao Wang, and Tat- Seng Chua. Recall: Recalibrating capability degradation for mllm-based composed image retrieval, 2026. 3
work page 2026
-
[48]
Hao Yu, Zhuokai Zhao, Shen Yan, Lukasz Korycki, Jianyu Wang, Baosheng He, Jiayi Liu, Lizhu Zhang, Xiangjun Fan, and Hanchao Yu. Cafe: Unifying representation and gen- eration with contrastive-autoregressive finetuning.arXiv preprint arXiv:2503.19900, 2025. 3
-
[49]
Visrag: Vision-based retrieval-augmented generation on multi-modality documents
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, et al. Visrag: Vision-based retrieval-augmented generation on multi-modality documents.arXiv preprint arXiv:2410.10594, 2024. 3
-
[50]
E. Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D. Goodman. Quiet-star: Lan- guage models can teach themselves to think before speaking. ArXiv, abs/2403.09629, 2024. 3
-
[51]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 3
work page 2023
-
[52]
Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, and Ming-Wei Chang. Magi- clens: Self-supervised image retrieval with open-ended in- structions.arXiv preprint arXiv:2403.19651, 2024. 3
-
[53]
Xuan Zhang, Chao Du, Tianyu Pang, Qian Liu, Wei Gao, and Min Lin. Chain of preference optimization: Improving chain-of-thought reasoning in llms.Advances in Neural In- formation Processing Systems, 37:333–356, 2024. 3
work page 2024
-
[54]
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. Gme: Improving universal multimodal retrieval by multimodal llms.arXiv preprint arXiv:2412.16855, 2024. 1, 2, 3, 7
work page internal anchor Pith review arXiv 2024
-
[55]
Bridging modalities: Improving universal mul- timodal retrieval by multimodal large language models
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. Bridging modalities: Improving universal mul- timodal retrieval by multimodal large language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 9274–9285, 2025. 3, 7
work page 2025
-
[56]
Junjie Zhou, Zheng Liu, Ze Liu, Shitao Xiao, Yueze Wang, Bo Zhao, Chen Jason Zhang, Defu Lian, and Yongping Xiong. Megapairs: Massive data synthesis for universal mul- timodal retrieval.arXiv preprint arXiv:2412.14475, 2024. 3
-
[57]
Junjie Zhou, Yongping Xiong, Zheng Liu, Ze Liu, Shitao Xiao, Yueze Wang, Bo Zhao, Chen Jason Zhang, and Defu Lian. Megapairs: Massive data synthesis for universal multi- modal retrieval. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 19076–19095, 2025. 3 12 A. Curriculum Ablation De...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.