Recognition: 2 theorem links
· Lean TheoremAdaptive Learned State Estimation based on KalmanNet
Pith reviewed 2026-05-13 21:24 UTC · model grok-4.3
The pith
Adaptive Multi-modal KalmanNet narrows the gap between learned and classical state estimators on real-world automotive data by adding sensor-specific modules and context modulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
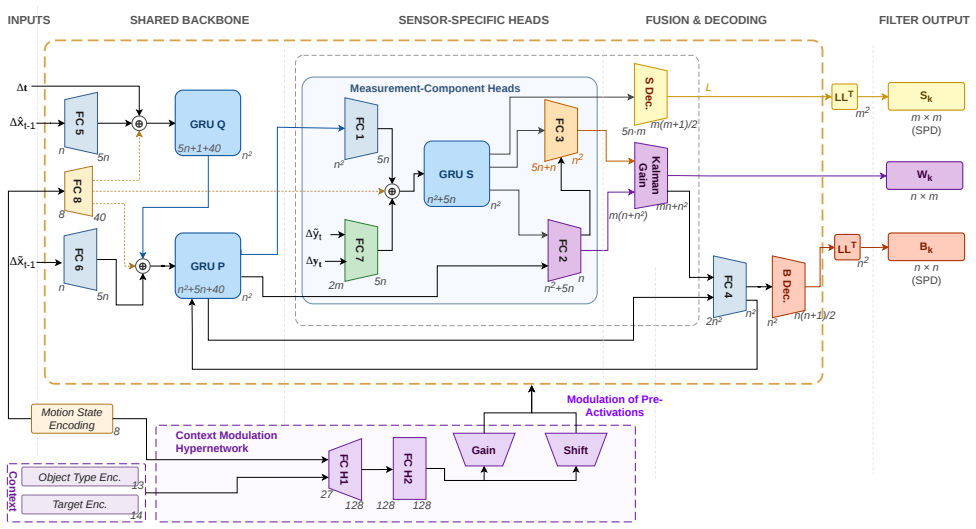
AM-KNet extends KalmanNet with sensor-specific measurement modules for independent noise learning across radar, lidar, and camera; a hypernetwork with context modulation that adapts the filter to target class, motion state, and relative pose; and a Joseph-form covariance estimation branch supervised by negative log-likelihood losses on both estimation error and innovation. A component-wise loss function encodes priors on sensor reliability, target type, motion state, and measurement flow consistency. When trained and tested on the nuScenes and View-of-Delft datasets, the resulting filter shows higher estimation accuracy and tracking stability than the original KalmanNet while closing part of
What carries the argument
Adaptive Multi-modal KalmanNet (AM-KNet) using sensor-specific measurement modules, hypernetwork context modulation, and Joseph-form covariance estimation trained under negative log-likelihood supervision
If this is right
- Sensor-specific modules allow the network to capture radar, lidar, and camera noise statistics separately rather than forcing a shared representation.
- Context modulation via the hypernetwork enables the filter to adjust its internal behavior according to target type and motion state without retraining the entire model.
- Joseph-form covariance estimation together with negative log-likelihood losses produces uncertainty estimates that are directly comparable to those of classical Kalman filters.
- The composite loss that injects physical priors reduces the amount of data needed to reach usable performance on real driving sequences.
Where Pith is reading between the lines
- If the learned modules truly separate sensor noise from dynamics, the same architecture could be reused across different vehicle platforms by swapping only the measurement heads.
- The approach suggests that explicit encoding of measurement-flow consistency inside the loss may be more effective than purely data-driven alternatives for maintaining track continuity during sensor outages.
- A natural next measurement would be to test whether the same hypernetwork can be conditioned on additional context such as weather or time of day without increasing overfitting.
Load-bearing premise
The comprehensive loss function that encodes physical priors on sensor reliability, target class, motion state, and measurement consistency will continue to produce useful behavior on driving data outside the nuScenes and View-of-Delft distributions.
