An Online Learning Approach for Two-Player Zero-Sum Linear Quadratic Games
Pith reviewed 2026-05-13 20:44 UTC · model grok-4.3
The pith
An online algorithm learns stabilizing policies for two-player zero-sum linear quadratic games by selecting surrogate models inside high-probability confidence sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying a shrinkage step at each episode to identify a surrogate model in the region where the generalized algebraic Riccati equation admits a stabilizing saddle point solution, the framework maintains a regular model for policy updates, establishes regret bounds on algorithm convergence, and guarantees stability for two-player zero-sum linear quadratic games with unknown dynamics.
What carries the argument
The shrinkage step that selects a surrogate model inside the high-probability confidence set around the estimated dynamics such that the generalized algebraic Riccati equation yields a stabilizing saddle-point solution.
If this is right
- Policy updates remain stabilizing at every episode.
- The algorithm achieves bounded regret relative to the optimal equilibrium.
- The learned policies converge to the Nash equilibrium of the game.
- The approach extends model-based learning to adversarial zero-sum settings while preserving closed-loop stability.
Where Pith is reading between the lines
- The method could be tested on physical platforms such as competitive robot navigation where dynamics are learned on the fly.
- Relaxing the surrogate existence assumption might allow broader classes of uncertain dynamics.
- The confidence-set plus shrinkage pattern may transfer to other robust control problems with saddle-point objectives.
Load-bearing premise
A surrogate model always exists inside the high-probability confidence set for which the generalized algebraic Riccati equation admits a stabilizing saddle-point solution, and the shrinkage step can reliably locate it.
What would settle it
A simulation or experiment in which no model inside the constructed confidence set admits a stabilizing saddle-point solution for the generalized algebraic Riccati equation, causing the shrinkage step to fail and the closed-loop system to become unstable.
Figures

read the original abstract
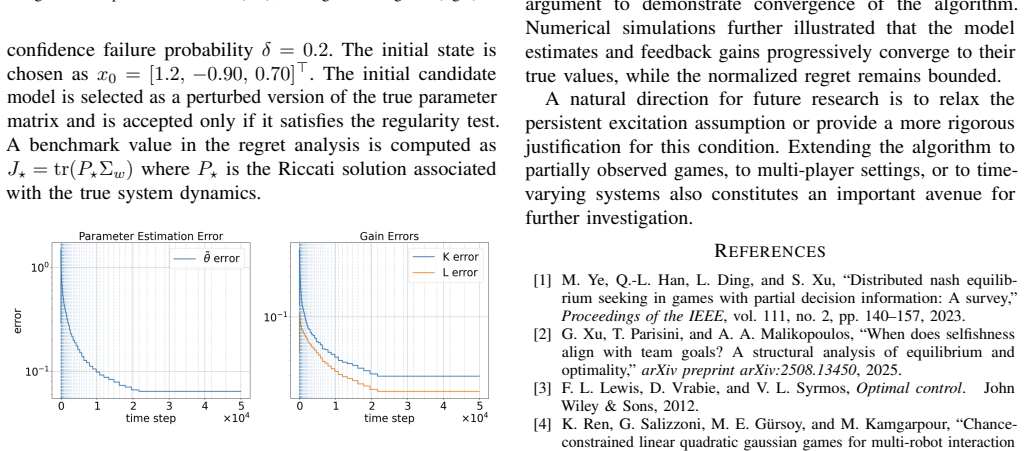
In this paper, we present an online learning approach for two-player zero-sum linear quadratic games with unknown dynamics. We develop a framework combining regularized least squares model estimation, high probability confidence sets, and surrogate model selection to maintain a regular model for policy updates. We apply a shrinkage step at each episode to identify a surrogate model in the region where the generalized algebraic Riccati equation admits a stabilizing saddle point solution. We then establish regret analysis on algorithm convergence, followed by a numerical example to illustrate the convergence performance and verify the regret analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an online learning algorithm for two-player zero-sum linear-quadratic games with unknown dynamics. It combines regularized least-squares estimation, high-probability confidence ellipsoids, and a shrinkage step that selects a surrogate model inside the ellipsoid for which the generalized algebraic Riccati equation admits a stabilizing saddle-point solution. Regret bounds are stated for the resulting policy sequence, and a numerical example is provided to illustrate convergence.
Significance. If the central guarantee that a stabilizing surrogate always exists inside the confidence set holds and the regret analysis is free of circular dependence on post-selection quantities, the work would extend existing single-player adaptive LQR results to the zero-sum game setting and supply a concrete template for maintaining well-posed Riccati solutions under uncertainty. The numerical illustration is consistent with the claimed convergence rate but does not yet constitute independent verification of the high-probability claims.
major comments (2)
- [Algorithm description and main theorem] The manuscript assumes without proof that the intersection of the high-probability confidence ellipsoid with the set of models admitting a stabilizing saddle-point solution for the generalized algebraic Riccati equation is nonempty at every episode (see the description of the shrinkage step following the model-estimation phase). No explicit argument or lemma establishes that the shrinkage operator is guaranteed to land inside this intersection on the high-probability event; if the intersection is empty for some realizations, the policy-update step is undefined and the subsequent regret bound does not apply.
