Recognition: 2 theorem links
· Lean TheoremAn Empirical Study of Many-Shot In-Context Learning for Machine Translation of Low-Resource Languages
Pith reviewed 2026-05-13 20:44 UTC · model grok-4.3
The pith
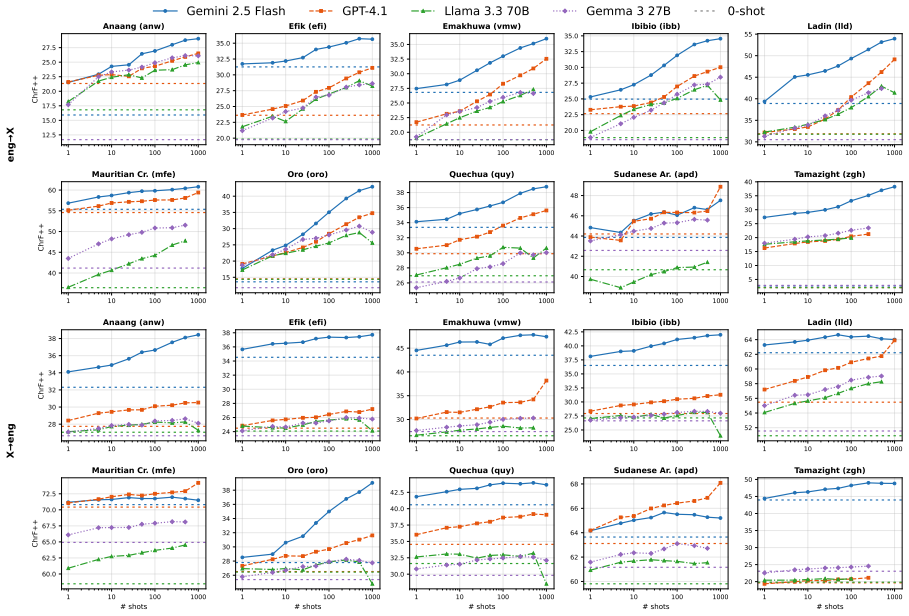
BM25 retrieval makes many-shot in-context learning five times more data-efficient for translating English into low-resource languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Many-shot in-context learning for machine translation becomes more effective as the number of examples increases. BM25-based retrieval substantially improves data efficiency: 50 retrieved examples roughly match the performance of 250 many-shot examples, while 250 retrieved examples perform similarly to 1,000 many-shot examples.
What carries the argument
BM25-based retrieval to select informative examples for many-shot in-context learning prompts.
If this is right
- Translation quality scales with example count under many-shot ICL for these languages.
- Retrieval cuts inference cost while preserving quality, making the method more usable in low-resource settings.
- Out-of-domain examples and length-based ordering produce measurable but secondary effects compared with retrieval.
- The approach directly addresses the high inference cost that otherwise limits many-shot ICL for communities with limited compute.
Where Pith is reading between the lines
- Similar retrieval selection could reduce example counts in other sequence-generation tasks that use long contexts.
- Low-resource language communities could pre-build compact, high-value example sets instead of relying on random sampling.
- The efficiency pattern may encourage wider adoption of many-shot prompts once retrieval pipelines are added to standard toolkits.
- Testing whether denser retrievers or learned selectors beat BM25 on the same languages would be a direct next measurement.
Load-bearing premise
The efficiency gains observed with BM25 retrieval hold for the specific models, languages, and data domains used in the experiments.
What would settle it
Re-running the exact protocol on a new large language model or a fresh set of low-resource languages and finding that BM25 no longer reduces the required example count by a factor of roughly five would falsify the data-efficiency claim.
Figures


read the original abstract
In-context learning (ICL) allows large language models (LLMs) to adapt to new tasks from a few examples, making it promising for languages underrepresented in pre-training. Recent work on many-shot ICL suggests that modern LLMs can further benefit from larger ICL examples enabled by their long context windows. However, such gains depend on careful example selection, and the inference cost can be prohibitive for low-resource language communities. In this paper, we present an empirical study of many-shot ICL for machine translation from English into ten truly low-resource languages recently added to FLORES+. We analyze the effects of retrieving more informative examples, using out-of-domain data, and ordering examples by length. Our findings show that many-shot ICL becomes more effective as the number of examples increases. More importantly, we show that BM25-based retrieval substantially improves data efficiency: 50 retrieved examples roughly match 250 many-shot examples, while 250 retrieved examples perform similarly to 1,000 many-shot examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical study of many-shot in-context learning (ICL) for English-to-low-resource machine translation across ten languages newly added to FLORES+. It examines scaling with larger numbers of examples, BM25-based retrieval versus random selection, the role of out-of-domain data, and example ordering by length. The central claims are that many-shot ICL performance improves as the number of examples grows and that BM25 retrieval yields large data-efficiency gains, with 50 retrieved examples roughly matching 250 random many-shot examples and 250 retrieved examples performing similarly to 1,000 random ones.
