Recognition: no theorem link
Beyond Resolution Rates: Behavioral Drivers of Coding Agent Success and Failure
Pith reviewed 2026-05-13 20:26 UTC · model grok-4.3
The pith
The LLM is the main driver of coding agent success and behavior, more so than the framework it runs in.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
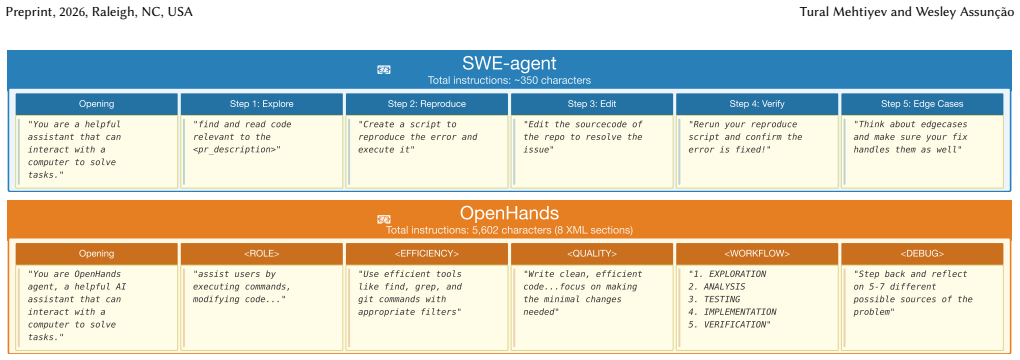
The LLM is the primary driver of both outcome and behavior: agents sharing the same LLM agree on far more tasks than agents sharing the same framework, and the framework performance gap shrinks with each generation of LLM improvement. Framework prompts influence agent tactics, but this influence diminishes with stronger LLMs.
What carries the argument
Comparison of task agreement rates between pairs of agents that share the LLM versus pairs that share the framework.
If this is right
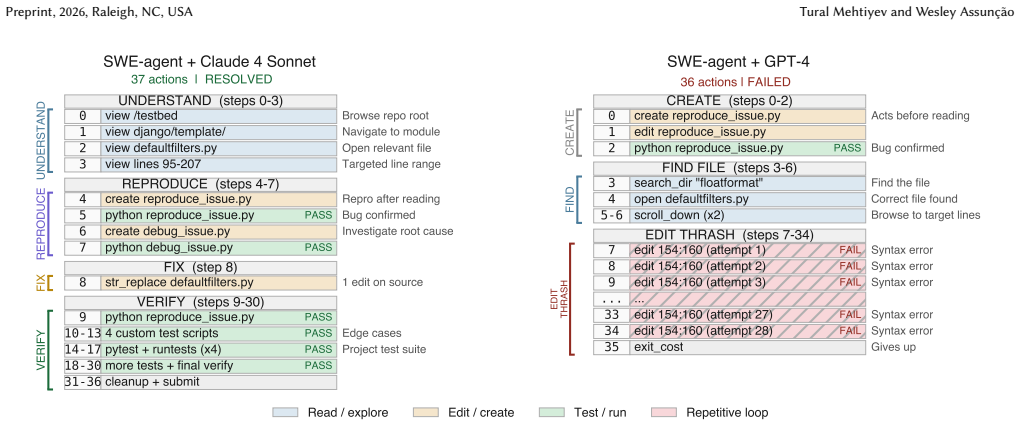
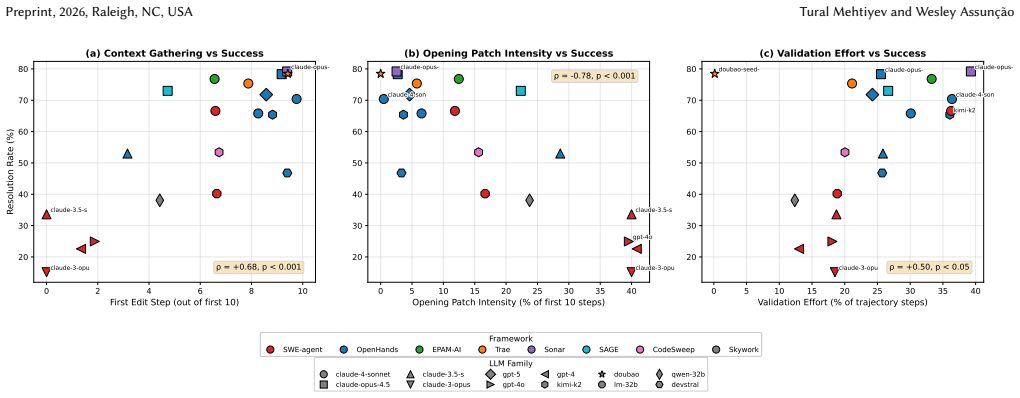
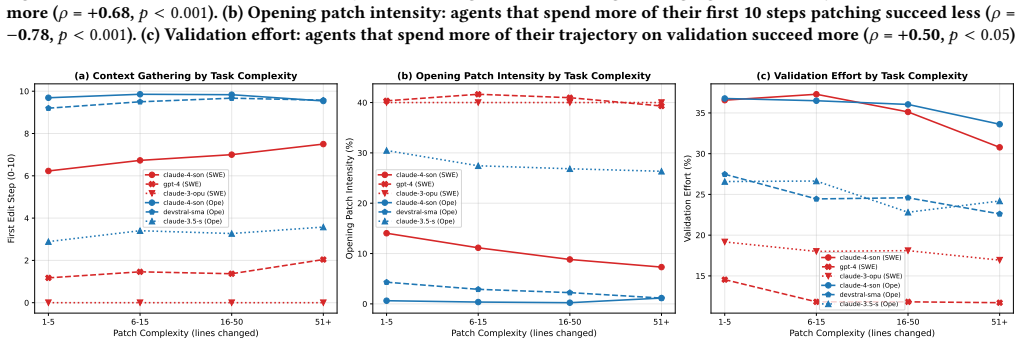
- Agents that gather context before editing and invest in validation succeed more often.
- Trajectory length correlates with failure only because it tracks task difficulty; after control, longer trajectories indicate more thorough work.
- Behavioral strategies are set by the agent rather than adapting to each task.
- Framework differences affect tactics but lose impact as LLMs improve.
- Twelve tasks with simple patches stay unsolved because agents lack architectural reasoning or domain knowledge.
Where Pith is reading between the lines
- Future work on coding agents should prioritize LLM selection over framework engineering.
- Benchmarks need more tasks that test domain knowledge and architecture to expose remaining failure modes.
- With stronger LLMs, coding agents may converge in performance regardless of framework.
Load-bearing premise
Controlling for task difficulty fully isolates behavioral effects, and the 500 tasks with 19 agents are representative enough for the patterns to hold beyond this benchmark.
What would settle it
A new study on a fresh set of tasks in which agents sharing frameworks agree on more solved tasks than agents sharing LLMs.
Figures






read the original abstract
