Recognition: no theorem link
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Pith reviewed 2026-05-13 21:29 UTC · model grok-4.3
The pith
Pretraining on one million in-the-wild videos followed by post-training on curated data produces high-fidelity full-body 3D avatars that generalize across identities and styles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors demonstrate that pretraining a 3D avatar model on 1M in-the-wild videos learns general priors over appearance and geometry; subsequent post-training on high-quality curated data then improves expressivity and fidelity. The resulting LCA model generalizes across hair styles, clothing, and demographics, supplies precise facial expressions and finger-level articulation, and maintains strong identity preservation. It also exhibits emergent capabilities such as relightability and loose-garment support on unconstrained inputs, together with zero-shot robustness to stylized imagery, all without direct supervision for those properties.
What carries the argument
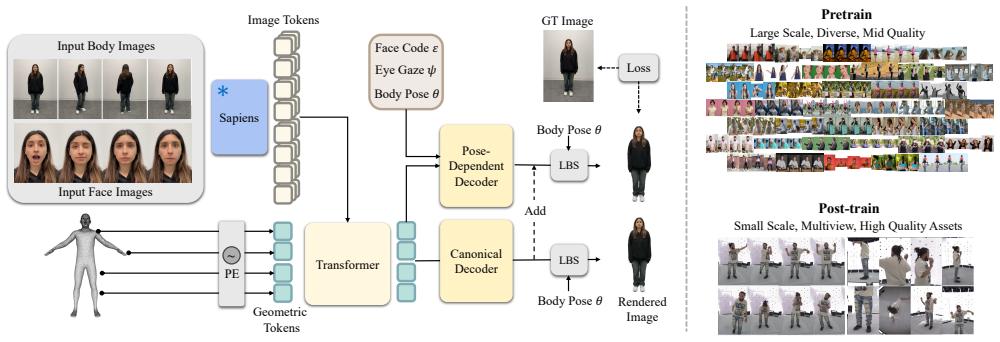
the pre/post-training paradigm for Large-scale Codec Avatars (LCA), in which pretraining on 1M in-the-wild videos supplies broad appearance and geometry priors that post-training on high-quality data then sharpens for expressivity and control
If this is right
- Avatars achieve precise fine-grained control over facial expressions and finger articulations.
- The model generalizes across hair styles, clothing, and demographic groups while preserving identity.
- Emergent support appears for relighting and loose garments on unconstrained inputs.
- Zero-shot robustness to stylized imagery occurs without explicit training for that case.
- Full-body avatars can be generated in a single feedforward pass at inference time.
Where Pith is reading between the lines
- The two-stage recipe suggests that data-scale benefits observed in language and 2D vision models may extend to 3D human modeling.
- Casual video capture could become sufficient for creating personalized avatars, reducing the need for per-person studio sessions.
- The feedforward design opens straightforward integration into real-time virtual environments that must handle varied real-world lighting and clothing.
Load-bearing premise
Pretraining on 1M in-the-wild videos produces priors that transfer cleanly to high-fidelity post-training without residual domain-gap artifacts or loss of fine control.
What would settle it
A controlled comparison in which post-trained avatars show measurable drops in finger articulation accuracy or identity preservation on held-out demographic groups relative to a high-quality-only baseline would falsify the transfer claim.
Figures






read the original abstract
High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Large-Scale Codec Avatars (LCA), a high-fidelity full-body 3D avatar model that employs a pre/post-training paradigm: pretraining on 1M in-the-wild videos to acquire broad priors on appearance and geometry, followed by post-training on high-quality curated data to boost expressivity and fidelity. It claims generalization across hair styles, clothing, and demographics, precise facial expressions and finger-level control, strong identity preservation, and emergent properties such as relightability, loose garment support, and zero-shot robustness to stylized imagery without direct supervision.
