Recognition: no theorem link
Semantic Data Processing with Holistic Data Understanding
Pith reviewed 2026-05-13 19:04 UTC · model grok-4.3
The pith
HoldUp improves semantic task accuracy by jointly processing dataset records to give LLMs necessary context for interpreting imprecise instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HoldUp resolves the LLM data understanding paradox by developing a bagging-inspired clustering algorithm that identifies latent dataset structure with judicious, limited LLM calls; this clustering primitive then powers new clustering-based classification and scoring methods that process records jointly and thereby interpret user tasks correctly within the full data context.
What carries the argument
Novel clustering algorithm that extracts latent structure from the dataset using limited LLM calls and serves as the primitive for joint, context-aware classification and scoring.
If this is right
- Classification accuracy rises by up to 33 percent over row-by-row baselines.
- Scoring and clustering accuracy rises by up to 30 percent.
- Joint record processing supplies the dataset-specific context that natural-language instructions require.
- The clustering primitive keeps total LLM calls small enough to avoid known long-context quality loss.
Where Pith is reading between the lines
- Similar clustering-based context gathering could be applied to other semantic operators such as filtering or entity resolution.
- Data systems that adopt the approach may be able to relax strict per-record independence assumptions in query planning.
- Further scaling the clustering step could support datasets too large for any single LLM call window.
- Testing the method on streaming or frequently updated data would reveal whether re-clustering cost remains acceptable.
Load-bearing premise
The clustering algorithm can reliably recover the latent structure needed to disambiguate the user's task for every record without long-context degradation.
What would settle it
On a dataset whose records have highly ambiguous labels or scores, the clustering step groups examples incorrectly and HoldUp shows no accuracy gain or lower accuracy than independent per-record processing.
Figures








read the original abstract
Semantic operators have increasingly become integrated within data systems to enable processing data using Large Language Models (LLMs). Despite significant recent effort in improving these operators, their accuracy is limited due to a critical flaw in their implementation: lack of holistic data understanding. In existing systems, semantic operators often process each data record independently using an LLM, without considering data context, only leveraging LLM's dataset-agnostic interpretation of the user-provided task. However, natural language is imprecise, so a task can only be accurately performed if it is correctly interpreted in the context of the dataset. For example, for classification and scoring tasks, which are typical semantic map tasks, the standard method of processing each record row by row yields inaccurate results in a wide range of datasets. We propose HoldUp, a new method for semantic data processing with holistic data understanding. HoldUp processes records jointly, leveraging cross-record relationships to correctly interpret the task within the data context. Enabling holistic data understanding, however, is challenging due to what we call LLM data understanding paradox: while large representative data subsets are necessary to provide context, feeding long inputs to LLMs causes quality degradation due to well-known long-context issues. To resolve this paradox, we develop a novel clustering algorithm to identify the latent structure within the dataset through judicious use of LLMs, inspired by bagging. Using this approach as a primitive, we develop novel clustering-based classification and scoring methods to perform these two tasks with high accuracy. Experiments across 15 real-world datasets show that HoldUp consistently outperforms existing solutions, providing up to 33% higher accuracy for classification and 30% higher accuracy for scoring and clustering tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HoldUp, a method for semantic data processing with holistic data understanding. It argues that existing LLM-based semantic operators process records independently and thus fail to correctly interpret imprecise natural-language tasks in dataset context. HoldUp resolves the resulting 'LLM data understanding paradox' by introducing a bagging-inspired clustering algorithm that identifies latent structure via judicious (short-context) LLM calls, then uses the resulting clusters to develop improved classification and scoring primitives. Experiments on 15 real-world datasets are reported to show consistent outperformance, with gains of up to 33% in classification accuracy and 30% in scoring/clustering accuracy.
