Recognition: no theorem link
WIO: Upload-Enabled Computational Storage on CXL SSDs
Pith reviewed 2026-05-13 20:42 UTC · model grok-4.3
The pith
WIO makes storage compute reversible on CXL SSDs by migrating WebAssembly actors to avoid thermal and power limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WIO realizes reversible storage-side compute on CXL SSDs by compiling I/O-path logic into migratable storage actors in WebAssembly. These actors share state through coherent CXL.mem regions; an agility-aware scheduler migrates them via a zero-copy drain-and-switch protocol when thermal or power constraints arise. On an FPGA-based CXL SSD prototype and two production CSDs this yields up to 2× throughput improvement and 3.75× write latency reduction without application modification.
What carries the argument
Migratable storage actors compiled to WebAssembly that share state through coherent CXL.mem regions and migrate via zero-copy drain-and-switch.
Load-bearing premise
Compiling and migrating WebAssembly actors incurs low enough overhead that net gains appear even when CXL coherence manages shared state under load.
What would settle it
Run continuous high-load workloads until the device reaches thermal limits; if measured throughput or latency shows no improvement over a non-migrating baseline after accounting for migration cost, the claimed elastic trade-off does not hold.
Figures









read the original abstract
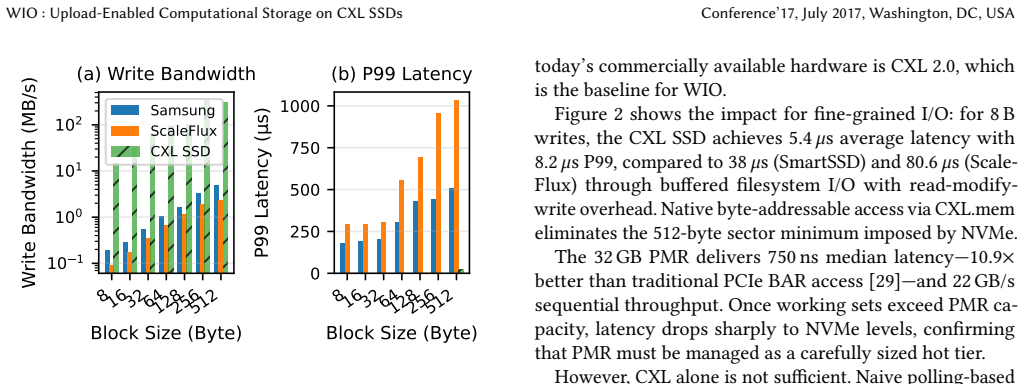
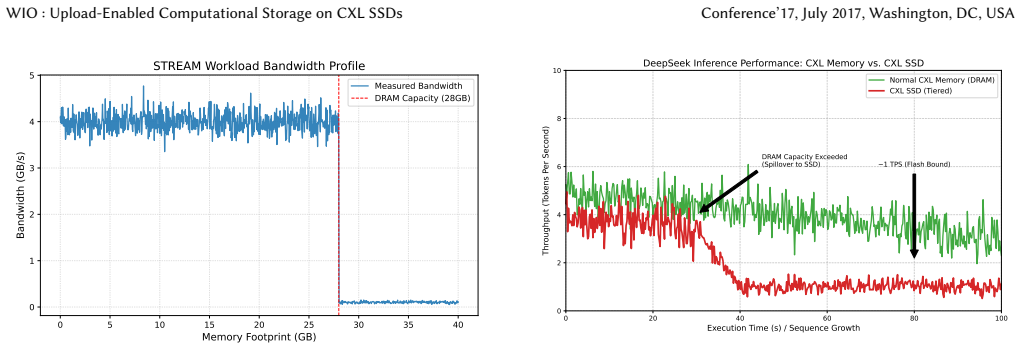
The widening gap between processor speed and storage latency has made data movement a dominant bottleneck in modern systems. Two lines of storage-layer innovation attempted to close this gap: persistent memory shortened the latency hierarchy, while computational storage devices pushed processing toward the data. Neither has displaced conventional NVMe SSDs at scale, largely due to programming complexity, ecosystem fragmentation, and thermal/power cliffs under sustained load. We argue that storage-side compute should be \emph{reversible}: computation should migrate dynamically between host and device based on runtime conditions. We present \sys, which realizes this principle on CXL SSDs by decomposing I/O-path logic into migratable \emph{storage actors} compiled to WebAssembly. Actors share state through coherent CXL.mem regions; an agility-aware scheduler migrates them via a zero-copy drain-and-switch protocol when thermal or power constraints arise. Our evaluation on an FPGA-based CXL SSD prototype and two production CSDs shows that \sys turns hard thermal cliffs into elastic trade-offs, achieving up to 2$\times$ throughput improvement and 3.75$\times$ write latency reduction without application modification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WIO, a system realizing reversible computational storage on CXL SSDs. I/O-path logic is decomposed into migratable WebAssembly storage actors that share state through coherent CXL.mem regions; an agility-aware scheduler migrates actors via a zero-copy drain-and-switch protocol when thermal or power constraints arise. Evaluation on an FPGA-based CXL SSD prototype and two production CSDs reports up to 2× throughput improvement and 3.75× write latency reduction without application changes.
