Recognition: no theorem link
Analytic Drift Resister for Non-Exemplar Continual Graph Learning
Pith reviewed 2026-05-13 20:48 UTC · model grok-4.3
The pith
Analytic merging of GNN layers resists feature drift to enable theoretically zero-forgetting non-exemplar continual graph learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ADR uses iterative backpropagation to adapt frozen pre-trained models to evolving graph distributions. HAM then merges linear transformations layer-wise in GNNs via ridge regression to guarantee absolute resistance to feature drift from updates. On this foundation ACR reconstructs classifiers to deliver theoretically zero-forgetting class-incremental learning.
What carries the argument
Hierarchical Analytic Merging (HAM), the layer-wise ridge regression that combines linear transformations in GNNs to block downstream feature drift.
If this is right
- Class-incremental learning proceeds on graphs without storing or replaying raw examples.
- Model plasticity is retained through backpropagation while past performance is preserved analytically.
- Competitive accuracy holds against state-of-the-art methods on four standard node classification benchmarks.
- Zero-forgetting is achieved at the classifier level for any sequence of class-incremental tasks.
Where Pith is reading between the lines
- The same ridge-regression merging step could be tested on other graph tasks such as link prediction to check drift resistance beyond node classification.
- Extending HAM beyond GNNs to standard MLPs might reveal whether the drift resistance is architecture-specific.
- Scaling the approach to larger graphs would test whether the analytic merge remains computationally tractable at high node counts.
Load-bearing premise
Layer-wise ridge regression merging of linear transformations in GNNs produces absolute resistance to feature drift induced by parameter updates.
What would settle it
Any observed drop in accuracy on earlier classes after training on a new class in the node classification benchmarks.
Figures


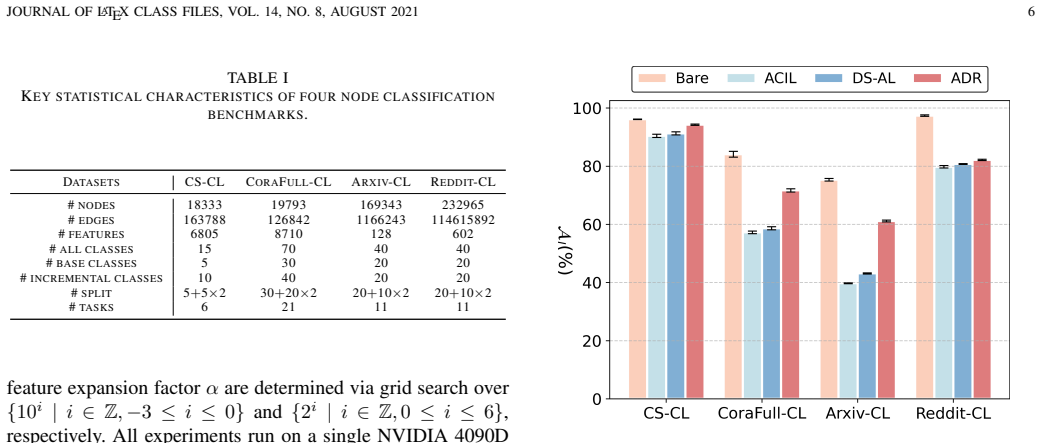


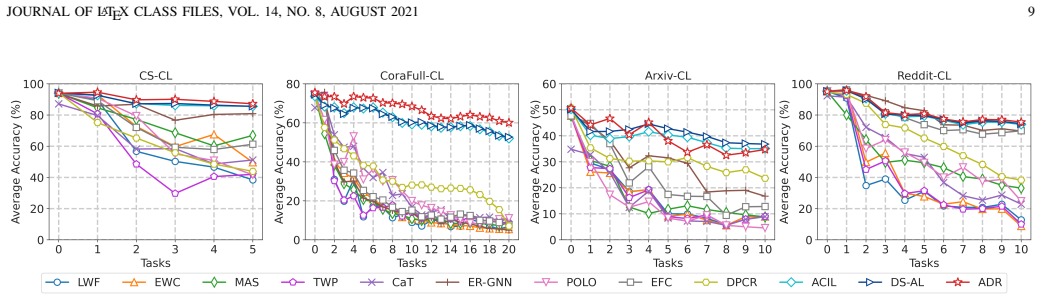

read the original abstract
Non-Exemplar Continual Graph Learning (NECGL) seeks to eliminate the privacy risks intrinsic to rehearsal-based paradigms by retaining solely class-level prototype representations rather than raw graph examples for mitigating catastrophic forgetting. However, this design choice inevitably precipitates feature drift. As a nascent alternative, Analytic Continual Learning (ACL) capitalizes on the intrinsic generalization properties of frozen pre-trained models to bolster continual learning performance. Nonetheless, a key drawback resides in the pronounced attenuation of model plasticity. To surmount these challenges, we propose Analytic Drift Resister (ADR), a novel and theoretically grounded NECGL framework. ADR exploits iterative backpropagation to break free from the frozen pre-trained constraint, adapting to evolving task graph distributions and fortifying model plasticity. Since parameter updates trigger feature drift, we further propose Hierarchical Analytic Merging (HAM), performing layer-wise merging of linear transformations in Graph Neural Networks (GNNs) via ridge regression, thereby ensuring absolute resistance to feature drift. On this basis, Analytic Classifier Reconstruction (ACR) enables theoretically zero-forgetting class-incremental learning. Empirical evaluation on four node classification benchmarks demonstrates that ADR maintains strong competitiveness against existing state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Analytic Drift Resister (ADR) for Non-Exemplar Continual Graph Learning. It uses iterative backpropagation to adapt pre-trained GNNs, Hierarchical Analytic Merging (HAM) via layer-wise ridge regression on linear transformations to achieve absolute resistance to feature drift induced by updates, and Analytic Classifier Reconstruction (ACR) to enable theoretically zero-forgetting class-incremental learning while retaining only class prototypes. Experiments on four node classification benchmarks report competitive performance against existing methods.