Significance. If the central algorithmic claim holds, the work would be significant for database systems that integrate semantic operators: it offers a concrete mechanism to obtain data-context-aware LLM judgments without incurring long-context degradation, which could improve reliability of semantic map operations across classification, scoring, and related tasks.
major comments (3)
- [Abstract and §3] Abstract and §3 (clustering primitive): the description of the novel bagging-inspired clustering algorithm supplies no distance/similarity function, no prompt template for the LLM judgments, no bound on subset size or number of calls, and no argument establishing that the chosen subsets remain representative enough to avoid long-context degradation. Because this mechanism is the load-bearing step that is supposed to deliver holistic understanding, its absence prevents assessment of whether the reported accuracy gains can be attributed to the proposed primitive.
- [Experimental evaluation] Experimental evaluation (results on 15 datasets): the abstract states empirical gains but supplies no error bars, no description of the clustering algorithm actually used in the experiments, no baseline implementation details, and no statistical tests. Without these, it is impossible to determine whether the 33% and 30% improvements are robust or artifactual.
- [§4] §4 (classification and scoring methods): the claim that the clustering step 'correctly disambiguates the user's task for every record' is asserted without any supporting analysis or bound showing that the latent-structure extraction succeeds on the full dataset; this assumption is central to the accuracy claims yet remains unverified in the provided description.
minor comments (1)
- [Abstract] The acronym 'HoldUp' is introduced in the abstract without expansion or motivation for the name.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript describing HoldUp. The comments highlight important areas for improving clarity, reproducibility, and rigor, particularly around the clustering primitive and experimental reporting. We address each point below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (clustering primitive): the description of the novel bagging-inspired clustering algorithm supplies no distance/similarity function, no prompt template for the LLM judgments, no bound on subset size or number of calls, and no argument establishing that the chosen subsets remain representative enough to avoid long-context degradation. Because this mechanism is the load-bearing step that is supposed to deliver holistic understanding, its absence prevents assessment of whether the reported accuracy gains can be attributed to the proposed primitive.
Authors: We agree that the current description of the bagging-inspired clustering algorithm in §3 lacks sufficient detail for full assessment and reproducibility. In the revised manuscript, we will add: (1) the similarity function (semantic similarity via short LLM prompts on record pairs or embeddings), (2) the exact prompt templates used for LLM judgments during clustering, (3) explicit bounds (subsets capped at 15 records to avoid long-context degradation, with a fixed number of bagging iterations leading to O(n) total calls), and (4) an argument based on bootstrap sampling properties showing that the subsets preserve dataset representativeness for latent structure discovery. These additions will directly tie the mechanism to the observed accuracy gains. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation (results on 15 datasets): the abstract states empirical gains but supplies no error bars, no description of the clustering algorithm actually used in the experiments, no baseline implementation details, and no statistical tests. Without these, it is impossible to determine whether the 33% and 30% improvements are robust or artifactual.
Authors: We acknowledge the need for more complete experimental reporting. The revised version will include: error bars (standard deviation across 5 runs with different random seeds), a full description of the clustering algorithm parameters actually used in the experiments (e.g., subset size, number of clusters, bagging rounds), precise baseline details (row-by-row LLM processing using the same model and prompt templates), and statistical tests (paired t-tests and McNemar's test) to establish significance of the improvements. This will confirm that the gains of up to 33% classification and 30% scoring accuracy are robust across the 15 datasets. revision: yes
-
Referee: [§4] §4 (classification and scoring methods): the claim that the clustering step 'correctly disambiguates the user's task for every record' is asserted without any supporting analysis or bound showing that the latent-structure extraction succeeds on the full dataset; this assumption is central to the accuracy claims yet remains unverified in the provided description.