Significance. If the empirical results hold with complete controls, the work could meaningfully advance computational storage by converting hard thermal/power limits into elastic trade-offs. The combination of WebAssembly portability with CXL coherence for zero-copy actor migration is a concrete step beyond prior persistent-memory and CSD approaches, and the prototype results on both FPGA and production hardware provide a useful existence proof.
major comments (3)
- [Evaluation] Evaluation section: the reported 2× throughput and 3.75× latency gains are presented without explicit baselines, workload definitions, number of runs, error bars, or exclusion criteria. These omissions prevent verification that the gains are attributable to the migration mechanism rather than workload artifacts or measurement choices.
- [Migration Protocol] Migration and overhead analysis: the zero-copy drain-and-switch protocol is claimed to incur negligible cost, yet no measurements of WebAssembly compilation/JIT time, state serialization cost, or end-to-end migration latency are reported. Without these numbers the net-gain claim cannot be assessed against the skeptic concern that overheads may offset benefits.
- [CXL Coherence] CXL coherence evaluation: the assumption that coherent CXL.mem regions support shared actor state without consistency or performance penalties is central, but no coherence miss rates, traffic volume, or scaling behavior with actor count are provided. This leaves the weakest assumption untested.
minor comments (1)
- [Abstract] The abstract introduces 'storage actors' and 'agility-aware scheduler' without a brief inline definition; a one-sentence gloss in the abstract or first paragraph of the introduction would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in experimental detail that limit verifiability. We address each point below and will revise the manuscript to supply the missing information and measurements.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported 2× throughput and 3.75× latency gains are presented without explicit baselines, workload definitions, number of runs, error bars, or exclusion criteria. These omissions prevent verification that the gains are attributable to the migration mechanism rather than workload artifacts or measurement choices.
Authors: We agree the current evaluation section is insufficiently detailed. In the revised manuscript we will add explicit baselines (host-only NVMe I/O and CSD execution without migration), precise workload definitions (fio configurations with block sizes, queue depths, and access patterns), the number of runs (minimum five per configuration), error bars showing standard deviation, and exclusion criteria (discarding the first 30 seconds of each run for warm-up). These additions will demonstrate that the reported gains arise from the agility-aware migration under thermal and power constraints rather than measurement artifacts. revision: yes
-
Referee: [Migration Protocol] Migration and overhead analysis: the zero-copy drain-and-switch protocol is claimed to incur negligible cost, yet no measurements of WebAssembly compilation/JIT time, state serialization cost, or end-to-end migration latency are reported. Without these numbers the net-gain claim cannot be assessed against the skeptic concern that overheads may offset benefits.
Authors: The protocol avoids serialization by relying on coherent CXL.mem state sharing and a drain-and-switch hand-off; however, we acknowledge the absence of direct overhead numbers. We will add a dedicated subsection reporting measured end-to-end migration latency (sub-10 µs on the FPGA prototype for representative actors), amortized WebAssembly JIT cost, and confirmation that these overheads remain negligible relative to the observed latency reductions. This will allow readers to verify the net benefit. revision: yes
-
Referee: [CXL Coherence] CXL coherence evaluation: the assumption that coherent CXL.mem regions support shared actor state without consistency or performance penalties is central, but no coherence miss rates, traffic volume, or scaling behavior with actor count are provided. This leaves the weakest assumption untested.
