Recognition: 2 theorem links
· Lean TheoremCASHG: Context-Aware Stylized Online Handwriting Generation
Pith reviewed 2026-05-13 21:41 UTC · model grok-4.3
The pith
CASHG explicitly models character transitions to generate more natural sentence-level stylized handwriting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
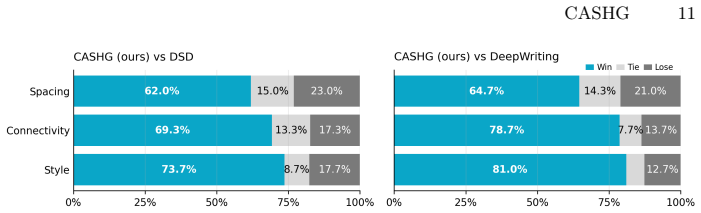
CASHG is a context-aware generator that obtains character identity and sentence context via a Character Context Encoder, fuses them in a bigram-aware sliding-window Transformer decoder with gated context fusion, and trains through a three-stage curriculum from isolated glyphs to full sentences; this explicit modeling of inter-character connectivity yields improved Connectivity and Spacing Metrics under benchmark-matched protocols while remaining competitive in DTW trajectory similarity, with gains corroborated by human evaluation.
What carries the argument
Bigram-aware sliding-window Transformer decoder that emphasizes local predecessor-current transitions, fused with sentence context from the Character Context Encoder via gated fusion.
If this is right
- Higher scores on Connectivity and Spacing Metrics than prior methods under matched evaluation protocols.
- Competitive performance on DTW-based trajectory similarity measures.
- Gains in boundary naturalness confirmed by human evaluation.
- Improved robustness to sparse transition coverage through staged curriculum training.
Where Pith is reading between the lines
- The explicit transition modeling could transfer to other sequential synthesis tasks such as speech prosody or gesture generation where local continuity matters.
- The new Connectivity and Spacing Metrics may serve as a reusable benchmark that shifts future handwriting evaluation toward boundary properties.
- Curriculum scaling from glyphs to sentences offers a reusable training pattern for any generative model facing compositional data scarcity.
Load-bearing premise
That explicit bigram-aware modeling of predecessor-current transitions plus curriculum training will reliably produce natural inter-character connectivity even when training data has sparse transition coverage at sentence scale.
What would settle it
A controlled test on sentences containing rare or unseen character bigrams where CASHG shows no improvement or a drop in Connectivity and Spacing Metrics relative to strong baselines would falsify the central claim.
Figures





read the original abstract
Online handwriting represents strokes as time-ordered trajectories, which makes handwritten content easier to transform and reuse in a wide range of applications. However, generating natural sentence-level online handwriting that faithfully reflects a writer's style remains challenging, since sentence synthesis demands context-dependent characters with stroke continuity and spacing. Prior methods treat these boundary properties as implicit outcomes of sequence modeling, which becomes unreliable at the sentence scale and under limited compositional diversity. We propose CASHG, a context-aware stylized online handwriting generator that explicitly models inter-character connectivity for style-consistent sentence-level trajectory synthesis. CASHG uses a Character Context Encoder to obtain character identity and sentence-dependent context memory and fuses them in a bigram-aware sliding-window Transformer decoder that emphasizes local predecessor--current transitions, complemented by gated context fusion for sentence-level context.Training proceeds through a three-stage curriculum from isolated glyphs to full sentences, improving robustness under sparse transition coverage. We further introduce Connectivity and Spacing Metrics (CSM), a boundary-aware evaluation suite that quantifies cursive connectivity and spacing similarity. Under benchmark-matched evaluation protocols, CASHG consistently improves CSM over comparison methods while remaining competitive in DTW-based trajectory similarity, with gains corroborated by a human evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CASHG, a context-aware model for stylized online handwriting generation at the sentence level. It uses a Character Context Encoder for character identity and sentence-dependent context memory, fused via a bigram-aware sliding-window Transformer decoder with gated context fusion. Training follows a three-stage curriculum from isolated glyphs to full sentences to handle sparse transitions, and the work proposes Connectivity and Spacing Metrics (CSM) as a boundary-aware evaluation suite. Under benchmark protocols, CASHG reports consistent CSM improvements over baselines while remaining competitive on DTW trajectory similarity, with corroboration from human evaluation.
Significance. If the CSM gains are substantiated by ablations and statistical tests, the explicit modeling of predecessor-current transitions and curriculum training could meaningfully advance sentence-level stylized handwriting synthesis beyond implicit sequence modeling approaches. The new CSM metrics address a gap in evaluating cursive connectivity and spacing, potentially influencing future benchmarks in the field.
major comments (2)
- [Experimental Evaluation] Experimental section: the central claim of consistent CSM gains rests on the three-stage curriculum and bigram-aware decoder, yet no ablation isolating the curriculum stages (glyphs to words to sentences) or frequency analysis of bigram coverage in the training data is provided. This leaves open whether gains hold for rare transitions or are driven by frequent ones only.