What would settle it
Run AM-KNet and the base KalmanNet on a fresh multi-sensor automotive dataset collected under different sensor models or traffic conditions; if AM-KNet no longer improves accuracy or stability over the base network or over classical filters, the claim is falsified.
Figures



read the original abstract
Hybrid state estimators that combine model-based Kalman filtering with learned components have shown promise on simulated data, yet their performance on real-world automotive data remains insufficient. In this work we present Adaptive Multi-modal KalmanNet (AM-KNet), an advancement of KalmanNet tailored to the multi-sensor autonomous driving setting. AM-KNet introduces sensor-specific measurement modules that enable the network to learn the distinct noise characteristics of radar, lidar, and camera independently. A hypernetwork with context modulation conditions the filter on target type, motion state, and relative pose, allowing adaptation to diverse traffic scenarios. We further incorporate a covariance estimation branch based on the Josephs form and supervise it through negative log-likelihood losses on both the estimation error and the innovation. A comprehensive, component-wise loss function encodes physical priors on sensor reliability, target class, motion state, and measurement flow consistency. AM-KNet is trained and evaluated on the nuScenes and View-of-Delft datasets. The results demonstrate improved estimation accuracy and tracking stability compared to the base KalmanNet, narrowing the performance gap with classical Bayesian filters on real-world automotive data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Adaptive Multi-modal KalmanNet (AM-KNet), an extension of KalmanNet for multi-sensor state estimation in autonomous driving. It incorporates sensor-specific measurement modules for radar, lidar, and camera, a hypernetwork with context modulation conditioned on target type, motion state, and relative pose, and a covariance estimation branch supervised via negative log-likelihood losses. A comprehensive loss function encodes physical priors. The method is trained and evaluated on nuScenes and View-of-Delft datasets, claiming improved estimation accuracy and tracking stability over base KalmanNet, narrowing the gap to classical Bayesian filters.
Significance. If the reported improvements are validated with quantitative results, ablations, and realistic inference conditions, AM-KNet could represent a meaningful step forward in hybrid learned-model-based filters for real-world multi-modal sensor fusion in automotive applications, addressing limitations of standard KalmanNet on diverse traffic scenarios.
major comments (2)
- The abstract states performance gains on two public datasets but supplies no quantitative tables, ablation results, or error-bar analysis; without these it is impossible to verify whether the reported improvements survive proper statistical testing or are driven by post-hoc tuning.
- The hypernetwork conditioning on target type, motion state, and relative pose (as described in the abstract) assumes these context variables are available at inference; if they are supplied only as ground-truth labels during training while base KalmanNet receives no such oracle input, the measured accuracy and stability gains are not guaranteed to survive when context must be obtained from noisy upstream detectors.
minor comments (1)
- The abstract mentions a 'comprehensive, component-wise loss function' encoding physical priors but provides no details on the individual terms, loss weights, or supervision schedule, which hinders assessment of the contribution of each component.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will update the manuscript to strengthen the presentation of results and clarify practical aspects of the method.
read point-by-point responses
-
Referee: The abstract states performance gains on two public datasets but supplies no quantitative tables, ablation results, or error-bar analysis; without these it is impossible to verify whether the reported improvements survive proper statistical testing or are driven by post-hoc tuning.
Authors: We agree that the abstract would benefit from more specific quantitative highlights to allow readers to immediately assess the scale of improvements. The full paper already contains detailed tables in Section 4 reporting position, velocity, and orientation errors on both nuScenes and View-of-Delft, together with ablation studies isolating the sensor-specific modules, hypernetwork, and Joseph-form covariance branch, as well as standard deviations computed over five independent training runs. We will revise the abstract to include the key numerical gains (e.g., average position RMSE reduction and stability metrics) and will add a brief reference to the ablation and statistical analysis already present in the experimental section. revision: yes
-
Referee: The hypernetwork conditioning on target type, motion state, and relative pose (as described in the abstract) assumes these context variables are available at inference; if they are supplied only as ground-truth labels during training while base KalmanNet receives no such oracle input, the measured accuracy and stability gains are not guaranteed to survive when context must be obtained from noisy upstream detectors.