Significance. If validated with quantitative evidence, this pre/post-training approach could be significant for 3D avatar modeling by bridging the scale of in-the-wild data with studio fidelity, potentially enabling more generalizable feedforward avatar systems for real-world applications.
major comments (2)
- [Abstract] Abstract: The claims of precise fine-grained facial expressions, finger-level articulation control, and emergent generalization (relightability, loose garments, stylized robustness) are stated qualitatively but supply no quantitative metrics, baselines, ablation studies, or error analysis to isolate the pretraining contribution or measure domain-gap closure.
- [Training paradigm description] Training paradigm description: The pre/post-training procedure is outlined at a high level with no details on stage integration (weight freezing, learning-rate schedules, regularization to prevent forgetting, or loss weighting), which is load-bearing for the central claim that broad priors from 1M in-the-wild videos transfer cleanly without residual geometry or appearance inconsistencies.
minor comments (1)
- [Abstract] The phrase 'world-scale populations' is imprecise; specifying the demographic coverage or diversity statistics of the 1M-video pretraining set would strengthen the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting areas where additional evidence and detail would strengthen the central claims. We will revise the manuscript to incorporate quantitative metrics, ablations, and expanded training details as outlined below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of precise fine-grained facial expressions, finger-level articulation control, and emergent generalization (relightability, loose garments, stylized robustness) are stated qualitatively but supply no quantitative metrics, baselines, ablation studies, or error analysis to isolate the pretraining contribution or measure domain-gap closure.
Authors: We agree that the abstract is primarily qualitative and that stronger quantitative support is needed to substantiate the claims and isolate the pretraining effect. The full manuscript contains qualitative demonstrations and some comparative results, but lacks dedicated ablations and error analysis for domain-gap closure. In the revision we will add quantitative metrics (e.g., expression and pose reconstruction errors, identity preservation scores), baselines against prior avatar models, and ablation studies that measure the contribution of the 1M-video pretraining stage, including analysis of residual inconsistencies. revision: yes
-
Referee: [Training paradigm description] Training paradigm description: The pre/post-training procedure is outlined at a high level with no details on stage integration (weight freezing, learning-rate schedules, regularization to prevent forgetting, or loss weighting), which is load-bearing for the central claim that broad priors from 1M in-the-wild videos transfer cleanly without residual geometry or appearance inconsistencies.
Authors: We acknowledge that the current description of the pre/post-training pipeline is high-level and does not specify the integration mechanics. In the revised manuscript we will expand the methods section with concrete details on weight freezing (or lack thereof), learning-rate schedules across stages, regularization terms used to mitigate forgetting, and the loss-weighting scheme between pretraining and post-training objectives. These additions will directly address how the broad priors are preserved without introducing geometry or appearance inconsistencies. revision: yes
Circularity Check
No circularity: empirical pre/post-training pipeline is self-contained
full rationale
The paper presents a standard two-stage neural network training procedure—pretrain a codec avatar model on 1M in-the-wild videos, then post-train on curated high-quality captures—without any equations, uniqueness theorems, or fitted parameters that reduce the reported generalization or fidelity claims to quantities defined inside the paper itself. All performance assertions rest on external experimental outcomes (reconstruction metrics, qualitative results on held-out data) rather than algebraic identities or self-referential definitions. No load-bearing self-citations, ansatzes smuggled via prior work, or renamings of known results appear in the provided text; the method is therefore independently falsifiable by re-running the training pipeline on the stated data splits.
Axiom & Free-Parameter Ledger
free parameters (1)
- Pretraining dataset size
axioms (1)
- domain assumption Pretraining on in-the-wild videos learns broad priors over appearance and geometry that transfer to high-fidelity post-training
Forward citations
Cited by 1 Pith paper
-
GenLCA: 3D Diffusion for Full-Body Avatars from In-the-Wild Videos
GenLCA enables scalable training of a 3D diffusion model for photorealistic, animatable full-body avatars by tokenizing large-scale real-world videos with a pretrained reconstructor and applying visibility-aware diffu...