Significance. If the theoretical guarantees of absolute drift resistance and zero forgetting can be established, the framework would represent a meaningful advance in privacy-preserving continual graph learning by combining model plasticity with analytic merging, potentially influencing non-exemplar settings beyond graphs.
major comments (3)
- [§3.2] §3.2 (HAM description): The claim that layer-wise ridge regression merging produces 'absolute resistance to feature drift' is not supported. Ridge regression minimizes ||W_new X - W_old X||^2 + λ||W_new||^2 and leaves non-zero residual error in general; this residual propagates through non-linear activations and graph aggregations in GNNs, so the features supplied to ACR are not guaranteed identical to pre-update features.
- [Theoretical analysis] Theoretical analysis (around ACR): No equations, proof sketches, or bounds are supplied to show how ACR achieves zero forgetting once HAM is applied. The abstract asserts 'theoretically zero-forgetting' and 'theoretically grounded' guarantees, yet the central derivation linking merged parameters to identical classifier inputs is missing.
- [Experiments] Experiments section: Results are described only qualitatively as 'strong competitiveness' with no quantitative tables, per-task accuracies, forgetting metrics, or error bars visible. This prevents verification that the method actually delivers the claimed zero-forgetting behavior on the four benchmarks.
minor comments (2)
- [Abstract] Abstract: The four node classification benchmarks are not named; list the datasets explicitly.
- [Notation] Notation: Define symbols for prototypes, merged weights, and ridge-regression targets at first use and maintain consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help strengthen the presentation of our work on Analytic Drift Resister. We address each major comment point by point below. Revisions will be incorporated in the next version of the manuscript to clarify claims, add missing derivations, and improve experimental reporting.
read point-by-point responses
-
Referee: [§3.2] §3.2 (HAM description): The claim that layer-wise ridge regression merging produces 'absolute resistance to feature drift' is not supported. Ridge regression minimizes ||W_new X - W_old X||^2 + λ||W_new||^2 and leaves non-zero residual error in general; this residual propagates through non-linear activations and graph aggregations in GNNs, so the features supplied to ACR are not guaranteed identical to pre-update features.
Authors: We agree with the referee that ridge regression yields a non-zero residual in general and that this residual can propagate through non-linear activations and graph convolutions. The term 'absolute resistance' in the original manuscript was intended to emphasize the analytic, closed-form nature of the layer-wise merge (as opposed to heuristic regularization), but it overstates the guarantee. In the revision we will replace 'absolute resistance' with 'analytic resistance to linear feature drift' and add a new subsection deriving an upper bound on the residual norm after merging, together with a brief discussion of its propagation through the GNN pipeline. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis (around ACR): No equations, proof sketches, or bounds are supplied to show how ACR achieves zero forgetting once HAM is applied. The abstract asserts 'theoretically zero-forgetting' and 'theoretically grounded' guarantees, yet the central derivation linking merged parameters to identical classifier inputs is missing.
