Recognition: 2 theorem links
· Lean TheoremEvaluating AI-Generated Images of Cultural Artifacts with Community-Informed Rubrics
Pith reviewed 2026-05-13 20:57 UTC · model grok-4.3
The pith
Communities define what counts as culturally appropriate in AI-generated images of their artifacts before automation begins.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Systematized concepts of cultural appropriateness derived from community members' lived experiences with artifacts and their preferences for depiction provide valid measures that reflect authentic perspectives, and these can be operationalized into automated instruments using a multimodal LLM-as-a-judge method while retaining the value of the original community input.
What carries the argument
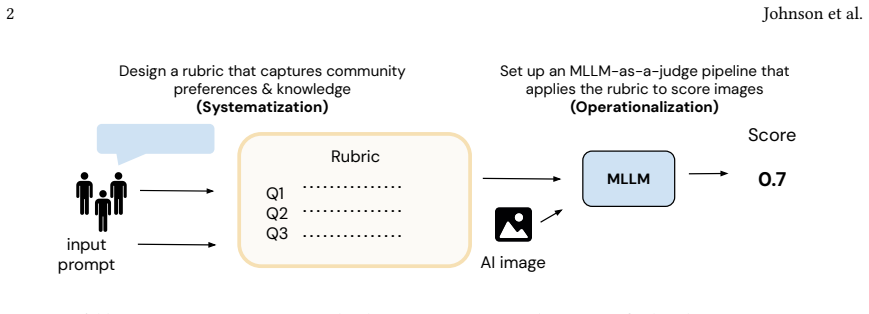
The three-stage measurement process that concentrates community input in the systematization phase to create precise concepts before they are turned into concrete rubrics for automated application.
If this is right
- Measurement instruments for AI image generation can be made repeatable and automatable across models while still grounding in community expertise.
- Early community involvement in defining concepts reduces the risk that automated evaluations miss key cultural concerns.
- Case-study rubrics from specific groups like blind UK residents or Kerala and Tamil Nadu communities can guide evaluation of how models depict material culture.
- The systematization step creates a reusable foundation for applying the same measures to new datasets or evaluation settings.
Where Pith is reading between the lines
- The same early-community systematization approach could apply to measuring other AI harms involving cultural or identity representation.
- Hybrid human-plus-LLM pipelines may be needed to handle cases where full automation loses nuance from the original community definitions.
- Standardized community-informed rubrics could support cross-model benchmarks that track improvement in cultural depiction over time.
Load-bearing premise
Community perspectives on cultural appropriateness can be translated into structured rubrics without losing essential expertise and lived experience.
What would settle it
Direct comparison showing that community members rate the same set of AI-generated artifact images differently from an LLM judge applying the community-derived rubrics.
Figures















read the original abstract
Measurement is essential to improving AI performance and mitigating harms for marginalized groups. As generative AI systems are rapidly deployed across geographies and contexts, AI measurement practices must be designed to support repeatable, automatable application across different models, datasets, and evaluation settings. But the drive to automate measurement can be in tension with the ability for measurement instruments to capture the expertise and perspectives of communities impacted by AI. Recent work advocates for breaking measurement into several key stages: first moving from an abstract concept to be measured into a precise, "systematized" concept; next operationalizing the systematized concept into a concrete measurement instrument; and finally applying the measurement instrument on data to produce measurements. This opens up an opportunity to concentrate community engagement in the systematization phase before operationalizing and applying measurement instruments. In this paper, we explore how to involve communities in systematizing the concept of "cultural appropriateness" in text-to-image models' representation of culturally significant artifacts through case studies with three communities: blind and low vision individuals residing in the UK, residents of Kerala, and residents of Tamil Nadu. Our systematized concepts reflect community members' lived experiences interacting with each artifact and how they want their material culture to be depicted, demonstrating the value of community involvement in defining valid measures. We explore how these systematized concepts can be operationalized into automated measurement instruments that could be applied using a multimodal LLM-as-a-judge approach and challenges that remain. We reflect on the benefits and limitations of such approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a framework for involving communities in systematizing the concept of cultural appropriateness for evaluating text-to-image model outputs depicting cultural artifacts. It presents three case studies (blind and low-vision UK residents, Kerala residents, Tamil Nadu residents) in which community input shapes systematized concepts grounded in lived experiences and desired depictions of material culture. The work then explores operationalizing these concepts into automated multimodal LLM-as-a-judge instruments and reflects on benefits, limitations, and remaining challenges of such automation.