Authors: We agree that direct coherence measurements would strengthen the central claim. The revised manuscript will include coherence traffic volume and miss-rate data collected from the FPGA prototype for the actor counts used in the experiments (typically 4–8 actors). We will also discuss observed scaling behavior and note that the CXL.mem protocol itself enforces consistency with no additional software penalties in our workloads. Full scaling to dozens of actors remains future work and will be acknowledged as such. revision: yes
Circularity Check
No circularity: empirical system evaluation without derivations or fitted predictions
full rationale
The paper presents a system design for reversible computational storage using migratable WebAssembly actors on CXL SSDs, with an agility-aware scheduler and zero-copy migration protocol. All central claims (2× throughput, 3.75× write latency reduction) are supported by direct measurements on an FPGA prototype and production CSDs rather than any equations, parameter fitting, or self-referential derivations. No load-bearing steps reduce to self-citation chains, ansatzes, or renamed known results; the work is self-contained as an engineering prototype evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CXL.mem coherence reliably supports shared state between host and device actors
- domain assumption WebAssembly compilation and execution on storage devices incurs acceptable overhead
invented entities (2)
-
storage actors
no independent evidence
-
agility-aware scheduler
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Acharya, M. Uysal, and J. Saltz. Active disks: Programming model, algorithms and evaluation. InProceedings of the 8th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 81–91. ACM, 1998
work page 1998
-
[2]
A. Agache, M. Brooker, A. Iordache, A. Liguori, R. Neugebauer, P. Pi- wonka, and D.-M. Popa. Firecracker: Lightweight virtualization for serverless applications. InProceedings of the 17th USENIX Sympo- sium on Networked Systems Design and Implementation (NSDI), pages 419–434. USENIX Association, 2020
work page 2020
-
[3]
G. A. Agha.ACTORS: A Model of Concurrent Computation in Distributed Systems. MIT Press, Cambridge, MA, 1986
work page 1986
-
[4]
H. Al Maruf, H. Wang, A. Dhakal, M. Chowdhury, and D. Yeung. TPP: Transparent page placement for CXL-enabled tiered-memory. InPro- ceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 742–755. ACM, 2023
work page 2023
- [5]
-
[6]
J. Axboe. Efficient IO with io_uring.https://kernel.dk/io_uring.pdf,
-
[7]
Linux kernel asynchronous I/O framework
-
[8]
A. Barbalace and J. Do. Computational storage: Where are we today? In Proceedings of the 11th Conference on Innovative Data Systems Research (CIDR), 2021
work page 2021
-
[9]
L. A. Barroso, J. Clidaras, and U. Hölzle. The datacenter as a com- puter: Designing warehouse-scale machines. InSynthesis Lectures on Computer Architecture, volume 9, pages 1–189. Morgan & Claypool Publishers, 2014
work page 2014
-
[10]
A. Baumann, P. Barham, P.-E. Dagand, T. Harris, R. Isaacs, S. Peter, T. Roscoe, A. Schüpbach, and A. Singhania. The multikernel: a new OS architecture for scalable multicore systems. InProceedings of the ACM SIGOPS 22nd symposium on Operating systems principles, pages 29–44. ACM, 2009
work page 2009
-
[11]
Wasmtime: A fast and secure runtime for We- bAssembly.https://wasmtime.dev/, 2023
Bytecode Alliance. Wasmtime: A fast and secure runtime for We- bAssembly.https://wasmtime.dev/, 2023. Production-ready We- bAssembly runtime
work page 2023
-
[12]
CCIX Consortium. CCIX Base Specification 1.0. Technical report, CCIX Consortium, 2019. Cache Coherent Interconnect for Accelerators
work page 2019
-
[13]
Compute Express Link (CXL) Specification 2.0