Authors: We acknowledge that the manuscript lacks an explicit derivation connecting the output of HAM to the zero-forgetting property of ACR. In the revised version we will insert a dedicated theoretical subsection that (i) states the precise assumption under which the merged linear transformations leave the pre-update node embeddings unchanged, (ii) provides the algebraic steps showing that the inputs to the analytic classifier remain identical, and (iii) sketches the proof that the reconstructed classifier therefore incurs zero forgetting on prior tasks. This will directly support the claims made in the abstract. revision: yes
-
Referee: [Experiments] Experiments section: Results are described only qualitatively as 'strong competitiveness' with no quantitative tables, per-task accuracies, forgetting metrics, or error bars visible. This prevents verification that the method actually delivers the claimed zero-forgetting behavior on the four benchmarks.
Authors: The full manuscript contains tables reporting average accuracy, per-task accuracy, and a forgetting metric across the four benchmarks, together with standard deviations over five random seeds. To address the referee's concern that these results are not sufficiently visible or highlighted, we will (i) move the main quantitative tables to the body of the paper (rather than the appendix), (ii) add an explicit column or row for the forgetting measure used to quantify zero-forgetting behavior, and (iii) include error bars in the figures. These changes will make the empirical support for the theoretical claims immediately verifiable. revision: partial
Circularity Check
Ridge regression merge claimed to deliver absolute drift resistance, but the resistance is the fitted objective by construction
specific steps
-
fitted input called prediction
[Abstract (HAM proposal)]
"we further propose Hierarchical Analytic Merging (HAM), performing layer-wise merging of linear transformations in Graph Neural Networks (GNNs) via ridge regression, thereby ensuring absolute resistance to feature drift. On this basis, Analytic Classifier Reconstruction (ACR) enables theoretically zero-forgetting class-incremental learning."
Ridge regression explicitly minimizes a loss of the form ||W_new X - W_old X||^2 + λ||W_new||^2. The paper treats the output of this minimization as 'absolute resistance' (i.e., zero residual drift) and then uses that property to underwrite the ACR zero-forgetting claim. The resistance is therefore the fitted quantity itself, not an independent consequence; any non-zero residual (inevitable once non-linearities and graph aggregations are present) falsifies the premise that ACR sees identical features.
full rationale
The paper's central derivation chain runs: parameter updates cause drift → HAM performs layer-wise ridge regression on linear maps → this 'ensures absolute resistance' → ACR therefore yields theoretically zero-forgetting. The resistance claim is not derived from an independent theorem or external benchmark; it is the direct minimization objective of the ridge regression itself. Because GNNs contain non-linear activations and graph aggregations, any per-layer residual error propagates, yet the paper presents the merged features as identical to pre-update features. This makes the zero-forgetting guarantee reduce to the fitting step rather than an independent prediction. No self-citation chain or renaming is required for the reduction; the circularity is internal to the HAM-ACR linkage.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Semi-Supervised Classification with Graph Convolutional Networks
T. Kipf, “Semi-supervised classification with graph convolutional net- works,”arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Inductive representation learning on large graphs,
W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[3]
Lightgcn: Simplifying and powering graph convolution network for recommenda- tion,
X. He, K. Deng, X. Wang, Y . Li, Y . Zhang, and M. Wang, “Lightgcn: Simplifying and powering graph convolution network for recommenda- tion,” inProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, 2020, pp. 639– 648
work page 2020
-
[4]
Decoupled behavior-based contrastive recommendation,