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Oleg Alexander, Mike Rogers, William Lambeth, Jen-Yuan Chiang, Wan-Chun Ma, Chuan-Chang Wang, and Paul De- bevec. The digital emily project: Achieving a photorealistic digital actor.IEEE Computer Graphics and Applications, 30 (4):20–31, 2010. 3
work page 2010
-
[3]
Driving-signal aware full-body avatars.ACM Transactions on Graphics (TOG), 40(4):1–17,
Timur Bagautdinov, Chenglei Wu, Tomas Simon, Fabian Prada, Takaaki Shiratori, Shih-En Wei, Weipeng Xu, Yaser Sheikh, and Jason Saragih. Driving-signal aware full-body avatars.ACM Transactions on Graphics (TOG), 40(4):1–17,
-
[4]
Lumiere: A space-time diffu- sion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Her- rmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, et al. Lumiere: A space-time diffu- sion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 2, 3
work page 2024
-
[5]
Sai Bi, Stephen Lombardi, Shunsuke Saito, Tomas Simon, Shih-En Wei, Kevyn Mcphail, Ravi Ramamoorthi, Yaser Sheikh, and Jason Saragih. Deep relightable appearance models for animatable faces.ACM Transactions on Graphics (ToG), 40(4):1–15, 2021. 3, 5
work page 2021
-
[6]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the net- work.arXiv preprint arXiv:2504.13181, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[7]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020. 3
work page 1901
-
[8]
Ge- nie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Ge- nie: Generative interactive environments. InForty-first Inter- national Conference on Machine Learning, 2024. 3
work page 2024
-
[9]
Zeyu Cai, Ziyang Li, Xiaoben Li, Boqian Li, Zeyu Wang, Zhenyu Zhang, and Yuliang Xiu. Up2you: Fast reconstruc- tion of yourself from unconstrained photo collections.arXiv preprint arXiv:2509.24817, 2025. 6
-
[10]
Chen Cao, Tomas Simon, Jin Kyu Kim, Gabe Schwartz, Michael Zollhoefer, Shunsuke Saito, Stephen Lombardi, Shih-En Wei, Danielle Belko, Shoou-I Yu, et al. Authen- tic volumetric avatars from a phone scan.ACM Transactions on Graphics (TOG), 41(4):1–19, 2022. 2
work page 2022
-
[11]
PERSE: per- sonalized 3d generative avatars from A single portrait
Hyunsoo Cha, Inhee Lee, and Hanbyul Joo. PERSE: per- sonalized 3d generative avatars from A single portrait. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 15953–15962. Computer Vision Foundation / IEEE, 2025. 6
work page 2025
-
[12]
Meshavatar: Learning high-quality triangular human avatars from multi-view videos
Yushuo Chen, Zerong Zheng, Zhe Li, Chao Xu, and Yebin Liu. Meshavatar: Learning high-quality triangular human avatars from multi-view videos. InEuropean Conference on Computer Vision, pages 250–269. Springer, 2024. 3
work page 2024
-
[13]
Gang Cheng, Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Ju Li, Dechao Meng, Jinwei Qi, Penchong Qiao, et al. Wan-animate: Unified character animation and replacement with holistic replication.arXiv preprint arXiv:2509.14055, 2025. 3, 7, 2
-
[14]
Kevin G Der, Robert W Sumner, and Jovan Popovi´c. Inverse kinematics for reduced deformable models.ACM Transac- tions on graphics (TOG), 25(3):1174–1179, 2006. 5
work page 2006
-
[15]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805, 2018. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[17]
Fernando A Fardo, Victor H Conforto, Francisco C De Oliveira, and Paulo S Rodrigues. A formal evaluation of psnr as quality measurement parameter for image segmen- tation algorithms.arXiv preprint arXiv:1605.07116, 2016. 6
-
[18]
Mhr: Momentum human rig.arXiv preprint arXiv:2511.15586, 2025