- [Method and Results] Method and results: exact baseline implementations, hyperparameter details, and statistical significance tests (e.g., p-values or confidence intervals) for the reported CSM improvements are not described, making it difficult to verify the 'consistent' outperformance under matched protocols.
minor comments (2)
- [Model Architecture] The description of the gated context fusion and sliding-window mechanism would benefit from additional equations or a detailed diagram for clarity and reproducibility.
- [Human Evaluation] Ensure the human evaluation protocol (number of participants, rating scale, and statistical analysis) is fully detailed to support the corroboration claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and will revise the paper accordingly to strengthen the experimental validation and reporting.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental section: the central claim of consistent CSM gains rests on the three-stage curriculum and bigram-aware decoder, yet no ablation isolating the curriculum stages (glyphs to words to sentences) or frequency analysis of bigram coverage in the training data is provided. This leaves open whether gains hold for rare transitions or are driven by frequent ones only.
Authors: We agree that the current manuscript would benefit from explicit ablations and bigram analysis to substantiate the curriculum's role. In the revision we will add ablation studies comparing the full three-stage curriculum against reduced variants (e.g., direct sentence-level training and two-stage training) and include a frequency breakdown of bigrams in the training set, reporting separate CSM scores for frequent versus rare transitions to demonstrate that gains are not limited to common cases. revision: yes
-
Referee: [Method and Results] Method and results: exact baseline implementations, hyperparameter details, and statistical significance tests (e.g., p-values or confidence intervals) for the reported CSM improvements are not described, making it difficult to verify the 'consistent' outperformance under matched protocols.
Authors: We acknowledge that the manuscript lacks sufficient implementation and statistical details. The revised version will provide exact baseline code references and hyperparameter tables for all models, along with statistical significance tests (paired t-tests with p-values and 95% confidence intervals) on the CSM improvements to rigorously verify consistent outperformance under the benchmark protocols. revision: yes
Circularity Check
No circularity: CASHG architecture, curriculum, and CSM metrics are independently defined and empirically tested
full rationale
The paper defines a new Transformer-based architecture with Character Context Encoder, bigram-aware decoder, and gated fusion, plus a three-stage curriculum from glyphs to sentences. It introduces Connectivity and Spacing Metrics (CSM) as a separate boundary-aware evaluation suite. All performance claims (CSM gains, DTW competitiveness, human eval) are presented as results of training on standard external handwriting datasets under benchmark protocols. No equations, parameters, or metrics are defined in terms of each other by construction, no load-bearing self-citations appear, and no fitted inputs are relabeled as predictions. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transformer attention mechanisms can be made to emphasize local predecessor-current transitions via sliding-window masking and bigram conditioning.
- domain assumption A three-stage curriculum from isolated glyphs to full sentences improves robustness when transition coverage is sparse.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CASHG uses a Character Context Encoder ... bigram-aware sliding-window Transformer decoder ... three-stage curriculum (glyphs→bigrams→sentences)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We further introduce Connectivity and Spacing Metrics (CSM)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aksan, E., Pece, F., Hilliges, O.: Deepwriting: Making digital ink editable via deep generative modeling. In: CHI. pp. 1–14 (2018) 2, 4, 5, 10, 14, 32, 33, 34, 35, 41
work page 2018
-
[2]
Berndt, D.J., Clifford, J.: Using dynamic time warping to find patterns in time series. In: KDD Workshop. pp. 359–370 (1994) 11, 31, 32, 39, 41
work page 1994
- [3]
- [4]
-
[5]
Clark, J.H., Garrette, D., Turc, I., Wieting, J.: Canine: Pre-training an efficient tokenization-free encoder for language representation. TACL10, 73–91 (2022) 4, 6, 27
