Recognition: no theorem link
No Single Best Model for Diversity: Learning a Router for Sample Diversity
Pith reviewed 2026-05-13 21:46 UTC · model grok-4.3
The pith
A router that predicts the best model for each query outperforms any fixed LLM at generating diverse answer sets to open-ended prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
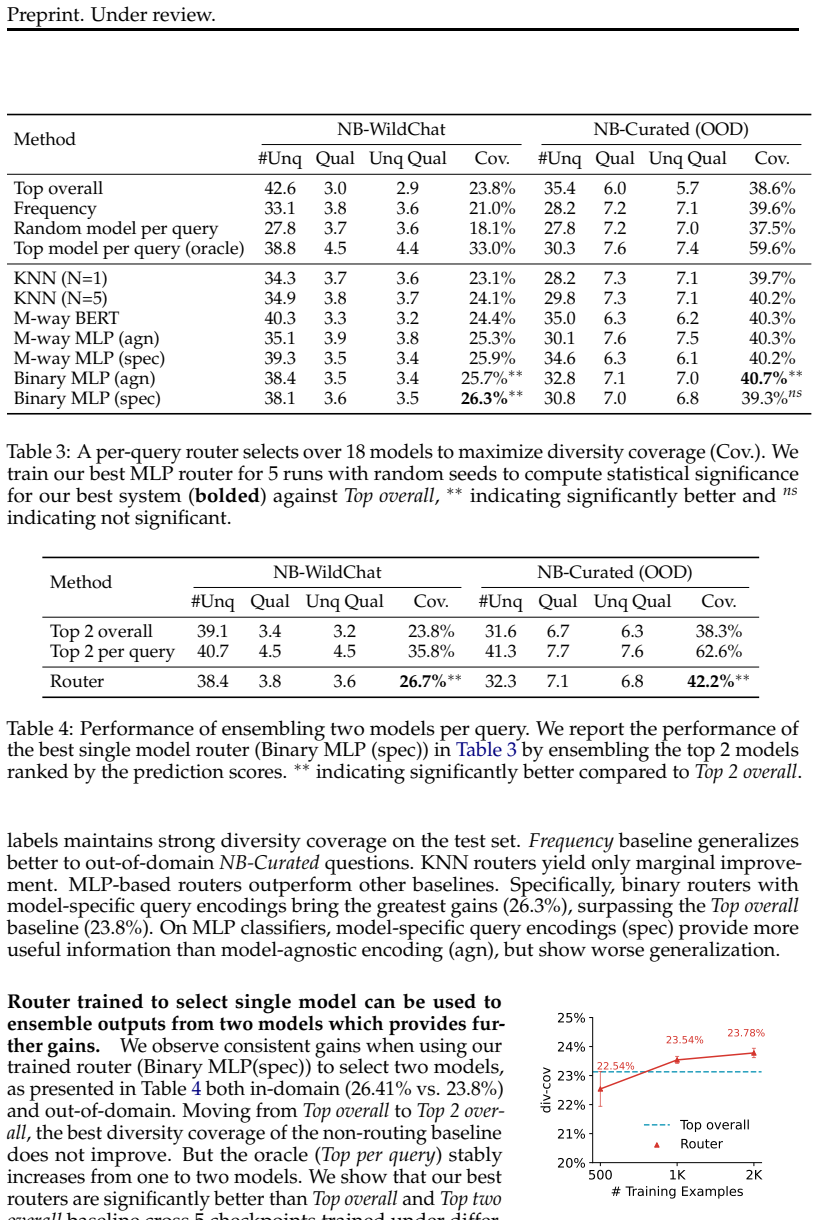
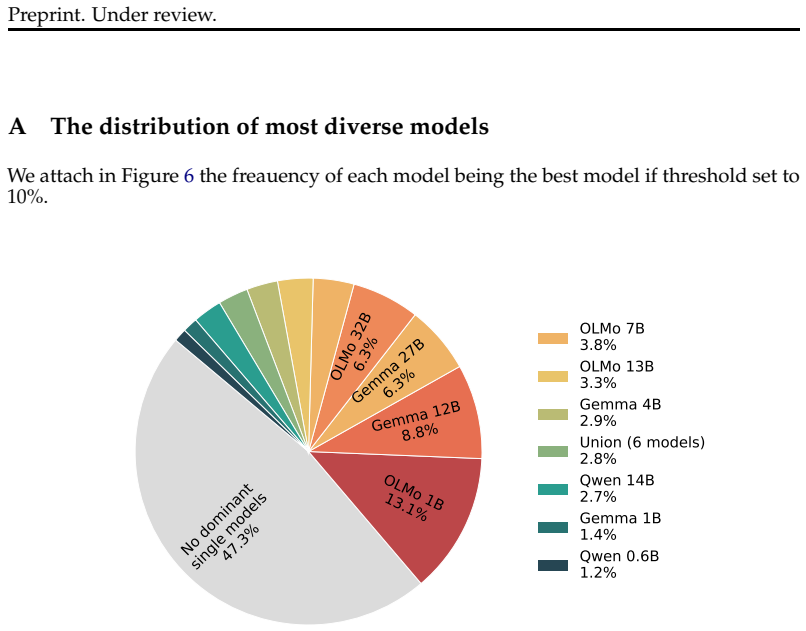
Evaluating 18 LLMs on prompts that permit many valid answers reveals no single model dominates at generating diverse responses. However, for each prompt there exists a model that significantly outperforms the others in producing a comprehensive answer set, as measured by diversity coverage. This motivates training a router to select the best model per query, which improves performance from 23.8% to 26.3% on the NB-Wildchat dataset and generalizes to out-of-domain data and alternative generation strategies.
What carries the argument
A trained router that predicts the best LLM for maximizing diversity coverage on a given prompt.
Load-bearing premise
The router trained on observed model performances can reliably predict the optimal model for new prompts and that diversity coverage scores reflect meaningful differences in how comprehensively users experience the answer sets.
What would settle it
On a fresh collection of prompts, if the router-selected models produce lower average diversity coverage than the single best fixed model, the central claim of reliable improvement would be refuted.
Figures


















read the original abstract
When posed with prompts that permit a large number of valid answers, comprehensively generating them is the first step towards satisfying a wide range of users. In this paper, we study methods to elicit a comprehensive set of valid responses. To evaluate this, we introduce \textbf{diversity coverage}, a metric that measures the total quality scores assigned to each \textbf{unique} answer in the predicted answer set relative to the best possible answer set with the same number of answers. Using this metric, we evaluate 18 LLMs, finding no