M. Yang, J. Zhou, M. Xi, X. Pan, Y . Yuan, Y . Li, Y . Wu, J. Zhang, and J. Yin, “Decoupled behavior-based contrastive recommendation,” in Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, 2024, pp. 2858–2868
work page 2024
-
[5]
A deep connectome learning network using graph convolution for connectome-disease association study,
Y . Yang, C. Ye, and T. Ma, “A deep connectome learning network using graph convolution for connectome-disease association study,”Neural Networks, vol. 164, pp. 91–104, 2023
work page 2023
-
[6]
Y . Li, X. Zhang, S. Guan, G. Ma, and Y . Kong, “Topology-guided graph masked autoencoder learning for population-based neurodevelopmental disorder diagnosis,”IEEE Transactions on Neural Systems and Rehabil- itation Engineering, 2025
work page 2025
-
[7]
Overcoming catastrophic forgetting in graph neural networks with experience replay,
F. Zhou and C. Cao, “Overcoming catastrophic forgetting in graph neural networks with experience replay,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 5, 2021, pp. 4714–4722
work page 2021
-
[8]
Sparsified subgraph memory for continual graph representation learning,
X. Zhang, D. Song, and D. Tao, “Sparsified subgraph memory for continual graph representation learning,” in2022 IEEE International Conference on Data Mining (ICDM). IEEE, 2022, pp. 1335–1340
work page 2022
-
[9]
E. Arani, F. Sarfraz, and B. Zonooz, “Learning fast, learning slow: A general continual learning method based on complementary learning system,”arXiv preprint arXiv:2201.12604, 2022
-
[10]
Incremental graph classification by class prototype construction and augmentation,
Y . Ren, L. Ke, D. Li, H. Xue, Z. Li, and S. Zhou, “Incremental graph classification by class prototype construction and augmentation,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 2136–2145. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10
work page 2023
-
[11]
Non-exemplar class- incremental learning via adaptive old class reconstruction,
S. Wang, W. Shi, Y . He, Y . Yu, and Y . Gong, “Non-exemplar class- incremental learning via adaptive old class reconstruction,” inProceed- ings of the 31st ACM International Conference on Multimedia, 2023, pp. 4524–4534
work page 2023
-
[12]
Elastic feature consolidation for cold start exemplar-free incremental learning,
S. Magistri, T. Trinci, A. Soutif-Cormerais, J. van de Weijer, and A. D. Bagdanov, “Elastic feature consolidation for cold start exemplar-free incremental learning,”arXiv preprint arXiv:2402.03917, 2024
-
[13]
Acil: Analytic class-incremental learning with absolute memorization and privacy protection,
H. Zhuang, Z. Weng, H. Wei, R. Xie, K.-A. Toh, and Z. Lin, “Acil: Analytic class-incremental learning with absolute memorization and privacy protection,”Advances in Neural Information Processing Systems, vol. 35, pp. 11 602–11 614, 2022
work page 2022
-
[14]
Gkeal: Gaussian kernel embedded analytic learning for few-shot class incremental task,
H. Zhuang, Z. Weng, R. He, Z. Lin, and Z. Zeng, “Gkeal: Gaussian kernel embedded analytic learning for few-shot class incremental task,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 7746–7755
work page 2023
-
[15]
Gacl: Exemplar-free generalized analytic continual learn- ing,
H. Zhuang, Y . Chen, D. Fang, R. He, K. Tong, H. Wei, Z. Zeng, and C. Chen, “Gacl: Exemplar-free generalized analytic continual learn- ing,”Advances in Neural Information Processing Systems, vol. 37, pp. 83 024–83 047, 2024
work page 2024
-
[16]
Ds-al: A dual-stream analytic learning for exemplar-free class-incremental learn- ing,
H. Zhuang, R. He, K. Tong, Z. Zeng, C. Chen, and Z. Lin, “Ds-al: A dual-stream analytic learning for exemplar-free class-incremental learn- ing,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 15, 2024, pp. 17 237–17 244
work page 2024
-
[17]
R. He, D. Fang, Y . Xu, Y . Cui, M. Li, C. Chen, Z. Zeng, and H. Zhuang, “Semantic shift estimation via dual-projection and classifier recon- struction for exemplar-free class-incremental learning,”arXiv preprint arXiv:2503.05423, 2025
-
[18]
Merging models with fisher-weighted averaging,
M. S. Matena and C. A. Raffel, “Merging models with fisher-weighted averaging,”Advances in Neural Information Processing Systems, vol. 35, pp. 17 703–17 716, 2022