Significance. If the reported efficiency ratios hold, the results offer concrete, actionable guidance for reducing inference costs when applying LLMs to truly low-resource MT. The empirical focus on retrieval and scaling provides a useful baseline for the community. However, the significance is limited by the narrow set of models and languages tested; broader validation would be needed to establish the findings as a general property of BM25 retrieval in ICL.
major comments (2)
- [§3 (Experiments and Results)] §3 (Experiments and Results): The headline efficiency equivalences (50 BM25 ≈ 250 random; 250 BM25 ≈ 1,000 random) are presented without reported statistical significance tests, confidence intervals, or variance across runs or seeds. This makes it impossible to determine whether the observed matches fall within noise and directly undermines the data-efficiency claim.
- [§4 (Discussion/Limitations)] §4 (Discussion/Limitations): No cross-model ablations or additional language pairs beyond the ten FLORES+ languages are included. The efficiency ratios are therefore demonstrated only under the specific LLMs, domains, and language set tested, leaving open whether they reflect a general property of BM25 retrieval or are tied to those exact conditions.
minor comments (1)
- [Abstract] Abstract: The abstract omits the specific LLMs used and the primary evaluation metrics (BLEU, COMET, etc.), which would allow readers to contextualize the numerical claims immediately.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We appreciate the emphasis on statistical rigor and scope, and will revise the manuscript to strengthen these aspects while preserving the empirical focus of the study.
read point-by-point responses
-
Referee: [§3 (Experiments and Results)] §3 (Experiments and Results): The headline efficiency equivalences (50 BM25 ≈ 250 random; 250 BM25 ≈ 1,000 random) are presented without reported statistical significance tests, confidence intervals, or variance across runs or seeds. This makes it impossible to determine whether the observed matches fall within noise and directly undermines the data-efficiency claim.
Authors: We agree that statistical significance testing and variance reporting are needed to support the efficiency claims. In the revised manuscript, we will add bootstrap confidence intervals computed across the ten languages for the key comparisons (50 BM25 vs. 250 random and 250 BM25 vs. 1,000 random) and report standard deviations where feasible. While full multi-seed reruns are computationally expensive for many-shot inference, the observed trends hold consistently across all languages, and we will quantify this robustness explicitly. revision: yes
-
Referee: [§4 (Discussion/Limitations)] §4 (Discussion/Limitations): No cross-model ablations or additional language pairs beyond the ten FLORES+ languages are included. The efficiency ratios are therefore demonstrated only under the specific LLMs, domains, and language set tested, leaving open whether they reflect a general property of BM25 retrieval or are tied to those exact conditions.
Authors: We acknowledge that the efficiency ratios are demonstrated for the specific models and the ten FLORES+ languages studied. The paper is framed as an empirical investigation providing concrete guidance for these low-resource settings rather than claiming universality. We will expand the limitations section to state this scope more explicitly and to recommend broader validation across models and languages as future work. Additional cross-model ablations would require substantial extra compute beyond the current study. revision: partial
Circularity Check
No circularity: purely empirical comparisons with no derivations or self-referential reductions
full rationale
The paper is an empirical study reporting direct experimental results on many-shot ICL for MT across ten FLORES+ languages. All key claims (e.g., performance scaling with example count and BM25 retrieval efficiency gains such as 50 retrieved ≈ 250 random) are grounded in measured BLEU/CHRF scores from controlled runs, not in any equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation chain exists that reduces outputs to inputs by construction; the work contains no mathematical modeling, uniqueness theorems, or ansatzes. Generalization limits are acknowledged as an external validity concern rather than a circularity issue.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our findings show that many-shot ICL becomes more effective as the number of examples increases. More importantly, we show that BM25-based retrieval substantially improves data efficiency: 50 retrieved examples roughly match 250 many-shot examples, while 250 retrieved examples perform similarly to 1,000 many-shot examples.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We focus on ten extremely low-resource languages... scaling from 0 to 1,000 parallel examples and evaluating four LLMs.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
David Ifeoluwa Adelani, Jesujoba Oluwadara Alabi, Angela Fan, Julia Kreutzer, Xiaoyu Shen, Machel Reid, Dana Ruiter, Dietrich Klakow, Peter Nabende, Ernie Chang, Tajuddeen Gwadabe, Freshia Sackey, Bonaventure F. P. Dossou, Chris Emezue, Colin Leong, Michael Beukman, Shamsuddeen H. Muhammad, Guyo D. Jarso, Oreen Yousuf, and 26 others. 2022. https://doi.org...