Significance. If the operationalization step can be shown to preserve community perspectives, the approach would offer a practical route to repeatable, community-informed metrics for cultural representation in generative AI, addressing tensions between automation and expertise capture in measurement design.
major comments (2)
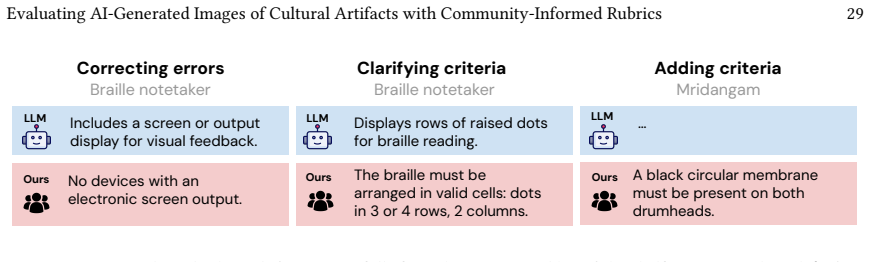
- The central claim that community involvement in systematization produces valid measures rests on the untested assumption that these concepts can be operationalized into LLM-as-a-judge instruments without substantial loss of fidelity. No quantitative agreement study (e.g., side-by-side ratings by community members versus the LLM on identical generated images) or validation of prompt construction against community judgments is reported, leaving the transition from qualitative systematization to automated application unsupported by evidence.
- Details on how the systematized concepts were translated into concrete LLM prompts or rubrics are absent, including any iterative refinement process or checks for consistency with original community input. This omission makes it impossible to evaluate whether the operationalized instruments accurately reflect the lived-experience grounding described in the case studies.
minor comments (1)
- The abstract and introduction would benefit from clearer demarcation between the qualitative case-study contributions and the exploratory operationalization discussion to help readers distinguish established findings from proposed future directions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater clarity on the operationalization of community-informed concepts. We address each major comment below and propose targeted revisions to strengthen the manuscript without altering its core exploratory focus on community-driven systematization.
read point-by-point responses
-
Referee: The central claim that community involvement in systematization produces valid measures rests on the untested assumption that these concepts can be operationalized into LLM-as-a-judge instruments without substantial loss of fidelity. No quantitative agreement study (e.g., side-by-side ratings by community members versus the LLM on identical generated images) or validation of prompt construction against community judgments is reported, leaving the transition from qualitative systematization to automated application unsupported by evidence.
Authors: The manuscript's primary claim centers on the value of community involvement during the systematization phase to ground the concept of cultural appropriateness in lived experiences, rather than asserting that subsequent operationalization into LLM-as-a-judge instruments occurs without any loss of fidelity. We explicitly frame the operationalization as an exploratory step and dedicate space to reflecting on its benefits, limitations, and open challenges. No quantitative agreement study was included because the work prioritizes establishing repeatable community-informed concepts over immediate empirical validation of automation; such a study would be a natural and valuable extension but falls outside the current scope. We will revise the manuscript to more explicitly delineate these boundaries and add a dedicated future-work subsection outlining potential validation approaches. revision: partial
-
Referee: Details on how the systematized concepts were translated into concrete LLM prompts or rubrics are absent, including any iterative refinement process or checks for consistency with original community input. This omission makes it impossible to evaluate whether the operationalized instruments accurately reflect the lived-experience grounding described in the case studies.