Authors: We agree the phrasing in §4 is too strong and lacks supporting evidence. We will revise the claim to state that the clustering provides holistic context that improves task disambiguation in aggregate rather than guaranteeing correctness for every record. The revision will add empirical analysis (e.g., cluster purity metrics and manual verification of disambiguation success on sampled records from the 15 datasets) and a discussion of the conditions under which latent structure extraction succeeds. A formal bound is difficult given the data-dependent nature of the problem, but the added analysis will substantiate the central assumption. revision: partial
Circularity Check
No circularity: empirical claims rest on experiments, not self-referential definitions or fitted inputs.
full rationale
The paper introduces HoldUp via a novel bagging-inspired clustering primitive to resolve the LLM data understanding paradox, then applies it to classification and scoring. No equations, derivations, or parameter fits are described that reduce the reported accuracy gains (33% classification, 30% scoring) to the method's own inputs by construction. The central claims are supported by experiments on 15 real-world datasets rather than tautological reductions, self-citations, or renamed known results. This is a standard non-circular systems contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can correctly interpret user tasks when supplied with representative data context extracted via clustering
Reference graph
Works this paper leans on
- [1]
-
[2]
Rami Aly, Steffen Remus, and Chris Biemann. 2019. Hierarchical multi-label classification of text with capsule networks. InProceedings of the 57th annual meeting of the association for computational linguistics: student research workshop. 323–330
work page 2019
- [3]
-
[4]
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, et al. 2025. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 3639–3664
work page 2025
-
[5]
Nikhil Bansal, Avrim Blum, and Shuchi Chawla. 2004. Correlation clustering. Machine learning56, 1 (2004), 89–113
work page 2004
-
[6]
Lawrence W Barsalou. 1987. The Instability of Graded Structure: Implications for the.Concepts and conceptual development: Ecological and intellectual factors in categorization1 (1987), 101
work page 1987
-
[7]
Leo Breiman. 1996. Bagging predictors.Machine learning24, 2 (1996), 123–140
work page 1996
-
[8]
Vincent Conitzer, Andrew Davenport, and Jayant Kalagnanam. 2006. Improved bounds for computing Kemeny rankings. InAAAI, Vol. 6. 620–626
work page 2006
-
[9]
Susan B Davidson, Sanjeev Khanna, Tova Milo, and Sudeepa Roy. 2013. Using the crowd for top-k and group-by queries. InProceedings of the 16th international conference on database theory. 225–236
work page 2013
-
[10]
arXiv preprint arXiv:2005.00547 (2020)
Dorottya Demszky, Dana Movshovitz-Attias, Jeongwoo Ko, Alan S. Cowen, Gaurav Nemade, and Sujith Ravi. 2020. GoEmotions: A Dataset of Fine-Grained Emotions.CoRRabs/2005.00547 (2020). arXiv:2005.00547 https://arxiv.org/abs/ 2005.00547
-
[11]
Jairo Diaz-Rodriguez. 2026. Summaries as Centroids for Interpretable and Scal- able Text Clustering. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=Uzku7RZXvI
work page 2026
-
[12]
Eyal Dushkin and Tova Milo. 2018. Top-k sorting under partial order information. InProceedings of the 2018 International Conference on Management of Data. 1007– 1019
work page 2018
-
[13]
Till Döhmen. 2024. Introducing the prompt() Function: Use the Power of LLMs with SQL! https://motherduck.com/blog/sql-llm-prompt-function-gpt-models/. Accessed: 2025-06-22
work page 2024
-
[14]
