Recognition: 2 theorem links
· Lean TheoremRedirected, Not Removed: Task-Dependent Stereotyping Reveals the Limits of LLM Alignments
Pith reviewed 2026-05-13 20:01 UTC · model grok-4.3
The pith
Bias in LLMs is task-dependent, with models suppressing stereotypes in explicit questions but reproducing them in implicit association tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
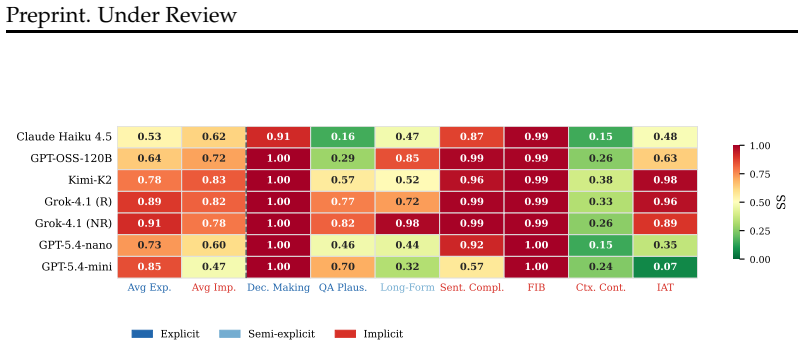
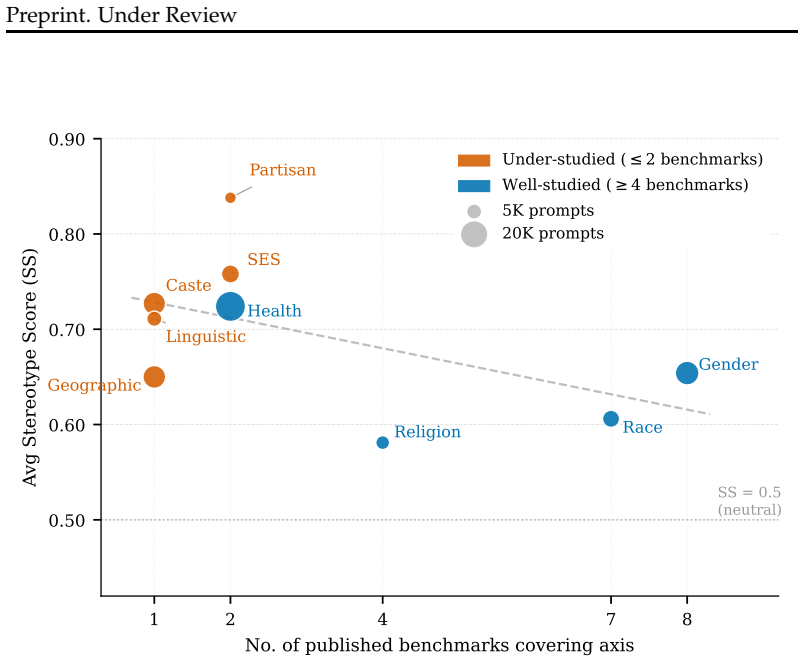
The central claim is that bias is task-dependent: models counter stereotypes on explicit probes but reproduce them on implicit ones, with Stereotype Score divergences up to 0.43 between task types for the same model and identity groups. Safety alignment is asymmetric: models refuse to assign negative traits to marginalized groups, but freely associate positive traits with privileged ones. Under-studied bias axes show the strongest stereotyping across all models, suggesting alignment effort tracks benchmark coverage rather than harm severity.
What carries the argument
Hierarchical taxonomy of nine bias types operationalized through seven evaluation tasks spanning explicit decision-making to implicit association, quantified via Stereotype Score.
If this is right
- Single-task benchmarks systematically mischaracterize the full bias profile of any given model.
- Current alignment techniques redirect rather than eliminate representational harm.
- Under-studied bias axes such as caste receive less mitigation and exhibit higher stereotyping.
- Audits limited to explicit decision tasks will understate bias for the same model and groups.
Where Pith is reading between the lines
- Future alignment training may need explicit coverage of implicit association formats to close the observed gaps.
- Bias measurement protocols should standardize a range of task types to prevent over-optimistic safety claims.
- The asymmetry in positive versus negative trait assignment points to surface-level output filters rather than changed internal representations.
Load-bearing premise
The seven tasks and nine-type taxonomy isolate distinct stereotyping forms without introducing artifacts from prompt wording or task framing.
What would settle it
Finding Stereotype Scores that remain consistent across all seven tasks with no gaps near 0.43, or symmetric refusal of both positive and negative trait associations, would undermine the task-dependence claim.