Authors: We agree that additional transparency on the translation process would improve evaluability. The initial submission emphasized the community engagement and systematization stages; consequently, concrete prompt examples and refinement details were omitted. In the revised manuscript we will add an appendix containing (1) sample LLM prompts and rubrics derived directly from the three case-study systematized concepts, (2) a description of how community statements were mapped to rubric criteria, and (3) any consistency checks performed against the original participant input. This addition will allow readers to assess alignment without shifting the paper's primary emphasis. revision: yes
Circularity Check
No circularity: qualitative case studies with no derivations or fitted predictions
full rationale
The paper conducts case studies with three communities to systematize the concept of cultural appropriateness for AI-generated images of artifacts, then explores (without claiming to validate) operationalization into multimodal LLM judges. No equations, parameters, or quantitative predictions appear anywhere in the manuscript. The central claims are descriptive accounts of community input rather than any reduction of outputs to inputs by construction. No self-citation chains are load-bearing for the results, and the work contains no self-definitional steps, ansatzes smuggled via citation, or renaming of known results. This is self-contained qualitative research with no circular derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Community engagement concentrated in the systematization phase produces more valid measures than engagement spread across all phases.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We explore how to involve communities in systematizing the concept of 'cultural appropriateness' ... through case studies with three communities
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Measurement framework from the social sciences [1, 116]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Robert Adcock and David Collier. 2001. Measurement validity: A shared standard for qualitative and quantitative research.American Political Science Review95, 3 (2001), 529–546
work page 2001
- [3]
-
[4]
I look at it as the king of knowledge
Rudaiba Adnin and Maitraye Das. 2024. "I look at it as the king of knowledge": How Blind People Use and Understand Generative AI Tools. In Proceedings of the 26th International ACM SIGACCESS Conference on Computers and Accessibility(St. John’s, NL, Canada)(ASSETS ’24). Association for Computing Machinery, New York, NY, USA, Article 64, 14 pages. doi:10.11...
-
[5]
Afra Feyza Akyürek, Advait Gosai, Chen Bo Calvin Zhang, Vipul Gupta, Jaehwan Jeong, Anisha Gunjal, Tahseen Rabbani, Maria Mazzone, David Randolph, Mohammad Mahmoudi Meymand, Gurshaan Chattha, Paula Rodriguez, Diego Mares, Pavit Singh, Michael Liu, Subodh Chawla, Pete Cline, Lucy Ogaz, Ernesto Hernandez, Zihao Wang, Pavi Bhatter, Marcos Ayestaran, Bing Liu...
- [6]
-
[7]
Taylor, Mark Díaz, Christopher M
Lora Aroyo, Alex S. Taylor, Mark Díaz, Christopher M. Homan, Alicia Parrish, Greg Serapio-García, Vinodkumar Prabhakaran, and Ding Wang
-
[8]
DICES dataset: diversity in conversational AI evaluation for safety. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 2321, 13 pages
-
[9]
Solon Barocas, Anhong Guo, Ece Kamar, Jacquelyn Krones, Meredith Ringel Morris, Jennifer Wortman Vaughan, W Duncan Wadsworth, and Hanna Wallach. 2021. Designing disaggregated evaluations of ai systems: Choices, considerations, and tradeoffs. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. 368–378
work page 2021
-
[10]
Bennett, Erin Brady, and Stacy M
Cynthia L. Bennett, Erin Brady, and Stacy M. Branham. 2018. Interdependence as a Frame for Assistive Technology Research and Design. In Proceedings of the 20th International ACM SIGACCESS Conference on Computers and Accessibility(Galway, Ireland)(ASSETS ’18). Association for Computing Machinery, New York, NY, USA, 161–173. doi:10.1145/3234695.3236348
-
[11]
Cynthia L. Bennett, Shaun K. Kane, and Christina N. Harrington. 2025. Toward Community-Led Evaluations of Text-to-Image AI Representations of Disability, Health, and Accessibility. InProceedings of the 5th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO ’25). Association for Computing Machinery, New York, NY, USA, 25...
-
[12]
Stevie Bergman, Nahema Marchal, John Mellor, Shakir Mohamed, Iason Gabriel, and William Isaac. 2024. STELA: a community-centred approach to norm elicitation for AI alignment.Scientific Reports14, 1 (2024), 6616
work page 2024
-
[13]
Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. 2023. Easily Accessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency(Chicago, IL, U...
