Recognition: 2 theorem links
· Lean TheoremWGFINNs: Weak formulation-based GENERIC formalism informed neural networks
Pith reviewed 2026-05-13 20:59 UTC · model grok-4.3
The pith
WGFINNs use weak formulations to make neural networks robust to noise while exactly preserving thermodynamic laws.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
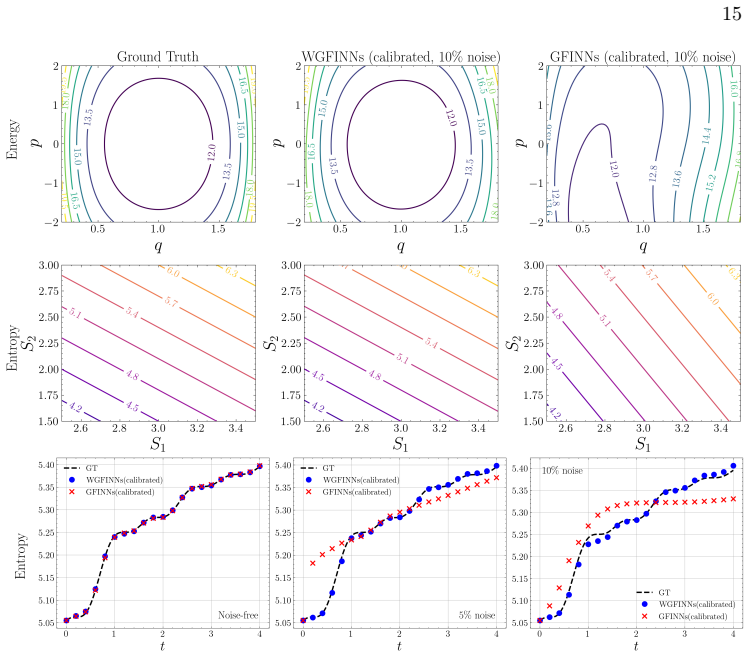
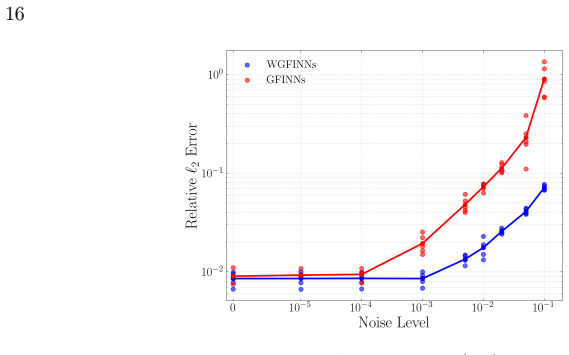
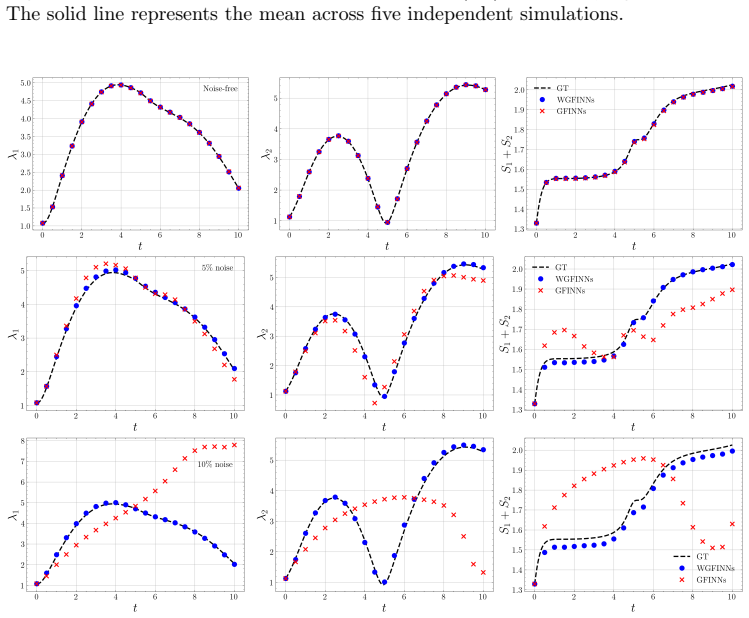
WGFINNs integrate the weak formulation of dynamical systems with the structure-preserving architecture of GFINNs, yielding networks that enhance robustness to noisy data while retaining exact satisfaction of GENERIC degeneracy and symmetry conditions. A state-wise weighted loss and residual-based attention mechanism address scale imbalance across state variables. Theoretical analysis shows that the strong-form estimator diverges as the time step decreases under noise, whereas the weak-form estimator can remain accurate when test functions satisfy appropriate conditions. Numerical experiments confirm that WGFINNs consistently outperform GFINNs at varying noise levels with more accurate state,
What carries the argument
Weak formulation of the dynamical system equations embedded in the loss of a GENERIC formalism informed neural network, augmented by state-wise weighting and residual attention.
If this is right
- WGFINNs outperform GFINNs consistently in prediction accuracy at multiple noise levels.