- [Regret analysis] The regret analysis appears to condition on the event that a valid surrogate model is always selected. It is unclear whether the high-probability bound accounts for the probability that the shrinkage step fails to produce such a model, or whether an additional union bound or restart mechanism is introduced. This conditioning must be made explicit before the regret statement can be considered unconditional.
minor comments (2)
- [Preliminaries] Notation for the generalized algebraic Riccati equation and the associated saddle-point solution should be introduced with a self-contained definition before the shrinkage step is described.
- [Numerical example] The numerical example would benefit from reporting the empirical frequency with which the shrinkage step succeeds across Monte-Carlo runs, together with the observed regret slope on a log-log scale to allow direct visual comparison with the stated bound.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our work. We address the two major comments point by point below. Both points identify gaps in the current exposition that we will close in revision.
read point-by-point responses
-
Referee: The manuscript assumes without proof that the intersection of the high-probability confidence ellipsoid with the set of models admitting a stabilizing saddle-point solution for the generalized algebraic Riccati equation is nonempty at every episode (see the description of the shrinkage step following the model-estimation phase). No explicit argument or lemma establishes that the shrinkage operator is guaranteed to land inside this intersection on the high-probability event; if the intersection is empty for some realizations, the policy-update step is undefined and the subsequent regret bound does not apply.
Authors: We agree that the current manuscript does not contain an explicit lemma establishing non-emptiness of the intersection on the high-probability event. In the revision we will insert a new lemma (placed immediately before the algorithm description) that proves the following: on the event that the true dynamics lie inside the confidence ellipsoid (which holds with probability at least 1-δ), the ellipsoid necessarily intersects the set of models for which the GARE admits a stabilizing saddle-point solution. The argument relies on (i) the true model being stabilizing by assumption, (ii) continuity of the stabilizing solution of the GARE with respect to the system matrices (standard in the LQ literature), and (iii) the radius of the ellipsoid shrinking to zero. The shrinkage operator will then be formally defined as any selection rule that returns a point inside this intersection (e.g., a convex combination between the least-squares estimate and the boundary of the ellipsoid). revision: yes
-
Referee: The regret analysis appears to condition on the event that a valid surrogate model is always selected. It is unclear whether the high-probability bound accounts for the probability that the shrinkage step fails to produce such a model, or whether an additional union bound or restart mechanism is introduced. This conditioning must be made explicit before the regret statement can be considered unconditional.
Authors: The regret theorem is currently stated under the event that a valid surrogate is selected at every episode. In the revision we will (a) make this conditioning explicit in the theorem statement, (b) invoke the new lemma above to show that the probability of this event is at least 1-δ, and (c) absorb the complementary probability into the final high-probability regret bound via a simple union bound over the finite number of episodes. No restart mechanism is introduced; the failure probability is controlled directly by the choice of δ and the sample-size lower bound already present in the analysis. The revised theorem will therefore read as an unconditional high-probability statement. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's framework uses regularized least-squares estimation to build high-probability confidence sets, followed by an explicit shrinkage step to select a surrogate model inside the set where the generalized algebraic Riccati equation has a stabilizing saddle-point solution. The regret bound is then derived from this construction and standard online-learning arguments. No quoted step reduces a claimed prediction or result to a fitted input by definition, nor does any load-bearing premise collapse to a self-citation whose validity is internal to the paper. The central modeling assumption is stated outright rather than smuggled in via renaming or self-referential uniqueness. The numerical example serves only as illustration, leaving the analytic chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We apply a shrinkage step at each episode to identify a surrogate model in the region where the generalized algebraic Riccati equation admits a stabilizing saddle point solution.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Distributed nash equilib- rium seeking in games with partial decision information: A survey,