Aaron Ferguson, Ahmed AA Osman, Berta Bescos, Carsten Stoll, Chris Twigg, Christoph Lassner, David Otte, Eric Vig- nola, Fabian Prada, Federica Bogo, et al. Mhr: Momentum human rig.arXiv preprint arXiv:2511.15586, 2025. 1
-
[19]
Dynamic neural radiance fields for monocular 4d facial avatar reconstruction
Guy Gafni, Justus Thies, Michael Zollh ¨ofer, and Matthias Nießner. Dynamic neural radiance fields for monocular 4d facial avatar reconstruction. InIEEE Conference on Com- puter Vision and Pattern Recognition, CVPR 2021, pages 8649–8658. Computer Vision Foundation / IEEE, 2021. 3
work page 2021
-
[20]
Vid2avatar: 3d avatar reconstruction from videos in the wild via self-supervised scene decomposition
Chen Guo, Tianjian Jiang, Xu Chen, Jie Song, and Otmar Hilliges. Vid2avatar: 3d avatar reconstruction from videos in the wild via self-supervised scene decomposition. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12858–12868, 2023. 3
work page 2023
-
[21]
Reloo: Reconstructing humans dressed in loose garments from monocular video in the wild
Chen Guo, Tianjian Jiang, Manuel Kaufmann, Chengwei Zheng, Julien Valentin, Jie Song, and Otmar Hilliges. Reloo: Reconstructing humans dressed in loose garments from monocular video in the wild. InEuropean Conference on Computer Vision, pages 21–38. Springer, 2024. 5
work page 2024
-
[22]
Vid2avatar-pro: Authentic avatar from videos in the wild via universal prior
Chen Guo, Junxuan Li, Yash Kant, Yaser Sheikh, Shunsuke Saito, and Chen Cao. Vid2avatar-pro: Authentic avatar from videos in the wild via universal prior. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5559–5570, 2025. 2, 3
work page 2025
-
[23]
Kaiwen Guo, Peter Lincoln, Philip Davidson, Jay Busch, Xueming Yu, Matt Whalen, Geoff Harvey, Sergio Orts- Escolano, Rohit Pandey, Jason Dourgarian, et al. The re- lightables: V olumetric performance capture of humans with realistic relighting.ACM Transactions on Graphics (ToG), 38(6):1–19, 2019. 3
work page 2019
-
[24]
Diffrelight: Diffusion-based facial performance relighting
Mingming He, Pascal Clausen, Ahmet Levent Tas ¸el, Li Ma, Oliver Pilarski, Wenqi Xian, Laszlo Rikker, Xueming Yu, Ryan Burgert, Ning Yu, et al. Diffrelight: Diffusion-based facial performance relighting. InSIGGRAPH Asia 2024 Conference Papers, pages 1–12, 2024. 3
work page 2024
-
[25]
Lam: Large avatar model for one-shot animatable gaus- sian head
Yisheng He, Xiaodong Gu, Xiaodan Ye, Chao Xu, Zhengyi Zhao, Yuan Dong, Weihao Yuan, Zilong Dong, and Liefeng Bo. Lam: Large avatar model for one-shot animatable gaus- sian head. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–13, 2025. 2
work page 2025
-
[26]
Animate anyone: Consistent and controllable image- to-video synthesis for character animation
Li Hu. Animate anyone: Consistent and controllable image- to-video synthesis for character animation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8153–8163, 2024. 3
work page 2024
-
[27]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lam- ple, Lucile Saulnier, et al. Mistral 7b.arXiv preprint arXiv:2310.06825, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
In- stantavatar: Learning avatars from monocular video in 60 seconds
Tianjian Jiang, Xu Chen, Jie Song, and Otmar Hilliges. In- stantavatar: Learning avatars from monocular video in 60 seconds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16922– 16932, 2023. 3
work page 2023
-
[29]
Neuman: Neural human radiance field from a single video
Wei Jiang, Kwang Moo Yi, Golnoosh Samei, Oncel Tuzel, and Anurag Ranjan. Neuman: Neural human radiance field from a single video. InEuropean Conference on Computer Vision, pages 402–418. Springer, 2022. 3
work page 2022