- They enable more reliable recovery of physical quantities from noisy observations.
- Exact enforcement of GENERIC degeneracy and symmetry conditions is retained despite noise.
- State-wise weighting and attention reduce scale imbalance problems among variables.
Where Pith is reading between the lines
- The weak-form strategy could be transferred to other structure-preserving neural network architectures that currently rely on strong-form losses.
- Finer time resolution in data collection may become usable without loss of model fidelity.
- Hybrid combinations with finite-element discretizations could extend the approach to spatially extended systems.
Load-bearing premise
The test functions chosen for the weak formulation satisfy conditions that keep the estimator accurate even when data contain noise.
What would settle it
An experiment in which WGFINNs produce prediction errors or recovered physical quantities no better than GFINNs across tested noise levels would falsify the claimed robustness advantage.
Figures














read the original abstract
Data-driven discovery of governing equations from noisy observations remains a fundamental challenge in scientific machine learning. While GENERIC formalism informed neural networks (GFINNs) provide a principled framework that enforces the laws of thermodynamics by construction, their reliance on strong-form loss formulations makes them highly sensitive to measurement noise. To address this limitation, we propose weak formulation-based GENERIC formalism informed neural networks (WGFINNs), which integrate the weak formulation of dynamical systems with the structure-preserving architecture of GFINNs. WGFINNs significantly enhance robustness to noisy data while retaining exact satisfaction of GENERIC degeneracy and symmetry conditions. We further incorporate a state-wise weighted loss and a residual-based attention mechanism to mitigate scale imbalance across state variables. Theoretical analysis contrasts quantitative differences between the strong-form and the weak-form estimators. Mainly, the strong-form estimator diverges as the time step decreases in the presence of noise, while the weak-form estimator can be accurate even with noisy data if test functions satisfy certain conditions. Numerical experiments demonstrate that WGFINNs consistently outperform GFINNs at varying noise levels, achieving more accurate predictions and reliable recovery of physical quantities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WGFINNs as an extension of GFINNs that replaces the strong-form loss with a weak-form loss to improve robustness to measurement noise when discovering governing equations for systems obeying the GENERIC formalism. The architecture is designed to enforce degeneracy and symmetry conditions exactly, with added state-wise weighted loss and residual-based attention to handle scale imbalance. Theoretical analysis contrasts the divergence of strong-form estimators under noise as time step decreases with the potential accuracy of weak-form estimators when test functions meet unspecified conditions; numerical experiments on several systems claim consistent outperformance over GFINNs across noise levels.
Significance. If the robustness advantage is substantiated, the work would provide a useful advance for structure-preserving scientific machine learning by enabling reliable equation discovery from noisy data while preserving thermodynamic structure, extending prior GFINN results with a principled weak-form approach.
major comments (3)
- [Abstract / Theoretical analysis] Abstract and theoretical analysis section: The central claim that the weak-form estimator 'can be accurate even with noisy data if test functions satisfy certain conditions' does not state what those conditions are, nor does the manuscript demonstrate that the test functions used in the numerical experiments satisfy them. This is load-bearing for both the theoretical contrast with strong-form estimators and the empirical robustness advantage.
- [Numerical experiments] Numerical experiments section: No quantitative error bars, confidence intervals, or exact specifications of how noise was added (distribution, variance per state variable, time-step dependence) are provided, so the claim of consistent outperformance over GFINNs at varying noise levels cannot be fully assessed.
- [Methods / Architecture] Methods section on architecture: The introduction of state-wise weighted loss and residual-based attention is presented as preserving exact GENERIC degeneracy and symmetry, but the manuscript does not explicitly show how these modifications maintain the exact enforcement (e.g., via the same projection or constraint mechanism as in GFINNs) rather than approximately.
minor comments (2)
- [Theoretical analysis] Notation for the weak-form loss and test-function space is introduced without a clear reference to standard Sobolev-space definitions or explicit statement of the integration-by-parts boundary terms assumed to vanish.
- [Numerical experiments] Figure captions and legends do not consistently report the exact noise levels or number of independent runs used for the plotted trajectories.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help us improve the clarity and rigor of the manuscript. We address each major comment below and will incorporate revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract / Theoretical analysis] Abstract and theoretical analysis section: The central claim that the weak-form estimator 'can be accurate even with noisy data if test functions satisfy certain conditions' does not state what those conditions are, nor does the manuscript demonstrate that the test functions used in the numerical experiments satisfy them. This is load-bearing for both the theoretical contrast with strong-form estimators and the empirical robustness advantage.
Authors: We agree that the conditions on the test functions require explicit statement and verification. In the revised manuscript, we will expand the theoretical analysis section to specify the conditions (test functions belonging to a suitable Sobolev space with sufficient smoothness to ensure the integration-by-parts identity holds exactly in the weak form, without residual boundary or approximation errors). We will also add a short verification subsection in the numerical experiments demonstrating that the chosen test functions (piecewise linear or quadratic polynomials on the time grid) satisfy these conditions for the reported systems. revision: yes
-
Referee: [Numerical experiments] Numerical experiments section: No quantitative error bars, confidence intervals, or exact specifications of how noise was added (distribution, variance per state variable, time-step dependence) are provided, so the claim of consistent outperformance over GFINNs at varying noise levels cannot be fully assessed.