Coding agents represent a new paradigm in automated software engineering, combining the reasoning capabilities of Large Language Models (LLMs) with tool-augmented interaction loops. However, coding agents still have severe limitations. Top-ranked LLM-based coding agents still fail on over 20% of benchmarked problems. Yet, we lack a systematic understanding of why (i.e., the causes) agents fail, and how failure unfolds behaviorally. We present a large-scale empirical study analyzing 9,374 trajectories from 19 agents (8 coding agent frameworks, 14 LLMs) on 500 tasks. We organize our analysis around three research questions. First, we investigate why agents fail on specific tasks and find that patch complexity alone does not explain difficulty: 12 never-solved tasks require only simple patches and were considered easy by human annotators, yet all agents fail due to gaps in architectural reasoning and domain knowledge. Second, we examine how behavioral patterns differentiate success from failure. The widely reported correlation between trajectory length and failure reverses direction once task difficulty is controlled, revealing it as a confound. Instead, trajectory structure discriminates consistently: agents that gather context before editing and invest in validation succeed more often, and these strategies are agent-determined rather than task-adaptive. Third, we disentangle LLM capability from framework design and find that the LLM is the primary driver of both outcome and behavior: agents sharing the same LLM agree on far more tasks than agents sharing the same framework, and the framework performance gap shrinks with each generation of LLM improvement. Framework prompts do influence agent tactics, but this influence diminishes with stronger LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale empirical study of 9,374 trajectories from 19 coding agents (8 frameworks and 14 LLMs) on 500 tasks. It investigates three questions: why agents fail on specific tasks (patch complexity does not explain 12 never-solved tasks that require simple patches but fail due to architectural reasoning and domain knowledge gaps), how behavioral patterns differentiate success from failure (after controlling for task difficulty, longer trajectories no longer predict failure; instead, context-gathering before editing and validation investment consistently discriminate success and are agent-determined), and the relative roles of LLMs versus frameworks (LLM is the primary driver, as same-LLM agents agree on far more tasks than same-framework agents, with framework performance gaps shrinking across LLM generations).