Authors: This concern is valid and points to an important practical consideration. In the reported experiments the context variables are taken from ground-truth annotations to evaluate the filter in isolation. We will add a dedicated robustness study in the revised manuscript that injects realistic noise into target type, motion state, and relative pose (drawn from typical detector error distributions on the same datasets) and re-evaluate AM-KNet under these conditions. This will quantify how much of the reported gain persists when context is obtained from upstream perception modules rather than oracle labels. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper extends KalmanNet with sensor-specific modules, a hypernetwork for context modulation on target type/motion state/pose, a Joseph-form covariance branch, and a composite loss encoding physical priors on sensor reliability and measurement consistency. These components are trained end-to-end on nuScenes and View-of-Delft data and evaluated empirically against baselines; the reported accuracy gains are presented as outcomes of this training rather than as quantities forced by definition or by renaming fitted parameters as predictions. No load-bearing self-citations, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation are invoked to justify the central architecture. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A hypernetwork with context modulation conditions the filter on target type, motion state, and relative pose... covariance estimation branch based on the Josephs form and supervise it through negative log-likelihood losses
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
comprehensive, component-wise loss function encodes physical priors on sensor reliability, target class, motion state, and measurement flow consistency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alex Sherstinsky. Fundamentals of recurrent neural network (rnn) and long short-term memory (lstm) network.Physica D: Nonlinear Phenomena, 404:132306, March 2020
work page 2020
-
[2]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017
work page 2017
-
[3]
Rahul G Krishnan, Uri Shalit, and David Sontag. Deep kalman filters. arXiv preprint arXiv:1511.05121, 2015
work page Pith review arXiv 2015
-
[4]
Deep Variational Bayes Filters: Unsupervised Learning of State Space Models from Raw Data
Maximilian Karl, Maximilian Soelch, Justin Bayer, and Patrick Van der Smagt. Deep variational bayes filters: Unsupervised learning of state space models from raw data.arXiv preprint arXiv:1605.06432, 2016
work page Pith review arXiv 2016
-
[5]
Recurrent kalman networks: Factorized inference in high-dimensional deep feature spaces
Philipp Becker, Harit Pandya, Gregor Gebhardt, Cheng Zhao, C James Taylor, and Gerhard Neumann. Recurrent kalman networks: Factorized inference in high-dimensional deep feature spaces. InInternational conference on machine learning, pages 544–552. PMLR, 2019
work page 2019
-
[6]
Guy Revach, Nir Shlezinger, Xiaoyong Ni, Adria Lopez Escoriza, Ruud JG Van Sloun, and Yonina C Eldar. Kalmannet: Neural network aided kalman filtering for partially known dynamics.IEEE Transactions on Signal Processing, 70:1532–1547, 2022
work page 2022
-
[7]
Multi-model kalmannet for maneuvering target tracking
Xuehan Han, Ling Ding, Cheng Peng, WenWen Zeng, Xin Zhang, Zheng Wen, and Le Zheng. Multi-model kalmannet for maneuvering target tracking. InIET International Radar Conference (IRC 2023), volume 2023, pages 399–405. IET, 2023
work page 2023
-
[8]
Shanli Chen, Yunfei Zheng, Dongyuan Lin, Peng Cai, Yingying Xiao, and Shiyuan Wang. Maml-kalmannet: A neural network-assisted kalman filter based on model-agnostic meta-learning.IEEE Transactions on Signal Processing, 2025
work page 2025
-
[9]