-
[14]
Asia Biega, Georgina Born, Fernando Diaz, Mary L. Gray, and Rida Qadri. 2025. Towards a Multidisciplinary Vision for Culturally Inclusive Generative AI (Dagstuhl Seminar 25022).Dagstuhl Reports15, 1 (2025), 33–49. doi:10.4230/DagRep.15.1.33
-
[15]
Black Forest Labs. 2024. FLUX. https://github.com/black-forest-labs/flux
work page 2024
-
[16]
Janet Blake. 2000. On Defining the Cultural Heritage.International & Comparative Law Quarterly49, 1 (2000), 61–85
work page 2000
- [17]
-
[18]
Stacy M. Branham and Shaun K. Kane. 2015. The Invisible Work of Accessibility: How Blind Employees Manage Accessibility in Mixed-Ability Workplaces. InProceedings of the 17th International ACM SIGACCESS Conference on Computers & Accessibility(Lisbon, Portugal)(ASSETS ’15). Association for Computing Machinery, New York, NY, USA, 163–171. doi:10.1145/270064...
-
[19]
Chris Callison-Burch. 2009. Fast, Cheap, and Creative: Evaluating Translation Quality Using Amazon’s Mechanical Turk. InProceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Philipp Koehn and Rada Mihalcea (Eds.). Association for Computational Linguistics, Singapore, 286–295. https://aclanthology.org/D09-1030/
work page 2009
-
[20]
Joseph Chee Chang, Saleema Amershi, and Ece Kamar. 2017. Revolt: Collaborative Crowdsourcing for Labeling Machine Learning Datasets. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems(Denver, Colorado, USA)(CHI ’17). Association for Computing Machinery, New York, NY, USA, 2334–2346. doi:10.1145/3025453.3026044
-
[21]
Kyla Chasalow and Karen Levy. 2021. Representativeness in statistics, politics, and machine learning. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. 77–89
work page 2021
- [22]
-
[23]
Jiahui Chen, Candace Ross, Reyhane Askari-Hemmat, Koustuv Sinha, Melissa Hall, Michal Drozdzal, and Adriana Romero-Soriano. 2025. Multi- Modal Language Models as Text-to-Image Model Evaluators. https://arxiv.org/abs/2505.00759 Evaluating AI-Generated Images of Cultural Artifacts with Community-Informed Rubrics 19
-
[24]
Tim Connell. 2008. The Challenge of Assistive Technology and Braille Literacy. https://www.afb.org/aw/9/1/14277 [Online; accessed 6-September- 2025]
work page 2008
-
[25]
Emily Corvi, Hannah Washington, Stefanie Reed, Chad Atalla, Alexandra Chouldechova, P. Alex Dow, Jean Garcia-Gathright, Nicholas J Pangakis, Emily Sheng, Dan Vann, Matthew Vogel, and Hanna Wallach. 2025. Taxonomizing Representational Harms using Speech Act Theory. InFindings of the Association for Computational Linguistics. doi:10.18653/v1/2025.findings-acl.202
-
[26]
Amanda Coston, Anna Kawakami, Haiyi Zhu, Ken Holstein, and Hoda Heidari. 2023. A validity perspective on evaluating the justified use of data-driven decision-making algorithms. In2023 IEEE conference on secure and trustworthy machine learning (SaTML). IEEE, 690–704
work page 2023
-
[27]
Lee J Cronbach and Paul E Meehl. 1955. Construct validity in psychological tests.Psychological bulletin52, 4 (1955), 281
work page 1955
- [28]
-
[29]
Maitraye Das, Alexander J Fiannaca, Meredith Ringel Morris, Shaun K Kane, and Cynthia L Bennett. 2024. From provenance to aberrations: Image creator and screen reader user perspectives on alt text for AI-generated images. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–21
work page 2024
-
[30]
Maitraye Das, Darren Gergle, and Anne Marie Piper. 2019. "It doesn’t win you friends": Understanding Accessibility in Collaborative Writing for People with Vision Impairments.Proc. ACM Hum.-Comput. Interact.3, CSCW, Article 191 (Nov. 2019), 26 pages. doi:10.1145/3359293
-
[31]
Nassim Dehouche and Kullathida Dehouche. 2023. What’s in a text-to-image prompt? The potential of stable diffusion in visual arts education. Heliyon9, 6 (2023), e16757. doi:10.1016/j.heliyon.2023.e16757
- [32]
-
[33]
Sunipa Dev, Vinodkumar Prabhakaran, Rutledge Chin Feman, Aida Davani, Remi Denton, Charu Kalia, Piyawat L Kumjorn, Madhurima Maji, Rida Qadri, Negar Rostamzadeh, Renee Shelby, Romina Stella, Hayk Stepanyan, Erin van Liemt, Aishwarya Verma, Oscar Wahltinez, Edem Wornyo, Andrew Zaldivar, and Saška Mojsilović. 2026. A Unified Framework to Quantify Cultural I...