Significance. If the results hold, the work offers a substantive advance in understanding coding agents by shifting focus from aggregate resolution rates to identifiable behavioral drivers and the dominant influence of LLM choice over framework design. The large trajectory count, explicit difficulty controls, and direct empirical comparisons provide a stronger foundation than prior smaller-scale studies, with potential to inform more effective agent architectures and evaluation practices in automated software engineering.
major comments (1)
- [LLM vs framework analysis] The section on disentangling LLM and framework effects: the claim that the LLM is the primary driver because agents sharing the same LLM agree on far more tasks than those sharing the same framework lacks reported same-LLM pair counts, exact agreement fractions, and any statistical test (e.g., permutation or bootstrap) showing the difference exceeds chance or selection effects. With only 19 agents total, same-LLM pairs are necessarily sparse and may overlap with framework-specific choices, making the attribution sensitive to the particular combinations studied; this is load-bearing for the central claim and requires quantitative support.
minor comments (2)
- [Abstract] Abstract: provides only high-level descriptions of how task difficulty was measured and how statistical controls were applied; adding one sentence on the concrete metrics or regression approach would improve clarity.
- [Behavioral analysis] Behavioral patterns section: the quantification of 'trajectory structure' (context gathering, validation investment) should include explicit definitions or pseudocode for the derived features to allow replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. The comment on the LLM-versus-framework analysis has prompted us to strengthen the quantitative support for our central claim.
read point-by-point responses
-
Referee: [LLM vs framework analysis] The section on disentangling LLM and framework effects: the claim that the LLM is the primary driver because agents sharing the same LLM agree on far more tasks than those sharing the same framework lacks reported same-LLM pair counts, exact agreement fractions, and any statistical test (e.g., permutation or bootstrap) showing the difference exceeds chance or selection effects. With only 19 agents total, same-LLM pairs are necessarily sparse and may overlap with framework-specific choices, making the attribution sensitive to the particular combinations studied; this is load-bearing for the central claim and requires quantitative support.
Authors: We agree that the original presentation omitted the explicit counts, fractions, and statistical validation needed to substantiate the claim. In the revised manuscript we have added a new subsection (Section 5.3) that reports: the exact number of same-LLM pairs (21) and same-framework pairs (28) that can be formed from the 19 agents; the mean agreement rate across same-LLM pairs (0.73, SD 0.11) versus same-framework pairs (0.47, SD 0.14); and the results of a permutation test (10,000 iterations) that randomly reassigns LLMs while preserving framework structure, yielding p = 0.002. A bootstrap analysis of the difference in means further confirms significance. To address possible overlap and selection effects, we additionally report agreement rates restricted to cross-framework same-LLM pairs and show that the LLM advantage remains. These additions directly supply the quantitative support requested and demonstrate that the observed difference is unlikely to arise from the particular agent combinations in our study. revision: yes
Circularity Check
No significant circularity in empirical analysis
full rationale
The paper's central claims rest on direct empirical counts and comparisons from 9,374 trajectories across 19 agents on 500 tasks. The finding that agents sharing the same LLM agree on more tasks than those sharing frameworks is derived from observed agreement rates and behavioral patterns after controlling for task difficulty, with no equations, fitted parameters, self-definitions, or self-citation chains that reduce outcomes to inputs by construction. No ansatzes, uniqueness theorems, or renamings of known results are invoked in a load-bearing way; the analysis is self-contained against the benchmark data.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard statistical assumptions required to control for task difficulty when measuring correlations
Forward citations
Cited by 1 Pith paper
-
Counterfactual Trace Auditing of LLM Agent Skills
CTA framework detects 522 skill influence patterns in LLM agent traces across 49 tasks where average pass rate shifts only +0.3%, exposing evaluation gaps in behavioral effects like template copying and excess planning.