work page 2022
-
[19]
Ties- merging: Resolving interference when merging models,
P. Yadav, D. Tam, L. Choshen, C. A. Raffel, and M. Bansal, “Ties- merging: Resolving interference when merging models,”Advances in Neural Information Processing Systems, vol. 36, pp. 7093–7115, 2023
work page 2023
-
[20]
Magmax: Leveraging model merging for seamless continual learning,
D. Marczak, B. Twardowski, T. Trzci ´nski, and S. Cygert, “Magmax: Leveraging model merging for seamless continual learning,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 379–395
work page 2024
-
[21]
Ridge regression: Biased estimation for nonorthogonal problems,
A. E. Hoerl and R. W. Kennard, “Ridge regression: Biased estimation for nonorthogonal problems,”Technometrics, vol. 12, no. 1, pp. 55–67, 1970
work page 1970
-
[22]
Cat: Balanced continual graph learning with graph condensation,
Y . Liu, R. Qiu, and Z. Huang, “Cat: Balanced continual graph learning with graph condensation,” in2023 IEEE International Conference on Data Mining (ICDM). IEEE, 2023, pp. 1157–1162
work page 2023
-
[23]
Graph continual learning with debiased lossless memory replay,
C. Niu, G. Pang, and L. Chen, “Graph continual learning with debiased lossless memory replay,”arXiv preprint arXiv:2404.10984, 2024
-
[24]
Graph con- densation for graph neural networks,
W. Jin, L. Zhao, S. Zhang, Y . Liu, J. Tang, and N. Shah, “Graph con- densation for graph neural networks,”arXiv preprint arXiv:2110.07580, 2021
-
[25]
Graph condensation via receptive field distribution matching,
M. Liu, S. Li, X. Chen, and L. Song, “Graph condensation via receptive field distribution matching,”arXiv preprint arXiv:2206.13697, 2022
-
[26]
Prototype aug- mentation and self-supervision for incremental learning,
F. Zhu, X.-Y . Zhang, C. Wang, F. Yin, and C.-L. Liu, “Prototype aug- mentation and self-supervision for incremental learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 5871–5880
work page 2021
-
[27]
Fcs: Feature calibration and separation for non-exemplar class incremental learning,
Q. Li, Y . Peng, and J. Zhou, “Fcs: Feature calibration and separation for non-exemplar class incremental learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 28 495–28 504
work page 2024
-
[28]
Exemplar-free continual representation learning via learnable drift compensation,
A. Gomez-Villa, D. Goswami, K. Wang, A. D. Bagdanov, B. Twar- dowski, and J. van de Weijer, “Exemplar-free continual representation learning via learnable drift compensation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 473–490
work page 2024
-
[29]
Efficient statistical sampling adaptation for exemplar-free class incremental learn- ing,
D. Cheng, Y . Zhao, N. Wang, G. Li, D. Zhang, and X. Gao, “Efficient statistical sampling adaptation for exemplar-free class incremental learn- ing,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 11, pp. 11 451–11 463, 2024
work page 2024
-
[30]
P. Guo and M. R. Lyu, “A pseudoinverse learning algorithm for feedforward neural networks with stacked generalization applications to software reliability growth data,”Neurocomputing, vol. 56, pp. 101–121, 2004
work page 2004
-
[31]
Blockwise recursive moore–penrose inverse for network learning,
H. Zhuang, Z. Lin, and K.-A. Toh, “Blockwise recursive moore–penrose inverse for network learning,”IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 52, no. 5, pp. 3237–3250, 2021
work page 2021
-
[32]
Real: Representation enhanced analytic learning for exemplar-free class-incremental learning,
R. He, D. Fang, Y . Chen, K. Tong, C. Chen, Y . Wang, L.-p. Chau, and H. Zhuang, “Real: Representation enhanced analytic learning for exemplar-free class-incremental learning,”Knowledge-Based Systems, p. 114901, 2025
work page 2025
-
[33]
Mmal: Multi-modal analytic learning for exemplar-free audio-visual class incremental tasks,
X. Yue, X. Zhang, Y . Chen, C. Zhang, M. Lao, H. Zhuang, X. Qian, and H. Li, “Mmal: Multi-modal analytic learning for exemplar-free audio-visual class incremental tasks,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 2428–2437
work page 2024
-
[34]
arXiv preprint arXiv:2212.09849 , year=
X. Jin, X. Ren, D. Preotiuc-Pietro, and P. Cheng, “Dataless knowl- edge fusion by merging weights of language models,”arXiv preprint arXiv:2212.09849, 2022