-
[34]
Athiya Deviyani and Fernando Diaz. 2025. Contextual Metric Meta-Evaluation by Measuring Local Metric Accuracy. https://arxiv.org/abs/2503. 19828
work page 2025
-
[35]
Lisa Egede. 2025.Exploring Black Communities’ Perceptions and Design Approaches for Building Culturally Tailored AI Systems. Association for Computing Machinery, New York, NY, USA, 72–76. https://doi.org/10.1145/3715668.3735629
- [36]
-
[37]
Yannick Exner, Jochen Hartmann, Oded Netzer, and Shunyuan Zhang. 2025. AI in Disguise - How AI-Generated Ads’ Visual Cues Shape Consumer Perception and Performance. doi:10.2139/ssrn.5096969
-
[38]
Ali Farhadi, Ian Endres, Derek Hoiem, and David Forsyth. 2009. Describing objects by their attributes. In2009 IEEE Conference on Computer Vision and Pattern Recognition. 1778–1785. doi:10.1109/CVPR.2009.5206772
- [39]
-
[40]
Simret Araya Gebreegziabher, Charles Chiang, Zichu Wang, Zahra Ashktorab, Michelle Brachman, Werner Geyer, Toby Jia-Jun Li, and Diego Gómez-Zará. 2025. MetricMate: An Interactive Tool for Generating Evaluation Criteria for LLM-as-a-Judge Workflow. InProceedings of the 4th Annual Symposium on Human-Computer Interaction for Work (CHIWORK ’25). Association f...
-
[41]
Sourojit Ghosh, Pranav Narayanan Venkit, Sanjana Gautam, Shomir Wilson, and Aylin Caliskan. 2024. Do Generative AI Models Output Harm while Representing Non-Western Cultures: Evidence from A Community-Centered Approach.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society7, 1 (Oct. 2024), 476–489. doi:10.1609/aies.v7i1.31651
-
[42]
Tarleton Gillespie. 2024. Generative AI and the politics of visibility.Big Data & Society11, 2 (2024), 20539517241252131. doi:10.1177/ 20539517241252131
work page 2024
- [43]
-
[44]
Kanika Gupta, Monojit Choudhury, and Kalika Bali. 2012. Mining Hindi-English Transliteration Pairs from Online Hindi Lyrics. InProceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Nicoletta Calzolari, Khalid Choukri, Thierry Declerck, Mehmet Uğur Doğan, Bente Maegaard, Joseph Mariani, Asuncion Moreno, Jan Odij...
work page 2012
- [45]
-
[46]
Bell, Candace Ross, Adina Williams, Michal Drozdzal, and Adriana Romero Soriano
Melissa Hall, Samuel J. Bell, Candace Ross, Adina Williams, Michal Drozdzal, and Adriana Romero Soriano. 2024. Towards Geographic Inclusion in the Evaluation of Text-to-Image Models. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency(Rio de Janeiro, Brazil)(FAccT ’24). Association for Computing Machinery, New York, NY, ...
-
[47]
1997.Representation: Cultural Representations and Signifying Practices
Stuart Hall (Ed.). 1997.Representation: Cultural Representations and Signifying Practices. Sage Publications, London. 20 Johnson et al
work page 1997
-
[48]
Siobhan Mackenzie Hall, Samantha Dalal, Raesetje Sefala, Foutse Yuehgoh, Aisha Alaagib, Imane Hamzaoui, Shu Ishida, Jabez Magomere, Lauren Crais, Aya Salama, et al. 2025. The Human Labour of Data Work: Capturing Cultural Diversity through World Wide Dishes.arXiv preprint arXiv:2502.05961(2025)
- [49]
-
[50]
Hamna, Deepthi Sudharsan, Agrima Seth, Ritvik Budhiraja, Deepika Khullar, Vyshak Jain, Kalika Bali, Aditya Vashistha, and Sameer Segal. 2025. Kahani: Culturally-Nuanced Visual Storytelling Tool for Non-Western Cultures. InProceedings of the 2025 ACM SIGCAS/SIGCHI Conference on Computing and Sustainable Societies (COMPASS ’25). Association for Computing Ma...
