Recognition: no theorem link
PAC learning PDFA from data streams
Pith reviewed 2026-05-13 20:54 UTC · model grok-4.3
The pith
A streaming algorithm learns PDFAs from data streams with PAC guarantees and faster runtime for large samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
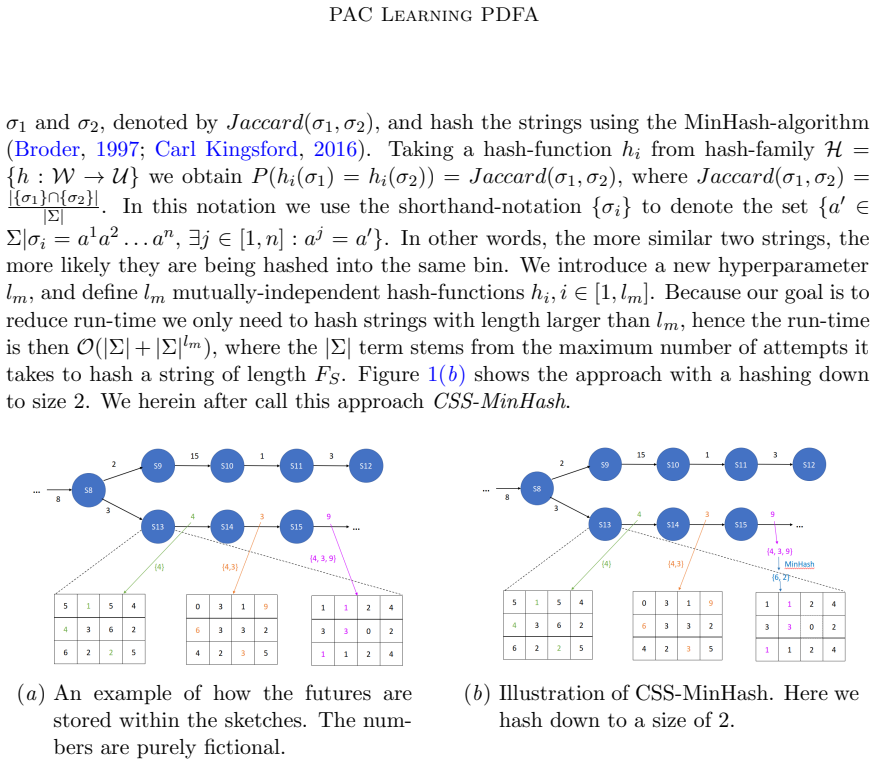
The paper establishes a streaming state merging algorithm for PDFAs that incrementally processes data, maintaining an approximate prefix tree and using frequency sketches to decide state merges. It proves that this algorithm satisfies PAC learning conditions, ensuring that with enough samples it converges to the target model. Additionally, it demonstrates a way to optimize the merge process for better performance on larger streams.
What carries the argument
The sketch-based heuristic for deciding merges in an incrementally built prefix tree, which approximates state probabilities to enable correct decisions under streaming constraints.
If this is right
- The algorithm can learn accurate PDFA models from ongoing data streams.
- It provides runtime improvements for larger sample sizes while maintaining PAC correctness.
- Implementation shows better runtime and memory use compared to existing methods on benchmark datasets.
- The formal PAC analysis guarantees learnability with sufficient data.
Where Pith is reading between the lines
- This approach could support real-time monitoring and modeling of systems like networks or software.
- Extensions might include handling concept drift where the underlying PDFA changes over time.
- Similar sketching techniques could improve other online automata learning algorithms.
Load-bearing premise
The underlying process generating the data stream is a fixed PDFA, and the sketches provide accurate enough approximations for merge decisions to satisfy the PAC sample complexity bounds.
What would settle it
Running the algorithm on streams from a known PDFA with a sample size meeting the PAC bound and verifying whether the output model is epsilon-close to the true distribution with high probability.
Figures


read the original abstract
This is an extended version of our publication Learning state machines from data streams: A generic strategy and an improved heuristic, International Conference on Grammatical Inference (ICGI) 2023, Rabat, Morocco. It has been extended with a formal proof on PAC-bounds, and the discussion and analysis of a similar approach has been moved from the appendix and now has a full dedicated section. State machine models are models that simulate the behavior of discrete event systems, capable of representing systems such as software systems, network interactions, and control systems, and have been researched extensively. The nature of most learning algorithms however is the assumption that all data be available at the beginning of the algorithm, and little research has been done in learning state machines from streaming data. In this paper, we want to close this gap further by presenting a generic method for learning state machines from data streams, as well as a merge heuristic that uses sketches to account for incomplete prefix trees. We implement our approach in an open-source state merging library and compare it with existing methods. We show the effectiveness of our approach with respect to run-time, memory consumption, and quality of results on a well known open dataset. Additionally, we provide a formal analysis of our algorithm, showing that it is capable of learning within the PAC framework, and show a theoretical improvement to increase run-time, without sacrificing correctness of the algorithm in larger sample sizes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a generic streaming algorithm for learning PDFAs via state merging on data streams, using a sketch-based heuristic to handle incomplete prefix trees. It includes an open-source implementation, empirical comparisons on a standard dataset for runtime/memory/quality, a formal PAC analysis claiming learnability within PAC bounds, and a theoretical runtime improvement that preserves correctness for large samples.