-
[35]
Fusing finetuned models for better pretraining,
L. Choshen, E. Venezian, N. Slonim, and Y . Katz, “Fusing finetuned models for better pretraining,”arXiv preprint arXiv:2204.03044, 2022
-
[36]
M. Wortsman, G. Ilharco, S. Y . Gadre, R. Roelofs, R. Gontijo-Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y . Carmon, S. Kornblith et al., “Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,” inInternational conference on machine learning. PMLR, 2022, pp. 23 965–23 998
work page 2022
-
[37]
Editing Models with Task Arithmetic
G. Ilharco, M. T. Ribeiro, M. Wortsman, S. Gururangan, L. Schmidt, H. Hajishirzi, and A. Farhadi, “Editing models with task arithmetic,” arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Z. Li and D. Hoiem, “Learning without forgetting,”IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 2935– 2947, 2017
work page 2017
-
[39]
Maintaining dis- crimination and fairness in class incremental learning,
B. Zhao, X. Xiao, G. Gan, B. Zhang, and S.-T. Xia, “Maintaining dis- crimination and fairness in class incremental learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 13 208–13 217
work page 2020
-
[40]
Exploring rationale learning for continual graph learning,
L. Song, J. Li, Q. Si, S. Guan, and Y . Kong, “Exploring rationale learning for continual graph learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 19, 2025, pp. 20 540–20 548
work page 2025
-
[41]
T. M. Cover, “Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition,”IEEE transactions on electronic computers, no. 3, pp. 326–334, 2006
work page 2006
-
[42]
Pitfalls of Graph Neural Network Evaluation
O. Shchur, M. Mumme, A. Bojchevski, and S. G ¨unnemann, “Pitfalls of graph neural network evaluation,”arXiv preprint arXiv:1811.05868, 2018
work page Pith review arXiv 2018
-
[43]
Automating the construction of internet portals with machine learning,
A. K. McCallum, K. Nigam, J. Rennie, and K. Seymore, “Automating the construction of internet portals with machine learning,”Information Retrieval, vol. 3, no. 2, pp. 127–163, 2000
work page 2000
-
[44]
Open graph benchmark: Datasets for machine learning on graphs,
W. Hu, M. Fey, M. Zitnik, Y . Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec, “Open graph benchmark: Datasets for machine learning on graphs,”Advances in neural information processing systems, vol. 33, pp. 22 118–22 133, 2020
work page 2020
-
[45]
Cglb: Benchmark tasks for continual graph learning,
X. Zhang, D. Song, and D. Tao, “Cglb: Benchmark tasks for continual graph learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 13 006–13 021, 2022
work page 2022
-
[46]
Can llms alleviate catastrophic forgetting in graph continual learning? a systematic study,
Z. Cheng, Z. Li, Y . Li, Y . Song, K. Zhao, D. Cheng, J. Li, H. Cheng, and J. X. Yu, “Can llms alleviate catastrophic forgetting in graph continual learning? a systematic study,”arXiv preprint arXiv:2505.18697, 2025
-
[47]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,”Pro- ceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017
work page 2017
-
[48]
Memory aware synapses: Learning what (not) to forget,
R. Aljundi, F. Babiloni, M. Elhoseiny, M. Rohrbach, and T. Tuytelaars, “Memory aware synapses: Learning what (not) to forget,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 139– 154
work page 2018
-
[49]
Overcoming catastrophic forgetting in graph neural networks,
H. Liu, Y . Yang, and X. Wang, “Overcoming catastrophic forgetting in graph neural networks,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 10, 2021, pp. 8653–8661
work page 2021
-
[50]
Learning to learn without forgetting by maximizing transfer and minimizing interference,
M. Riemer, I. Cases, R. Ajemian, M. Liu, I. Rish, Y . Tu, and G. Tesauro, “Learning to learn without forgetting by maximizing transfer and minimizing interference,”arXiv preprint arXiv:1810.11910, 2018
-
[51]
Model merging and safety alignment: One bad model spoils the bunch,
H. A. A. K. Hammoud, U. Michieli, F. Pizzati, P. Torr, A. Bibi, B. Ghanem, and M. Ozay, “Model merging and safety alignment: One bad model spoils the bunch,”arXiv preprint arXiv:2406.14563, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.