Reference graph
Works this paper leans on
-
[1]
Nicolas Bettenburg, Sascha Just, Adrian Schröter, Cathrin Weiss, Rahul Premraj, and Thomas Zimmermann. 2008. What Makes a Good Bug Report?. InProceedings of the 16th ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE). 308–318. doi:10.1145/1453101.1453146
-
[2]
Islem Bouzenia and Michael Pradel. 2025. Understanding Software Engineer- ing Agents: A Study of Thought-Action-Result Trajectories. In40th IEEE/ACM International Conference on Automated Software Engineering (ASE)
work page 2025
-
[3]
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christo- pher Ré, and Azalia Mirhoseini. 2024. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [4]
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, et al. 2021. Evaluating Large Language Models Trained on Code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Zhi Chen et al. 2025. Beyond Final Code: A Process-Oriented Error Analysis of Software Development Agents in Real-World GitHub Scenarios.arXiv preprint arXiv:2503.12374(2025). Accepted at ICSE 2026
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Zhi Chen et al. 2026. Rethinking the Value of Agent-Generated Tests for LLM- Based Software Engineering Agents.arXiv preprint arXiv:2602.07900(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [8]
-
[9]
Jatin Ganhotra. 2025. Cracking the Code: How Difficult Are SWE-Bench-Verified Tasks Really? https://jatinganhotra.dev/blog/swe-agents/2025/04/15/swe-bench- verified-easy-medium-hard.html. Blog post
work page 2025
-
[10]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A Survey on Large Language Models for Code Generation.arXiv preprint arXiv:2406.00515(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues?. InInternational Conference on Learning Representations (ICLR)
work page 2024
-
[12]
Mosh Levy, Alon Jacoby, and Yoav Goldberg. 2024. Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models. In62nd Annual Meeting of the Association for Computational Linguistics (ACL)
work page 2024
- [13]
-
[14]
Shuyang Liu, Yang Chen, Rahul Krishna, et al. 2026. Process-Centric Analysis of Agentic Software Systems.arXiv preprint arXiv:2512.02393(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [15]
- [16]
- [17]
-
[18]
Tural Mehtiyev and Wesley Assunção. 2026. Supplementary material uploaded as part of the paper. https://zenodo.org/records/19351830?preview=1&token=eyJh bGciOiJIUzUxMiJ9.eyJpZCI6IjRhN2QwMzAwLTEwYWItNDJiYS1hMDgxLWV mZmI3MDI1ZjQwNyIsImRhdGEiOnt9LCJyYW5kb20iOiJlMDMyNThjYzQ5Z Dc5MjkyNDdjODg2ZGU1YTJjZGUxMCJ9.DfDdG85SXug_ZUp1UbkhJuvzaH xWczC90r8esizwPmdZL-6h9xQ...
- [19]
-
[20]
OpenAI. 2024. Introducing SWE-bench Verified. https://openai.com/index/intro ducing-swe-bench-verified/. 93 human annotators provided difficulty estimates for each of the 500 tasks. Annotation instructions: https://cdn.openai.com/intro ducing-swe-bench-verified/swe-b-annotation-instructions.pdf
work page 2024
-
[21]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2024. Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I Learned to Start Worrying about Prompt Formatting. In12th International Conference on Learning Representations (ICLR)
work page 2024
-
[22]
SWE-Bench Pro Team. 2025. SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?arXiv preprint arXiv:2509.16941(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
SWE-bench Team. 2025. SWE-bench Verified Leaderboard. https://www.sweben ch.com. Accessed March 2026
work page 2025
- [24]
-
[25]
Lei Wang, Chen Ma, Xueyang Feng, et al. 2024. A Survey on Large Language Model based Autonomous Agents.Frontiers of Computer Science18, 6 (2024), 186345
work page 2024
-
[26]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, et al
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, et al. 2025. OpenHands: An Open Plat- form for AI Software Developers as Generalist Agents. InInternational Conference on Learning Representations (ICLR)
work page 2025
-
[27]
Cathrin Weiss, Rahul Premraj, Thomas Zimmermann, and Andreas Zeller. 2007. How Long Will It Take to Fix This Bug?. InProceedings of the Fourth International Workshop on Mining Software Repositories (MSR). doi:10.1109/MSR.2007.13
-
[28]
Chunqiu Steven Xia et al. 2025. Agentless: Demystifying LLM-based Software En- gineering Agents. InACM International Conference on the Foundations of Software Engineering (FSE)
work page 2025
-
[29]
John Yang, Carlos E. Jimenez, et al. 2024. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems (NeurIPS)
work page 2024
-
[30]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
work page 2023
-
[31]
Daoguang Zan et al . 2025. Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving. OpenReview, under review
work page 2025
- [32]
-
[33]
Yuntong Zhang et al. 2024. AutoCodeRover: Autonomous Program Improve- ment. InACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA)
work page 2024
-
[34]
Jingming Zhuo, Songyang Zhang, Xinyu Fang, Haodong Duan, Dahua Lin, and Kai Chen. 2024. ProSA: Assessing and Understanding the Prompt Sensitivity of LLMs. InFindings of the Association for Computational Linguistics: EMNLP 2024. 1950–1976
work page 2024
-
[35]
Thomas Zimmermann, Nachiappan Nagappan, Harald Gall, Emanuel Giger, and Brendan Murphy. 2009. Cross-project Defect Prediction: A Large Scale Experiment on Data vs. Domain vs. Process. InProceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIG- SOFT Symposium on the Foundations of Software Engineering (ESEC/FSE)....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.