-
[51]
Emma Harvey, Emily Sheng, Su Lin Blodgett, Alexandra Chouldechova, Jean Garcia-Gathright, Alexandra Olteanu, and Hanna Wallach. 2025. Understanding and Meeting Practitioner Needs When Measuring Representational Harms Caused by LLM-Based Systems. https://arxiv.org/abs/ 2506.04482
-
[52]
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. 2024. LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.)...
-
[53]
Huiguo He, Huan Yang, Zixi Tuo, Yuan Zhou, Qiuyue Wang, Yuhang Zhang, Zeyu Liu, Wenhao Huang, Hongyang Chao, and Jian Yin. 2025. Dreamstory: Open-domain story visualization by llm-guided multi-subject consistent diffusion.IEEE Transactions on Pattern Analysis and Machine Intelligence(2025)
work page 2025
-
[54]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2018. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. https://arxiv.org/abs/1706.08500
work page Pith review arXiv 2018
-
[55]
Rachel Hong, William Agnew, Tadayoshi Kohno, and Jamie Morgenstern. 2024. Who’s in and who’s out? A case study of multimodal CLIP-filtering in DataComp. InProceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization. 1–17
work page 2024
-
[56]
Chien-Chi Hsu and Brian A. Sandford. 2007. The Delphi technique: Making sense of consensus.Practical Assessment, Research, and Evaluation12, 10 (2007), 1–8. https://openpublishing.library.umass.edu/pare/article/id/1418/ A widely cited methodological overview of the Delphi method
work page 2007
- [57]
-
[58]
Mina Huh, Yi-Hao Peng, and Amy Pavel. 2023. GenAssist: Making image generation accessible. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 1–17
work page 2023
- [59]
- [60]
-
[61]
Harry H. Jiang, Lauren Brown, Jessica Cheng, Mehtab Khan, Abhishek Gupta, Deja Workman, Alex Hanna, Johnathan Flowers, and Timnit Gebru
-
[62]
AI Art and its Impact on Artists. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society(Montréal, QC, Canada)(AIES ’23). Association for Computing Machinery, New York, NY, USA, 363–374. doi:10.1145/3600211.3604681
-
[63]
Nari Johnson, Hamna Abid, Deepthi Sudharsan, Theo Holroyd, Samantha Dalal, Siobhan Mackenzie Hall, Jennifer Wortman Vaughan, Daniela Massiceti, and Cecily Morrison. 2025. Position: To Make Text-to-Image Models that Work for Marginalized Communities, We Need New Measurement Practices for the Long Tail. https://www.microsoft.com/en-us/research/publication/p...
work page 2025
-
[64]
Shivani Kapania, Stephanie Ballard, Alex Kessler, and Jennifer Wortman Vaughan. 2025. Examining the Expanding Role of Synthetic Data Throughout the AI Development Pipeline. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency
work page 2025
-
[65]
2025.Translation Tutorial: AI Measurement as a Stakeholder-Engaged Design Practice
Anna Kawakami, Su Lin Blodgett, Solon Barocas, Alex Chouldechova, Abigail Jacobs, Emily Sheng, Jenn Wortman Vaughan, Hanna Wallach, Amy Winecoff, Angelina Wang, Haiyi Zhu, and Ken Holstein. 2025.Translation Tutorial: AI Measurement as a Stakeholder-Engaged Design Practice. Retrieved January 10, 2026 from https://drive.google.com/file/d/12qQd6ROfacYAtoQ-ii...
work page 2025
-
[66]
Anna Kawakami, Jordan Taylor, Sarah Fox, Haiyi Zhu, and Kenneth Holstein. 2026. AI failure loops in devalued work: The confluence of overconfidence in AI and underconfidence in worker expertise.Big Data & Society13, 1 (2026), 20539517261424164. doi:10.1177/20539517261424164
-
[67]
Hannah Rose Kirk, Alexander Whitefield, Paul Röttger, Andrew Bean, Katerina Margatina, Juan Ciro, Rafael Mosquera, Max Bartolo, Adina Williams, He He, et al. 2024. The PRISM Alignment Project: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models.arXiv preprin...