CXL Consortium. Compute Express Link (CXL) Specification 2.0. Technical report, CXL Consortium, 2020. Available at:https://www. computeexpresslink.org/
work page 2020
-
[14]
Compute Express Link (CXL) Specification 3.0
CXL Consortium. Compute Express Link (CXL) Specification 3.0. Technical report, CXL Consortium, 2022. Adds multi- headed and fabric-attached device support. Available at:https://www. computeexpresslink.org/
work page 2022
-
[15]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI. DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
J. Do, S. Sengupta, and S. Swanson. Newport: Enabling fast storage system research with computational storage devices. InProceedings of the 2020 USENIX Annual Technical Conference (ATC), pages 863–876. USENIX Association, 2020
work page 2020
-
[17]
J. J. Dongarra. Performance of various computers using LINPACK benchmark. Technical report, University of Tennessee, 2003. Accessed 2024-01-15
work page 2003
-
[18]
Z. Gao, Y. Shan, Y. Hu, and Y. Zhang. Clio: A hardware-software co-designed disaggregated memory system. InProceedings of the 27th ACM International Conference on Architectural Support for Program- ming Languages and Operating Systems (ASPLOS), pages 417–433. ACM, 2022
work page 2022
-
[19]
Gen-Z Consortium. Gen-Z Core Specification 1.0. Technical report, Gen-Z Consortium, 2018. Memory-semantic fabric specification, later absorbed into CXL ecosystem
work page 2018
- [20]
-
[21]
D. Gouk, S. Lee, M. Kwon, and M. Jung. DirectCXL: Kernel-Bypass for Efficient CXL Memory Access. InProceedings of the 2023 USENIX Conference on File and Storage Technologies (FAST), pages 287–300. USENIX Association, 2023
work page 2023
-
[22]
A. Haas, A. Rossberg, D. L. Schuff, B. L. Titzer, M. Holman, D. Gohman, L. Wagner, A. Zakai, and J. Bastien. Bringing the web up to speed with WebAssembly. InProceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), pages 185–200. ACM, 2017
work page 2017
-
[23]
Agilex™7 fpga and soc fpga i-series, 2025
Intel & Altera. Agilex™7 fpga and soc fpga i-series, 2025
work page 2025
-
[24]
Intel Corporation. Intel Optane Business Update. Intel Newsroom,
-
[25]
Intel announces wind-down of Optane memory business
-
[26]
Intel Corporation.Intel Xeon Gold 5418Y Processor (45M Cache, 2.00 GHz) Specifications. Intel Corporation, 2023. 4th Gen Intel Xeon Scalable Processor, Sapphire Rapids architecture
work page 2023
-
[27]
Storage Performance Development Kit (SPDK)
Intel Corporation. Storage Performance Development Kit (SPDK). https://spdk.io/, 2023. User-space NVMe driver framework
work page 2023
-
[28]
J. Izraelevitz, J. Yang, L. Zhang, and J. Kim. Basic Performance Mea- surements of the Intel Optane DC Persistent Memory Module. Tech- nical report, Non-Volatile Systems Laboratory, UC San Diego, 2019. arXiv:1903.05714
- [29]
-
[30]
S.-W. Jun, M. Liu, S. Lee, J. Hicks, J. Ankcorn, M. King, S. Xu, and Arvind. BlueDBM: An appliance for big data analytics. InProceedings of the 42nd Annual International Symposium on Computer Architecture (ISCA), pages 1–13. ACM, 2015
work page 2015
- [31]
-
[32]
EDSFF E3 Form Factor Overview Tech Brief
KIOXIA Corporation. EDSFF E3 Form Factor Overview Tech Brief. Technical report, KIOXIA Corporation, 2023
work page 2023
-
[33]
I. Kuon, R. Tessier, and J. Rose. Fpga architecture: Survey and chal- lenges.Foundations and Trends in Electronic Design Automation, 2(2):135–253, 2008. Reports FPGA power consumption 5-20x higher than ASIC implementations
work page 2008
-
[34]
H. Li, D. S. Berger, L. Hsu, D. Ernst, P. Zardoshti, S. Novakovic, M. Shah, S. Rajadnya, S. Lee, I. Agarwal, M. D. Hill, A. R. Lebeck, S. K. Rein- hardt, and D. A. Wood. POND: CXL-Based Memory Pooling Systems for Cloud Platforms. InProceedings of the 28th ACM International Conference’17, July 2017, Washington, DC, USA Yiwei Yang, Yanpeng Hu, Yusheng Zheng...