single model dominates at generating diverse responses to a wide range of open-ended prompts. Yet, per each prompt, there exists a model that outperforms all other models significantly at generating a diverse answer set. Motivated by this finding, we introduce a router that predicts the best model for each query. On NB-Wildchat, our trained router outperforms the single best model baseline (26.3% vs $23.8%). We further show generalization to an out-of-domain dataset (NB-Curated) as well as different answer-generation prompting strategies. Our work lays foundation for studying generating comprehensive answers when we have access to a suite of models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that no single LLM among 18 evaluated models dominates at generating diverse responses to open-ended prompts, but that a per-prompt best model exists; it introduces a 'diversity coverage' metric (sum of quality scores of unique answers relative to an oracle top-k set of equal size) and trains a router that selects the best model per query, reporting 26.3% coverage versus 23.8% for the single-best baseline on NB-Wildchat with generalization to NB-Curated and varied prompting strategies.
Significance. If the diversity coverage metric is shown to be reliable, the work provides empirical evidence against a universal best model for diversity and demonstrates that lightweight routing can yield measurable gains in comprehensive answer generation, which is a practical contribution for multi-model serving systems. The absence of a single dominant model and the router's reported lift are the core findings.
major comments (3)
- [Abstract] Abstract: the diversity coverage metric is defined only at a high level as summing quality scores of unique answers relative to an oracle top-k set; the manuscript must specify (1) the exact criterion for uniqueness (embedding cosine threshold, exact string match, etc.) and (2) the procedure for obtaining per-answer quality scores (LLM judge prompt, reference-free scoring, etc.). These details are load-bearing for the 26.3% vs 23.8% headline result and all generalization claims.