Aristides Gionis, Heikki Mannila, and Panayiotis Tsaparas. 2007. Clustering aggregation.ACM Trans. Knowl. Discov. Data1, 1 (March 2007), 4–es. https: //doi.org/10.1145/1217299.1217303
-
[15]
Ryan Gomes, Peter Welinder, Andreas Krause, and Pietro Perona. 2011. Crowd- clustering.Advances in neural information processing systems24 (2011)
work page 2011
-
[16]
Google. 2025. Perform intelligent SQL queries using AlloyDB AI query en- gine. http://cloud.google.com/alloydb/docs/ai/evaluate-semantic-queries-ai- operators
work page 2025
-
[17]
Stephen Guo, Aditya Parameswaran, and Hector Garcia-Molina. 2012. So who won? Dynamic max discovery with the crowd. InProceedings of the 2012 ACM SIGMOD international conference on management of data. 385–396
work page 2012
-
[18]
Xifeng Guo, Long Gao, Xinwang Liu, and Jianping Yin. 2017. Improved deep embedded clustering with local structure preservation.. InIjcai, Vol. 17. 1753– 1759
work page 2017
-
[19]
Amir Hadifar, Lucas Sterckx, Thomas Demeester, and Chris Develder. 2019. A self-training approach for short text clustering. InProceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019). 194–199
work page 2019
-
[20]
Ben Hamner, Jaison Morgan, lynnvandev, Mark Shermis, and Tom Vander Ark
-
[21]
https://kaggle.com/ competitions/asap-aes
The Hewlett Foundation: Automated Essay Scoring. https://kaggle.com/ competitions/asap-aes. Kaggle Competition
-
[22]
James A Hampton, Danièle Dubois, and Wenchi Yeh. 2006. Effects of classification context on categorization in natural categories.Memory & Cognition34, 7 (2006), 1431–1443
work page 2006
-
[23]
Wassily Hoeffding. 1994. Probability inequalities for sums of bounded random variables.The collected works of Wassily Hoeffding(1994), 409–426
work page 1994
-
[24]
Chen Huang and Guoxiu He. 2025. Text clustering as classification with llms. In Proceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region. 374–384
work page 2025
- [25]
-
[26]
Hwiyeol Jo, Hyunwoo Lee, Kang Min Yoo, and Taiwoo Park. 2025. ZeroDL: Zero-shot Distribution Learning for Text Clustering via Large Language Models. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Au...
-
[27]
Saehan Jo and Immanuel Trummer. 2024. Thalamusdb: Approximate query processing on multi-modal data.Proceedings of the ACM on Management of Data 2, 3 (2024), 1–26
work page 2024
-
[28]
Saehan Jo and Immanuel Trummer. 2025. SpareLLM: Automatically Selecting Task-Specific Minimum-Cost Large Language Models under Equivalence Con- straint.Proceedings of the ACM on Management of Data3, 3 (2025), 1–26
work page 2025
-
[29]
David R Karger, Sewoong Oh, and Devavrat Shah. 2014. Budget-optimal task allocation for reliable crowdsourcing systems.Operations Research62, 1 (2014), 1–24
work page 2014
-
[30]
John G Kemeny. 1959. Mathematics without numbers.Daedalus88, 4 (1959), 577–591
work page 1959
-
[31]
Yoon Kim. 2014. Convolutional neural networks for sentence classification. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 1746–1751
work page 2014
-
[32]
Kamran Kowsari, Kiana Jafari Meimandi, Mojtaba Heidarysafa, Sanjana Mendu, Laura Barnes, and Donald Brown. 2019. Text classification algorithms: A survey. Information10, 4 (2019), 150
work page 2019
-
[33]
Harold W Kuhn. 1955. The Hungarian method for the assignment problem. Naval research logistics quarterly2, 1-2 (1955), 83–97
work page 1955
-
[34]
Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K
Stefan Larson, Anish Mahendran, Joseph J. Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K. Kummerfeld, Kevin Leach, Michael A. Lauren- zano, Lingjia Tang, and Jason Mars. 2019. An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction. InProceedings of the 2019 Con- ference on Empirical Methods in Natural Language Processi...