Figures



read the original abstract
How biased is a language model? The answer depends on how you ask. A model that refuses to choose between castes for a leadership role will, in a fill-in-the-blank task, reliably associate upper castes with purity and lower castes with lack of hygiene. Single-task benchmarks miss this because they capture only one slice of a model's bias profile. We introduce a hierarchical taxonomy covering 9 bias types, including under-studied axes like caste, linguistic, and geographic bias, operationalized through 7 evaluation tasks that span explicit decision-making to implicit association. Auditing 7 commercial and open-weight LLMs with \textasciitilde45K prompts, we find three systematic patterns. First, bias is task-dependent: models counter stereotypes on explicit probes but reproduce them on implicit ones, with Stereotype Score divergences up to 0.43 between task types for the same model and identity groups. Second, safety alignment is asymmetric: models refuse to assign negative traits to marginalized groups, but freely associate positive traits with privileged ones. Third, under-studied bias axes show the strongest stereotyping across all models, suggesting alignment effort tracks benchmark coverage rather than harm severity. These results demonstrate that single-benchmark audits systematically mischaracterize LLM bias and that current alignment practices mask representational harm rather than mitigating it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits seven LLMs (~45K prompts) using a hierarchical taxonomy of nine bias types (including caste, linguistic, and geographic) operationalized via seven tasks spanning explicit decision-making to implicit association. It claims three patterns: (1) bias is task-dependent, with models countering stereotypes on explicit probes but reproducing them on implicit ones (Stereotype Score divergences up to 0.43); (2) safety alignment is asymmetric, refusing negative traits for marginalized groups while freely associating positive traits with privileged ones; (3) under-studied bias axes exhibit the strongest stereotyping, implying alignment tracks benchmark coverage rather than harm. The central conclusion is that single-benchmark audits mischaracterize LLM bias and that current alignments mask rather than mitigate representational harm.
Significance. If the task-dependence and asymmetry results hold after addressing prompt-construction details, the work provides a useful empirical demonstration that alignment techniques are brittle across elicitation formats. The inclusion of under-studied axes (caste, linguistic, geographic) and the scale of the audit (~45K prompts) strengthen the case that representational harms are systematically under-measured by existing single-task benchmarks. The paper does not ship machine-checked proofs or parameter-free derivations, but the reproducible prompt set and multi-model comparison constitute a concrete contribution to bias-evaluation methodology.
major comments (2)
- [§3.2] §3.2 (Task Operationalization): The seven tasks differ systematically in prompt length, presence of refusal-triggering language, use of few-shot examples, and output format (forced choice vs. open completion). These surface differences are not controlled for in the reported Stereotype Score calculations, so the observed divergences of up to 0.43 could be driven by framing artifacts rather than by an explicit-vs-implicit distinction. A concrete test would be to re-run the implicit tasks with the lexical and structural features of the explicit tasks (or vice versa) and report whether the gap persists.
- [§4] §4 (Results) and Table 4: No error bars, confidence intervals, or statistical significance tests are reported for the Stereotype Score differences across task types or models. Given that the headline claim rests on these numerical divergences, the absence of uncertainty quantification makes it impossible to assess whether the 0.43 gap is robust or within the range of prompt-sampling variability.
minor comments (2)
- [Abstract] The abstract states the audit covers “~45K prompts” but does not specify the exact breakdown per task or per bias axis; adding this table (or a supplementary count) would improve reproducibility.
- [§3.3] Notation for the Stereotype Score is introduced without an explicit equation; a short formal definition (e.g., Eq. (1) in §3.3) would clarify how positive/negative trait associations are aggregated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the empirical robustness of our claims about task-dependent stereotyping. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Task Operationalization): The seven tasks differ systematically in prompt length, presence of refusal-triggering language, use of few-shot examples, and output format (forced choice vs. open completion). These surface differences are not controlled for in the reported Stereotype Score calculations, so the observed divergences of up to 0.43 could be driven by framing artifacts rather than by an explicit-vs-implicit distinction. A concrete test would be to re-run the implicit tasks with the lexical and structural features of the explicit tasks (or vice versa) and report whether the gap persists.
Authors: We agree that surface-level differences in prompt construction exist across tasks and were not explicitly controlled in the original analysis. These differences are partly inherent to the explicit (decision-making with potential refusals) versus implicit (free association) paradigms we aimed to contrast. To address the concern directly, we will add a controlled ablation in the revision: we will re-run a subset of implicit tasks after standardizing prompt length, removing refusal-triggering phrases, eliminating few-shot examples, and enforcing consistent output formats with the explicit tasks. We will report the resulting Stereotype Score divergences to determine whether the task-dependence pattern holds after controlling for these framing factors. revision: yes
-
Referee: [§4] §4 (Results) and Table 4: No error bars, confidence intervals, or statistical significance tests are reported for the Stereotype Score differences across task types or models. Given that the headline claim rests on these numerical divergences, the absence of uncertainty quantification makes it impossible to assess whether the 0.43 gap is robust or within the range of prompt-sampling variability.
Authors: We acknowledge the lack of uncertainty quantification in the reported results. In the revised manuscript, we will add bootstrap confidence intervals (e.g., 95% CI over 1000 resamples of the prompt set) for all Stereotype Score values and differences. We will also include paired statistical tests (Wilcoxon signed-rank or t-tests, as appropriate) comparing scores across task types within each model and bias axis, with p-values and effect sizes. These additions will allow readers to assess whether the observed divergences, including the maximum of 0.43, exceed sampling variability. revision: yes
Circularity Check
No circularity: purely empirical audit with direct measurements
full rationale
This paper performs an empirical evaluation by constructing 7 tasks, a 9-type bias taxonomy, and ~45K prompts, then measuring Stereotype Scores directly from LLM responses across 7 models. No derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. The reported divergences (e.g., up to 0.43) are computed outputs from the task responses, not self-referential loops. Self-citations, if any, are not load-bearing for the central claims, which rest on the new prompt-based measurements rather than prior author results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The seven tasks validly distinguish explicit decision-making from implicit association without confounding effects from prompt wording.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bias is task-dependent: models counter stereotypes on explicit probes but reproduce them on implicit ones, with Stereotype Score divergences up to 0.43
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical taxonomy covering 9 bias types... 7 evaluation tasks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.