-
[30]
Yuheng Jiang, Zhehao Shen, Yu Hong, Chengcheng Guo, Yize Wu, Yingliang Zhang, Jingyi Yu, and Lan Xu. Robust dual gaussian splatting for immersive human-centric volu- metric videos.ACM Transactions on Graphics (TOG), 43 (6):1–15, 2024. 5
work page 2024
-
[31]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4):1–14, 2023. 2
work page 2023
-
[32]
Sapiens: Foundation for human vision mod- els
Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, Su Zhaoen, Austin James, Peter Selednik, Stuart Anderson, and Shunsuke Saito. Sapiens: Foundation for human vision mod- els. InEuropean Conference on Computer Vision, pages 206–228. Springer, 2024. 2, 3, 5, 6, 1
work page 2024
-
[33]
Personabooth: Per- sonalized text-to-motion generation
Boeun Kim, Hea In Jeong, JungHoon Sung, Yihua Cheng, Jeongmin Lee, Ju Yong Chang, Sang-Il Choi, Younggeun Choi, Saim Shin, Jungho Kim, et al. Personabooth: Per- sonalized text-to-motion generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22756–22765, 2025. 3
work page 2025
-
[34]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Uravatar: Universal relightable gaussian codec avatars
Junxuan Li, Chen Cao, Gabriel Schwartz, Rawal Khirodkar, Christian Richardt, Tomas Simon, Yaser Sheikh, and Shun- suke Saito. Uravatar: Universal relightable gaussian codec avatars. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 2, 3
work page 2024
-
[36]
Tava: Template-free animatable volumetric actors
Ruilong Li, Julian Tanke, Minh V o, Michael Zollh ¨ofer, J¨urgen Gall, Angjoo Kanazawa, and Christoph Lassner. Tava: Template-free animatable volumetric actors. InEu- ropean Conference on Computer Vision, pages 419–436. Springer, 2022. 2
work page 2022
-
[37]
Zhe Li, Zerong Zheng, Lizhen Wang, and Yebin Liu. Ani- matable gaussians: Learning pose-dependent gaussian maps for high-fidelity human avatar modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19711–19722, 2024. 3
work page 2024
-
[38]
Learning implicit templates for point-based clothed human modeling
Siyou Lin, Hongwen Zhang, Zerong Zheng, Ruizhi Shao, and Yebin Liu. Learning implicit templates for point-based clothed human modeling. InEuropean Conference on Com- puter Vision, pages 210–228. Springer, 2022. 5
work page 2022
-
[39]
Lucas: Layered universal codec avatars
Di Liu, Teng Deng, Giljoo Nam, Yu Rong, Stanislav Pid- horskyi, Junxuan Li, Jason Saragih, Dimitris N Metaxas, and Chen Cao. Lucas: Layered universal codec avatars. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 21127–21137, 2025. 2
work page 2025
-
[40]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Shugao Ma, Tomas Simon, Jason Saragih, Dawei Wang, Yuecheng Li, Fernando De La Torre, and Yaser Sheikh. Pixel codec avatars. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 64–73,
-
[42]
Julieta Martinez, Emily Kim, Javier Romero, Timur Bagaut- dinov, Shunsuke Saito, Shoou-I Yu, Stuart Anderson, Michael Zollh ¨ofer, Te-Li Wang, Shaojie Bai, et al. Codec avatar studio: Paired human captures for complete, drive- able, and generalizable avatars.Advances in Neural Infor- mation Processing Systems, 37:83008–83023, 2024. 2, 3, 5
work page 2024
-
[43]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 3
work page 2021
-
[44]
Expressive whole-body 3d gaussian avatar
Gyeongsik Moon, Takaaki Shiratori, and Shunsuke Saito. Expressive whole-body 3d gaussian avatar. InEuropean Conference on Computer Vision, pages 19–35. Springer,
-
[45]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022. 3
work page 2022
-
[46]
Predicting loose-fitting garment defor- mations using bone-driven motion networks