Geon Choi, Jeonghun Park, Nir Shlezinger, Yonina C Eldar, and Namyoon Lee. Split-kalmannet: A robust model-based deep learning approach for state estimation.IEEE transactions on vehicular technol- ogy, 72(9):12326–12331, 2023
work page 2023
-
[10]
Hassan Mortada, Cyril Falcon, Yanis Kahil, Math ´eo Clavaud, and Jean-Philippe Michel. Recursive kalmannet: Deep learning-augmented kalman filtering for state estimation with consistent uncertainty quan- tification. In2025 33rd European Signal Processing Conference (EU- SIPCO), pages 885–889. IEEE, 2025
work page 2025
-
[11]
Yehonatan Dahan, Guy Revach, Jindrich Dunik, and Nir Shlezinger. Bayesian kalmannet: quantifying uncertainty in deep learning augmented kalman filter.IEEE Transactions on Signal Processing, 2025
work page 2025
-
[12]
Adaptive kalmannet: Data-driven kalman filter with fast adaptation
Xiaoyong Ni, Guy Revach, and Nir Shlezinger. Adaptive kalmannet: Data-driven kalman filter with fast adaptation. InICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5970–5974. IEEE, 2024
work page 2024
-
[13]
Performance evaluation of deep learning-based state estimation: A comparative study of kalmannet
Arian Mehrfard, Bharanidhar Duraisamy, Stefan Haag, and Florian Geiss. Performance evaluation of deep learning-based state estimation: A comparative study of kalmannet. In2024 Sensor Data Fusion: Trends, Solutions, Applications (SDF), pages 1–7. IEEE, 2024
work page 2024
-
[14]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
work page 2020
-
[15]
Andras Palffy, Ewoud Pool, Srimannarayana Baratam, Julian F. P. Kooij, and Dariu M. Gavrila. Multi-class road user detection with 3+1d radar in the view-of-delft dataset.IEEE Robotics and Automation Letters, 7(2):4961–4968, 2022
work page 2022
-
[16]
Yaakov Bar-Shalom, X Rong Li, and Thiagalingam Kirubarajan.Esti- mation with applications to tracking and navigation: theory algorithms and software. John Wiley & Sons, 2004
work page 2004
-
[17]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Junyoung Chung. Empirical evaluation of gated recurrent neural net- works on sequence modeling.arXiv preprint arXiv:1412.3555, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models.Nature machine intelligence, 5(3):220–235, 2023
work page 2023
-
[19]
David Ha, Andrew Dai, and Quoc V Le. Hypernetworks.arXiv preprint arXiv:1609.09106, 2016
work page internal anchor Pith review arXiv 2016
-
[20]
Oafuser: Online adaptive extended object tracking and fusion using automotive radar detections
Stefan Haag, Bharanidhar Duraisamy, Constantin Blessing, Reiner Marchthaler, Wolfgang Koch, Martin Fritzsche, and J ¨urgen Dickmann. Oafuser: Online adaptive extended object tracking and fusion using automotive radar detections. In2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), pages 303–309, 2020
work page 2020
-
[21]
Bevdepth: Acquisition of reliable depth for multi-view 3d object detection, 2022
Yinhao Li, Zheng Ge, Guanyi Yu, Jinrong Yang, Zengran Wang, Yukang Shi, Jianjian Sun, and Zeming Li. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection, 2022
work page 2022
-
[22]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Extended object tracking assisted adaptive clustering for radar in autonomous driving applications
Stefan Haag, Bharanidhar Duraisamy, Felix Govaers, Wolfgang Koch, Martin Fritzsche, and J ¨urgen Dickmann. Extended object tracking assisted adaptive clustering for radar in autonomous driving applications. In2019 Sensor Data Fusion: Trends, Solutions, Applications (SDF), pages 1–7, 2019
work page 2019
-
[24]
Stefan Haag, Bharanidhar Duraisamy, Felix Govaers, Martin Fritzsche, J¨urgen Dickmann, and Wolfgang Koch. Extended object tracking assisted adaptive multi-hypothesis clustering for radar in autonomous driving domain. In2021 21st International Radar Symposium (IRS), pages 1–10, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.