Significance. If the PAC analysis holds, the work would advance streaming automata learning by closing the gap between batch state-merging methods and online settings, with practical benefits for modeling discrete-event systems. The open-source library, empirical evaluation, and explicit PAC proof are strengths that would make the contribution notable in formal language learning.
major comments (2)
- [Formal PAC Analysis] Formal PAC Analysis section: the proof sketch assumes that merge decisions based on frequency comparisons are exact (or controlled solely by the PAC sample size n and delta), but the sketch heuristic introduces additive approximation error of order 1/w. This error is not bounded relative to the minimum distribution gap in the analysis, so the probability of incorrect merges (and thus failure to achieve epsilon-closeness) can exceed delta even when the exact-count version succeeds. A revised sample-complexity bound incorporating w and the number of candidate pairs is needed.
- [Theoretical Improvement] Section on theoretical runtime improvement: the claim that the improvement increases runtime without sacrificing correctness for larger samples relies on the same merge heuristic; if sketch errors invalidate merges, the correctness preservation does not follow. Please clarify how the improvement interacts with the PAC guarantee.
minor comments (2)
- [Abstract] Abstract: the statement that the approach is 'capable of learning within the PAC framework' should be qualified to note that it holds under the sketch approximation assumptions made explicit in the analysis.
- [Implementation and Experiments] The manuscript mentions an open-source state merging library but provides no repository link, version, or exact name in the text; this should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below and revise the formal analysis and related sections accordingly.
read point-by-point responses
-
Referee: [Formal PAC Analysis] Formal PAC Analysis section: the proof sketch assumes that merge decisions based on frequency comparisons are exact (or controlled solely by the PAC sample size n and delta), but the sketch heuristic introduces additive approximation error of order 1/w. This error is not bounded relative to the minimum distribution gap in the analysis, so the probability of incorrect merges (and thus failure to achieve epsilon-closeness) can exceed delta even when the exact-count version succeeds. A revised sample-complexity bound incorporating w and the number of candidate pairs is needed.
Authors: We agree that the current proof sketch does not explicitly incorporate the additive approximation error of order 1/w from the sketches. In the revised manuscript we will strengthen the PAC analysis by deriving a modified sample-complexity bound that accounts for this error. The bound will be expressed in terms of the sketch width w, the minimum distribution gap, and a union bound over the (polynomially many) candidate merge pairs, ensuring that the overall probability of an incorrect merge remains below delta. revision: yes
-
Referee: [Theoretical Improvement] Section on theoretical runtime improvement: the claim that the improvement increases runtime without sacrificing correctness for larger samples relies on the same merge heuristic; if sketch errors invalidate merges, the correctness preservation does not follow. Please clarify how the improvement interacts with the PAC guarantee.
Authors: We acknowledge the need for explicit clarification. The runtime improvement is intended for regimes in which the sample size n is large enough that the sketch error 1/w is dominated by the distribution gaps used in the PAC analysis. In the revision we will add a precise statement of the parameter regime (relating n, w, and the minimum gap) under which the improved procedure inherits the same PAC guarantee as the base algorithm, together with a short argument showing that erroneous merges due to sketches are absorbed into the existing delta term. revision: yes
Circularity Check
Minor self-citation to prior conference version; PAC analysis is an independent extension
specific steps
-
self citation load bearing
[Abstract]
"This is an extended version of our publication Learning state machines from data streams: A generic strategy and an improved heuristic, International Conference on Grammatical Inference (ICGI) 2023, Rabat, Morocco. It has been extended with a formal proof on PAC-bounds"
The core algorithm originates in the authors' prior self-publication; the new PAC analysis is described as an extension rather than derived from first principles within this manuscript alone. However, because the PAC proof is explicitly added as novel content and does not reduce the learning guarantee to the prior paper's fitted heuristics, the self-citation remains non-load-bearing.
full rationale
The paper is an extended version of the authors' own ICGI 2023 work, with the new formal PAC proof added here. No derivation step reduces a claimed prediction or bound to a fitted parameter or to the self-citation by construction. The streaming state-merging algorithm and sketch heuristic are presented as a generic strategy whose correctness under PAC is analyzed separately using standard sample-complexity arguments. The self-citation is therefore minor and non-load-bearing for the central PAC claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Association for Computing Machinery. ISBN 1581138857. doi: 10.1145/997817. 997857. URLhttps://doi-org.tudelft.idm.oclc.org/10.1145/997817.997857. B. de Balle Pigem, R.G. Mestre, and Universitat Polit` ecnica de Catalunya. Departament de Llenguatges i Sistemes Inform` atics.Learning Finite-state Machines: Statistical and Algorithmic Aspects. PhD thesis, 20...
-
[2]
Springer-Verlag. ISBN 3540242880. doi: 10.1007/978-3-540-30570-5 27. URL https://doi.org/10.1007/978-3-540-30570-5_27. Nicholas Nethercote and Julian Seward. Valgrind: A framework for heavyweight dynamic binary instrumentation.SIGPLAN Not., 42(6):89–100, jun 2007. ISSN 0362-1340. doi: 10.1145/1273442.1250746. URLhttps://doi.org/10.1145/1273442.1250746. A....
-
[3]
doi: 10.1007/s10994-013-5409-9
ISSN 15730565. doi: 10.1007/s10994-013-5409-9. URLhttp://ai.cs.umbc.edu/ icgi2012/challenge/Pautomac/committee.php. Asmir Vodenˇ carevi´ c, Hans Kleine B¨ urring, Oliver Niggemann, and Alexander Maier. Iden- tifying behavior models for process plants. InETFA2011, pages 1–8, 2011. doi: 10.1109/ETFA.2011.6059080. Neil Walkinshaw, Ramsay Taylor, and John Der...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.