Xiaoyu Pan, Jiaming Mai, Xinwei Jiang, Dongxue Tang, Jingxiang Li, Tianjia Shao, Kun Zhou, Xiaogang Jin, and Dinesh Manocha. Predicting loose-fitting garment defor- mations using bone-driven motion networks. InACM SIG- GRAPH 2022 conference proceedings, pages 1–10, 2022. 5
work page 2022
-
[47]
Atlas: Decoupling skeletal and shape parameters for expressive parametric hu- man modeling
Jinhyung Park, Javier Romero, Shunsuke Saito, Fabian Prada, Takaaki Shiratori, Yichen Xu, Federica Bogo, Shoou- I Yu, Kris Kitani, and Rawal Khirodkar. Atlas: Decoupling skeletal and shape parameters for expressive parametric hu- man modeling. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 6508–6518,
-
[48]
Ani- matable neural radiance fields for modeling dynamic human bodies
Sida Peng, Junting Dong, Qianqian Wang, Shangzhan Zhang, Qing Shuai, Xiaowei Zhou, and Hujun Bao. Ani- matable neural radiance fields for modeling dynamic human bodies. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 14314–14323, 2021. 3
work page 2021
-
[49]
Gaus- sianavatars: Photorealistic head avatars with rigged 3d gaus- sians
Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, and Matthias Nießner. Gaus- sianavatars: Photorealistic head avatars with rigged 3d gaus- sians. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 20299–20309,
-
[50]
LHM: large animatable human reconstruction model from a single image in seconds
Lingteng Qiu, Xiaodong Gu, Peihao Li, Qi Zuo, Weichao Shen, Junfei Zhang, Kejie Qiu, Weihao Yuan, Guanying Chen, Zilong Dong, and Liefeng Bo. LHM: large animatable human reconstruction model from a single image in seconds. CoRR, abs/2503.10625, 2025. 2, 3, 4, 5, 6, 7, 1
-
[51]
Lingteng Qiu, Peihao Li, Qi Zuo, Xiaodong Gu, Yuan Dong, Weihao Yuan, Siyu Zhu, Xiaoguang Han, Guanying Chen, and Zilong Dong. Pf-lhm: 3d animatable avatar reconstruc- tion from pose-free articulated human images.arXiv preprint arXiv:2506.13766, 2025. 2, 5
-
[52]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023. 3
work page 2023
-
[53]
Relightable gaussian codec avatars
Shunsuke Saito, Gabriel Schwartz, Tomas Simon, Junxuan Li, and Giljoo Nam. Relightable gaussian codec avatars. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 130–141, 2024. 2, 3
work page 2024
-
[54]
Exploring multimodal diffusion transform- ers for enhanced prompt-based image editing
Joonghyuk Shin, Alchan Hwang, Yujin Kim, Daneul Kim, and Jaesik Park. Exploring multimodal diffusion transform- ers for enhanced prompt-based image editing. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 19492–19502, 2025. 2
work page 2025
-
[55]
Persona: Personalized whole-body 3d avatar with pose-driven deformations from a single image
Geonhee Sim and Gyeongsik Moon. Persona: Personalized whole-body 3d avatar with pose-driven deformations from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12670–12680, 2025. 3, 6
work page 2025
-
[56]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Em- bedded deformation for shape manipulation
Robert W Sumner, Johannes Schmid, and Mark Pauly. Em- bedded deformation for shape manipulation. InACM sig- graph 2007 papers, pages 80–es. 2007. 5
work page 2007
-
[58]
Tiancheng Sun, Zexiang Xu, Xiuming Zhang, Sean Fanello, Christoph Rhemann, Paul Debevec, Yun-Ta Tsai, Jonathan T Barron, and Ravi Ramamoorthi. Light stage super- resolution: continuous high-frequency relighting.ACM Transactions on Graphics (TOG), 39(6):1–12, 2020. 3
work page 2020
-
[59]
Scale efficiently: Insights from pre-training and fine-tuning transformers
Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, and Donald Metzler. Scale effi- ciently: Insights from pre-training and fine-tuning transform- ers.arXiv preprint arXiv:2109.10686, 2021. 3