-
[2]
Zhang, Bernd Bohnet, Luis Rosias, Stephanie C
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie C. Y. Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, and Hugo Larochelle. 2024. https://openreview.net/forum?id=AB6XpMzvqH Many- Shot In - Context Learning . In The Thirty -eighth Annual Conference on Ne...
work page 2024
-
[3]
Sweta Agrawal, Chunting Zhou, Mike Lewis, Luke Zettlemoyer, and Marjan Ghazvininejad. 2023. https://doi.org/10.18653/v1/2023.findings-acl.564 In-context examples selection for machine translation . In Findings of the Association for Computational Linguistics: ACL 2023, pages 8857--8873, Toronto, Canada. Association for Computational Linguistics
-
[4]
Felermino Dario Mario Ali, Henrique Lopes Cardoso, and Rui Sousa-Silva. 2024. https://doi.org/10.18653/v1/2024.wmt-1.45 Expanding FLORES + benchmark for more low-resource settings: P ortuguese-emakhuwa machine translation evaluation . In Proceedings of the Ninth Conference on Machine Translation, pages 579--592, Miami, Florida, USA. Association for Comput...
-
[5]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
work page 2020
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan-Jiang Jiang, and 3416 others. 2025. https://arxiv.org/abs/2507.06261 Gemini 2.5: Pus...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Sara Court and Micha Elsner. 2024. https://doi.org/10.18653/v1/2024.wmt-1.125 Shortcomings of LLM s for low-resource translation: Retrieval and understanding are both the problem . In Proceedings of the Ninth Conference on Machine Translation, pages 1332--1354, Miami, Florida, USA. Association for Computational Linguistics
-
[8]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.64 A survey on in-context learning . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1107--1128, Miami, Florid...
-
[9]
Andrew Drozdov, Honglei Zhuang, Zhuyun Dai, Zhen Qin, Razieh Rahimi, Xuanhui Wang, Dana Alon, Mohit Iyyer, Andrew McCallum, Donald Metzler, and Kai Hui. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.950 P a R a D e: Passage ranking using demonstrations with LLM s . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 142...
-
[10]
Samuel Frontull, Thomas Str \"o hle, Carlo Zoli, Werner Pescosta, Ulrike Frenademez, Matteo Ruggeri, Daria Valentin, Karin Comploj, Gabriel Perathoner, Silvia Liotto, and Paolo Anvidalfarei. 2025. https://aclanthology.org/2025.wmt-1.81/ Bringing L adin to FLORES + . In Proceedings of the Tenth Conference on Machine Translation, pages 1061--1071, Suzhou, C...
work page 2025
-
[11]
Gemini-Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, and 1 others. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Juraj Juraska, Mara Finkelstein, Daniel Deutsch, Aditya Siddhant, Mehdi Mirzazadeh, and Markus Freitag. 2023. https://doi.org/10.18653/v1/2023.wmt-1.63 M etric X -23: The G oogle submission to the WMT 2023 metrics shared task . In Proceedings of the Eighth Conference on Machine Translation, pages 756--767, Singapore. Association for Computational Linguistics
-
[14]
Oluwadara Kalejaiye, Luel Hagos Beyene, David Ifeoluwa Adelani, Mmekut-mfon Gabriel Edet, Aniefon Daniel Akpan, Eno-Abasi Urua, and Anietie Andy. 2025. https://aclanthology.org/2025.ijcnlp-long.22/ Ibom NLP : A step toward inclusive natural language processing for N igeria ' s minority languages . In Proceedings of the 14th International Joint Conference ...
work page 2025
-
[15]
Xiaonan Li and Xipeng Qiu. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.411 Finding support examples for in-context learning . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 6219--6235, Singapore. Association for Computational Linguistics
-
[16]
Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O ' Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, and 2 others. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.616 Fe...
-
[17]
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. https://doi.org/10.18653/v1/2022.acl-long.556 Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086-...