work page 2019
- [35]
- [36]
-
[37]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baille Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, and Gerardo Vitagliano
- [38]
-
[39]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173
work page 2024
- [40]
-
[41]
Adam Marcus, Eugene Wu, David Karger, Samuel Madden, and Robert Miller
- [42]
-
[43]
Michael C Mozer, Harold Pashler, Matthew Wilder, Robert V Lindsey, Matt C Jones, and Michael N Jones. 2010. Decontaminating human judgments by re- moving sequential dependencies.In Advances in Neural Information Processing Systems23 (2010)
work page 2010
-
[44]
Michael C Mozer, Michael Shettel, and Michael Holmes. 2006. Context effects in category learning: An investigation of four probabilistic models.Advances in Neural Information Processing Systems19 (2006)
work page 2006
- [45]
- [46]
- [47]
-
[48]
Anup Pattnaik, Cijo George, Rishabh Kumar Tripathi, Sasanka Vutla, and Jithen- dra Vepa. 2024. Improving Hierarchical Text Clustering with LLM-guided Multi- view Cluster Representation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, Franck Dernoncourt, Daniel Preoţiuc-Pietro, and Anastasia Shimori...
-
[49]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 3982–3992
work page 2019
- [50]
-
[51]
Falk Scholer, Diane Kelly, Wan-Ching Wu, Hanseul S Lee, and William Webber
-
[52]
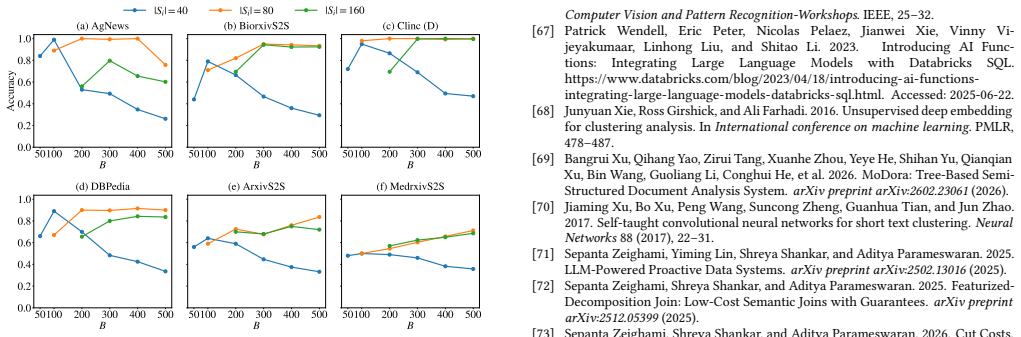
The effect of threshold priming and need for cognition on relevance13 50100 200 300 400 500 B 0.0 0.2 0.4 0.6 0.8 1.0Accuracy (a) AgNews 50100 200 300 400 500 B (b) BiorxivS2S 50100 200 300 400 500 B (c) Clinc (D) 50100 200 300 400 500 B 0.0 0.2 0.4 0.6 0.8 1.0 (d) DBPedia 50100 200 300 400 500 B (e) ArxivS2S 50100 200 300 400 500 B (f) MedrxivS2S |Si| = ...
-
[53]
Norbert Schwarz. 1999. Self-reports: How the questions shape the answers. American psychologist54, 2 (1999), 93
work page 1999
-
[54]
2012.Context effects in social and psychological research
Norbert Schwarz and Seymour Sudman. 2012.Context effects in social and psychological research. Springer Science & Business Media
work page 2012
- [55]
- [56]
-
[57]
Victor S Sheng, Foster Provost, and Panagiotis G Ipeirotis. 2008. Get another label? improving data quality and data mining using multiple, noisy labelers. InProceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 614–622
work page 2008
-
[58]
Snoflake. 2025. Introducing Cortex AISQL: Reimagining SQL into AI Query Language for Multimodal Data. https://www.snowflake.com/en/blog/ai-sql- query-language/
work page 2025
-
[59]
Xiaofei Sun, Xiaoya Li, Jiwei Li, Fei Wu, Shangwei Guo, Tianwei Zhang, and Guoyin Wang. 2023. Text Classification via Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 8990–9005. https://doi.org/10.18653/v1/...