work page 2022
- [6]
-
[7]
Cartographica10(2), 112– 122 (1973) 11, 25, 26
Douglas, D.H., Peucker, T.K.: Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartographica10(2), 112– 122 (1973) 11, 25, 26
work page 1973
- [8]
-
[9]
Cognitive Computation13(5), 1406–1421 (2021) 1, 4
Faundez-Zanuy, M., Mekyska, J., Impedovo, D.: Online handwriting, signature and touch dynamics: tasks and potential applications in the field of security and health. Cognitive Computation13(5), 1406–1421 (2021) 1, 4
work page 2021
- [10]
- [11]
- [12]
-
[13]
arXiv preprint arXiv:1308.0850 (2013) 4, 5
Graves, A.: Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850 (2013) 4, 5
-
[14]
Gutmann, M., Hyvärinen, A.: Noise-contrastive estimation: A new estimation prin- ciple for unnormalized statistical models. In: AISTATS. pp. 297–304. JMLR Work- shop and Conference Proceedings (2010) 4
work page 2010
- [15]
- [16]
- [17]
- [18]
-
[19]
NeurIPS33, 18661–18673 (2020) 4
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D.: Supervised contrastive learning. NeurIPS33, 18661–18673 (2020) 4
work page 2020
- [20]
-
[21]
In: International Joint Conference on Neural Networks (IJCNN)
Lee, H., Verma, B.: Over-segmentation and neural binary validation for cursive handwriting recognition. In: International Joint Conference on Neural Networks (IJCNN). pp. 1–5. IEEE (2010) 4
work page 2010
- [22]
- [23]
- [24]
-
[25]
TNNLS34(11), 8503–8515 (2022) 4
Luo, C., Zhu, Y., Jin, L., Li, Z., Peng, D.: Slogan: handwriting style synthesis for arbitrary-length and out-of-vocabulary text. TNNLS34(11), 8503–8515 (2022) 4
work page 2022
-
[26]
Mitrevski, B., Rak, A., Schnitzler, J., Li, C., Maksai, A., Berent, J., Musat, C.C.: Inksight: Offline-to-online handwriting conversion by teaching vision-language models to read and write. TMLR (2025) 4
work page 2025
- [27]
-
[28]
IJDAR25(4), 385–414 (2022) 1, 4
Ott, F., Rügamer, D., Heublein, L., Hamann, T., Barth, J., Bischl, B., Mutschler, C.: Benchmarking online sequence-to-sequence and character-based handwriting recognition from imu-enhanced pens. IJDAR25(4), 385–414 (2022) 1, 4
work page 2022
-
[29]
In: ICLR (2026), https://openreview.net/forum?id=XKOEQFKFdL11
Pan, W., He, H., Cheng, H., Shi, Y., Jin, L.: Diffink: Glyph- and style-aware latent diffusion transformer for text to online handwriting generation. In: ICLR (2026), https://openreview.net/forum?id=XKOEQFKFdL11
work page 2026
- [30]
-
[31]
IEEE TPAMI22(1), 63–84 (2002) 4
Plamondon, R., Srihari, S.N.: Online and off-line handwriting recognition: a com- prehensive survey. IEEE TPAMI22(1), 63–84 (2002) 4
work page 2002
-
[32]
Ramer, U.: An iterative procedure for the polygonal approximation of plane curves. Comput. Graph. Image Process.1(3), 244–256 (1972) 11, 25, 26
work page 1972
-
[33]
In: ICLR (2025),https://openreview.net/forum?id= DhHIw9Nbl12, 4, 5, 10, 14, 25, 26
Ren, M., Zhang, Y.M., Chen, Y.: Decoupling layout from glyph in online chinese handwriting generation. In: ICLR (2025),https://openreview.net/forum?id= DhHIw9Nbl12, 4, 5, 10, 14, 25, 26
work page 2025
-
[34]
Neurocomputing568, 127063 (2024) 8
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024) 8
work page 2024
-
[35]
Tang, S., Lian, Z.: Write like you: Synthesizing your cursive online chinese hand- writingviametric-basedmetalearning.In:CGF.vol.40,pp.141–151.WileyOnline Library (2021) 4, 13
work page 2021
-
[36]
Tang, S., Xia, Z., Lian, Z., Tang, Y., Xiao, J.: Fontrnn: Generating large-scale chinese fonts via recurrent neural network. In: CGF. vol. 38, pp. 567–577. Wiley Online Library (2019) 4, 5
work page 2019
- [37]
-
[38]
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. NeurIPS30(2017) 5
work page 2017
-
[39]
Xue, L., Barua, A., Constant, N., Al-Rfou, R., Narang, S., Kale, M., Roberts, A., Raffel, C.: Byt5: Towards a token-free future with pre-trained byte-to-byte models. TACL10, 291–306 (2022) 4, 6
work page 2022
-
[40]
IEEE TPAMI40(4), 849–862 (2017) 4, 5, 13
Zhang, X.Y., Yin, F., Zhang, Y.M., Liu, C.L., Bengio, Y.: Drawing and recognizing chinese characters with recurrent neural network. IEEE TPAMI40(4), 849–862 (2017) 4, 5, 13
work page 2017
-
[41]
Zhao, B., Tao, J., Yang, M., Tian, Z., Fan, C., Bai, Y.: Deep imitator: Handwriting calligraphyimitationviadeepattentionnetworks.PatternRecognition104,107080 (2020) 4, 5, 13 18 J. Shin et al. Appendices for CASHG: Context-Aware Stylized Online Handwriting Generation A Training Details and Curriculum Schedule A.1 Three-Stage Curriculum Sentence-level onlin...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.