Authors: We accept this point and will revise the numerical experiments section to include quantitative error bars (mean and standard deviation over 10 independent random seeds) for all reported metrics. We will also add an explicit noise specification: independent additive Gaussian noise with zero mean and variance equal to a stated percentage of each state variable's clean-data standard deviation, applied uniformly across time steps with no time-step dependence. revision: yes
-
Referee: [Methods / Architecture] Methods section on architecture: The introduction of state-wise weighted loss and residual-based attention is presented as preserving exact GENERIC degeneracy and symmetry, but the manuscript does not explicitly show how these modifications maintain the exact enforcement (e.g., via the same projection or constraint mechanism as in GFINNs) rather than approximately.
Authors: We thank the referee for highlighting the need for explicit clarification. The state-wise weighting and residual-based attention modify only the loss function used during training; they do not alter the network output projection that enforces degeneracy and symmetry. The projection step remains identical to that in GFINNs and is applied after the network forward pass, guaranteeing exact satisfaction independent of the loss weighting. In the revised methods section we will insert a dedicated paragraph (with the relevant equations) that separates the constraint-enforcement mechanism from the loss modifications and confirms that exactness is preserved. revision: yes
Circularity Check
Minor self-citation to prior GFINN architecture; weak-form loss and robustness analysis are independent additions
full rationale
The derivation introduces a new weak-form loss integrated with the existing GFINN structure-preserving network. The exact degeneracy and symmetry conditions are enforced by the base architecture (inherited via citation), but the central claims about noise robustness and divergence of strong-form estimators derive from the added weak-form estimator and test-function analysis, which do not reduce to a redefinition or fit of the same data. No equations equate a prediction to a fitted input by construction, and the self-citation is not load-bearing for the novel theoretical contrast or numerical outperformance. This is a standard, non-circular extension.
Axiom & Free-Parameter Ledger
free parameters (1)
- state-wise loss weights
axioms (1)
- domain assumption GENERIC degeneracy and symmetry conditions must hold for the learned dynamics
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WGFINNs integrate the weak formulation of dynamical systems with the structure-preserving architecture of GFINNs... retaining exact satisfaction of GENERIC degeneracy and symmetry conditions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the strong-form estimator diverges as the time step decreases in the presence of noise, while the weak-form estimator can be accurate even with noisy data if test functions satisfy certain conditions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[1]P. J. Schmid,Dynamic mode decomposition of numerical and experimental data, Journal of Fluid Mechanics, 656 (2010), pp. 5–28. [2]C. W. Rowley, I. Mezić, S. Bagheri, P. Schlatter, and D. S. Henningson,Spectral analysis of nonlinear flows, Journal of fluid mechanics, 641 (2009), pp. 115–127,https: //doi.org/10.1017/S0022112009992059. [3]J. H. Tu, C. W. R...
- [2]
-
[3]
[20]K. Champion, B. Lusch, J. N. Kutz, and S. L. Brunton,Data-driven discovery of co- ordinates and governing equations, Proceedings of the National Academy of Sciences, 116 (2019), pp. 22445–22451. [21]B. Kim, V. C. Azevedo, N. Thuerey, T. Kim, M. Gross, and B. Solenthaler,Deep fluids: A generative network for parameterized fluid simulations, in Computer...
-
[4]
[32]H. C. Öttinger and M. Grmela,Dynamics and thermodynamics of complex fluids. II. Illustrations of a general formalism, Physical Review E, 56 (1997), p
work page 1997
-
[5]
[34]Q. Hernandez, A. Badias, D. Gonzalez, F. Chinesta, and E. Cueto,Structure- preserving neural networks, Journal of Computational Physics, 426 (2021), p. 109950. [35]Q. Hernandez, A. Badias, D. Gonzalez, F. Chinesta, and E. Cueto,Deep learning of thermodynamics-aware reduced-order models from data, Computer Methods in Applied Mechanics and Engineering, ...
work page 2021
-
[6]
[44]M. Tang, W. Liao, R. Kuske, and S. H. Kang,Weakident: Weak formulation for identify- ing differential equation using narrow-fit and trimming, Journal of Computational Physics, 483 (2023), p. 112069. [45]A. Tran, X. He, D. A. Messenger, Y. Choi, and D. M. Bortz,Weak-form latent space dynamics identification, Computer Methods in Applied Mechanics and En...
-
[7]
[57]Z. Liu, Y. W ang, S. V aidya, F. Ruehle, J. Hal verson, M. Soljacić, T. Y. Hou, and M. Tegmark,Kan: Kolmogorov-arnold networks, arXiv preprint arXiv:2404.19756, (2024). [58]X. He, Y. Shin, A. Gruber, S. Jung, K. Lee, and Y. Choi,Thermodynamically consistent latent dynamics identification for parametric systems, Transactions on Machine Learning Researc...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.