-
[18]
Man Luo, Xin Xu, Yue Liu, Panupong Pasupat, and Mehran Kazemi. 2024. https://openreview.net/forum?id=NQPo8ZhQPa In-context learning with retrieved demonstrations for language models: A survey . Transactions on Machine Learning Research. Survey Certification
work page 2024
-
[19]
Ali Marashian, Enora Rice, Luke Gessler, Alexis Palmer, and Katharina von der Wense. 2025. https://aclanthology.org/2025.coling-main.472/ From priest to doctor: Domain adaptation for low-resource neural machine translation . In Proceedings of the 31st International Conference on Computational Linguistics, pages 7087--7098, Abu Dhabi, UAE. Association for ...
work page 2025
-
[20]
NLLB Team , Marta R. Costa-juss \`a , James Cross, Onur C elebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, and 20 others. 2024. https://doi.org/10.1038/s41586-024-073...
-
[21]
Alp Oktem, Mohamed Aymane Farhi, Brahim Essaidi, Naceur Jabouja, and Farida Boudichat. 2025. https://aclanthology.org/2025.wmt-1.82/ Correcting the tamazight portions of FLORES + and OLDI seed datasets . In Proceedings of the Tenth Conference on Machine Translation, pages 1072--1080, Suzhou, China. Association for Computational Linguistics
work page 2025
-
[22]
Renhao Pei, Yihong Liu, Peiqin Lin, Fran c ois Yvon, and Hinrich Schuetze. 2025. https://doi.org/10.18653/v1/2025.acl-long.429 Understanding in-context machine translation for low-resource languages: A case study on M anchu . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8767--878...
-
[23]
Maja Popovi \'c . 2017. https://doi.org/10.18653/v1/W17-4770 chr F ++: words helping character n-grams . In Proceedings of the Second Conference on Machine Translation, pages 612--618, Copenhagen, Denmark. Association for Computational Linguistics
- [24]
-
[25]
Yush Rajcoomar. 2025. https://doi.org/10.18653/v1/2025.wmt-1.92 K oz K reol MRU WMT 2025 C reole MT system description: Koz kreol: Multi-stage training for E nglish -- mauritian creole MT . In Proceedings of the Tenth Conference on Machine Translation, pages 1183--1190, Suzhou, China. Association for Computational Linguistics
-
[26]
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.213 COMET : A neural framework for MT evaluation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685--2702, Online. Association for Computational Linguistics
-
[27]
Stephen Robertson and Hugo Zaragoza. 2009. https://doi.org/10.1561/1500000019 The probabilistic relevance framework: Bm25 and beyond . Found. Trends Inf. Retr., 3(4):333–389
- [28]
-
[29]
Hadia Mohmmedosman Ahmed Samil and David Ifeoluwa Adelani. 2026. https://openreview.net/forum?id=uLKTcetdkB Sudanese-flores: Extending FLORES + to sudanese arabic dialect . In 7th Workshop on African Natural Language Processing
work page 2026
-
[30]
Garrett Tanzer, Mirac Suzgun, Eline Visser, Dan Jurafsky, and Luke Melas-Kyriazi. 2024. https://openreview.net/forum?id=tbVWug9f2h A benchmark for learning to translate a new language from one grammar book . In The Twelfth International Conference on Learning Representations
work page 2024
-
[31]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, and et al. 2025. https://arxiv.org/abs/2503.19786 Gemma 3 technical report . Preprint, arXiv:2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Inacio Vieira, Will Allred, S \'e amus Lankford, Sheila Castilho, and Andy Way. 2024. https://aclanthology.org/2024.amta-research.20/ How much data is enough data? fine-tuning large language models for in-house translation: Performance evaluation across multiple dataset sizes . In Proceedings of the 16th Conference of the Association for Machine Translati...
work page 2024
-
[33]
Biao Zhang, Barry Haddow, and Alexandra Birch. 2023. Prompting large language model for machine translation: A case study. In International conference on machine learning, pages 41092--41110. PMLR
work page 2023
-
[34]
Chen Zhang, Xiao Liu, Jiuheng Lin, and Yansong Feng. 2024. https://doi.org/10.18653/v1/2024.findings-acl.519 Teaching Large Language Models an Unseen Language on the Fly . In Findings of the Association for Computational Linguistics : ACL 2024 , pages 8783--8800, Bangkok, Thailand. Association for Computational Linguistics
-
[35]
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. 2024. https://doi.org/10.18653/v1/2024.findings-naacl.176 Multilingual machine translation with large language models: Empirical results and analysis . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2765--2781, Mexico ...
-
[36]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[37]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.