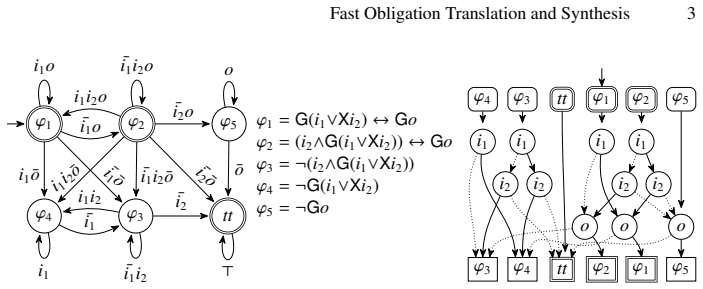
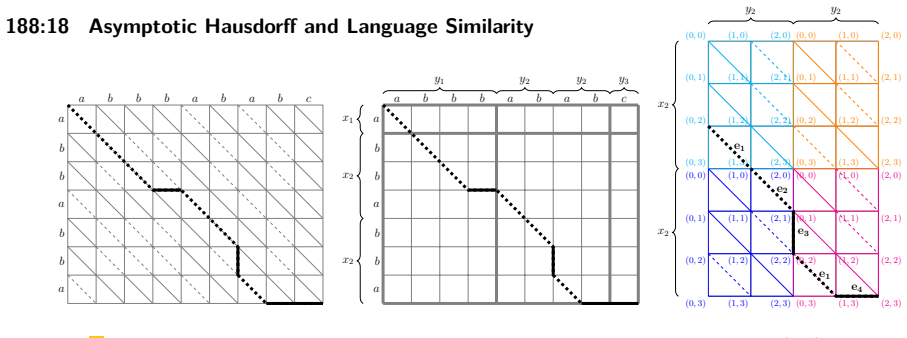
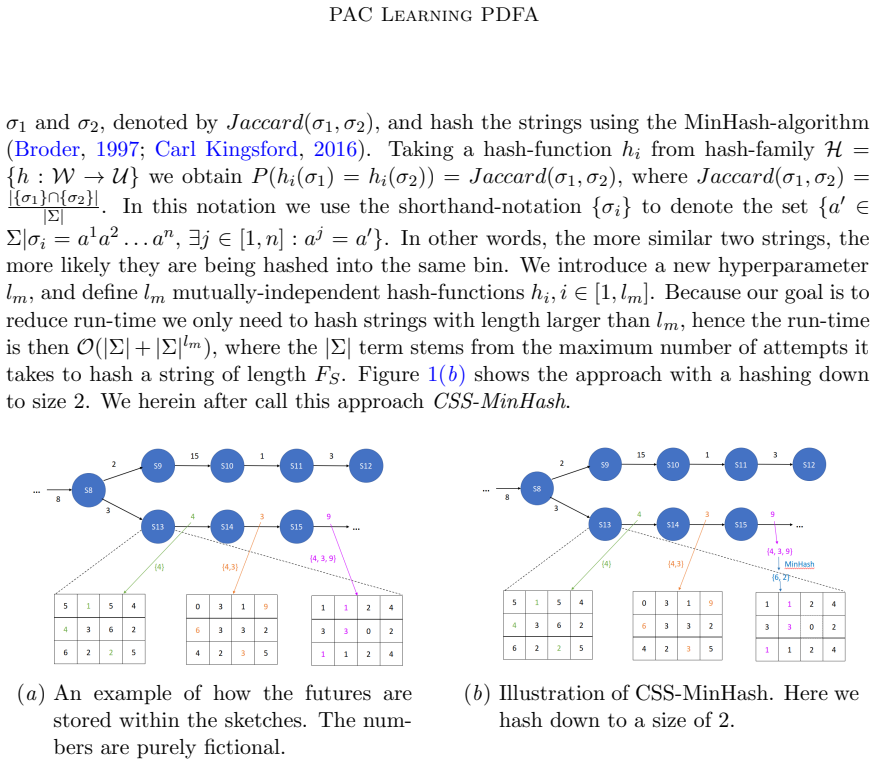
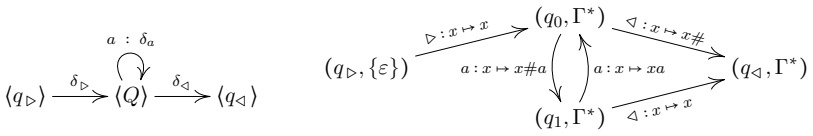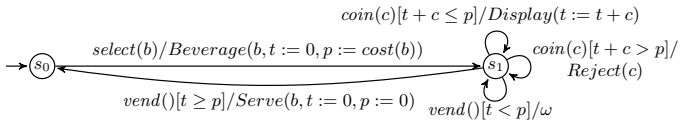0
Conventions enable composition of policies for multiple omega-regular goals
Decoupled Planning for Multiple Omega-Regular Objectives
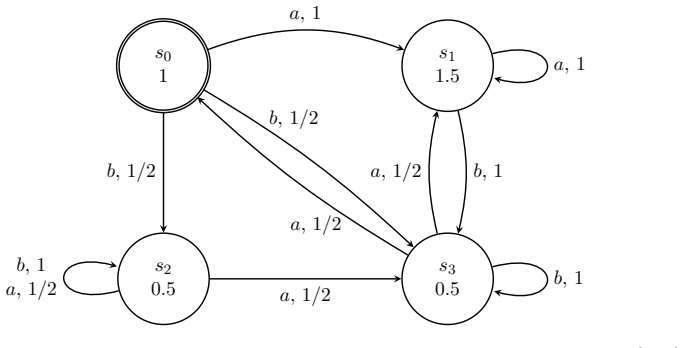
Büchi needs no scheduler info while parity requires knowing which agent is active to ensure all goals are met.
 full image
full image
abstract click to expand
We study the problem of generating paths on a graph that satisfy a collection of {\omega}-regular objectives. We propose a decoupled framework in which each objective is assigned to an independent agent that selects a local policy, while a scheduler -- oblivious to the graph and objective -- dynamically composes these policies into a single path. We ask when such a composition satisfies all objectives, assuming their conjunction is realizable. The framework enables modular policy design but raises fundamental compositional challenges. We show that even extremely fair deterministic schedulers do not ensure correctness, and that stochastic schedulers, while necessary, are insufficient without coordination. For safety objectives, we demonstrate that fully decentralized implementations are impossible, and we introduce a protocol for synchronizing on maximal safe actions. For non-safety objectives, we introduce conventions -- simple, a priori restrictions agreed upon before the graph or objectives are revealed -- that guarantee satisfaction of all objectives when followed by all agents. We characterize minimally restrictive conventions for major subclasses of {\omega}-regular objectives. In particular, B\"uchi objectives admit universal composition of finite-memory policies without scheduler communication; co-B\"uchi objectives require only knowledge of whether the agent was scheduled; and parity objectives additionally require knowledge of which agent was scheduled.