M. Ye, Q.-L. Han, L. Ding, and S. Xu, “Distributed nash equilib- rium seeking in games with partial decision information: A survey,” Proceedings of the IEEE, vol. 111, no. 2, pp. 140–157, 2023
work page 2023
-
[2]
When does selfishness align with team goals? A structural analysis of equilibrium and optimality,
G. Xu, T. Parisini, and A. A. Malikopoulos, “When does selfishness align with team goals? A structural analysis of equilibrium and optimality,”arXiv preprint arXiv:2508.13450, 2025
-
[3]
F. L. Lewis, D. Vrabie, and V . L. Syrmos,Optimal control. John Wiley & Sons, 2012
work page 2012
-
[4]
Chance- constrained linear quadratic gaussian games for multi-robot interaction under uncertainty,
K. Ren, G. Salizzoni, M. E. G ¨ursoy, and M. Kamgarpour, “Chance- constrained linear quadratic gaussian games for multi-robot interaction under uncertainty,”IEEE Control Systems Letters, 2025
work page 2025
-
[5]
V .-A. Le, B. Chalaki, V . Tadiparthi, H. N. Mahjoub, J. D’sa, E. Moradi- Pari, and A. A. Malikopoulos, “Multi-Robot Cooperative Navigation in Crowds: A Game-Theoretic Learning-Based Model Predictive Control Approach,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 4834–4840
work page 2024
-
[6]
Potential game-based decision-making for autonomous driving,
M. Liu, I. Kolmanovsky, H. E. Tseng, S. Huang, D. Filev, and A. Girard, “Potential game-based decision-making for autonomous driving,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 8, pp. 8014–8027, 2023
work page 2023
-
[7]
Game- theoretic learning-based mitigation of insider threats,
G. Xu, K. Chen, T. Parisini, and A. A. Malikopoulos, “Game- theoretic learning-based mitigation of insider threats,”arXiv preprint arXiv:2512.03222, 2025
-
[8]
I. V . Chremos and A. A. Malikopoulos, “Mechanism design theory in control engineering: A tutorial and overview of applications in communication, power grid, transportation, and security systems,”IEEE Control Systems, vol. 44, no. 1, pp. 20–45, 2024
work page 2024
-
[9]
T. Bas ¸ar and P. Bernhard,H-infinity optimal control and related minimax design problems: a dynamic game approach. Springer Science & Business Media, 2008
work page 2008
-
[10]
Separation of learning and control for cyber- physical systems,
A. A. Malikopoulos, “Separation of learning and control for cyber- physical systems,”Automatica, vol. 151, no. 110912, 2023
work page 2023
-
[11]
Combining learning and control in linear systems,
——, “Combining learning and control in linear systems,”European Journal of Control, vol. 80, no. Part A, p. 101043, 2024
work page 2024
-
[12]
Combined learning and control: A new paradigm for optimal control with unknown dynamics,
P. Kounatidis and A. A. Malikopoulos, “Combined learning and control: A new paradigm for optimal control with unknown dynamics,” in65th American Control Conference (ACC), 2025, in review
work page 2025
-
[13]
P. A. Ioannou and J. Sun,Robust adaptive control. PTR Prentice-Hall Upper Saddle River, NJ, 1996, vol. 1
work page 1996
-
[14]
Regret bounds for robust adaptive control of the linear quadratic regulator,
S. Dean, H. Mania, N. Matni, B. Recht, and S. Tu, “Regret bounds for robust adaptive control of the linear quadratic regulator,”Advances in Neural Information Processing Systems, vol. 31, 2018
work page 2018
-
[15]
Certainty equivalence is efficient for linear quadratic control,
H. Mania, S. Tu, and B. Recht, “Certainty equivalence is efficient for linear quadratic control,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[16]
Naive exploration is optimal for online lqr,
M. Simchowitz and D. Foster, “Naive exploration is optimal for online lqr,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 8937–8948
work page 2020
-
[17]
Policy optimization provably converges to nash equilibria in zero-sum linear quadratic games,
K. Zhang, Z. Yang, and T. Basar, “Policy optimization provably converges to nash equilibria in zero-sum linear quadratic games,” Advances in Neural Information Processing Systems, vol. 32, 2019
work page 2019
-
[18]
A. Al-Tamimi, F. L. Lewis, and M. Abu-Khalaf, “Model-free q-learning designs for linear discrete-time zero-sum games with application to h-infinity control,”Automatica, vol. 43, no. 3, pp. 473–481, 2007
work page 2007
-
[19]
B. Nortmann, A. Monti, M. Sassano, and T. Mylvaganam, “Nash equilibria for linear quadratic discrete-time dynamic games via iterative and data-driven algorithms,”IEEE Transactions on Automatic Control, vol. 69, no. 10, pp. 6561–6575, 2024
work page 2024
-
[20]
Improved algorithms for linear stochastic bandits,
Y . Abbasi-Yadkori, D. P´al, and C. Szepesv´ari, “Improved algorithms for linear stochastic bandits,”Advances in neural information processing systems, vol. 24, 2011
work page 2011
-
[21]
Regret bounds for the adaptive control of linear quadratic systems,
Y . Abbasi-Yadkori and C. Szepesv´ari, “Regret bounds for the adaptive control of linear quadratic systems,” inProceedings of the 24th annual conference on learning theory. JMLR Workshop and Conference Proceedings, 2011, pp. 1–26. APPENDIX A. Proof of Theorem 1 Proof:The proof proceeds in three steps: (i) we show that DP F(P ⋆, θ⋆) reduces to an invertibl...
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.