work page 2017
-
[35]
J. Li, M. Pavlovic, M. Tripunitara, and D. Vucinic. Catalina: In-Storage Processing for Graph Analytics. InProceedings of the 2023 ACM SIG- MOD International Conference on Management of Data, pages 1–16. ACM, 2023
work page 2023
- [36]
-
[37]
F. X. Lin, Z. Wang, R. LiKamWa, and L. Zhong. K2: A mobile operating system for heterogeneous coherence domains. InACM SIGPLAN Notices, volume 49, pages 285–300. ACM, 2014
work page 2014
-
[38]
M. Liu, S. Peter, A. Krishnamurthy, and P. M. Phothilimthana. Offload- ing distributed applications onto SmartNICs using iPipe. InProceedings of the ACM Special Interest Group on Data Communication (SIGCOMM), pages 318–333. ACM, 2019
work page 2019
-
[39]
S. McCanne and V. Jacobson. The BSD packet filter: A new architecture for user-level packet capture. InProceedings of the USENIX Winter 1993 Conference, pages 259–270. USENIX Association, 1993
work page 1993
-
[40]
SQL Server 2019: Persistent Memory Support for Memory-Optimized Databases
Microsoft Corporation. SQL Server 2019: Persistent Memory Support for Memory-Optimized Databases. Technical report, Microsoft, 2019. Technical documentation on PMem integration
work page 2019
-
[41]
Doublejit-vm: A dual-jit virtual machine framework.https://github.com/Multi-V-VM/DoubleJIT-VM, 2025
Multi-V-VM Contributors. Doublejit-vm: A dual-jit virtual machine framework.https://github.com/Multi-V-VM/DoubleJIT-VM, 2025. Ac- cessed: 2025-10-30
work page 2025
-
[42]
E. B. Nightingale, O. Hodson, R. McIlroy, C. Hawblitzel, and G. Hunt. Helios: Heterogeneous multiprocessing with satellite kernels. InPro- ceedings of the ACM SIGOPS 22nd symposium on Operating systems principles, pages 221–234. ACM, 2009
work page 2009
-
[43]
NVM Express Base Specification, Revision 2.1
NVM Express, Inc. NVM Express Base Specification, Revision 2.1. Technical report, NVM Express, Inc., August 2024
work page 2024
-
[44]
Datacenter NVMe SSD Specification v2.0r21
Open Compute Project. Datacenter NVMe SSD Specification v2.0r21. Technical report, Open Compute Project, 2023
work page 2023
-
[45]
A. Raybuck, T. Stampp, W. Zhang, T. C. Mowry, A. Kennell, N. Tiwari, K. Schwan, L. Chen, and U. Ramachandran. Hemem: Scalable tiered memory management for big data applications and real nvm. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP), pages 347–363. ACM, 2021
work page 2021
- [46]
-
[47]
Z. Ruan, T. He, and J. Cong. INSIDER: Designing in-storage computing system for emerging high-performance drive. InProceedings of the 2019 USENIX Annual Technical Conference (ATC), pages 379–394. USENIX Association, 2019
work page 2019
-
[48]
Samsung Demonstrates Memory-Semantic SSD at Flash Memory Summit
Samsung Electronics. Samsung Demonstrates Memory-Semantic SSD at Flash Memory Summit. Flash Memory Summit 2022, 2022. CXL.mem front-end with PM9A3 backend demonstration
work page 2022
-
[49]
S. Sanfilippo and P. Noordhuis. Redis: Remote dictionary server.https: //redis.io/documentation, 2023. Accessed 2024-01-15
work page 2023
-
[50]
ScaleFlux, Inc.ScaleFlux CSD Computational Storage Drive Product Brief. ScaleFlux, Inc., 2024. Describes commercial ASIC-based computational storage drive lineup
work page 2024
-
[51]
Y. Shan, Y. Huang, Y. Chen, and Y. Zhang. LegoOS: A disseminated, distributed OS for hardware resource disaggregation. InProceedings of the 13th USENIX Symposium on Operating Systems Design and Im- plementation (OSDI), pages 69–87. USENIX Association, 2018