-
[60]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 2, 4, 1
work page 2025
-
[65]
Ruihe Wang, Yukang Cao, Kai Han, and Kwan-Yee K Wong. A survey on 3d human avatar modeling–from reconstruction to generation.arXiv preprint arXiv:2406.04253, 2024. 3
-
[66]
Relightable full-body gaussian codec avatars
Shaofei Wang, Tomas Simon, Igor Santesteban, Timur Bagautdinov, Junxuan Li, Vasu Agrawal, Fabian Prada, Shoou-I Yu, Pace Nalbone, Matt Gramlich, et al. Relightable full-body gaussian codec avatars. InProceedings of the Special Interest Group on Computer Graphics and Interac- tive Techniques Conference Conference Papers, pages 1–12,
-
[67]
Zhenzhen Weng, Jingyuan Liu, Hao Tan, Zhan Xu, Yang Zhou, Serena Yeung-Levy, and Jimei Yang. Template-free single-view 3d human digitalization with diffusion-guided lrm.arXiv preprint arXiv:2401.12175, 2024. 3
-
[68]
Jingjing Xu, Xu Sun, Zhiyuan Zhang, Guangxiang Zhao, and Junyang Lin. Understanding and improving layer normaliza- tion.Advances in neural information processing systems, 32,
-
[69]
Sicheng Xu, Guojun Chen, Yu-Xiao Guo, Jiaolong Yang, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong, and Baining Guo. Vasa-1: Lifelike audio-driven talking faces generated in real time.Advances in Neural Information Pro- cessing Systems, 37:660–684, 2024. 2
work page 2024
-
[70]
Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians
Yuelang Xu, Benwang Chen, Zhe Li, Hongwen Zhang, Lizhen Wang, Zerong Zheng, and Yebin Liu. Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 1931–1941, 2024. 2
work page 1931
-
[71]
Towards practical capture of high-fidelity relightable avatars
Haotian Yang, Mingwu Zheng, Wanquan Feng, Haibin Huang, Yu-Kun Lai, Pengfei Wan, Zhongyuan Wang, and Chongyang Ma. Towards practical capture of high-fidelity relightable avatars. InSIGGRAPH Asia 2023 Conference Papers, pages 1–11, 2023. 3
work page 2023
-
[72]
Kevin Yu, Gleb Gorbachev, Ulrich Eck, Frieder Pankratz, Nassir Navab, and Daniel Roth. Avatars for teleconsultation: Effects of avatar embodiment techniques on user perception in 3d asymmetric telepresence.IEEE Transactions on Visu- alization and Computer Graphics, 27(11):4129–4139, 2021. 2
work page 2021
-
[73]
Guava: Gen- eralizable upper body 3d gaussian avatar
Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Yang Li, Minghan Qin, Yu Li, and Haoqian Wang. Guava: Gen- eralizable upper body 3d gaussian avatar. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 14205–14217, 2025. 7, 2, 3
work page 2025
-
[74]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 4, 6
work page 2018
-
[75]
Zerong Zheng, Xiaochen Zhao, Hongwen Zhang, Boning Liu, and Yebin Liu. Avatarrex: Real-time expressive full- body avatars.ACM Transactions on Graphics (TOG), 42(4): 1–19, 2023. 2, 3
work page 2023
-
[76]
Idol: Instant photorealistic 3d human creation from a single image
Yiyu Zhuang, Jiaxi Lv, Hao Wen, Qing Shuai, Ailing Zeng, Hao Zhu, Shifeng Chen, Yujiu Yang, Xun Cao, and Wei Liu. Idol: Instant photorealistic 3d human creation from a single image. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26308–26319, 2025. 3
work page 2025
-
[77]
Driv- able 3d gaussian avatars
Wojciech Zielonka, Timur Bagautdinov, Shunsuke Saito, Michael Zollh ¨ofer, Justus Thies, and Javier Romero. Driv- able 3d gaussian avatars. In2025 International Conference on 3D Vision (3DV), pages 979–990. IEEE, 2025. 2, 3 Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining Supplementary Material A. Additional Qual...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.