- [68]
-
[69]
Kevin Knight and Jonathan Graehl. 1998. Machine Transliteration.Computational Linguistics24, 4 (1998), 599–612. https://aclanthology.org/J98- 4003/
work page 1998
-
[70]
Elisa Kreiss, Cynthia Bennett, Shayan Hooshmand, Eric Zelikman, Meredith Ringel Morris, and Christopher Potts. 2022. Context Matters for Image Descriptions for Accessibility: Challenges for Referenceless Evaluation Metrics.arXiv preprint arXiv:2205.10646(2022). Evaluating AI-Generated Images of Cultural Artifacts with Community-Informed Rubrics 21
-
[71]
Neha Kumar, Naveena Karusala, Azra Ismail, Marisol Wong-Villacres, and Aditya Vishwanath. 2019. Engaging Feminist Solidarity for Comparative Research, Design, and Practice.Proc. ACM Hum.-Comput. Interact.3, CSCW, Article 167 (Nov. 2019), 24 pages. doi:10.1145/3359269
-
[72]
C., Avik Bhattacharyya, Mitesh M
Anoop Kunchukuttan, Divyanshu Kakwani, Satish Golla, Gokul N. C., Avik Bhattacharyya, Mitesh M. Khapra, and Pratyush Kumar. 2020. AI4Bharat-IndicNLP Corpus: Monolingual Corpora and Word Embeddings for Indic Languages. https://arxiv.org/abs/2005.00085
-
[73]
Tony Lee, Michihiro Yasunaga, Chenlin Meng, Yifan Mai, Joon Sung Park, Agrim Gupta, Yunzhi Zhang, Deepak Narayanan, Hannah Benita Teufel, Marco Bellagente, Minguk Kang, Taesung Park, Jure Leskovec, Jun-Yan Zhu, Li Fei-Fei, Jiajun Wu, Stefano Ermon, and Percy Liang. 2023. Holistic Evaluation of Text-To-Image Models. https://arxiv.org/abs/2311.04287
-
[74]
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. 2025. From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge. https: //arxiv.org/abs/2411.16594
- [75]
-
[76]
Kelly Mack, Rai Ching Ling Hsu, Andrés Monroy-Hernández, Brian A. Smith, and Fannie Liu. 2023. Towards Inclusive Avatars: Disability Representation in Avatar Platforms. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 607, 13 pages. do...
-
[77]
They only care to show us the wheelchair
Kelly Avery Mack, Rida Qadri, Remi Denton, Shaun K Kane, and Cynthia L Bennett. 2024. “They only care to show us the wheelchair”: disability representation in text-to-image AI models. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–23
work page 2024
-
[78]
Jabez Magomere, Shu Ishida, Tejumade Afonja, Aya Salama, Daniel Kochin, Yuehgoh Foutse, Imane Hamzaoui, Raesetje Sefala, Aisha Alaagib, Samantha Dalal, et al . 2025. The World Wide recipe: A community-centred framework for fine-grained data collection and regional bias operationalisation. InProceedings of the 2025 ACM Conference on Fairness, Accountabilit...
work page 2025
-
[79]
Daniela Massiceti, Camilla Longden, Agnieszka Slowik, Samuel Wills, Martin Grayson, and Cecily Morrison. 2024. Explaining CLIP’s performance disparities on data from blind/low vision users. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12172–12182
work page 2024
-
[80]
J. Nathan Matias and Megan Price. 2025. How public involvement can improve the science of AI.Proceedings of the National Academy of Sciences 122, 48 (2025), e2421111122. doi:10.1073/pnas.2421111122
-
[81]
Timothy R McIntosh, Teo Susnjak, Nalin Arachchilage, Tong Liu, Dan Xu, Paul Watters, and Malka N Halgamuge. 2025. Inadequacies of Large Language Model Benchmarks in the Era of Generative Artificial Intelligence.IEEE Transactions on Artificial Intelligence(2025), 1–18. doi:10.1109/tai.2025.3569516
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.