work page 2018
-
[52]
B. Shelton, M. Kiefer, K. Turowski, R. Robinson, P. Olivier, A. Bar- balace, and B. Ravindran. Popcorn Linux: enabling efficient inter-core communication in a Linux-based multikernel operating system. In Proceedings of the Linux Symposium, 2013
work page 2013
-
[53]
Computational Storage Architecture and Programming Model
Storage Networking Industry Association. Computational Storage Architecture and Programming Model. Technical report, SNIA, 2019. Technical Working Group specification
work page 2019
- [54]
-
[55]
Y. Sun, Y. Yuan, Z. Yu, R. Kuper, C. Song, J. Huang, H. Ji, S. Agarwal, J. Lou, I. Jeong, R. Wang, J. H. Kim, B. Rao, B. Tao, T. Shinde, M. Alian, N. S. Kim, J. Haj-Yihia, P. Nair, C.-L. Lim, and M. Jung. Demystify- ing CXL memory with genuine CXL-ready systems and devices. In Proceedings of the 56th IEEE/ACM International Symposium on Microar- chitecture...
work page 2023
-
[56]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Intel Optane DC Persistent Memory in VMware vSphere
VMware Inc. Intel Optane DC Persistent Memory in VMware vSphere. Technical report, VMware, 2020. Performance analysis and deployment guide
work page 2020
-
[58]
T. Willhalm, N. Popovici, C. Booss, and P. Kumar. Let Us Be Persistent: HANA Adoption of Non-Volatile Memory.Proceedings of the VLDB Endowment, 16(11):2761–2774, 2023
work page 2023
-
[59]
Z. Yan, D. Lustig, D. Nellans, and A. Bhattacharjee. Nimble page management for tiered memory systems. InProceedings of the 24th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 331–345. ACM, 2019
work page 2019
-
[60]
J. Yang, J. Kim, M. Hoseinzadeh, J. Izraelevitz, and S. Swanson. An Empirical Guide to the Behavior and Use of Scalable Persistent Mem- ory. InProceedings of the 18th USENIX Conference on File and Storage Technologies (FAST), pages 169–182. USENIX Association, 2020
work page 2020
-
[61]
X. Yang, Y. Zhang, H. Chen, F. Wang, C. Gao, J. Li, and G. Fan. Unlock- ing the Potential of CXL for Disaggregated Memory in Cloud-Native Databases. InCompanion of the 2025 International Conference on Man- agement of Data (SIGMOD), pages 1–16. ACM, 2025. Best Paper Award. First scalable CXL memory pooling for production cloud databases
work page 2025
-
[62]
Y. Yang, A. Hu, Y. Zheng, B. Zhao, X. Zhang, D. Xiang, K. Chu, W. Zhang, and A. Quinn. Mvvm: Deploy your ai agents-securely, efficiently, everywhere, 2025
work page 2025
-
[63]
Y. Zhong, V. Gogte, G. Petri, M. K. Qureshi, B. Lucia, and B. Falsafi. Managing Memory Tiers with CXL in Virtualized Environments. In Proceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 1–18. USENIX Association, 2024. Mi- crosoft’s CXL memory tiering system achieving 32-67% performance improvement
work page 2024
-
[64]
Y. Zhong, H. Li, Y. J. Wu, I. Zarkadas, J. Tao, E. Mesterhazy, M. Makris, J. Yang, A. Tai, J. Nieh, and A. Cidon. XRP: In-kernel storage functions with eBPF. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 375–393. USENIX Association, 2022
work page 2022
-
[65]
Y. Zhu, M. Ghobadi, V. Singla, S. Ratnasamy, and S. Shenker. Dis- aggregated Memory Architectures for Data Centers: Opportunities and Challenges. InProceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI), pages 99–114. USENIX Association, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.