- [Abstract] Abstract and evaluation sections: no human validation or correlation study is reported for the automated diversity coverage metric against human judgments of answer-set comprehensiveness. Without such validation, the router's training labels and the reported out-of-domain gains rest on an untested assumption.
- [Abstract] Abstract: the router is said to be 'trained' on per-prompt performance, yet no details are given on training data construction, input features, model architecture, or held-out evaluation protocol. This information is required to assess whether the 2.5-point improvement is statistically reliable and whether the generalization results are robust.
minor comments (2)
- The paper should cite prior work on model routing (e.g., mixture-of-experts routing, LLM routing papers) and existing diversity metrics to clarify the novelty of the proposed coverage measure.
- Notation for the diversity coverage formula should be introduced formally with an equation rather than only in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and will revise the manuscript to incorporate clarifications and additional details where needed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the diversity coverage metric is defined only at a high level as summing quality scores of unique answers relative to an oracle top-k set of equal size; the manuscript must specify (1) the exact criterion for uniqueness (embedding cosine threshold, exact string match, etc.) and (2) the procedure for obtaining per-answer quality scores (LLM judge prompt, reference-free scoring, etc.). These details are load-bearing for the 26.3% vs 23.8% headline result and all generalization claims.
Authors: We agree that the abstract provides only a high-level overview and that precise specifications are essential for reproducibility. The full manuscript describes these components in the evaluation section, but we will revise the abstract to explicitly state the uniqueness criterion (cosine similarity threshold on sentence embeddings) and the quality scoring procedure (reference-free LLM judge). We will also move the full implementation details, including the exact prompt and threshold, to the main text and appendix in the revised version. revision: yes
-
Referee: [Abstract] Abstract and evaluation sections: no human validation or correlation study is reported for the automated diversity coverage metric against human judgments of answer-set comprehensiveness. Without such validation, the router's training labels and the reported out-of-domain gains rest on an untested assumption.
Authors: We acknowledge the importance of validating the automated metric against human judgments. No such study was included in the original submission. We will add a small-scale human evaluation on a subset of prompts in the revised manuscript, reporting correlation between diversity coverage scores and human ratings of answer-set comprehensiveness. This will be placed in the evaluation section to support the metric's reliability. revision: yes
-
Referee: [Abstract] Abstract: the router is said to be 'trained' on per-prompt performance, yet no details are given on training data construction, input features, model architecture, or held-out evaluation protocol. This information is required to assess whether the 2.5-point improvement is statistically reliable and whether the generalization results are robust.
Authors: We agree that additional details on the router are required to assess reliability. We will add a dedicated methods subsection describing the training data construction (labels derived from per-prompt diversity coverage across the 18 models on the training split), input features (prompt embeddings), model architecture (lightweight classifier), and held-out evaluation protocol (cross-validation with significance testing). These additions will directly address concerns about the reported improvement and generalization. revision: yes
Circularity Check
No circularity: router is a standard supervised predictor trained on held-out labels
full rationale
The paper first computes diversity coverage on a training split to label the per-prompt best model, then trains a router (presumably a classifier or regressor over prompt features) to predict that label, and finally reports router performance on a held-out test split (NB-Wildchat) plus out-of-domain sets. This is ordinary supervised learning; the test-set lift (26.3 % vs 23.8 %) is not forced by construction because the router never sees the test labels during training. No equations reduce a claimed prediction to a fitted parameter, no self-citation supplies a uniqueness theorem, and the diversity-coverage definition is used only to generate training labels, not to tautologically reproduce the test metric. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
No Single Best Model for Diversity: Learning a Router for Sample Diversity
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.