-
[60]
Youran Sun, Sepanta Zeighami, Bhavya Chopra, Shreya Shankar, and Aditya Parameswaran. 2026. Semantic Data Processing with Holistic Data Understand- ing (Code). https://github.com/YouranSun/HOLDUP
work page 2026
-
[61]
suraj520. 2023. Customer Support Ticket Dataset. https://www.kaggle.com/ datasets/suraj520/customer-support-ticket-dataset. Kaggle Dataset
work page 2023
-
[62]
2009.Nudge: Improving decisions about health, wealth, and happiness
Richard H Thaler and Cass R Sunstein. 2009.Nudge: Improving decisions about health, wealth, and happiness. Penguin
work page 2009
-
[63]
Roger Tourangeau, Lance J Rips, and Kenneth Rasinski. 2000. The psychology of survey response. (2000)
work page 2000
-
[64]
Matthias Urban and Carsten Binnig. 2024. Demonstrating CAESURA: Language Models as Multi-Modal Query Planners. InCompanion of the 2024 International Conference on Management of Data. 472–475
work page 2024
-
[65]
Matthias Urban and Carsten Binnig. 2024. ELEET: Efficient Learned Query Execution over Text and Tables.Proc. VLDB Endow17 (2024), 13
work page 2024
-
[67]
Vijay Viswanathan, Kiril Gashteovski, Carolin Lawrence, Tongshuang Wu, and Graham Neubig. 2024. Large Language Models Enable Few-Shot Clustering. Transactions of the Association for Computational Linguistics12 (2024), 321–333. https://doi.org/10.1162/tacl_a_00648
- [68]
- [69]
-
[70]
Peter Welinder and Pietro Perona. 2010. Online crowdsourcing: rating annotators and obtaining cost-effective labels. In2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops. IEEE, 25–32
work page 2010
-
[71]
Patrick Wendell, Eric Peter, Nicolas Pelaez, Jianwei Xie, Vinny Vi- jeyakumaar, Linhong Liu, and Shitao Li. 2023. Introducing AI Func- tions: Integrating Large Language Models with Databricks SQL. https://www.databricks.com/blog/2023/04/18/introducing-ai-functions- integrating-large-language-models-databricks-sql.html. Accessed: 2025-06-22
work page 2023
-
[72]
Junyuan Xie, Ross Girshick, and Ali Farhadi. 2016. Unsupervised deep embedding for clustering analysis. InInternational conference on machine learning. PMLR, 478–487
work page 2016
-
[73]
Bangrui Xu, Qihang Yao, Zirui Tang, Xuanhe Zhou, Yeye He, Shihan Yu, Qianqian Xu, Bin Wang, Guoliang Li, Conghui He, et al. 2026. MoDora: Tree-Based Semi- Structured Document Analysis System.arXiv preprint arXiv:2602.23061(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[74]
Jiaming Xu, Bo Xu, Peng Wang, Suncong Zheng, Guanhua Tian, and Jun Zhao
-
[75]
Self-taught convolutional neural networks for short text clustering.Neural Networks88 (2017), 22–31
work page 2017
- [76]
- [77]
-
[78]
Sepanta Zeighami, Shreya Shankar, and Aditya Parameswaran. 2026. Cut Costs, Not Accuracy: LLM-Powered Data Processing with Guarantees.SIGMOD’26 (2026). To appear
work page 2026
- [79]
-
[80]
Dejiao Zhang, Feng Nan, Xiaokai Wei, Shang-Wen Li, Henghui Zhu, Kathleen McKeown, Ramesh Nallapati, Andrew O Arnold, and Bing Xiang. 2021. Support- ing clustering with contrastive learning. InProceedings of the 2021 conference of the North American chapter of the association for computational linguistics: Human language technologies. 5419–5430
work page 2021
-
[81]
Xiaohang Zhang, Guoliang Li, and Jianhua Feng. 2016. Crowdsourced Top-k Algorithms: An Experimental Evaluation.Proc. VLDB Endow.9, 8 (2016), 612–623
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.